SigmaScale: LLM Compression with SVD-based Low-Rank Decomposition and Learned Scaling Matrices
Pith reviewed 2026-06-27 22:02 UTC · model grok-4.3
The pith
Learned diagonal scaling matrices lower the effective intrinsic rank of LLM weights during SVD truncation and correlate with reduced compression loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
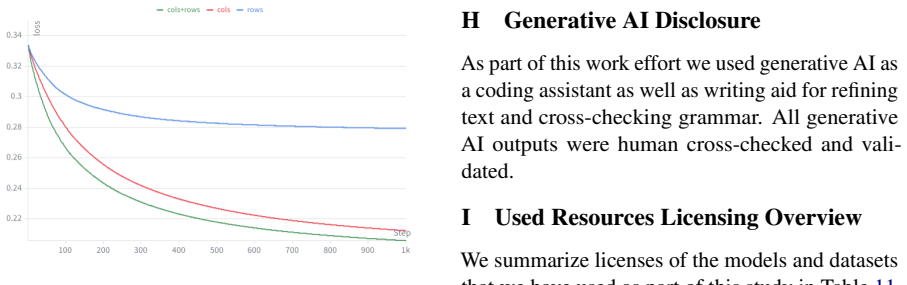
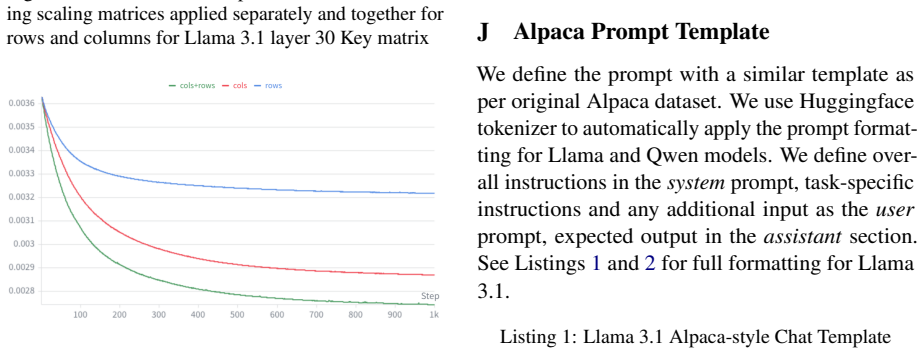
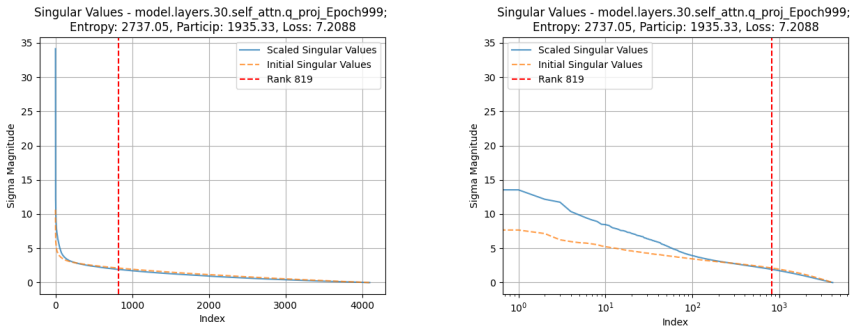
SigmaScale learns auxiliary scaling matrices S by optimizing vectors that define diagonal row and column transformations under an activation-aware compression loss. This learned scaling lowers the effective intrinsic rank of weight matrices, visible as drops in effective-rank entropy, and the entropy reduction is strongly correlated with compression loss. The method matches closely related state-of-the-art SVD compression techniques on perplexity and zero-shot benchmarks for 8B-scale models.
What carries the argument
Learned diagonal row and column scaling vectors optimized under activation-aware loss to precondition weight matrices for truncated SVD.
If this is right
- Effective-rank entropy drops when learned scalings are used instead of analytical ones.
- The size of the entropy drop tracks the size of the compression-loss improvement.
- Performance on perplexity and zero-shot tasks stays within range of prior SVD methods for Llama 3.1 8B Instruct and Qwen3-8B.
- The method adapts transformations to the structure of individual model weights rather than using a fixed rule.
- Inference cost is reduced when the low-rank factors replace the original weights.
Where Pith is reading between the lines
- The same learned-scaling idea could be tested as a plug-in step before other low-rank or pruning compressors.
- If the entropy-loss correlation holds across model families, it supplies a cheap diagnostic for whether a scaling step is worth running.
- Activation-aware optimization may capture layer-specific activation statistics that static scaling rules miss, suggesting a route to task-targeted compression.
- Checking whether the added scaling matrices increase memory bandwidth at inference time would clarify the net compute saving.
Load-bearing premise
Scaling vectors found by optimizing the activation-aware loss on training data continue to work on new inputs without adding inference cost or instability that cancels the compression benefit.
What would settle it
Measure whether effective-rank entropy still drops and whether compression loss still improves when the same scaling vectors are applied to a held-out set of activations never seen during optimization.
Figures


read the original abstract
We present SigmaScale, a method for learning auxiliary scaling matrices $S$ to aid truncated Singular Value Decomposition (SVD) based Large Language Model (LLM) compression. Instead of deriving scaling matrices analytically, SigmaScale optimizes two sets of vectors that define diagonal row and column scaling transformations under an activation-aware compression loss. We show that learned scaling lowers the effective intrinsic rank of weight matrices, as reflected by reductions in effective-rank entropy, and that this reduction is strongly correlated with compression loss. Experiments on Llama 3.1 8B Instruct and Qwen3-8B show that SigmaScale is competitive with closely related state-of-the-art SVD-based compression methods across perplexity and zero-shot benchmarks. By using learned activation-aware transformations, SigmaScale explores a more flexible route to low-rank LLM compression by adapting to the structure of individual model weights. The advantage observed in specific tasks makes our approach a valid option for applications requiring a reduced LLM-inference computing cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SigmaScale, a technique for compressing LLMs via truncated SVD augmented with learned diagonal scaling matrices. These scalings are obtained by optimizing row and column vectors under an activation-aware compression loss. The authors report that the learned scalings reduce effective-rank entropy of the weight matrices and that this reduction correlates strongly with the compression loss. On Llama 3.1 8B Instruct and Qwen3-8B, the method is competitive with existing SVD-based compressors on perplexity and zero-shot benchmarks.
Significance. Should the empirical claims be substantiated with detailed ablations and robustness checks, the work would contribute a flexible, activation-adaptive approach to low-rank decomposition for LLM compression, potentially improving upon fixed analytical scalings while maintaining inference efficiency.
major comments (2)
- [Abstract] Abstract: the claim that learned scaling lowers effective intrinsic rank (as reflected by reductions in effective-rank entropy) and that this reduction is strongly correlated with compression loss is at risk of circularity, because the scaling vectors are obtained by direct optimization against the same activation-aware compression loss used to evaluate performance.
- [Abstract] Abstract / Experiments: no quantitative effect sizes, ablation details, or controls for activation distribution shift are provided, leaving the central interpretation—that the entropy reductions reflect intrinsic weight-matrix structure rather than properties of the calibration activations—untested and load-bearing for the claim of a more flexible route to low-rank compression.
minor comments (1)
- The abstract states competitiveness on benchmarks but supplies no numerical comparisons, perplexity deltas, or zero-shot accuracies; adding these would improve clarity without altering the core claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below. Both concerns can be mitigated through targeted revisions to the abstract and experiments section, including clarifications and additional analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that learned scaling lowers effective intrinsic rank (as reflected by reductions in effective-rank entropy) and that this reduction is strongly correlated with compression loss is at risk of circularity, because the scaling vectors are obtained by direct optimization against the same activation-aware compression loss used to evaluate performance.
Authors: We appreciate the referee highlighting this potential issue. The scaling vectors are indeed optimized directly against the activation-aware compression loss. However, the effective-rank entropy is computed as a separate, post-hoc diagnostic on the resulting scaled matrices and is not part of the optimization objective itself. The observed correlation demonstrates that minimizing the loss produces matrices with lower entropy, supporting our interpretation of rank reduction. To remove any ambiguity, we will revise the abstract to explicitly distinguish the optimization target from the independent entropy analysis. revision: partial
-
Referee: [Abstract] Abstract / Experiments: no quantitative effect sizes, ablation details, or controls for activation distribution shift are provided, leaving the central interpretation—that the entropy reductions reflect intrinsic weight-matrix structure rather than properties of the calibration activations—untested and load-bearing for the claim of a more flexible route to low-rank compression.
Authors: We agree that the current manuscript lacks these elements and that they are necessary to substantiate the central claim. In the revised version we will report quantitative effect sizes for the entropy reductions, include detailed ablations on the learned scaling matrices (e.g., comparing learned vs. fixed scalings and varying optimization hyperparameters), and add controls that repeat the entropy analysis with multiple distinct calibration sets to test sensitivity to activation distribution shift. These additions will directly test whether the observed benefits arise from adaptation to weight-matrix structure. revision: yes
Circularity Check
Scaling optimization under the compression loss renders the reported entropy-loss correlation partly tautological
specific steps
-
fitted input called prediction
[Abstract]
"We show that learned scaling lowers the effective intrinsic rank of weight matrices, as reflected by reductions in effective-rank entropy, and that this reduction is strongly correlated with compression loss."
The scaling matrices S are obtained by direct optimization under the activation-aware compression loss; the subsequent claim that entropy reductions correlate with compression loss is therefore evaluated on the same fitted quantities that were produced by minimizing that loss, making the reported correlation partly tautological with the optimization procedure.
full rationale
The paper optimizes the scaling vectors directly against the activation-aware compression loss and then reports that the resulting reductions in effective-rank entropy are strongly correlated with that same loss. This correlation is measured on the fitted outputs rather than on an independent test set or out-of-distribution activations, so the observed relationship is at least partly forced by the fitting procedure itself. No other circular steps (self-citation chains, imported uniqueness theorems, or ansatz smuggling) are present in the provided text.
Axiom & Free-Parameter Ledger
free parameters (1)
- row and column scaling vectors
axioms (1)
- domain assumption Activation-aware compression loss is a suitable objective for learning scaling transformations that improve downstream model performance.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
arXiv preprint arXiv:2001.08361 , year=
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
Pith/arXiv arXiv 2001
-
[3]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[4]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[5]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[6]
arXiv preprint arXiv:2108.07258 , year=
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
-
[7]
Frontiers in Robotics and AI , volume=
A survey of model compression techniques: Past, present, and future , author=. Frontiers in Robotics and AI , volume=. 2025 , publisher=
2025
-
[8]
arXiv preprint arXiv:2403.07378 , year=
Svd-llm: Truncation-aware singular value decomposition for large language model compression , author=. arXiv preprint arXiv:2403.07378 , year=
-
[9]
Aghajanyan, Armen and Gupta, Sonal and Zettlemoyer, Luke. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.a...
-
[10]
Linear and Multilinear Algebra , volume=
Literature survey on low rank approximation of matrices , author=. Linear and Multilinear Algebra , volume=. 2017 , publisher=
2017
-
[11]
Numerical Linear Algebra with Applications , volume=
Fast approximate truncated SVD , author=. Numerical Linear Algebra with Applications , volume=. 2019 , publisher=
2019
-
[12]
The quarterly journal of mathematics , volume=
Symmetric gauge functions and unitarily invariant norms , author=. The quarterly journal of mathematics , volume=. 1960 , publisher=
1960
-
[13]
Psychometrika , volume=
The approximation of one matrix by another of lower rank , author=. Psychometrika , volume=. 1936 , publisher=
1936
-
[14]
2023 , eprint=
ASVD: Activation-aware Singular Value Decomposition for Compressing Large Language Models , author=. 2023 , eprint=
2023
-
[15]
IEEE Transactions on Acoustics, Speech, and Signal Processing , volume=
Statistical analysis of effective singular values in matrix rank determination , author=. IEEE Transactions on Acoustics, Speech, and Signal Processing , volume=. 2002 , publisher=
2002
-
[16]
arXiv preprint arXiv:2604.00821 , year=
Optimal Brain Decomposition for Accurate LLM Low-Rank Approximation , author=. arXiv preprint arXiv:2604.00821 , year=
-
[17]
ArXiv , year=
Language model compression with weighted low-rank factorization , author=. ArXiv , year=
-
[18]
Transactions of the Association for Computational Linguistics , volume=
A survey on model compression for large language models , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[19]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[20]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[21]
arXiv preprint arXiv:1503.02531 , year=
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[22]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[23]
Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
-
[24]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[25]
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457v1 , year =
-
[26]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[27]
2016 , eprint=
Pointer Sentinel Mixture Models , author=. 2016 , eprint=
2016
-
[28]
Up or Down?
Nagel, Markus and Amjad, Rana Ali and Van Baalen, Mart and Louizos, Christos and Blankevoort, Tijmen , booktitle =. Up or Down?. 2020 , editor =
2020
-
[29]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[30]
arXiv preprint arXiv:2411.06839 , year=
Llm-neo: Parameter efficient knowledge distillation for large language models , author=. arXiv preprint arXiv:2411.06839 , year=
-
[31]
Yang, Huanrui and Tang, Minxue and Wen, Wei and Yan, Feng and Hu, Daniel and Li, Ang and Li, Hai and Chen, Yiran , month = apr, year =. Learning. doi:10.48550/arXiv.2004.09031 , abstract =
-
[32]
Nagel, Markus and Fournarakis, Marios and Amjad, Rana Ali and Bondarenko, Yelysei and Baalen, Mart van and Blankevoort, Tijmen , month = jun, year =. A. doi:10.48550/arXiv.2106.08295 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.08295
-
[33]
SpinQuant: LLM quantization with learned rotations
Liu, Zechun and Zhao, Changsheng and Fedorov, Igor and Soran, Bilge and Choudhary, Dhruv and Krishnamoorthi, Raghuraman and Chandra, Vikas and Tian, Yuandong and Blankevoort, Tijmen , month = feb, year =. doi:10.48550/arXiv.2405.16406 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.16406
-
[34]
A $(\log n)^{\Omega(1)}$ integrality gap for the Sparsest Cut SDP
Liu, Xiao-Yang and Zhang, Jie and Wang, Guoxuan and Tong, Weiqin and Walid, Anwar , month = jul, year =. Efficient. 2024. doi:10.1109/ICDCS60910.2024.00036 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icdcs60910.2024.00036 2024
-
[35]
Xin, Meng and Priyadarshi, Sweta and Xin, Jingyu and Kartal, Bilal and Vavre, Aditya and Thekkumpate, Asma Kuriparambil and Chen, Zijia and Mahabaleshwarkar, Ameya Sunil and Shahaf, Ido and Bercovich, Akhiad and Patel, Kinjal and Velury, Suguna Varshini and Luo, Chenjie and Cheng, Zhiyu and Chen, Jenny and Yu, Chen-Han and Ping, Wei and Rybakov, Oleg and ...
-
[36]
Ashkboos, Saleh and Mohtashami, Amirkeivan and Croci, Maximilian L. and Li, Bo and Cameron, Pashmina and Jaggi, Martin and Alistarh, Dan and Hoefler, Torsten and Hensman, James , month = oct, year =. doi:10.48550/arXiv.2404.00456 , abstract =
-
[37]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, Elias and Ashkboos, Saleh and Hoefler, Torsten and Alistarh, Dan , month = mar, year =. doi:10.48550/arXiv.2210.17323 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.17323
-
[38]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
Robust. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2022 , note =. doi:10.1109/TPAMI.2021.3072422 , abstract =
-
[39]
Wang, Qinsi and Ke, Jinghan and Tomizuka, Masayoshi and Chen, Yiran and Keutzer, Kurt and Xu, Chenfeng , month = feb, year =. Dobi-. doi:10.48550/arXiv.2502.02723 , abstract =
-
[40]
and Pilanci, Mert , month = nov, year =
Saha, Rajarshi and Sagan, Naomi and Srivastava, Varun and Goldsmith, Andrea J. and Pilanci, Mert , month = nov, year =. Compressing. doi:10.48550/arXiv.2405.18886 , abstract =
-
[41]
A comprehensive review of network pruning based on pruning granularity and pruning time perspectives , volume =. Neurocomputing , author =. 2025 , keywords =. doi:https://doi.org/10.1016/j.neucom.2025.129382 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.