LRMIL: Efficient Low-Resolution Multiple Instance Learning via High-Resolution Knowledge Distillation for Whole Slide Image Classification
Pith reviewed 2026-06-27 22:43 UTC · model grok-4.3
The pith
LRMIL transfers high-resolution knowledge to low-resolution patch embeddings so that a student MIL model can classify whole slide images accurately while using only low-resolution data at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LRMIL adopts a two-stage distillation strategy. First, patch-level cross-resolution distillation aligns low-resolution patch embeddings with high-resolution representations. Second, slide-level knowledge distillation trains a low-resolution student MIL model under both slide-level supervision and teacher guidance. At inference time, LRMIL operates exclusively on low-resolution patches, substantially reducing data preprocessing and computational cost while outperforming state-of-the-art MIL methods on multiple WSI benchmarks.
What carries the argument
Two-stage knowledge distillation consisting of patch-level cross-resolution alignment followed by slide-level teacher-student training of the MIL aggregator.
If this is right
- Inference cost drops because only low-resolution patches need extraction and encoding.
- Global visual cues from lower magnifications become available without sacrificing local detail through the distilled representations.
- The same low-resolution student model can be deployed across multiple slides without re-extracting high-resolution data.
- Slide-level prediction accuracy improves over prior MIL baselines that rely solely on high-resolution patches.
Where Pith is reading between the lines
- The method may allow pathology labs to scan and store slides at lower resolution from the outset, changing acquisition protocols.
- Similar cross-resolution distillation could be tested on other MIL tasks such as video or document classification where resolution or scale trade-offs exist.
- If the patch-level alignment step is removed, the slide-level distillation alone might still suffice; this could be checked by ablating the first stage on the same benchmarks.
Load-bearing premise
High-resolution knowledge can be distilled into low-resolution patch representations without losing the information required for correct slide-level predictions.
What would settle it
Training a low-resolution MIL model from scratch on the same low-resolution patches, without any high-resolution teacher, and showing that its accuracy equals or exceeds LRMIL on the reported benchmarks would falsify the necessity of the distillation step.
Figures

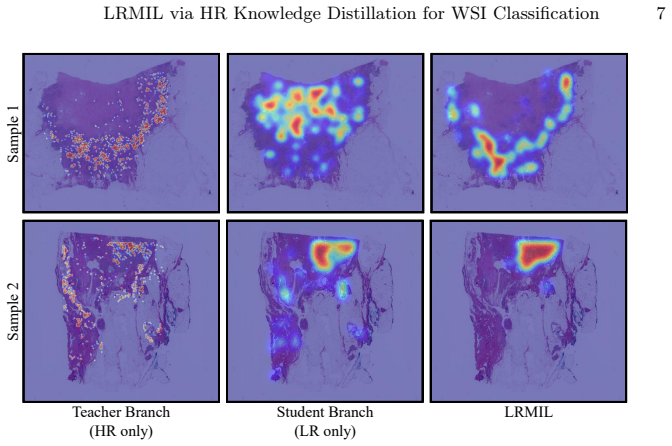
read the original abstract
Multiple instance learning (MIL) has become a standard paradigm for whole slide image (WSI) analysis in digital pathology, as it enables slide-level prediction without dense annotations. Existing MIL methods typically rely on exhaustive extraction and encoding of high-resolution patches. However, this practice suffers from two critical limitations in real-world clinical settings: it struggles to capture global visual cues at lower magnifications, and incurs substantial computational overhead due to the massive number of high-resolution patches per slide. To address these limitations, we propose an efficient low-resolution multiple instance learning (LRMIL) framework that transfers high-resolution knowledge to low-resolution representations. LRMIL adopts a two-stage distillation strategy. First, patch-level cross-resolution distillation aligns low-resolution patch embeddings with high-resolution representations. Second, slide-level knowledge distillation trains a low-resolution student MIL model under both slide-level supervision and teacher guidance. At inference time, LRMIL operates exclusively on low-resolution patches, substantially reducing data preprocessing and computational cost. Extensive experiments on multiple WSI benchmarks demonstrate that LRMIL consistently outperforms state-of-the-art MIL methods while achieving more efficient inference. These results highlight LRMIL as a practical and scalable solution for WSI analysis in clinical pathology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the LRMIL framework for whole slide image classification using multiple instance learning. It addresses limitations of high-resolution patch processing by distilling knowledge from high-resolution to low-resolution representations through a two-stage process: patch-level cross-resolution distillation to align embeddings, followed by slide-level knowledge distillation to train a low-resolution student model. At inference, only low-resolution patches are used, claiming superior performance and efficiency over existing MIL methods on WSI benchmarks.
Significance. If the experimental claims hold, this would represent a meaningful advance in computational pathology by mitigating the computational costs of high-resolution WSI processing while preserving discriminative power via distillation, potentially enabling more scalable clinical deployment.
minor comments (1)
- [Abstract] Abstract: the claim that LRMIL 'consistently outperforms state-of-the-art MIL methods' on 'multiple WSI benchmarks' is stated without any quantitative metrics, table references, or result highlights. Adding 1-2 key performance numbers (e.g., AUC deltas and inference-time reductions) would make the central claim immediately verifiable from the abstract.
Simulated Author's Rebuttal
We thank the referee for their constructive summary of our work and for recommending minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces LRMIL as an independent two-stage distillation framework (patch-level cross-resolution alignment followed by slide-level KD) that is trained and evaluated on external WSI benchmarks. No derivation chain reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction; the central performance claims rest on empirical comparisons rather than internal redefinitions or ansatzes imported from the authors' prior work. The method description contains no self-definitional equations, no renaming of known results as novel organization, and no load-bearing uniqueness theorems justified solely by overlapping citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multiple instance learning can be applied to whole slide images with slide-level labels only.
Reference graph
Works this paper leans on
-
[1]
Database2022, baac093 (2022)
Brancati, N., Anniciello, A.M., Pati, P., Riccio, D., Scognamiglio, G., Jaume, G., De Pietro, G., Di Bonito, M., Foncubierta, A., Botti, G., et al.: Bracs: A dataset for breast carcinoma subtyping in h&e histology images. Database2022, baac093 (2022)
2022
-
[2]
Advances in neural information pro- cessing systems30(2017)
Chen, G., Choi, W., Yu, X., Han, T., Chandraker, M.: Learning efficient object detection models with knowledge distillation. Advances in neural information pro- cessing systems30(2017)
2017
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Chen, P., Liu, S., Zhao, H., Jia, J.: Distilling knowledge via knowledge review. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 5008–5017 (2021)
2021
-
[4]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Dong, J., Jiang, J., Jiang, K., Li, J., Zhang, Y.: Fast and accurate gigapixel patho- logical image classification with hierarchical distillation multi-instance learning. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 30818–30828 (2025)
2025
-
[5]
In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention
Filiot, A., Dop, N., Tchita, O., Riou, A., Dubois, R., Peeters, T., Valter, D., Scal- bert, M., Saillard, C., Robin, G., et al.: Distilling foundation models for robust and efficient models in digital pathology. In: International Conference on Medi- cal Image Computing and Computer-Assisted Intervention. pp. 162–172. Springer (2025) 10 Shin et al
2025
-
[6]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Guo, H., Zhang, Q., Gao, Z., Yang, S., Peng, S., Tao, X., Yu, T., Wang, Y., Li, Q.: Efficient multi-slide visual-language feature fusion for placental disease classifica- tion. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 8018–8027 (2025)
2025
-
[7]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Guo, Z., Xiong, C., Ma, J., Sun, Q., Feng, L., Wang, J., Chen, H.: Focus: Knowledge-enhanced adaptive visual compression for few-shot whole slide image classification. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 15590–15600 (2025)
2025
-
[8]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
In: International conference on machine learning
Ilse,M.,Tomczak,J.,Welling,M.:Attention-baseddeepmultipleinstancelearning. In: International conference on machine learning. pp. 2127–2136. PMLR (2018)
2018
-
[10]
Patterns5(3) (2024)
Kefeli, J., Tatonetti, N.: Tcga-reports: A machine-readable pathology report re- source for benchmarking text-based AI models. Patterns5(3) (2024)
2024
-
[11]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, B., Li, Y., Eliceiri, K.W.: Dual-stream multiple instance learning network for whole slide image classification with self-supervised contrastive learning. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14318–14328 (2021)
2021
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lin, S., Xie, H., Wang, B., Yu, K., Chang, X., Liang, X., Wang, G.: Knowledge distillation via the target-aware transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10915–10924 (2022)
2022
-
[13]
Nature Medicine30(3), 863–874 (2024)
Lu, M.Y., Chen, B., Williamson, D.F., Chen, R.J., Liang, I., Ding, T., Jaume, G., Odintsov, I., Le, L.P., Gerber, G., et al.: A visual-language foundation model for computational pathology. Nature Medicine30(3), 863–874 (2024)
2024
-
[14]
Nature biomedical engineering5(6), 555–570 (2021)
Lu, M.Y., Williamson, D.F., Chen, T.Y., Chen, R.J., Barbieri, M., Mahmood, F.: Data-efficient and weakly supervised computational pathology on whole-slide images. Nature biomedical engineering5(6), 555–570 (2021)
2021
-
[15]
Advances in neural information processing systems34, 2136–2147 (2021)
Shao, Z., Bian, H., Chen, Y., Wang, Y., Zhang, J., Ji, X., et al.: Transmil: Trans- former based correlated multiple instance learning for whole slide image classifica- tion. Advances in neural information processing systems34, 2136–2147 (2021)
2021
-
[16]
In: European Conference on Computer Vision
Thandiackal, K., Chen, B., Pati, P., Jaume, G., Williamson, D.F., Gabrani, M., Goksel, O.: Differentiable zooming for multiple instance learning on whole-slide im- ages. In: European Conference on Computer Vision. pp. 699–715. Springer (2022)
2022
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Z., Li, Z., Zeng, A., Li, Z., Yuan, C., Li, Y.: Vitkd: Feature-based knowledge distillation for vision transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1379–1388 (2024)
2024
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang, Z., Zeng, A., Li, Z., Zhang, T., Yuan, C., Li, Y.: From knowledge distillation to self-knowledge distillation: A unified approach with normalized loss and cus- tomized soft labels. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17185–17194 (2023)
2023
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, H., Meng, Y., Zhao, Y., Qiao, Y., Yang, X., Coupland, S.E., Zheng, Y.: Dtfd-mil: Double-tier feature distillation multiple instance learning for histopathol- ogy whole slide image classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18802–18812 (2022)
2022
-
[20]
Virchow2: Scaling self- supervised mixed magnification models in pathology
Zimmermann, E., Vorontsov, E., Viret, J., Casson, A., Zelechowski, M., Shaikovski, G., Tenenholtz, N., Hall, J., Klimstra, D., Yousfi, R., et al.: Virchow2: Scal- ing self-supervised mixed magnification models in pathology. arXiv preprint arXiv:2408.00738 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.