Lighting-Aware Representation Learning under Controllable Lighting Variation
Pith reviewed 2026-06-27 22:45 UTC · model grok-4.3
The pith
Incorporating lighting variation as an explicit training signal improves contrastive representations for classification and detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adding an auxiliary objective that captures illumination-dependent variation in rendered scenes, contrastive learning produces representations that preserve semantic consistency while remaining sensitive to lighting-dependent visual structure, yielding improved downstream performance on classification and detection without changes to architecture or training cost.
What carries the argument
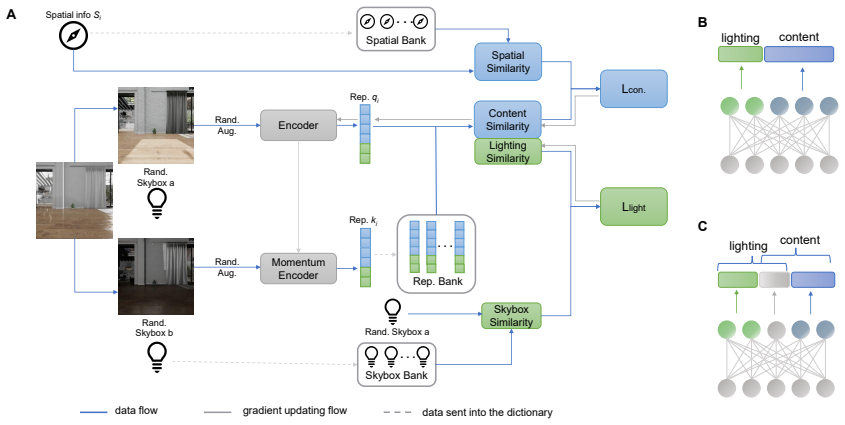
An auxiliary objective added to contrastive learning that captures illumination-dependent variation in rendered scenes as an explicit training signal.
If this is right
- Downstream image classification accuracy rises on benchmarks that include lighting variation.
- Object detection performance improves on datasets like PASCAL VOC and ExDark.
- The same training method produces gains in both self-supervised and supervised regimes.
- Benefits appear even when lighting variation is simpler than the full controllable setup.
Where Pith is reading between the lines
- The learned representations may support downstream tasks that require explicit lighting reasoning, such as relighting or material estimation.
- Similar auxiliary objectives could be designed for other appearance factors like viewpoint or weather to reduce reliance on invariance alone.
- In deployment settings with uncontrolled lighting, the method may reduce the need for heavy data augmentation pipelines.
Load-bearing premise
That the auxiliary objective can capture lighting variation in a way that helps rather than interferes with learning semantic consistency.
What would settle it
Running the lighting-aware model and a standard contrastive baseline on ImageNet classification with identical architecture and training budget and finding no accuracy gain or a loss for the lighting-aware version.
Figures




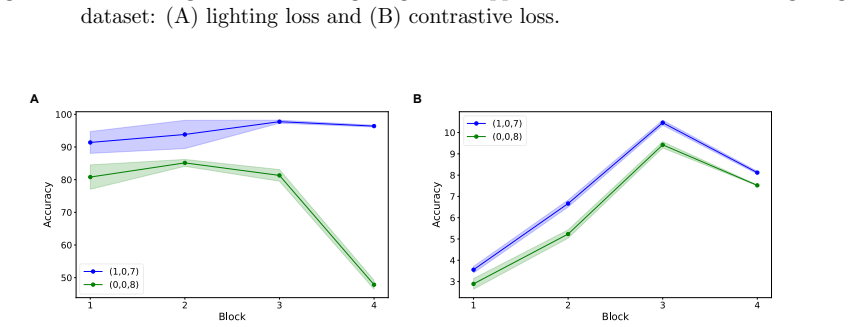
read the original abstract
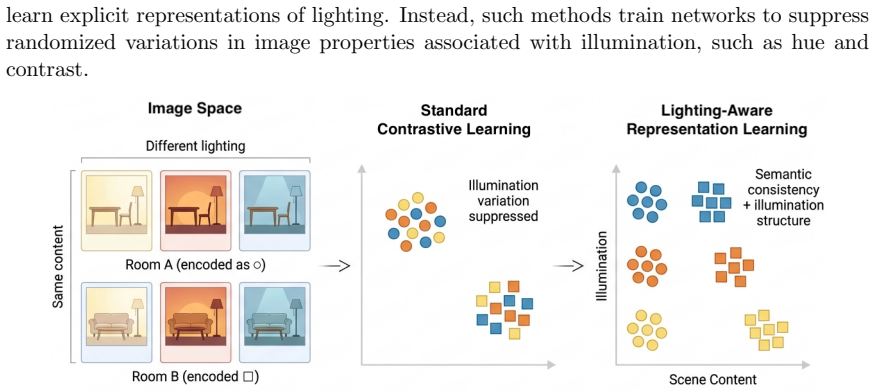
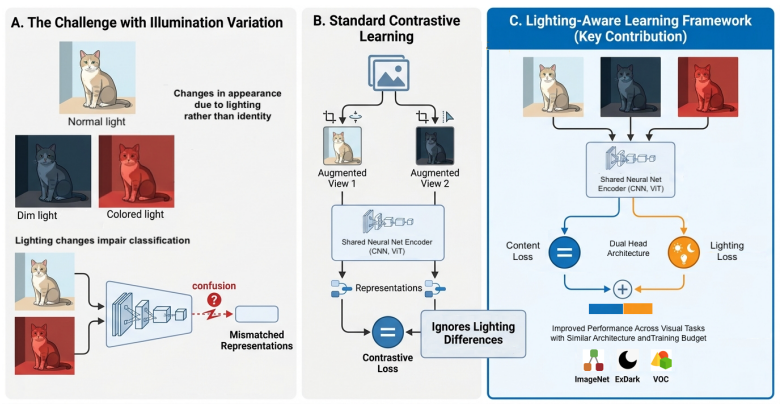
Variations in illumination remain a major challenge for visual representation learning, as they induce substantial appearance changes both across and within environments. While existing approaches typically address this issue through data augmentations that encourage models to become invariant to lighting changes, such strategies do not explicitly model lighting information during learning. Inspired by theories of human vision, we propose a lighting-aware representation learning framework that incorporates illumination variation as an explicit training signal rather than a nuisance factor to be suppressed. Our method extends contrastive learning by introducing an auxiliary objective that captures illumination-dependent variation in rendered scenes, enabling the model to jointly learn representations that preserve semantic consistency while remaining sensitive to lighting-dependent visual structure. We evaluate the proposed model on image classification and object detection tasks across the ImageNet, ExDark, and PASCAL VOC benchmarks. Results demonstrate that the proposed lighting-aware training consistently improves downstream performance over standard contrastive learning baselines, while maintaining the same architecture and training budget. Furthermore, our approach shows promising performance in supervised learning frameworks and under settings involving simpler lighting variation, suggesting broad applicability beyond complex illumination scenarios. These results indicate its potential to enhance model robustness and adaptability in complex visual environments as well as in more conventional image processing tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a lighting-aware representation learning framework that extends standard contrastive learning by adding an auxiliary objective to explicitly capture illumination-dependent variation in rendered scenes. This enables joint learning of semantically consistent representations that remain sensitive to lighting structure, rather than enforcing invariance. The approach is evaluated on image classification and object detection using ImageNet, ExDark, and PASCAL VOC, with claims of consistent downstream gains over contrastive baselines at fixed architecture and training budget; additional results are reported for supervised settings and simpler lighting variations.
Significance. If the empirical gains are robust and reproducible, the work could meaningfully shift representation learning paradigms away from pure invariance toward explicit factor modeling, with potential benefits for robustness in real-world illumination changes. Maintaining identical compute budgets strengthens the practical case. The explicit tie to human vision theories provides a coherent motivation, though the magnitude of gains and generality remain to be verified from the full results.
major comments (1)
- [Abstract] Abstract: the central claim of 'consistent improvements' over contrastive baselines is asserted without any quantitative metrics, error bars, statistical tests, or implementation details of the auxiliary objective, so the data cannot be verified to support the claim as stated.
minor comments (2)
- The description of the auxiliary objective would benefit from an explicit equation or pseudocode to clarify how illumination-dependent variation is encoded and combined with the contrastive loss.
- Provide implementation details (e.g., how rendered scenes are generated, choice of lighting parameters) to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and the recommendation for minor revision. We address the point on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent improvements' over contrastive baselines is asserted without any quantitative metrics, error bars, statistical tests, or implementation details of the auxiliary objective, so the data cannot be verified to support the claim as stated.
Authors: We agree that the abstract would benefit from quantitative support for the claim of consistent improvements. In the revised manuscript we will incorporate specific performance deltas (drawn from the experimental tables) into the abstract, e.g., average top-1 accuracy gains on ImageNet and mAP gains on PASCAL VOC. Implementation details of the auxiliary objective are already fully specified in Section 3; we will add a one-sentence pointer in the abstract if space permits. Error bars and run statistics appear in the results tables and will be referenced at a high level in the revised abstract. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an empirical extension to contrastive learning via an auxiliary objective on illumination variation in rendered scenes, evaluated on ImageNet, ExDark, and PASCAL VOC. The central claim of consistent downstream gains at fixed architecture and budget is supported by direct experimental comparison rather than any derivation chain. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided abstract or method description. The construction (contrastive loss plus explicit lighting signal) is independent of the reported outcomes and does not reduce to its inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FirstName LastName , title =
-
[2]
FirstName Alpher , title =
-
[3]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[4]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[5]
FirstName Alpher and FirstName Gamow , title =
-
[6]
Journal of Electronic Imaging , volume=
Toward a digital camera to rival the human eye , author=. Journal of Electronic Imaging , volume=. 2011 , publisher=
2011
-
[7]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume=
Sensory, computational and cognitive components of human colour constancy , author=. Philosophical Transactions of the Royal Society B: Biological Sciences , volume=. 2005 , publisher=
2005
-
[8]
Improving Deep Learning with Generic Data Augmentation , year=
Taylor, Luke and Nitschke, Geoff , booktitle=. Improving Deep Learning with Generic Data Augmentation , year=
-
[9]
arXiv preprint arXiv:2404.07514 , year=
Generalization Gap in Data Augmentation: Insights from Illumination , author=. arXiv preprint arXiv:2404.07514 , year=
-
[10]
Journal of Big Data , volume=
A survey on image data augmentation for deep learning , author=. Journal of Big Data , volume=. 2019 , publisher=
2019
-
[11]
Patterns , volume=
Incorporating simulated spatial context information improves the effectiveness of contrastive learning models , author=. Patterns , volume=. 2024 , publisher=
2024
-
[12]
Computer Vision and Image Understanding , volume =
Getting to Know Low-light Images with The Exclusively Dark Dataset , author =. Computer Vision and Image Understanding , volume =. 2019 , OPTdoi =
2019
-
[13]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[14]
arXiv preprint arXiv:2007.04954 , year=
Threedworld: A platform for interactive multi-modal physical simulation , author=. arXiv preprint arXiv:2007.04954 , year=
-
[15]
Improved Baselines with Momentum Contrastive Learning
Improved baselines with momentum contrastive learning , author=. arXiv preprint arXiv:2003.04297 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[16]
and Van Gool, L
Everingham, M. and Van Gool, L. and Williams, C. K. I. and Winn, J. and Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. International Journal of Computer Vision. 2010
2010
-
[17]
Advances in Neural Information Processing Systems , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR) , pages=
Large-scale object detection of images from network cameras in variable ambient lighting conditions , author=. 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR) , pages=. 2019 , organization=
2019
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[22]
International Journal of Computer Sciences and Engineering , volume=
Deep learning algorithms and applications in computer vision , author=. International Journal of Computer Sciences and Engineering , volume=
-
[23]
Physics of Life Reviews , volume=
Perceptual learning and human expertise , author=. Physics of Life Reviews , volume=. 2009 , publisher=
2009
-
[24]
Science , volume=
Statistical learning by 8-month-old infants , author=. Science , volume=. 1996 , publisher=
1996
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[26]
Proceedings of the International Conference on Machine Learning , pages=
A simple framework for contrastive learning of visual representations , author=. Proceedings of the International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[27]
Science , volume=
Unsupervised natural experience rapidly alters invariant object representation in visual cortex , author=. Science , volume=. 2008 , publisher=
2008
-
[28]
Cognitive Science , volume=
The development of invariant object recognition requires visual experience with temporally smooth objects , author=. Cognitive Science , volume=. 2018 , publisher=
2018
-
[29]
arXiv preprint arXiv:2202.08114 , year=
Using Navigational Information to Learn Visual Representations , author=. arXiv preprint arXiv:2202.08114 , year=
-
[30]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Advances in Neural Information Processing Systems , volume=
Bootstrap your own latent-a new approach to self-supervised learning , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Exploring simple siamese representation learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Contrastive learning with stronger augmentations , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
2022
-
[34]
Zheng, Mingkai and You, Shan and Wang, Fei and Qian, Chen and Zhang, Changshui and Wang, Xiaogang and Xu, Chang , journal=
-
[35]
Proceedings of the 26th annual International Conference on Machine Learning , pages=
Curriculum learning , author=. Proceedings of the 26th annual International Conference on Machine Learning , pages=
-
[36]
Chu, Guanyi and Wang, Xiao and Shi, Chuan and JHouse100Kiang, Xunqiang , booktitle=
-
[37]
Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
Contrastive curriculum learning for sequential user behavior modeling via data augmentation , author=. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
-
[38]
Advances in Neural Information Processing Systems , volume=
Curriculum learning with infant egocentric videos , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
2021 , publisher=
Sullivan, Jessica and Mei, Michelle and Perfors, Andrew and Wojcik, Erica and Frank, Michael C , journal=. 2021 , publisher=
2021
-
[40]
Handbook of Child Psychology , volume=
Infant visual perception , author=. Handbook of Child Psychology , volume=. 2007 , publisher=
2007
-
[41]
Behavioral and Brain Sciences , volume=
Deictic codes for the embodiment of cognition , author=. Behavioral and Brain Sciences , volume=. 1997 , publisher=
1997
-
[42]
Developmental Review , volume=
Cognition as a dynamic system: Principles from embodiment , author=. Developmental Review , volume=. 2005 , publisher=
2005
-
[43]
Infancy , volume=
Travel broadens the mind , author=. Infancy , volume=. 2000 , publisher=
2000
-
[44]
Artificial Life , volume=
The development of embodied cognition: Six lessons from babies , author=. Artificial Life , volume=. 2005 , publisher=
2005
-
[45]
, author=
Development of reaching during the first year: role of movement speed. , author=. Journal of Experimental Psychology: Human perception and performance , volume=. 1996 , publisher=
1996
-
[46]
Overview: Motor Actions and Psychological Function , editor =
Motor Development: How Infants Get Into the Act , author =. Overview: Motor Actions and Psychological Function , editor =. 2006 , publisher =
2006
-
[47]
1994 , publisher=
A Dynamic Systems Approach to the Development of Cognition and Action , author=. 1994 , publisher=
1994
-
[48]
Handbook of Child Psychology: Vol
Motor development , author =. Handbook of Child Psychology: Vol. 2. Cognition, Perception, and Language , editor =. 2006 , publisher =
2006
-
[49]
2000 , publisher=
The Cradle of Knowledge: Development of perception in infancy , author=. 2000 , publisher=
2000
-
[50]
Proceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques , pages=
Animating rotation with quaternion curves , author=. Proceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques , pages=
-
[51]
Advances in Neural Information Processing Systems , volume=
Stochastic neighbor embedding , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
2009 , organization=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li , booktitle=. 2009 , organization=
2009
-
[53]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Places: A 10 million Image Database for Scene Recognition , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[54]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[55]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[56]
, title =
Robinson, Arthur L. , title =. 1980 , OPTdoi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[57]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[58]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =
1984
-
[59]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[60]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[61]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[62]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[63]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[64]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[65]
Medical Image Analysis , volume=
CDDSA: Contrastive domain disentanglement and style augmentation for generalizable medical image segmentation , author=. Medical Image Analysis , volume=. 2023 , publisher=
2023
-
[66]
International Conference on Database Systems for Advanced Applications , pages=
Disentangled contrastive learning for cross-domain recommendation , author=. International Conference on Database Systems for Advanced Applications , pages=. 2023 , organization=
2023
-
[67]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Disentangled contrastive collaborative filtering , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[68]
Advances in Neural Information Processing Systems , volume=
Disentangled contrastive learning on graphs , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
2025 , issn =
Disentangled contrastive learning for fair graph representations , journal =. 2025 , issn =
2025
-
[70]
Advances in Neural Information Processing Systems , volume=
Learning structured output representation using deep conditional generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
, author=
beta-vae: Learning basic visual concepts with a constrained variational framework. , author=. ICLR (Poster) , volume=
-
[72]
Duan, Yitong and Wang, Lei and Zhang, Qizhong and Li, Jian , booktitle=
-
[73]
International conference on machine learning , pages=
Disentangling by factorising , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[74]
International Conference on Learning Representations , year=
Variational Inference of Disentangled Latent Concepts from Unlabeled Observations , author=. International Conference on Learning Representations , year=
-
[75]
Medical Image Analysis , volume=
A disentangled generative model for disease decomposition in chest x-rays via normal image synthesis , author=. Medical Image Analysis , volume=. 2021 , publisher=
2021
-
[76]
IEEE Transactions on Radiation and Plasma Medical Sciences , volume=
Low-dimensional manifold-constrained disentanglement network for metal artifact reduction , author=. IEEE Transactions on Radiation and Plasma Medical Sciences , volume=. 2021 , publisher=
2021
-
[77]
Advances in Neural Information Processing Systems , volume=
Learning disentangled representations for recommendation , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
ACM Transactions on Information Systems , volume=
Disentangled representations learning for multi-target cross-domain recommendation , author=. ACM Transactions on Information Systems , volume=. 2023 , publisher=
2023
-
[79]
and Rahman, Z
Jobson, D.J. and Rahman, Z. and Woodell, G.A. , journal=. A multiscale retinex for bridging the gap between color images and the human observation of scenes , year=
-
[80]
An automated multi Scale Retinex with Color Restoration for image enhancement , year=
Parthasarathy, Sudharsan and Sankaran, Praveen , booktitle=. An automated multi Scale Retinex with Color Restoration for image enhancement , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.