From Vision to Text: A Compact Multimodal Approach for Robust, Cross-Domain Presentation Attack Detection on ID Cards
Pith reviewed 2026-06-27 22:14 UTC · model grok-4.3
The pith
Multimodal models for ID card presentation attack detection generalize after fine-tuning but fail zero-shot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
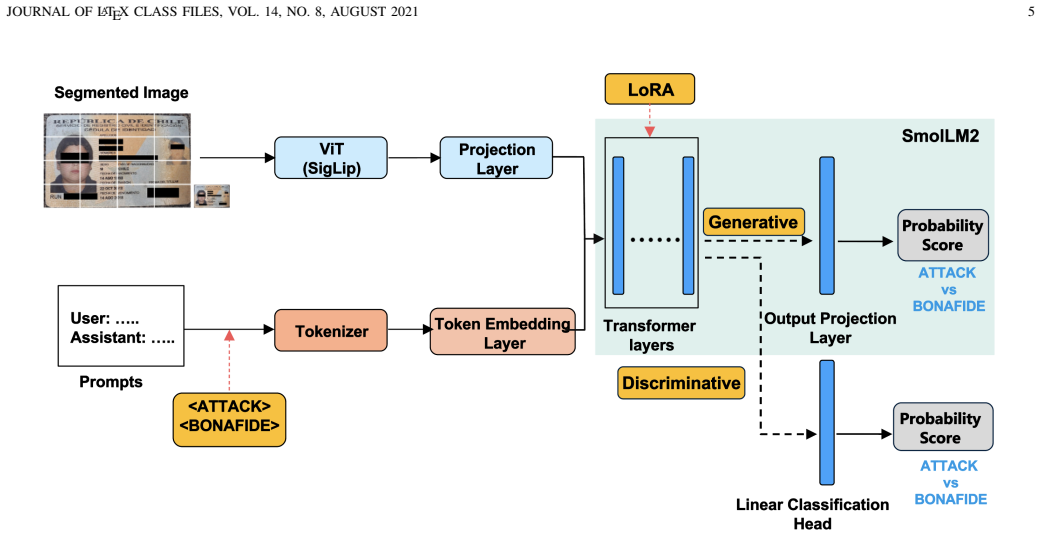
A compact multimodal model using generative and discriminative blocks to combine visual and textual data for presentation attack detection on genuine and synthetic ID images achieves strong cross-domain generalization after supervised fine-tuning but fails in zero-shot settings, showing that model capacity and real-world data are essential while synthetic datasets may not reflect real-world challenges.
What carries the argument
Compact multimodal model with generative and discriminative blocks that fuse visual and textual data for PAD on ID cards.
If this is right
- Supervised fine-tuning allows multimodal PAD models to generalize across domains for ID card attacks.
- The same models exhibit unreliable performance when applied without any task-specific training.
- Larger model capacity improves the reliability of PAD results.
- Current synthetic datasets do not capture the difficulties of real PAD scenarios.
- Advancing the field requires more realistic and diverse real-world datasets.
Where Pith is reading between the lines
- Scaling model size further could reduce dependence on large amounts of labeled real data for zero-shot transfer.
- Testing the same fusion blocks on other biometric modalities might reveal whether the approach generalizes beyond ID cards.
- Creating improved synthetic data generators that better mimic real capture conditions could serve as an interim solution until larger real datasets become available.
Load-bearing premise
The generative and discriminative blocks produce an effective fusion of visual and textual data that delivers cross-domain robustness.
What would settle it
A direct comparison in which the multimodal model with the new blocks shows no measurable gain over simple unimodal baselines on held-out real cross-domain ID card data would falsify the claimed benefit of the fusion mechanism.
Figures


read the original abstract
Cross-domain shifts challenge Presentation Attack Detection (PAD) on ID Cards, given the restricted data available due to privacy concerns. This work proposes a compact multimodal model, based on new generative and discriminative blocks, which combines visual and textual data for PAD on genuine and synthetic ID images. While multimodal models exhibit strong generalisation after supervised fine-tuning, they fail in zero-shot settings. Our findings underscore that model capacity and real-world data are essential for reliable PAD, while existing synthetic datasets may not reflect real-world challenges. We argue for a re-evaluation of synthetic data as a benchmark and emphasise the need for more realistic, diverse datasets to advance PAD research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a compact multimodal architecture for presentation attack detection (PAD) on ID cards that fuses visual and textual features via novel generative and discriminative blocks. It reports that the model generalizes well across domains after supervised fine-tuning but fails in zero-shot settings, concluding that model capacity and real-world data are essential while existing synthetic datasets are inadequate for benchmarking.
Significance. If the empirical findings hold under broader validation, the work would usefully highlight limitations of synthetic data for cross-domain PAD and the practical value of multimodal fusion under supervised regimes. The emphasis on real-world data needs is timely given privacy constraints in ID document datasets.
major comments (2)
- [Abstract, §3] Abstract and §3 (model description): The central claim that 'multimodal models exhibit strong generalisation after supervised fine-tuning' while failing zero-shot is framed as a property of the multimodal paradigm, yet the experiments appear limited to a single custom architecture with the proposed generative and discriminative blocks. This prevents attribution of the observed pattern to multimodal models in general rather than to the specific fusion design, capacity, or training recipe.
- [Abstract] Abstract: The statement that 'existing synthetic datasets may not reflect real-world challenges' is load-bearing for the recommendation to re-evaluate synthetic benchmarks, but no quantitative comparison (e.g., domain-shift metrics or cross-dataset performance tables) is referenced in the provided abstract to support the claim.
minor comments (1)
- [Abstract] Abstract lacks any mention of datasets, metrics, or experimental protocol, making it impossible to assess the strength of the reported generalization results from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which help us clarify the scope of our claims and strengthen the presentation of our findings. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (model description): The central claim that 'multimodal models exhibit strong generalisation after supervised fine-tuning' while failing zero-shot is framed as a property of the multimodal paradigm, yet the experiments appear limited to a single custom architecture with the proposed generative and discriminative blocks. This prevents attribution of the observed pattern to multimodal models in general rather than to the specific fusion design, capacity, or training recipe.
Authors: We acknowledge that our experiments are performed using the proposed compact multimodal architecture with the novel generative and discriminative blocks. The observed generalization after fine-tuning and failure in zero-shot are specific to this model and training setup. We will revise the abstract and §3 to replace the general phrasing 'multimodal models' with 'our multimodal model' to accurately reflect the scope of the results. Additionally, we will include a discussion note suggesting that future work could validate these patterns across a wider range of multimodal architectures. revision: yes
-
Referee: [Abstract] Abstract: The statement that 'existing synthetic datasets may not reflect real-world challenges' is load-bearing for the recommendation to re-evaluate synthetic benchmarks, but no quantitative comparison (e.g., domain-shift metrics or cross-dataset performance tables) is referenced in the provided abstract to support the claim.
Authors: The abstract is a concise summary, with the supporting quantitative results (cross-domain performance after fine-tuning versus zero-shot) presented in the main body of the paper. To address the concern, we will revise the abstract to briefly reference the key empirical observations, such as the performance differences that indicate limitations of synthetic data, thereby making the claim more directly supported within the abstract itself. revision: yes
Circularity Check
No circularity: empirical model evaluation with no derivations or self-referential claims
full rationale
The paper proposes a compact multimodal architecture for cross-domain PAD and reports experimental results on generalization after fine-tuning versus zero-shot failure. No equations, derivations, or first-principles claims appear in the abstract or described content. The central findings rest on supervised training and testing of the introduced model rather than any reduction of predictions to fitted inputs or self-citation chains. The architecture is presented as novel (generative and discriminative blocks), with performance claims tied directly to its implementation and data, without renaming known results or smuggling ansatzes via prior self-citations. This is a standard empirical CV contribution whose validity can be assessed against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Foundation models defining a new era in vision: A survey and outlook,
M. Awais, M. Naseer, S. Khan, R. M. Anwer, H. Cholakkal, M. Shah, M.-H. Yang, and F. S. Khan, “Foundation models defining a new era in vision: A survey and outlook,”IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 2245–2264, 2025
2025
-
[2]
Can foundation models generalise the presentation attack detection capabilities on id cards?
J. E. Tapia and C. Busch, “Can foundation models generalise the presentation attack detection capabilities on id cards?” 2025. [Online]. Available: https://arxiv.org/abs/2506.05263
arXiv 2025
-
[3]
Explainability and vision foundation models: A survey,
R. Kazmierczak, E. Berthier, G. Frehse, and G. Franchi, “Explainability and vision foundation models: A survey,”Information Fusion, vol. 122, p. 103184, 2025. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S156625352500257X
2025
-
[4]
Identity card presentation attack detection: A systematic review,
E. M. Ruiz, J. E. Tapia, R. T. Soto, and C. Busch, “Identity card presentation attack detection: A systematic review,” 2025. [Online]. Available: https://arxiv.org/abs/2511.06056
arXiv 2025
-
[5]
Forged presentation attack detection for ID cards on remote verification systems,
S. Gonzalez and J. E. Tapia, “Forged presentation attack detection for ID cards on remote verification systems,”Pattern Recognition, vol. 162, p. 111352, Jun. 2025. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0031320325000123
2025
-
[6]
Hybrid Two-Stage Architecture for Tampering Detection of Chipless ID Cards,
S. Gonzalez, A. Valenzuela, and J. Tapia, “Hybrid Two-Stage Architecture for Tampering Detection of Chipless ID Cards,”Trans. on Biometrics, Behavior, and Identity Science, vol. 3, no. 1, pp. 89–100, Jan
-
[7]
Available: https://ieeexplore.ieee.org/document/9197632
[Online]. Available: https://ieeexplore.ieee.org/document/9197632
-
[8]
Open-Set: ID Card Presentation Attack Detection Using Neural Style Transfer,
R. P. Markham, J. M. E. L ´opez, M. Nieto-Hidalgo, and J. E. Tapia, “Open-Set: ID Card Presentation Attack Detection Using Neural Style Transfer,”IEEE Access, vol. 12, pp. 68 573–68 585, 2024. [Online]. Available: https://ieeexplore.ieee.org/document/10520890
arXiv 2024
-
[9]
Image-to-image translation with conditional adversarial networks,
P. Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,”CVPR, 2017
2017
-
[10]
Synthetic ID Card Image Generation for Improving Presentation Attack Detection,
D. Benalcazar, J. E. Tapia, S. Gonzalez, and C. Busch, “Synthetic ID Card Image Generation for Improving Presentation Attack Detection,” Trans. on Information Forensics and Security, vol. 18, pp. 1814–1824,
-
[11]
Available: https://ieeexplore.ieee.org/abstract/document/ 10065533
[Online]. Available: https://ieeexplore.ieee.org/abstract/document/ 10065533
-
[12]
Idnet: A novel identity document dataset via few-shot and quality-driven synthetic data generation,
L. Xie, Y . Wang, H. Guan, S. Nag, R. Goel, N. Swamy, Y . Yang, C. Xiao, J. Prisby, R. Maciejewski, and J. Zou, “Idnet: A novel identity document dataset via few-shot and quality-driven synthetic data generation,” inIntl. Conf. on Big Data (BigData), 2024, pp. 2244–2253
2024
-
[13]
Fan- tasyID: A dataset for detecting digital manipulations in ID-documents,
P. Korshunov, A. Mohammadi, Vidit, C. Ecabert, and S. Marcel, “Fan- tasyID: A dataset for detecting digital manipulations in ID-documents,” inIEEE Intl. Joint Conf. on Biometrics (IJCB), 2025, pp. 1–9
2025
-
[14]
First competition on presentation attack detection on ID card,
J. E. Tapia, N. Damer, C. Busch, J. M. Espin, J. Barrachina, A. S. Rocamora, K. Ocvirk, L. Alessio, B. Batagelj, S. Patwardhan, R. Ra- machandra, R. Mudgalgundurao, K. Raja, D. Schulz, and C. Aravena, “First competition on presentation attack detection on ID card,” inIntl. Joint Conf. on Biometrics (IJCB), 2024, pp. 1–10
2024
-
[15]
Second competition on presentation attack detection on ID card,
J. E. Tapia, M. Nieto, J. M. Espin, A. S. Rocamora, J. Barrachina, N. Damer, C. Busch, M. Ivanovska, L. Todorov, R. Khizbullin, L. Lazarevich, A. Grishin, D. Schulz, S. Gonzalez, A. Mohammadi, K. Kotwal, S. Marcel, R. Mudgalgundurao, K. Raja, P. Schuch, S. Pat- wardhan, R. Ramachandra, P. Couto Pereira, J. R. Pinto, M. Xavier, A. Valenzuela, R. Lara, B. B...
2025
-
[16]
Contrastive localized language-image pre-training,
H.-Y . Chen, Z. Lai, H. Zhang, X. Wang, M. Eichner, K. You, M. Cao, B. Zhang, Y . Yang, and Z. Gan, “Contrastive localized language-image pre-training,” inForty-second Intl. Conf.on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=sGQEOXlezg
2025
-
[17]
DINOv2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “DINOv2: Learning robust visual features without ...
2024
-
[18]
Fakeidet: Exploring patches for privacy-preserving fake id detection,
J. Mu ˜noz-Haro, R. Tolosana, R. Vera-Rodriguez, A. Morales, and J. Fierrez, “Fakeidet: Exploring patches for privacy-preserving fake id detection,” inIEEE Intl. Joint Conf. on Biometrics (IJCB), 2025, pp. 1–9
2025
-
[19]
Syn- idpass: Passport synthetic dataset for presentation attack detection,
J. E. Tapia, F. Stockhardt, L. J. Gonz ´alez-Soler, and C. Busch, “Syn- idpass: Passport synthetic dataset for presentation attack detection,” in IEEE Intl. Joint Conf. on Biometrics (IJCB), 2025, pp. 1–9
2025
-
[20]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2017, pp. 4700–4708
2017
-
[21]
Pixel-wise supervision for presentation attack detection on identity document cards,
R. Mudgalgundurao, P. Schuch, K. Raja, R. Ramachandra, and N. Damer, “Pixel-wise supervision for presentation attack detection on identity document cards,”IET biometrics, vol. 11, no. 5, pp. 383–395, 2022
2022
-
[22]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[23]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inProceedings of the IEEE/CVF Intl. Conf. on computer vision, 2023, pp. 11 975–11 986
2023
-
[24]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[25]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[26]
Gaussian error linear units (gelus),
D. Hendrycks, “Gaussian error linear units (gelus),”arXiv preprint arXiv:1606.08415, 2016
Pith/arXiv arXiv 2016
-
[27]
Smolvlm: Redefining small and efficient multimodal models,
A. Marafioti, O. Zohar, M. Farr ´e, M. Noyan, E. Bakouch, P. Cuenca, C. Zakka, L. B. Allal, A. Lozhkov, N. Taziet al., “Smolvlm: Redefining small and efficient multimodal models,”arXiv preprint arXiv:2504.05299, 2025
Pith/arXiv arXiv 2025
-
[28]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[29]
Sgdr: Stochastic gradient descent with warm restarts,
——, “Sgdr: Stochastic gradient descent with warm restarts,”arXiv preprint arXiv:1608.03983, 2016
Pith/arXiv arXiv 2016
-
[30]
Why warmup the learning rate? under- lying mechanisms and improvements,
D. S. Kalra and M. Barkeshli, “Why warmup the learning rate? under- lying mechanisms and improvements,”Advances in Neural Information Processing Systems, vol. 37, pp. 111 760–111 801, 2024
2024
-
[31]
Optuna: A next- generation hyperparameter optimization framework,
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama, “Optuna: A next- generation hyperparameter optimization framework,” inProceedings of the 25th ACM SIGKDD intl. conf. on knowledge discovery & data mining, 2019, pp. 2623–2631
2019
-
[32]
C. M. Bishop and N. M. Nasrabadi,Pattern recognition and machine learning. Springer, 2006, vol. 4, no. 4
2006
-
[33]
Feature selection, l 1 vs. l 2 regularization, and rotational invariance,
A. Y . Ng, “Feature selection, l 1 vs. l 2 regularization, and rotational invariance,” inProceedings of the twenty-first intl. conf. on Machine learning, 2004, p. 78
2004
-
[34]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 Qingweng Zengreceived a B.Sc. degree in Data Science from the Institute of Disaster Prevention, China, in 2023. He is pursu...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.