UnpredictaBench: A Benchmark for Evaluating Distributional Randomness in LLMs
Pith reviewed 2026-06-28 01:41 UTC · model grok-4.3
The pith
No LLM exceeds 40 percent on KS@100 when sampling from target distributions in UnpredictaBench.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UnpredictaBench isolates the task of sampling from individual target distributions and shows that current models cannot do so reliably: even the best systems fall short of 40 percent on the KS@100 metric, confirming that distributional simulation remains an open challenge even for simple cases.
What carries the argument
UnpredictaBench, a collection of 448 problems paired with the KS@N metric that counts the fraction of trials in which Kolmogorov-Smirnov tests fail to reject the hypothesis that model samples of size N come from the same distribution as ground-truth samples.
If this is right
- LLMs cannot yet serve as calibrated substitutes for stochastic agents in simulations without additional mechanisms for distributional matching.
- Output-diversity techniques alone are insufficient because they do not guarantee calibration to a specific target distribution.
- Reasoning enhancements yield only partial improvement and do not close the gap to acceptable performance.
- Substantial room remains for new training or inference methods aimed at distributional sampling.
- The benchmark supplies a concrete, quantitative signal for tracking progress on this capability.
Where Pith is reading between the lines
- The same limitation likely constrains the reliability of LLM-based Monte Carlo methods or multi-agent economic models that rely on repeated random draws.
- Extending the benchmark to joint distributions over several variables would test whether the observed shortfall scales to more realistic simulation settings.
- Training objectives that directly penalize deviations measured by statistical tests could be explored as a targeted remedy.
Load-bearing premise
The 448 problems and the KS@N metric together provide a sufficient proxy for the distributional sampling demands that arise when LLMs are used as stand-ins for complex real-world systems.
What would settle it
A model that scores above 40 percent on KS@100 across the full set of 448 problems, or a demonstration that low KS@N scores do not predict failures in downstream simulation tasks that require calibrated randomness.
Figures






read the original abstract
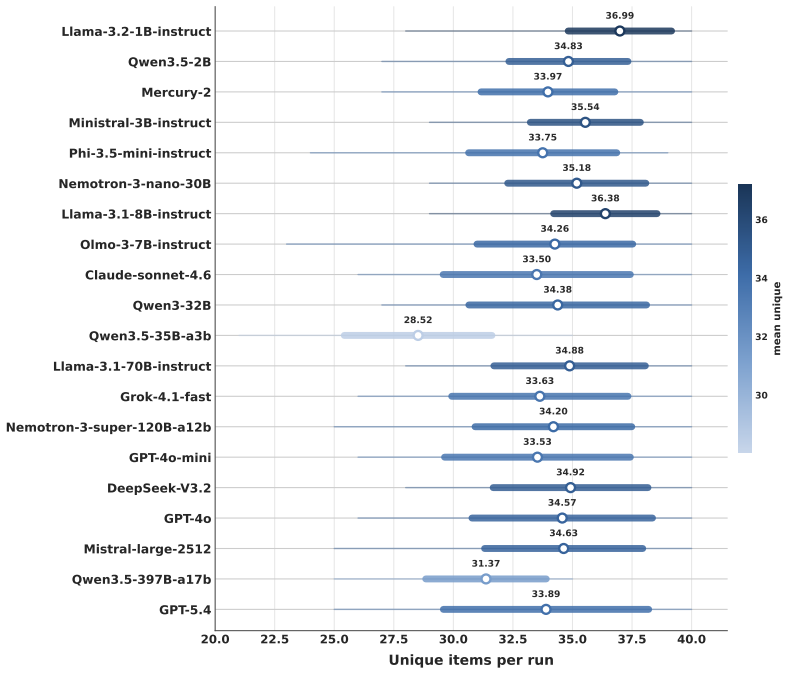
We introduce UnpredictaBench, an evaluation that tests the ability of large language models (LLMs) to capture true underlying distributions. As LLMs are increasingly used as substitutes for other entities (e.g., for humans in economic simulations), the tendency of many models to collapse towards a single plausible answer means a failure to capture the unpredictability of real systems. Recent work on improving output diversity is insufficient for this setting: simulation requires samples that are calibrated to a target distribution, not merely varied outputs. UnpredictaBench isolates a simplified but fundamental version of this problem: sampling outcomes from individual target distributions, including canonical statistical distributions, distributions induced by stochastic programs, and natural-language scenarios that describe random processes. We introduce 448 such problems together with KS@N, a general-purpose evaluation metric that quantifies how well a model outputs approximate black-box target distributions via the Kolmogorov-Smirnov statistical test. This is the rate at which we fail to reject model samples of size N against ground-truth samples, with larger N indicating greater difficulty. Tested across open and proprietary models, we find a large spread in distributional capabilities. For instance, when models generate samples of size 100 (KS@100, our standard metric), scores range from near 0 to over 20%. No model is able to achieve over 40% at KS@100, showing significant headroom in distributional sampling as a capability. Although adding reasoning can somewhat increase scores, we find no immediate solution for this issue. UnpredictaBench shows that even simple distributional simulation remains challenging, making it a necessary first step toward using LLMs as stand-ins for complex systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UnpredictaBench, consisting of 448 tasks that require LLMs to sample from target distributions drawn from canonical statistical families, stochastic programs, and natural-language descriptions of random processes. It defines the KS@N metric as the fraction of trials in which a Kolmogorov-Smirnov test fails to reject the hypothesis that N model samples are drawn from the same distribution as ground-truth samples. Across open and proprietary models the reported KS@100 scores range from near zero to above 20 percent, with no model exceeding 40 percent; modest gains are observed when chain-of-thought reasoning is added, but the gap remains large.
Significance. If the empirical findings are robust, the work identifies a concrete capability gap in distributional calibration that is directly relevant to the growing use of LLMs as substitutes for agents or stochastic components in simulations. The benchmark supplies a reproducible, statistically grounded yardstick (KS@N) that is independent of any model-specific parameters, and the systematic coverage of three distinct task sources is a clear methodological strength.
major comments (2)
- [Abstract and §4 (Results)] Abstract and §4 (Results): The headline claim that the benchmark reveals 'significant headroom' for using LLMs as stand-ins for complex real-world systems rests on the untested assumption that success on isolated single-distribution sampling transfers to joint, conditional, and temporally extended sampling. No correlation study, ablation, or external validation is reported that links KS@N scores to calibration performance in multi-component settings (e.g., multi-agent economic models).
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The manuscript supplies no quantitative details on how the 448 tasks were sampled, what criteria governed inclusion or difficulty calibration, or the statistical power of the KS tests at each N. Without these, it is impossible to determine whether the reported performance ceiling (no model >40 % at KS@100) is an artifact of task selection or a genuine capability limit.
minor comments (2)
- [§2 (Metric)] The definition of the KS@N failure-to-reject rate would benefit from an explicit equation or pseudocode in the methods section to avoid ambiguity about how ties and multiple trials are aggregated.
- [Figures 2-4] Figure captions and axis labels should explicitly state the number of trials per model-task pair so that readers can assess variance in the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and constructive suggestions. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] The headline claim that the benchmark reveals 'significant headroom' for using LLMs as stand-ins for complex real-world systems rests on the untested assumption that success on isolated single-distribution sampling transfers to joint, conditional, and temporally extended sampling. No correlation study, ablation, or external validation is reported that links KS@N scores to calibration performance in multi-component settings (e.g., multi-agent economic models).
Authors: We agree that the manuscript does not provide empirical evidence linking single-distribution KS@N performance to multi-component or temporally extended settings. The paper explicitly frames UnpredictaBench as testing 'a simplified but fundamental version of this problem' (abstract) and positions it as 'a necessary first step' rather than a complete proxy. The headline claim of headroom is scoped to distributional sampling capability itself. To strengthen the manuscript we will revise the abstract and §4 to include an explicit limitations paragraph acknowledging the transfer assumption and outlining planned extensions to joint/conditional sampling. No new experiments are feasible within the current revision cycle. revision: partial
-
Referee: [§3 (Benchmark Construction)] The manuscript supplies no quantitative details on how the 448 tasks were sampled, what criteria governed inclusion or difficulty calibration, or the statistical power of the KS tests at each N. Without these, it is impossible to determine whether the reported performance ceiling (no model >40 % at KS@100) is an artifact of task selection or a genuine capability limit.
Authors: We will expand §3 with the requested details: the procedure for sampling parameter ranges from each statistical family, the inclusion criteria (coverage of 8 canonical families plus stochastic programs and NL scenarios, with parameter bounds chosen to avoid degenerate cases), and a power analysis of the KS test at N=10, 50, 100, and 500 using the ground-truth sample sizes. These additions will be placed in a new subsection on task generation and statistical considerations. revision: yes
Circularity Check
No circularity: benchmark and KS metric are externally grounded
full rationale
The paper defines UnpredictaBench (448 problems) and KS@N (failure-to-reject rate under Kolmogorov-Smirnov test) as new constructs, then reports empirical scores on open/proprietary models. The headline result (no model >40% at KS@100) is a direct measurement against ground-truth samples using the standard external KS procedure; it does not reduce to any fitted parameter, self-citation chain, or definitional equivalence inside the paper. No load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Kolmogorov-Smirnov test provides a valid measure of whether model-generated samples approximate a target distribution.
Reference graph
Works this paper leans on
-
[1]
Introducing Claude Sonnet 4.6
Anthropic. Introducing Claude Sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, February 2026. Accessed: 2026-04-20
2026
-
[2]
Dick, Hidenori Tanaka, and Tomer Ullman
Eric J Bigelow, Ekdeep Singh Lubana, Robert P. Dick, Hidenori Tanaka, and Tomer Ullman. In-context learning dynamics with random binary sequences. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=62K7mALO2q
2024
-
[3]
Specializing large language models to simulate survey response distributions for global populations
Yong Cao, Haijiang Liu, Arnav Arora, Isabelle Augenstein, Paul Röttger, and Daniel Her- shcovich. Specializing large language models to simulate survey response distributions for global populations. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computa...
-
[4]
Deterministic or probabilistic? the psychology of llms as random number generators, 2025
Javier Coronado-Blázquez. Deterministic or probabilistic? the psychology of llms as random number generators, 2025. URLhttps://arxiv.org/abs/2502.19965
arXiv 2025
-
[5]
Deepseek-v3.2: Pushing the frontier of open large language models, 2025
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models, 2025. URL https://arxiv.org/abs/2512.02556
Pith/arXiv arXiv 2025
-
[6]
Do LLMs play dice? exploring probability distribution sampling in large language models for behavioral simulation
Jia Gu, Liang Pang, Huawei Shen, and Xueqi Cheng. Do LLMs play dice? exploring probability distribution sampling in large language models for behavioral simulation. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguisti...
2025
-
[7]
The illusion of stochasticity in llms, 2026
Xiangming Gu, Soham De, Michalis Titsias, Larisa Markeeva, Petar Veliˇckovi´c, and Razvan Pascanu. The illusion of stochasticity in llms, 2026. URL https://arxiv.org/abs/2604. 06543
2026
-
[8]
Zihao Guo, Hongtao Lv, Chaoli Zhang, Yibowen Zhao, Yixin Zhang, and Lizhen Cui. The illusion of randomness: How LLMs fail to emulate stochastic decision-making in rock-paper- scissors games? In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, page...
-
[9]
Can LLMs generate random numbers? eval- uating LLM sampling in controlled domains
Aspen K Hopkins, Alex Renda, and Michael Carbin. Can LLMs generate random numbers? eval- uating LLM sampling in controlled domains. InICML 2023 Workshop: Sampling and Optimiza- tion in Discrete Space, 2023. URLhttps://openreview.net/forum?id=Vhh1K9LjVI
2023
-
[10]
Inner monologue: Em- bodied reasoning through planning with language models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Tomas Jackson, Noah Brown, Linda Luu, Sergey Levine, Karol Hausman, and brian ichter. Inner monologue: Em- bodied reasoning through planning with language models. In6th Annual Conference on Robot Learning...
2022
-
[11]
Joshi, Kyle Jeffrey, Rosario Jauregui Ruano, Jasmine Hsu, Keerthana Gopalakrishnan, Byron David, Andy Zeng, and Chuyuan Kelly Fu
brian ichter, Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, Dmitry Kalashnikov, Sergey Levine, Yao Lu, Carolina Parada, Kanishka Rao, Pierre Sermanet, Alexander T Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Mengyuan Yan, Noah Brown, Michael Ahn, Omar ...
2023
-
[12]
Introducing Mercury 2
Inception Labs. Introducing Mercury 2. https://www.inceptionlabs.ai/blog/ introducing-mercury-2, February 2026. Accessed: 2026-04-20
2026
-
[13]
How random is random? evaluating the random- ness and humaness of llms’ coin flips, 2024
Katherine Van Koevering and Jon Kleinberg. How random is random? evaluating the random- ness and humaness of llms’ coin flips, 2024. URLhttps://arxiv.org/abs/2406.00092
arXiv 2024
-
[14]
Kolmogorov
Andrey N. Kolmogorov. Sulla determinazione empirica di una legge di distribuzione.Giornale dell’Istituto Italiano degli Attuari, 4:83–91, 1933
1933
-
[15]
Reinforcement learning from human feedback, 2026
Nathan Lambert. Reinforcement learning from human feedback, 2026. URL https://arxiv. org/abs/2504.12501
Pith/arXiv arXiv 2026
-
[16]
D. H. Lehmer. Teaching combinatorial tricks to a computer. 1960. URL https://api. semanticscholar.org/CorpusID:115452165
1960
-
[17]
Preserving diversity in supervised fine-tuning of large language models
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Zhi-Quan Luo, and Ruoyu Sun. Preserving diversity in supervised fine-tuning of large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=NQEe7B7bSw
2025
-
[18]
Divergence measures based on the shannon entropy.IEEE Transactions on In- formation theory, 37(1):145–151, 2002
Jianhua Lin. Divergence measures based on the shannon entropy.IEEE Transactions on In- formation theory, 37(1):145–151, 2002. URL https://ieeexplore.ieee.org/document/ 61115
2002
-
[19]
The llama 3 herd of models, 2024
AI @ Meta Llama Team. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/ 2407.21783
Pith/arXiv arXiv 2024
-
[20]
Estimating semantic alphabet size for LLM uncertainty quantification
Lucas Hurley McCabe, Rimon Melamed, Thomas Hartvigsen, and H Howie Huang. Estimating semantic alphabet size for LLM uncertainty quantification. InThe F ourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=uYK6GPVg1O
2026
-
[21]
Discover the new multi-lingual, high-quality Phi-3.5 SLMs
Microsoft. Discover the new multi-lingual, high-quality Phi-3.5 SLMs. https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/ discover-the-new-multi-lingual-high-quality-phi-3-5-slms/4225280 , August
-
[22]
Accessed: 2026-04-20
2026
-
[23]
Introducing Mistral 3
Mistral AI. Introducing Mistral 3. https://mistral.ai/news/mistral-3, December 2025. Accessed: 2026-04-20
2025
-
[24]
Nvidia nemotron 3: Efficient and open intelligence, 2025
NVIDIA. Nvidia nemotron 3: Efficient and open intelligence, 2025. URL https://arxiv. org/abs/2512.20856. White Paper
Pith/arXiv arXiv 2025
-
[25]
Team Olmo, :and Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng,...
Pith/arXiv arXiv 2026
-
[26]
Hello GPT-4o
OpenAI. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/, May 2024. Ac- cessed: 2026-04-20. 16
2024
-
[27]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , March 2026. Accessed: 2026-04-20
2026
-
[28]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23, New York, NY , USA, 2023. Association for Computing Machinery. ISBN 9798400701320. d...
-
[29]
What are the odds? language models are capable of probabilistic reasoning
Akshay Paruchuri, Jake Garrison, Shun Liao, John B Hernandez, Jacob Sunshine, Tim Althoff, Xin Liu, and Daniel McDuff. What are the odds? language models are capable of probabilistic reasoning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11712–1...
2024
-
[30]
Epidemiol- ogy of large language models: A benchmark for observational distribution knowledge
Drago Plevcko, Patrik Okanovic, Torsten Hoefler, and Elias Bareinboim. Epidemiol- ogy of large language models: A benchmark for observational distribution knowledge. ArXiv, abs/2511.03070, 2025. URL https://api.semanticscholar.org/CorpusID: 282757780
arXiv 2025
-
[31]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5. Accessed: 2026-04-20
2026
-
[32]
Reasoning under uncertainty: Efficient LLM inference via unsupervised confidence dilution and convergent adaptive sampling
Zhenning Shi, Yijia Zhu, Yi Xie, Junhan Shi, Guorui Xie, Haotian Zhang, Yong Jiang, Congcong Miao, and Qing Li. Reasoning under uncertainty: Efficient LLM inference via unsupervised confidence dilution and convergent adaptive sampling. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Confer...
2025
-
[33]
Nikolai V . Smirnov. Table for estimating the goodness of fit of empirical distributions.The Annals of Mathematical Statistics, 19(2):279–281, 1948
1948
-
[34]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[35]
Create: Testing llms for associative creativity, 2026
Manya Wadhwa, Tiasa Singha Roy, Harvey Lederman, Junyi Jessy Li, and Greg Durrett. Create: Testing llms for associative creativity, 2026. URLhttps://arxiv.org/abs/2603.09970
Pith/arXiv arXiv 2026
-
[36]
Base models beat aligned models at randomness and creativity
Peter West and Christopher Potts. Base models beat aligned models at randomness and creativity. InSecond Conference on Language Modeling, 2025. URL https://openreview. net/forum?id=vqN8uom4A1
2025
-
[37]
Grok 4.1.https://x.ai/news/grok-4-1, November 2025
xAI. Grok 4.1.https://x.ai/news/grok-4-1, November 2025. Accessed: 2026-04-20
2025
-
[38]
Embarrassingly simple self-distillation improves code generation, 2026
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang. Embarrassingly simple self-distillation improves code generation, 2026. URL https://arxiv.org/abs/2604.01193
Pith/arXiv arXiv 2026
-
[39]
Runze Zhang, Xiaowei Zhang, and Mingyang Zhao. Predicting effects, missing dis- tributions: Evaluating llms as human behavior simulators in operations management. ArXiv, abs/2510.03310, 2025. URL https://api.semanticscholar.org/CorpusID: 281842519
arXiv 2025
-
[40]
Noveltybench: Evaluating creativity and diversity in language models
Yiming Zhang, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay Samuel, Barry Wang, and Daphne Ippolito. Noveltybench: Evaluating creativity and diversity in language models. InSecond Conference on Language Modeling, 2025. URL https://openreview. net/forum?id=XZm1ekzERf. 17
2025
-
[41]
Minda Zhao, Yilun Du, and Mengyu Wang. Large language models are bad dice players: Llms struggle to generate random numbers from statistical distributions, 2026. URL https: //arxiv.org/abs/2601.05414
Pith/arXiv arXiv 2026
-
[42]
P1", 50) path2 = Path(
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openre...
2023
-
[43]
rationale
If the output does not report any number (only code, explanation, etc.), return {{"rationale": "No number found in the model output", "number": null}}
-
[44]
rationale
If the output reports a number, return {{"rationale": "The model mentioned «the_number» in the exact text «exact_span» at «exact_location» of the output", "number": <the_number>}}
-
[45]
rationale
There may exist some cases that the model output is incomplete, malformed, or does not follow instructions. In those cases, you may see some numbers unrelated to the final answer (like repeating the list of parameters from the input distribution); therefore, if you cannot confidently identify a number being reported as the final answer, default to {{"rati...
-
[46]
Do not infer, calculate, or extract values from variable names, code structure, or explanatory text unless they are clearly presented as the answer
Only use numbers that are explicitly present in the model output. Do not infer, calculate, or extract values from variable names, code structure, or explanatory text unless they are clearly presented as the answer. 49
-
[47]
For «exact_span», copy the smallest exact substring from the model output that contains the reported number
-
[48]
beginning of the output
For «exact_location», briefly describe where that exact span occurs in the output. Example templates include "beginning of the output", "middle of the output", "end of the output", "first line", and "last line", but any other concise, precise location description is allowed
-
[49]
Do NOT quote any number unless it is the final reported answer
-
[50]
Before finalizing, verify that the JSON is valid, the rationale matches the chosen number or null outcome, and any number returned is explicitly presented in the model output as the final answer
-
[51]
rationale
Return only one valid JSON object with exactly these keys and no extra text, markdown, or formatting: {{"rationale": "No number found in the model output", "number": null}} or {{"rationale": "The model mentioned «the_number» in the exact text «exact_span» at «exact_location» of the output", "number": <the_number>}}. Prompt N.14: Answer Extractor LLM (text...
-
[52]
rationale
If the output does not clearly present exactly {expected_count} distinct final numeric answers, return {{"rationale": <string explaining why>, "numbers": null}}
-
[53]
rationale
If the output clearly presents exactly {expected_count} final numeric answers (for example one number per line), return {{"rationale": <string summarizing where each value appears>, "numbers": [<n1>, <n2>, ...]}} with the numbers in the same order as in the model output (list length must be exactly {expected_count})
-
[54]
If you cannot confidently identify exactly {expected_count} values as the final answers, return "numbers": null
Ignore numbers that are clearly not part of the final answers (parameters from the prompt, line numbers, unrelated code). If you cannot confidently identify exactly {expected_count} values as the final answers, return "numbers": null
-
[55]
Do not infer or calculate unstated values
Only use numbers explicitly present in the model output. Do not infer or calculate unstated values
-
[56]
Each element of "numbers" must be a JSON number (integer or float), not a string. 50
-
[57]
rationale
Return only one valid JSON object with exactly these keys and no extra text, markdown, or code fences: "rationale" (string) and "numbers" (JSON array of length {expected_count} or null). Prompt N.15: Answer Extractor LLM (shuffling task) Analyze the model output below and extract exactly one shuffled list answer. The model output is the response of anothe...
-
[58]
rationale
Return exactly one valid JSON object with exactly these keys: {"rationale": <string>, "value": <list_or_null>}
-
[59]
rationale
If there is no valid list answer, return {"rationale": "No valid list found in the model output", "value": null}
-
[60]
If multiple possible answers appear (for example text containing "or"), choose the first complete list that appears in the output
-
[61]
The "value" field must be a JSON array (not a string) and must preserve the original order and element types
-
[62]
Allowed list element types: string, integer, float
-
[63]
If the model uses Python-style single quotes, convert them to equivalent JSON string values in "value"
-
[64]
Do not infer missing elements and do not synthesize a list
-
[65]
Prompt N.16: Answer Extractor LLM (real-world task) Analyze the model output below and extract one final textual answer exactly as reported
Return only the JSON object and no additional text, markdown, or code fences. Prompt N.16: Answer Extractor LLM (real-world task) Analyze the model output below and extract one final textual answer exactly as reported. The model output may be a single word, a short token, or a multiline program output. Model output: {model_output} Rules:
-
[66]
rationale
Return exactly one valid JSON object with exactly these keys: {"rationale": <string>, "value": <string_or_null>}. 51
-
[67]
rationale
If no usable answer text is present, return {"rationale": "No valid textual answer found in the model output", "value": null}
-
[68]
Preserve line order and internal newlines for multiline outputs
-
[69]
Trim only leading/trailing whitespace around the whole extracted answer
-
[70]
If the output contains multiple alternatives in one line (for example "A or B"), choose the first explicit answer candidate
-
[71]
Do not invent content and do not infer missing lines
-
[72]
Return only the JSON object and no additional text, markdown, or code fences. 52
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.