Chiseling Out Efficiency: Structured Skeleton Supervision for Efficient Code Generation
Pith reviewed 2026-06-27 21:41 UTC · model grok-4.3
The pith
LLMs generate faster code by explicitly learning abstract efficiency skeletons in a joint multi-task setup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
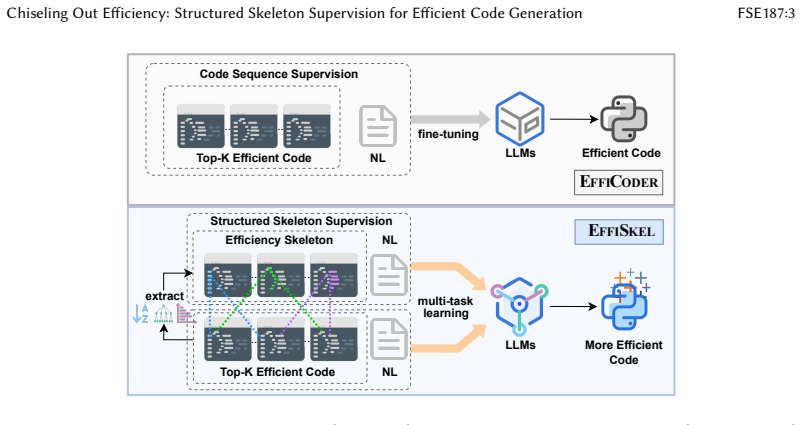
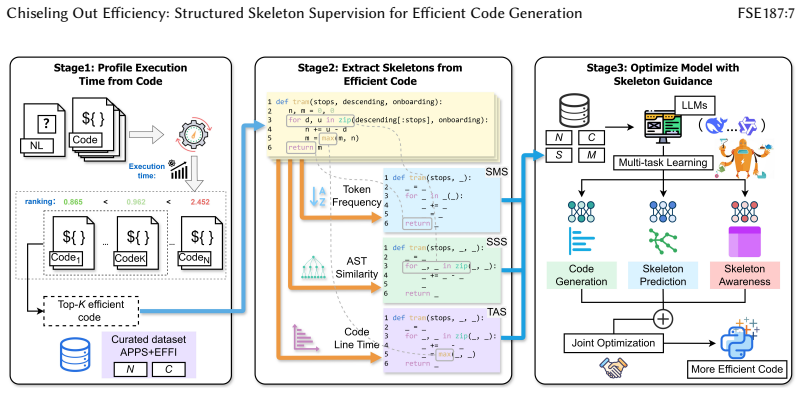
EffiSkel extracts efficiency skeletons as abstract reusable structural patterns embedded in efficient code and integrates them into a multi-task learning regime that jointly optimizes code generation and skeleton prediction, producing measurable gains in functional correctness together with higher Efficiency Ratio and Average Speedup on held-out benchmarks.
What carries the argument
Efficiency skeletons: abstract reusable structural patterns that underpin efficient code, extracted from complex syntax and control flows then supervised jointly with generation.
If this is right
- Generated programs achieve both higher functional correctness and better runtime performance across multiple programming languages.
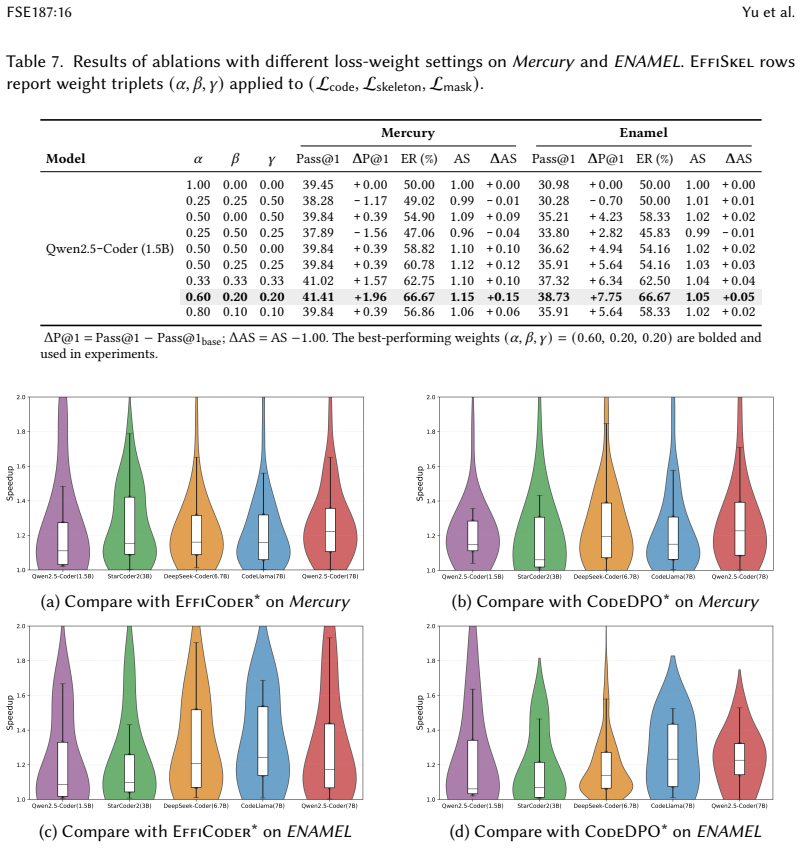
- On the Mercury benchmark with DeepSeek-Coder (7B), Efficiency Ratio rises by 11.11 percent over EffiCoder and 3.71 percent over CodeDPO.
- Average Speedup increases by 0.36 over EffiCoder and 0.22 over CodeDPO on the same setting.
- The multi-task skeleton supervision works without requiring separate post-generation optimization passes.
Where Pith is reading between the lines
- The same skeleton-supervision pattern might transfer to other structured generation domains such as query optimization or proof synthesis.
- If skeletons prove stable across model scales, the method could reduce dependence on large post-training efficiency corpora.
- A direct test would measure whether removing the skeleton-prediction head at inference time still retains most of the efficiency gain.
Load-bearing premise
Latent efficiency skeletons can be extracted reliably from syntax and control flow and learned jointly without harming the model's semantic code-generation ability.
What would settle it
Train an EffiSkel model and evaluate it on the Mercury benchmark; if Efficiency Ratio and Average Speedup show no improvement over the EffiCoder and CodeDPO baselines, the central claim is falsified.
Figures

read the original abstract
Large Language Models (LLMs) are capable of generating syntactically correct and functionally complete programs, greatly streamlining software development. However, recent studies reveal that these programs typically execute substantially slower than human-optimized counterparts. Existing approaches to bridging this efficiency gap typically involve either iteratively optimizing code after generation or fine-tuning models on corpora of efficient code. Yet, these methods expose the model to efficiency signals only by mimicking complete, optimized solutions, without explicitly encoding the structural code patterns essential for achieving high runtime performance. Addressing this gap presents two core challenges: (1) extracting and representing latent, efficiency-oriented structural patterns embedded within complex syntax and control flows, and (2) effectively learning these patterns without destabilizing the semantic training of LLMs. To tackle these challenges, we propose EffiSkel, an efficiency skeleton-guided framework that explicitly extracts and learns efficiency skeletons-abstract, reusable structural patterns underpinning efficient code-by leveraging three complementary strategies. These skeletons are integrated into a multi-task learning regime that jointly optimizes code generation and skeleton prediction. Experiments across multiple programming languages and benchmarks demonstrate that EffiSkel significantly enhances both functional correctness and efficiency, resulting on Mercury with DeepSeek-Coder (7B) a +11.11% (vs. EffiCoder) and +3.71% (vs. CodeDPO) higher Efficiency Ratio (ER), and a +0.36 (vs. EffiCoder) and +0.22 (vs. CodeDPO) increase in Average Speedup (AS). These results highlight the effectiveness of explicitly modeling efficiency skeletons in improving the runtime performance of code generated by LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EffiSkel, a framework that extracts 'efficiency skeletons' (abstract reusable structural patterns for efficient code) from optimized programs via three complementary strategies, then uses them in a multi-task learning setup to jointly train LLMs on code generation and skeleton prediction; it claims this improves both functional correctness and runtime efficiency metrics (ER and AS) over baselines like EffiCoder and CodeDPO on benchmarks including Mercury with DeepSeek-Coder (7B), reporting gains such as +11.11% ER and +0.36 AS.
Significance. If the central claim holds and the skeletons are shown to be distinct learnable efficiency abstractions rather than auxiliary signals, the work could provide a structured supervision method that goes beyond post-hoc optimization or direct fine-tuning on efficient code, with potential to improve LLM code generation in software engineering practice across languages.
major comments (3)
- [Abstract] Abstract: the central claim that efficiency skeletons are 'abstract, reusable structural patterns underpinning efficient code' extracted via three complementary strategies lacks any formal definition, extraction algorithm, invariance properties, or pseudocode; without this, it is impossible to determine whether the reported ER/AS gains arise from distinct efficiency signals or simply from extra gradient supervision in the multi-task objective.
- [Abstract] The manuscript supplies no error analysis, ablation isolating the skeleton component, or derivation showing how the multi-task loss preserves semantic capabilities while learning efficiency patterns; this directly bears on the weakest assumption that latent efficiency structures can be extracted from complex control flow without destabilizing functional correctness.
- [Abstract] The empirical results (e.g., +11.11% ER vs. EffiCoder on Mercury) are presented as post-hoc comparisons against named external baselines with no detail on how the three strategies were implemented or validated, leaving open whether gains reduce to quantities defined by the paper's own method or to generic multi-task effects.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that efficiency skeletons are 'abstract, reusable structural patterns underpinning efficient code' extracted via three complementary strategies lacks any formal definition, extraction algorithm, invariance properties, or pseudocode; without this, it is impossible to determine whether the reported ER/AS gains arise from distinct efficiency signals or simply from extra gradient supervision in the multi-task objective.
Authors: Section 3 of the manuscript details the three complementary extraction strategies along with their algorithmic descriptions. We will revise the abstract to include a concise outline of these strategies and add explicit cross-references to the formal definitions and pseudocode already present in the main text. This will better highlight that the skeletons constitute distinct structural patterns. revision: yes
-
Referee: [Abstract] The manuscript supplies no error analysis, ablation isolating the skeleton component, or derivation showing how the multi-task loss preserves semantic capabilities while learning efficiency patterns; this directly bears on the weakest assumption that latent efficiency structures can be extracted from complex control flow without destabilizing functional correctness.
Authors: We agree that an explicit ablation isolating the skeleton-prediction task and supporting analysis would strengthen the claims. We will add both an ablation study and a brief derivation of the multi-task objective in the revised version to demonstrate preservation of semantic performance. revision: yes
-
Referee: [Abstract] The empirical results (e.g., +11.11% ER vs. EffiCoder on Mercury) are presented as post-hoc comparisons against named external baselines with no detail on how the three strategies were implemented or validated, leaving open whether gains reduce to quantities defined by the paper's own method or to generic multi-task effects.
Authors: Implementation and validation details for the three strategies appear in Sections 3 and 4. We will expand the experimental section with additional validation metrics on skeleton quality and a clearer description of the shared experimental protocol used for all baselines to distinguish method-specific effects from generic multi-task learning. revision: partial
Circularity Check
No circularity: empirical comparisons to external baselines with independent efficiency metrics.
full rationale
The paper proposes EffiSkel via three strategies for extracting efficiency skeletons and a multi-task objective, then reports empirical gains on ER and AS versus named external baselines (EffiCoder, CodeDPO). No equations, fitted parameters, or self-citations are shown that reduce the reported predictions or skeleton definitions to the paper's own inputs by construction. The extraction and learning steps are presented as novel contributions evaluated against independent references, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-task loss balancing weights
axioms (1)
- domain assumption Efficiency skeletons exist as latent, reusable structural patterns embedded in efficient code that can be extracted independently of full program semantics.
invented entities (1)
-
efficiency skeleton
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed, Kunal Suresh Pai, Premkumar Devanbu, and Earl Barr. 2024. Automatic semantic augmentation of language model prompts (for code summarization). InProceedings of the IEEE/ACM 46th international conference on software engineering. 1–13
2024
-
[2]
2025.Welcome to Claude 4: Your Partner in AI Innovation
Anthropic. 2025.Welcome to Claude 4: Your Partner in AI Innovation. https://claude4.org/
2025
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732 (2021)
Pith/arXiv arXiv 2021
-
[4]
Tom Cappendijk, Pepijn de Reus, and Ana Oprescu. 2024. Generating Energy-efficient code with LLMs.arXiv preprint arXiv:2411.10599(2024)
arXiv 2024
-
[5]
Pierre Chambon, Baptiste Roziere, Benoit Sagot, and Gabriel Synnaeve. 2025. BigO(Bench): Can LLMs Generate Code with Controlled Time and Space Complexity?arXiv preprint arXiv:2503.15242(2025)
arXiv 2025
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
Pith/arXiv arXiv 2021
-
[7]
Tristan Coignion, Clément Quinton, and Romain Rouvoy. 2024. A performance study of llm-generated code on leetcode. InProceedings of the 28th international conference on evaluation and assessment in software engineering. 79–89
2024
-
[8]
Mingzhe Du, Anh Tuan Luu, Bin Ji, Qian Liu, and See-Kiong Ng. 2024. Mercury: A code efficiency benchmark for code large language models.Advances in Neural Information Processing Systems37 (2024), 16601–16622
2024
-
[9]
Mingzhe Du, Luu Anh Tuan, Yue Liu, Yuhao Qing, Dong Huang, Xinyi He, Qian Liu, Zejun Ma, and See-kiong Ng
-
[10]
Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization.arXiv preprint arXiv:2505.23387(2025)
arXiv 2025
-
[11]
Xiaoning Feng, Xiaohong Han, Simin Chen, and Wei Yang. 2024. Llmeffichecker: Understanding and testing efficiency degradation of large language models.ACM Transactions on Software Engineering and Methodology33, 7 (2024), 1–38
2024
-
[12]
Shuzheng Gao, Cuiyun Gao, Wenchao Gu, and Michael Lyu. 2024. Search-based llms for code optimization. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 254–266
2024
-
[13]
Qiuhan Gu. 2023. Llm-based code generation method for golang compiler testing. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2201–2203
2023
-
[14]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025). Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE187. Publication date: July 2026. Chiseling Out Effi...
Pith/arXiv arXiv 2025
-
[15]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
Pith/arXiv arXiv 2024
-
[16]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Measuring coding challenge competence with apps.arXiv preprint arXiv:2105.09938 (2021)
Pith/arXiv arXiv 2021
-
[17]
Dong Huang, Jianbo Dai, Han Weng, Puzhen Wu, Yuhao Qing, Heming Cui, Zhijiang Guo, and Jie Zhang. 2024. Effilearner: Enhancing efficiency of generated code via self-optimization.Advances in Neural Information Processing Systems37 (2024), 84482–84522
2024
-
[18]
Dong Huang, Yuhao Qing, Weiyi Shang, Heming Cui, and Jie Zhang. 2024. Effibench: Benchmarking the efficiency of automatically generated code.Advances in Neural Information Processing Systems37 (2024), 11506–11544
2024
-
[19]
Dong Huang, Guangtao Zeng, Jianbo Dai, Meng Luo, Han Weng, Yuhao QING, Heming Cui, Zhijiang Guo, and Jie Zhang. 2025. EffiCoder: Enhancing Code Generation in Large Language Models through Efficiency-Aware Fine-tuning. InForty-second International Conference on Machine Learning
2025
-
[20]
Tao Huang, Zhihong Sun, Zhi Jin, Ge Li, and Chen Lyu. 2024. Knowledge-aware code generation with large language models. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 52–63
2024
-
[21]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, et al . 2024. Qwen2.5-Coder Technical Report.arXiv preprint arXiv:2409.12186(2024)
Pith/arXiv arXiv 2024
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. GPT-4o System Card.arXiv preprint arXiv:2410.21276(2024)
Pith/arXiv arXiv 2024
-
[23]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation.arXiv preprint arXiv:2406.00515(2024)
Pith/arXiv arXiv 2024
-
[24]
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, et al . 2024. DevEval: A manually- annotated code generation benchmark aligned with real-world code repositories. InFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, 3603–3614
2024
-
[25]
Jia Li, Yongmin Li, Ge Li, Zhi Jin, Yiyang Hao, and Xing Hu. 2023. Skcoder: A sketch-based approach for automatic code generation. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2124–2135
2023
-
[26]
Jiawei Liu, Songrun Xie, Junhao Wang, Yuxiang Wei, Yifeng Ding, and Lingming Zhang. 2024. Evaluating language models for efficient code generation.arXiv preprint arXiv:2408.06450(2024)
arXiv 2024
-
[27]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. 2024. Starcoder 2 and the stack v2: The next generation.arXiv preprint arXiv:2402.19173(2024)
Pith/arXiv arXiv 2024
-
[28]
Alex Mathai, Kranthi Sedamaki, Debeshee Das, Noble Saji Mathews, Srikanth Tamilselvam, Sridhar Chimalakonda, and Atul Kumar. 2024. CodeSAM: Source Code Representation Learning by Infusing Self-Attention with Multi-Code-View Graphs.arXiv preprint arXiv:2411.14611(2024)
arXiv 2024
-
[29]
Changan Niu, Ting Zhang, Chuanyi Li, Bin Luo, and Vincent Ng. 2024. On evaluating the efficiency of source code generated by llms. InProceedings of the 2024 IEEE/ACM First International Conference on AI Foundation Models and Software Engineering. 103–107
2024
-
[30]
Yue Pan, Chen Lyu, Zhenyu Yang, Lantian Li, Qi Liu, and Xiuting Shao. 2025. E-code: Mastering efficient code generation through pretrained models and expert encoder group.Information and Software Technology178 (2025), 107602
2025
-
[31]
Indraneil Paul, Haoyi Yang, Goran Glavaš, Kristian Kersting, and Iryna Gurevych. 2025. ObscuraCoder: Powering Efficient Code LM Pre-Training Via Obfuscation Grounding.arXiv preprint arXiv:2504.00019(2025)
arXiv 2025
-
[32]
Huiyun Peng, Arjun Gupte, Nicholas John Eliopoulos, Chien Chou Ho, Rishi Mantri, Leo Deng, Wenxin Jiang, Yung- Hsiang Lu, Konstantin Läufer, George K Thiruvathukal, et al. 2024. Large Language Models for Energy-Efficient Code: Emerging Results and Future Directions.arXiv preprint arXiv:2410.09241(2024)
arXiv 2024
-
[33]
Yun Peng, Jun Wan, Yichen Li, and Xiaoxue Ren. 2025. Coffe: A code efficiency benchmark for code generation. Proceedings of the ACM on Software Engineering2, FSE (2025), 242–265
2025
-
[34]
Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al. 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks.arXiv preprint arXiv:2105.12655(2021)
arXiv 2021
-
[35]
Ruizhong Qiu, Weiliang Will Zeng, James Ezick, Christopher Lott, and Hanghang Tong. 2024. How efficient is llm-generated code? a rigorous & high-standard benchmark.arXiv preprint arXiv:2406.06647(2024)
arXiv 2024
-
[36]
Maxim Rabinovich, Mitchell Stern, and Dan Klein. 2017. Abstract Syntax Networks for Code Generation and Semantic Parsing. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1139–1149. Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE187. Publication date: July 2026. FSE187:22 Yu et al
2017
-
[37]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
Pith/arXiv arXiv 2023
-
[38]
Mohammed A Shehab, Mohammad Wardat, Safwan Omari, and Yaser Jararweh. 2024. Evaluating Large Language Models for Code Generation: Assessing Accuracy, Quality, and Performance. In2024 2nd International Conference on Foundation and Large Language Models (FLLM). IEEE, 407–416
2024
-
[39]
Jieke Shi, Zhou Yang, and David Lo. 2024. Efficient and green large language models for software engineering: Vision and the road ahead.ACM Transactions on Software Engineering and Methodology(2024)
2024
-
[40]
Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gardner, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, and Amir Yazdanbakhsh. 2023. Learning performance-improving code edits.arXiv preprint arXiv:2302.07867(2023)
arXiv 2023
-
[41]
Yewei Song, Cedric Lothritz, Xunzhu Tang, Tegawendé Bissyandé, and Jacques Klein. 2024. Revisiting Code Similarity Evaluation with Abstract Syntax Tree Edit Distance. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 38–46
2024
-
[42]
Zhihong Sun, Chen Lyu, Bolun Li, Yao Wan, Hongyu Zhang, Ge Li, and Zhi Jin. 2024. Enhancing Code Generation Performance of Smaller Models by Distilling the Reasoning Ability of LLMs. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 5878–5895
2024
-
[43]
Zeyu Sun, Qihao Zhu, Lili Mou, Yingfei Xiong, Ge Li, and Lu Zhang. 2019. A grammar-based structural cnn decoder for code generation. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 7055–7062
2019
-
[44]
Zeyu Sun, Qihao Zhu, Yingfei Xiong, Yican Sun, Lili Mou, and Lu Zhang. 2020. Treegen: A tree-based transformer architecture for code generation. InProceedings of the AAAI conference on artificial intelligence, Vol. 34. 8984–8991
2020
-
[45]
Siddhant Waghjale, Vishruth Veerendranath, Zhiruo Wang, and Daniel Fried. 2024. ECCO: Can We Improve Model- Generated Code Efficiency Without Sacrificing Functional Correctness?. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 15362–15376
2024
-
[46]
Chong Wang, Jian Zhang, Yebo Feng, Tianlin Li, Weisong Sun, Yang Liu, and Xin Peng. 2025. Teaching code llms to use autocompletion tools in repository-level code generation.ACM Transactions on Software Engineering and Methodology 34, 7 (2025), 1–27
2025
-
[47]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder- Decoder Models for Code Understanding and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 8696–8708
2021
-
[48]
Yingfei Xiong and Bo Wang. 2022. L2S: A framework for synthesizing the most probable program under a specification. ACM Transactions on Software Engineering and Methodology (TOSEM)31, 3 (2022), 1–45
2022
-
[49]
Chengran Yang, Hong Jin Kang, Jieke Shi, and David Lo. 2024. ACECode: A Reinforcement Learning Framework for Aligning Code Efficiency and Correctness in Code Language Models.arXiv preprint arXiv:2412.17264(2024)
arXiv 2024
-
[50]
Yanming Yang, Xing Hu, Xin Xia, David Lo, and Xiaohu Yang. 2024. Streamlining Java Programming: Uncovering Well- Formed Idioms with IdioMine. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–12
2024
-
[51]
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, and Ge Li
-
[52]
Exploring and unleashing the power of large language models in automated code translation.Proceedings of the ACM on Software Engineering1, FSE (2024), 1585–1608
2024
-
[53]
Tong Ye, Yangkai Du, Tengfei Ma, Lingfei Wu, Xuhong Zhang, Shouling Ji, and Wenhai Wang. 2025. Uncovering llm-generated code: A zero-shot synthetic code detector via code rewriting. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 968–976
2025
-
[54]
Tong Ye, Weigang Huang, Xuhong Zhang, Tengfei Ma, Peiyu Liu, Jianwei Yin, and Wenhai Wang. 2025. LLM4EFFI: Leveraging Large Language Models to Enhance Code Efficiency and Correctness.arXiv preprint arXiv:2502.18489 (2025)
arXiv 2025
-
[55]
Hailong Yu, Bo Shen, Dong Ran, Jian Zhang, Qi Zhang, Yifan Ma, et al. 2024. CodeEval: A benchmark of pragmatic code generation with generative pre-trained models. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. IEEE/ACM, 1–12
2024
-
[56]
Daoguang Zan, Ailun Yu, Wei Liu, Dong Chen, Bo Shen, Wei Li, Yafen Yao, Yongshun Gong, Xiaolin Chen, Bei Guan, et al. 2024. Codes: Natural language to code repository via multi-layer sketch.arXiv preprint arXiv:2403.16443(2024)
arXiv 2024
-
[57]
Kechi Zhang, Ge Li, Yihong Dong, Jingjing Xu, Jun Zhang, Jing Su, Yongfei Liu, and Zhi Jin. 2024. Codedpo: Aligning code models with self generated and verified source code.arXiv preprint arXiv:2410.05605(2024)
arXiv 2024
-
[58]
Lei Zhang, Yunshui Li, Jiaming Li, Xiaobo Xia, Jiaxi Yang, Run Luo, Minzheng Wang, Longze Chen, Junhao Liu, Qiang Qu, et al. 2025. Hierarchical context pruning: Optimizing real-world code completion with repository-level pretrained code llms. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25886–25894. Proc. ACM Softw. Eng., Vol....
2025
-
[59]
Qidong Zhao, Milind Chabbi, and Xu Liu. 2024. EasyView: Bringing Performance Profiles into Integrated Development Environments. In2024 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 386–398
2024
-
[60]
Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Lei Shen, Zihan Wang, Andi Wang, Yang Li, et al. 2023. Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5673–5684
2023
-
[61]
Qihao Zhu, Qingyuan Liang, Zeyu Sun, Yingfei Xiong, Lu Zhang, and Shengyu Cheng. 2024. GrammarT5: Grammar- integrated pretrained encoder-decoder neural model for code. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13. Received 2026-02-08; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE187. P...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.