Think Fast: Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
Pith reviewed 2026-06-27 22:07 UTC · model grok-4.3
The pith
Frontier AI models without chain-of-thought reasoning now solve tasks that take humans over three minutes at 50 percent success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
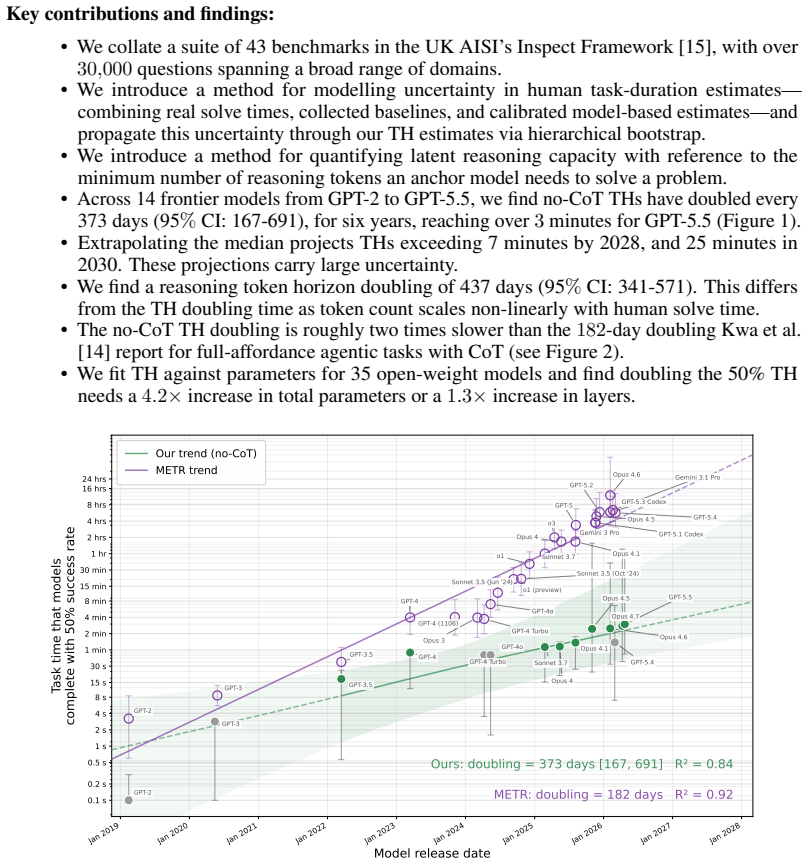
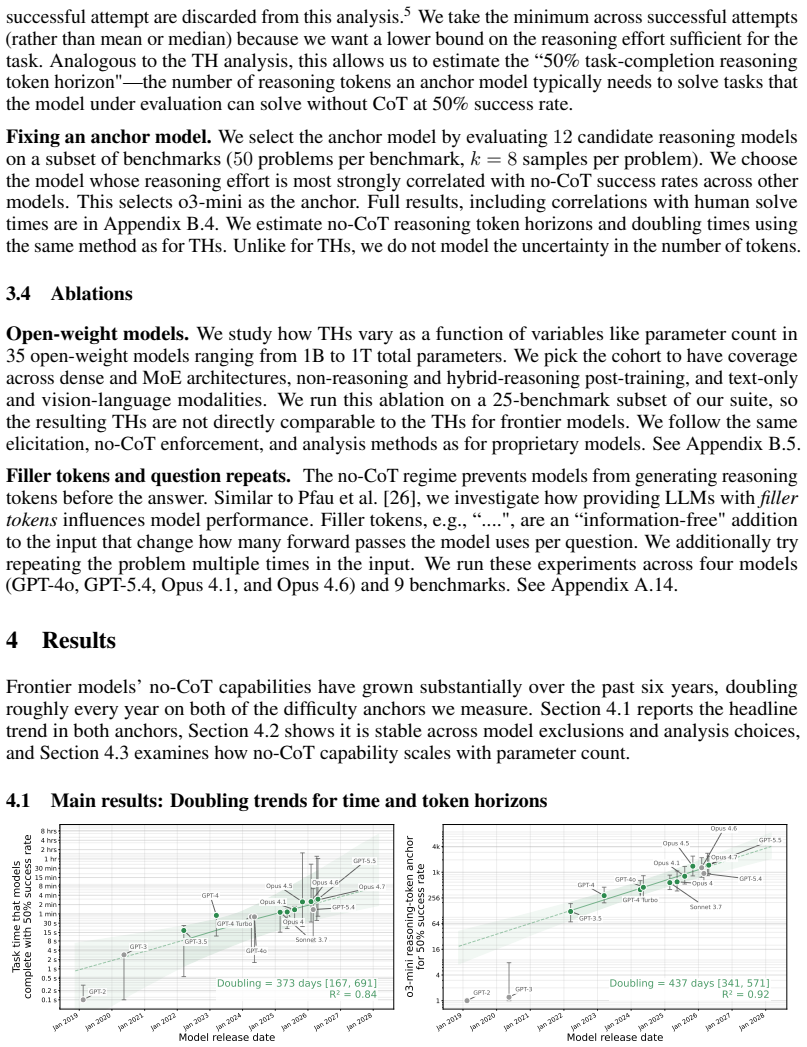
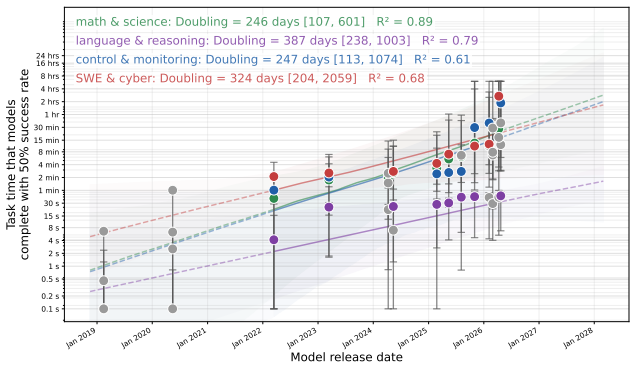
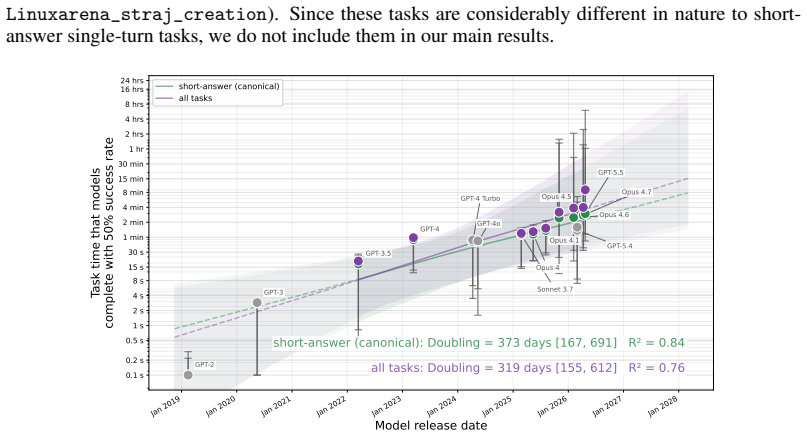
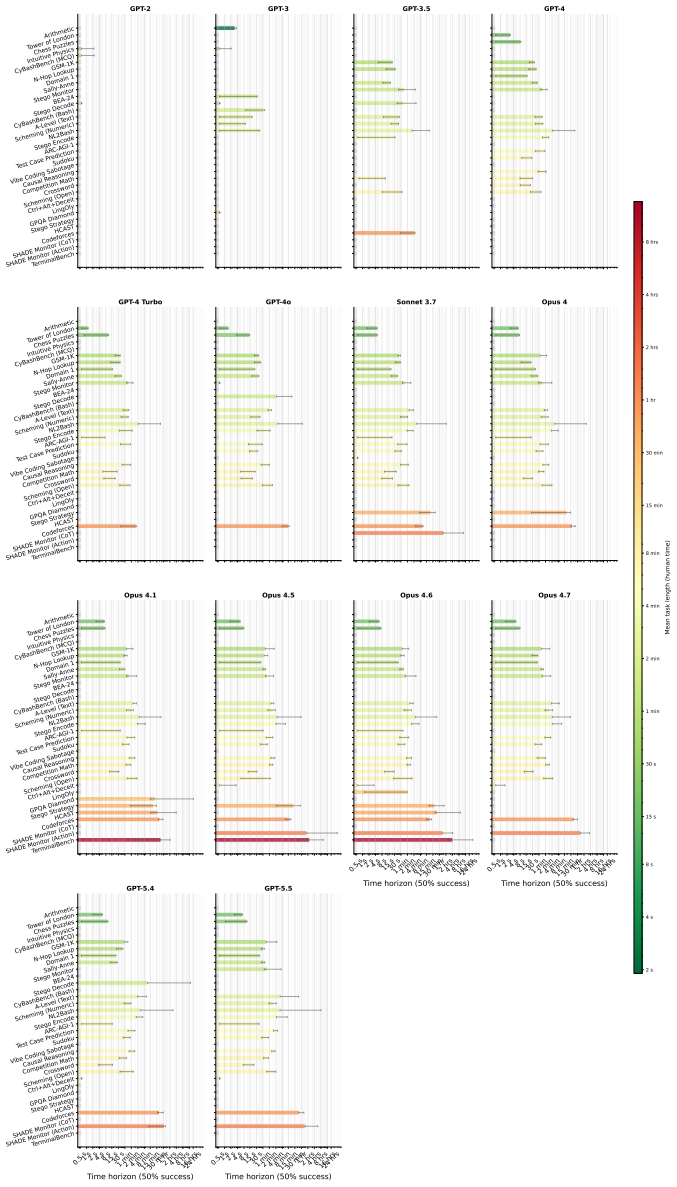
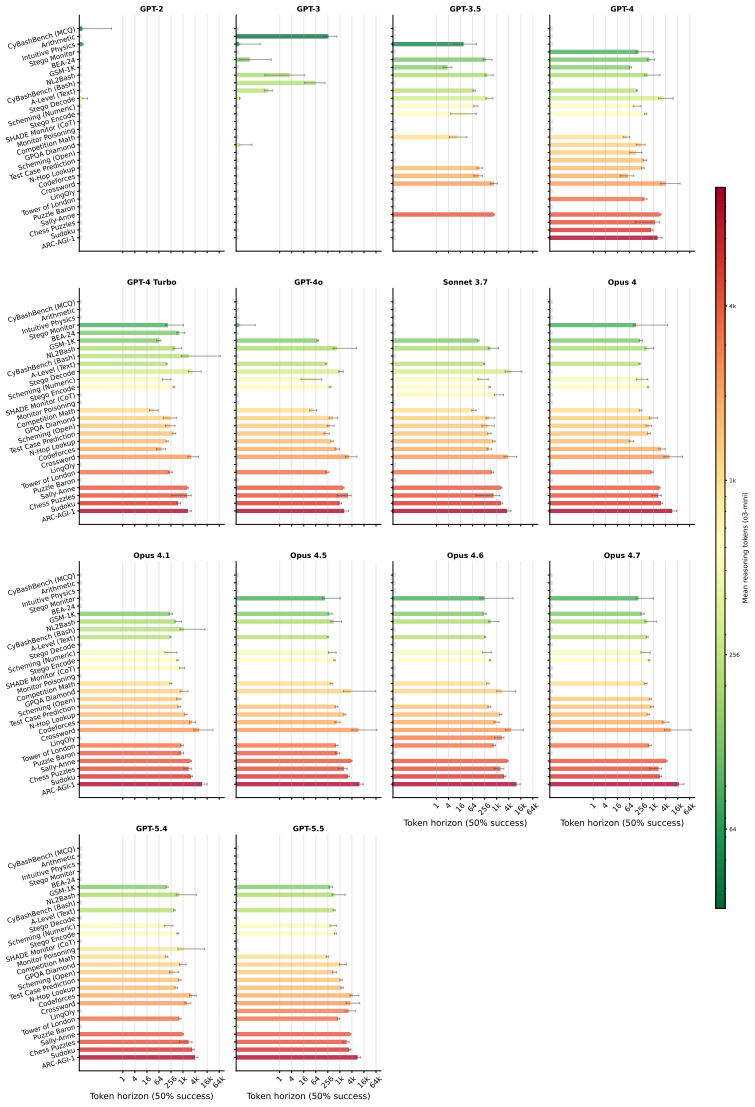
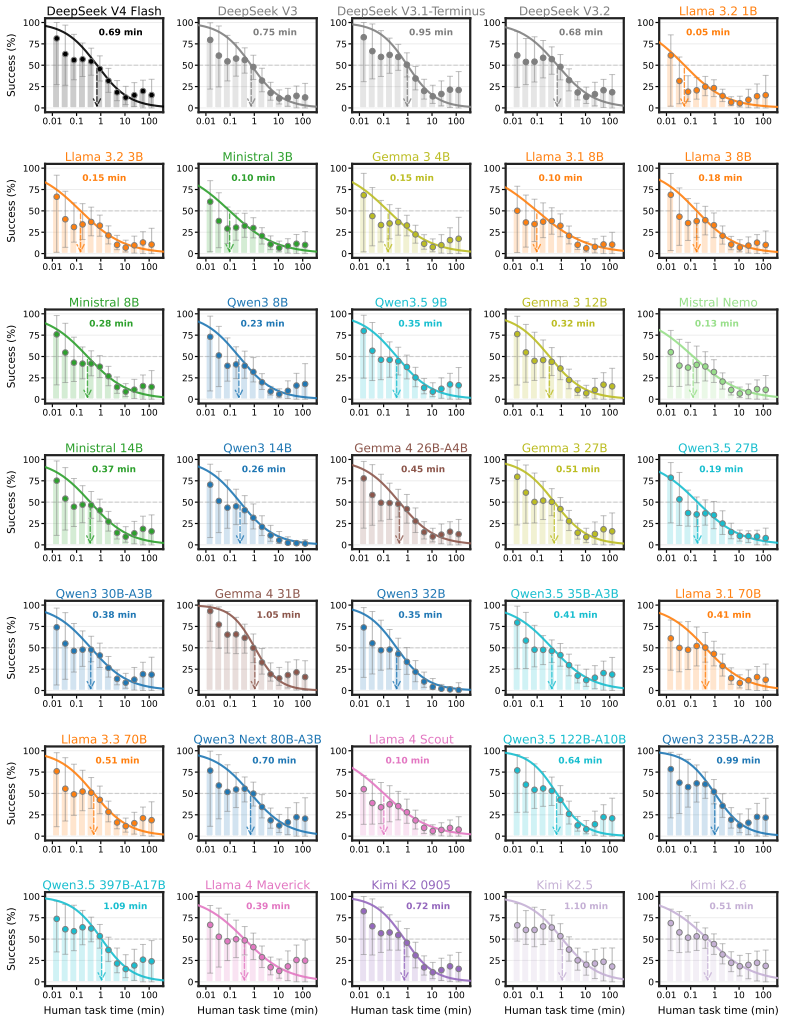
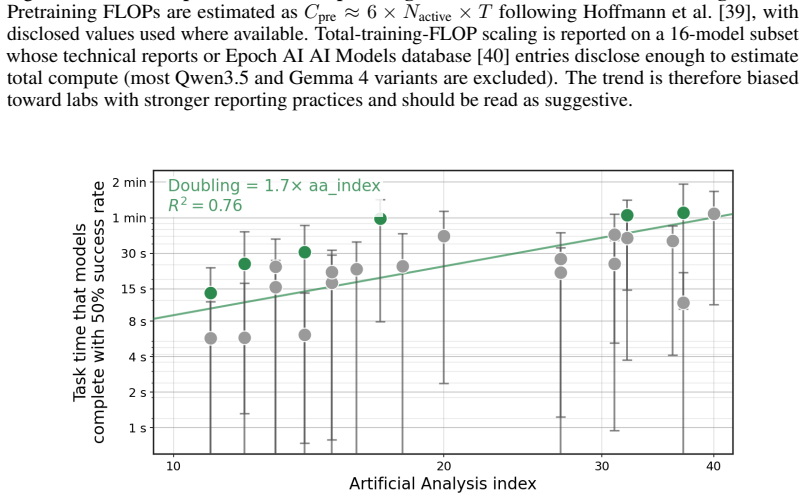
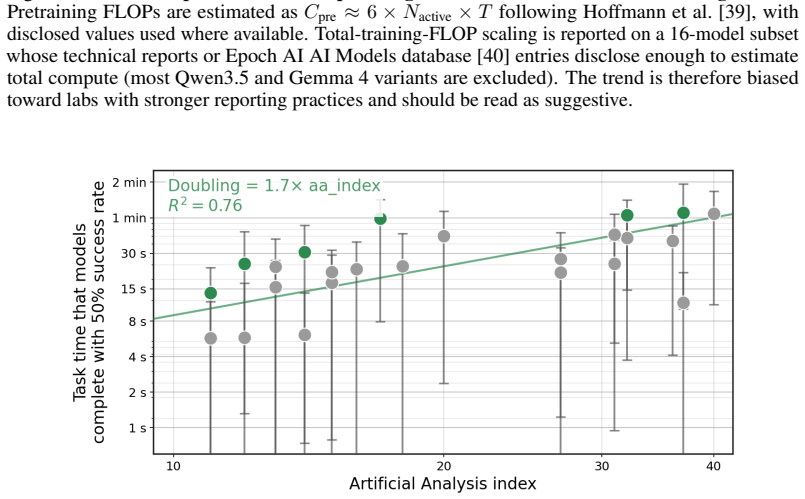
The no-CoT 50 percent task-completion time horizon of frontier models has doubled roughly every year over the past six years, with GPT-5.5 reaching over three minutes and a reasoning token horizon exceeding 1,500 tokens; median estimates project horizons above seven minutes by 2028 and 25 minutes by 2030.
What carries the argument
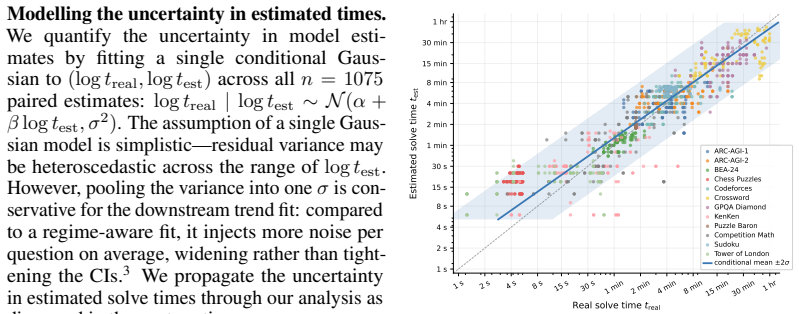
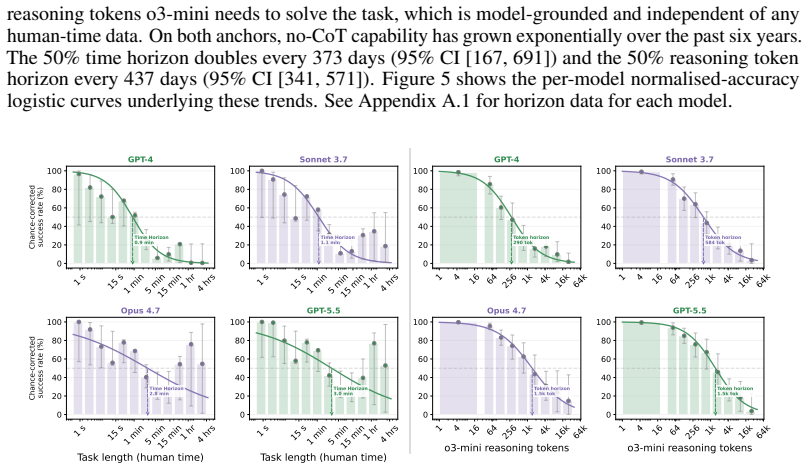
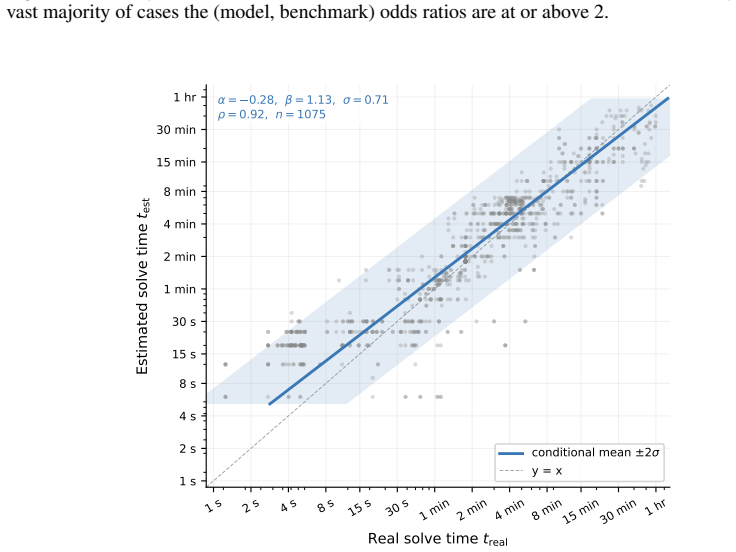
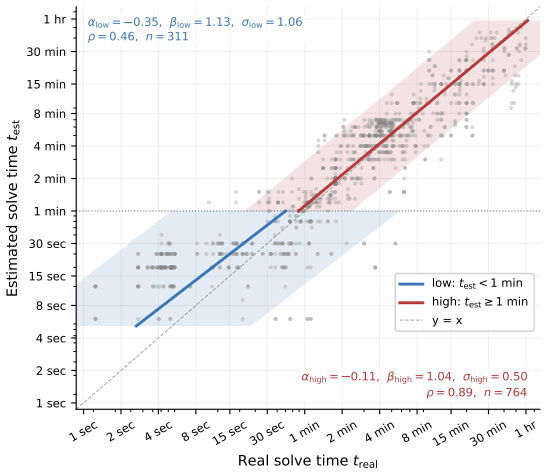
The 50 percent task-completion time horizon (TH), defined as the human time required for tasks a model completes with 50 percent success rate, paired with the 50 percent reasoning token horizon.
If this is right
- Models are approaching the ability to complete multi-minute tasks through internal reasoning alone.
- Safety monitoring that depends on inspecting chain-of-thought outputs will become less reliable as horizons grow.
- Frontier developers should begin explicit tracking of no-CoT time horizons alongside other capability metrics.
- Projections indicate no-CoT capabilities will reach tasks requiring 25 minutes of human effort by 2030 if the observed trend continues.
Where Pith is reading between the lines
- Continued doubling would mean models soon handle problems that require expert humans hours of effort without any visible intermediate steps.
- Safety research would need to develop new methods beyond output inspection, such as activation monitoring or behavioral testing on longer tasks.
- Benchmarks focused on tasks with 5- to 30-minute human completion times would be required to measure further progress accurately.
Load-bearing premise
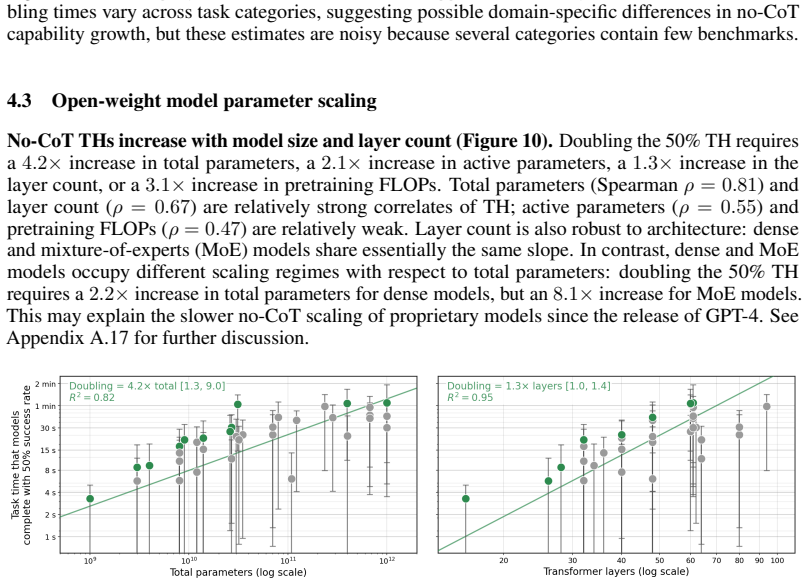
Performance on the chosen 43 benchmarks at the 50 percent success threshold provides a valid proxy for general no-CoT reasoning ability that can be directly compared to human task-completion times.
What would settle it
A new benchmark suite where current frontier models reach 50 percent success only on tasks that take humans under one minute would falsify both the reported horizons and the doubling trend.
Figures























read the original abstract
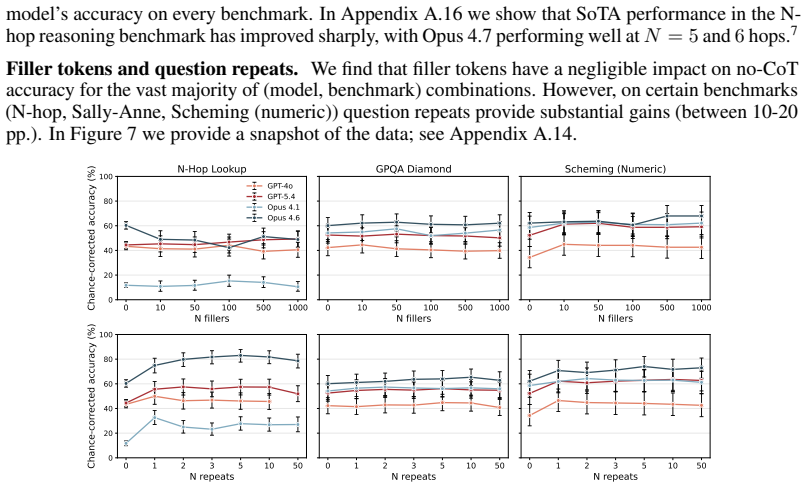
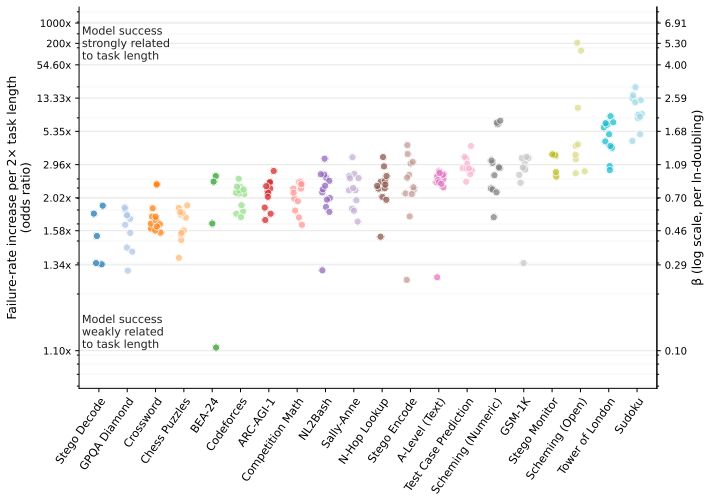
Many efforts to ensure frontier AI models are safe rely on monitoring their chain-of-thought (CoT) reasoning. If models become able to perform sufficiently complex reasoning internally, without explicit thinking tokens, this would undermine such oversight. We measure how well frontier models reason without CoT across a suite of over 30,000 questions spanning 43 benchmarks in domains including math, coding, puzzles, causality, theory-of-mind, and strategic reasoning. To compare models against humans, we estimate the $50\%$-task-completion time horizon (TH): the human time required for tasks a model completes with $50\%$ success rate. We complement this with a $50\%$ reasoning token horizon: the minimum number of o3-mini reasoning tokens needed for tasks a model solves with $50\%$ success rate. We find that the no-CoT $50\%$ TH of frontier models has been doubling roughly every year over the past six years, with GPT-5.5's TH reaching over 3 minutes and reasoning token horizon exceeding 1,500 tokens. Our median estimates predict that frontier no-CoT THs could exceed 7 minutes by 2028, and 25 minutes by 2030, though these projections carry substantial uncertainty. We recommend frontier developers track this explicitly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript measures frontier AI models' no-CoT reasoning performance across 43 benchmarks spanning math, coding, puzzles, causality, theory-of-mind, and strategic reasoning (over 30,000 questions total). It defines the 50% task-completion time horizon (TH) as the estimated human time required for tasks a model solves at 50% success rate, and a complementary 50% reasoning token horizon. The central claims are that no-CoT 50% TH has doubled roughly every year over the past six years, reaching >3 minutes for GPT-5.5 with a reasoning token horizon >1,500 tokens, and that median extrapolations predict >7 minutes by 2028 and >25 minutes by 2030.
Significance. If the benchmark suite and human-time mapping constitute a valid proxy for general no-CoT reasoning ability, the work supplies a concrete, time-based metric for tracking the erosion of CoT-based oversight and supplies falsifiable near-term predictions. The empirical trend over six years and the dual TH/token-horizon framing are strengths that could inform safety monitoring practices.
major comments (3)
- [Abstract] Abstract: The abstract states the doubling trend, GPT-5.5 values, and 2028/2030 projections but supplies no information on benchmark selection criteria, the method used to estimate human task-completion times, the statistical procedure for fitting the yearly doubling rate, or any error analysis. These omissions are load-bearing because the central claim that the 50% TH validly proxies general reasoning rests on the representativeness and calibration of the chosen tasks.
- [Methods] Methods (benchmark construction): The 50% success threshold is used to define task difficulty for both the time and token horizons, yet the manuscript provides no validation that tasks at this threshold correspond to real-world human task distributions or that the 43 benchmarks are not skewed toward short, multiple-choice, or AI-evaluation artifacts. This directly affects whether the observed trend can be extrapolated.
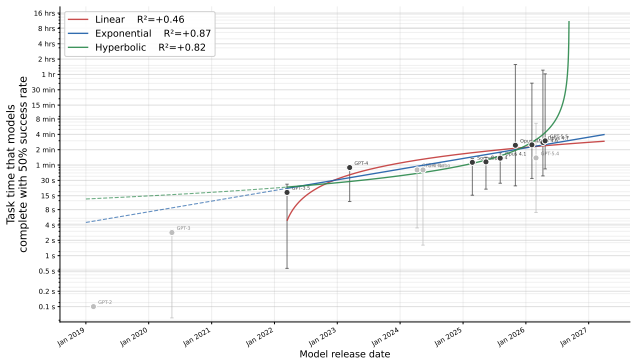
- [Results] Results (projections): The 2028 and 2030 forecasts are described as median estimates based on the observed yearly doubling trend. No sensitivity analysis to benchmark subset, alternative functional forms, or uncertainty quantification around the fitted rate is reported, rendering the projections an extrapolation of the same historical data used to establish the trend.
minor comments (2)
- [Abstract] The abstract states 'over 30,000 questions' but does not clarify whether all items are retained after filtering or how per-benchmark sample sizes affect the 50% threshold estimates.
- [Methods] Notation for the time horizon (TH) and reasoning token horizon should be introduced with an explicit equation in the methods section rather than only in the abstract.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states the doubling trend, GPT-5.5 values, and 2028/2030 projections but supplies no information on benchmark selection criteria, the method used to estimate human task-completion times, the statistical procedure for fitting the yearly doubling rate, or any error analysis. These omissions are load-bearing because the central claim that the 50% TH validly proxies general reasoning rests on the representativeness and calibration of the chosen tasks.
Authors: We agree the abstract would benefit from additional context. While full methodological details appear in the Methods and Results sections, we will revise the abstract to briefly note the benchmark selection (43 established datasets spanning math, coding, puzzles, causality, theory-of-mind, and strategic reasoning), the human-time estimation approach, the exponential fitting for the doubling rate, and the reported uncertainty in projections. revision: yes
-
Referee: [Methods] Methods (benchmark construction): The 50% success threshold is used to define task difficulty for both the time and token horizons, yet the manuscript provides no validation that tasks at this threshold correspond to real-world human task distributions or that the 43 benchmarks are not skewed toward short, multiple-choice, or AI-evaluation artifacts. This directly affects whether the observed trend can be extrapolated.
Authors: The 43 benchmarks were drawn from established public datasets chosen to cover diverse no-CoT reasoning domains with over 30,000 questions total. The 50% threshold is used consistently to define the horizon. We acknowledge that direct empirical validation against real-world task distributions is not performed and will add an expanded limitations section discussing potential selection effects and the difficulty of such calibration. revision: partial
-
Referee: [Results] Results (projections): The 2028 and 2030 forecasts are described as median estimates based on the observed yearly doubling trend. No sensitivity analysis to benchmark subset, alternative functional forms, or uncertainty quantification around the fitted rate is reported, rendering the projections an extrapolation of the same historical data used to establish the trend.
Authors: The projections are explicitly labeled as median extrapolations accompanied by a statement of substantial uncertainty. We will add sensitivity checks on the fitted doubling rate, alternative functional forms, and bootstrap-based uncertainty quantification around the trend in the revised Results section. revision: yes
Circularity Check
Future TH projections reduce to extrapolation of fitted historical doubling rate
specific steps
-
fitted input called prediction
[Abstract]
"We find that the no-CoT 50% TH of frontier models has been doubling roughly every year over the past six years, with GPT-5.5's TH reaching over 3 minutes and reasoning token horizon exceeding 1,500 tokens. Our median estimates predict that frontier no-CoT THs could exceed 7 minutes by 2028, and 25 minutes by 2030, though these projections carry substantial uncertainty."
The doubling rate is fitted directly to the observed historical performance data across models; the 'median estimates' for future years are obtained by applying that same fitted rate forward, making the numerical predictions statistically forced consequences of the input trend rather than an independent derivation.
full rationale
The paper measures current no-CoT 50% TH values on the benchmark suite and observes a doubling trend over six years of historical model data. The 2028/2030 projections are then generated by extending that fitted rate, which matches the fitted_input_called_prediction pattern. No other circular steps (self-definitional, self-citation load-bearing, etc.) are present in the provided text; the benchmark-to-TH mapping and trend observation are independent of the forward extrapolation.
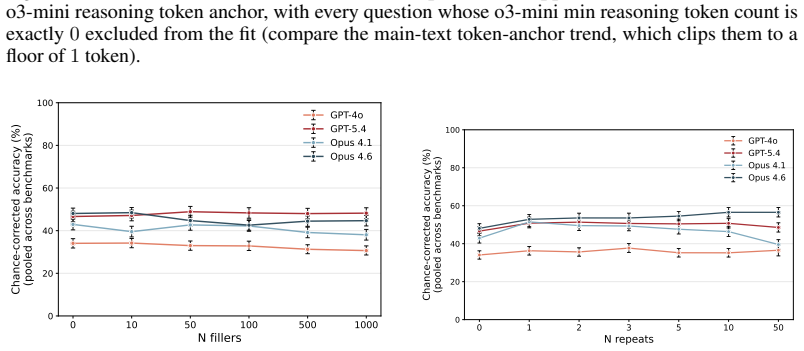
Axiom & Free-Parameter Ledger
free parameters (1)
- yearly doubling rate =
roughly 2x per year
axioms (1)
- domain assumption Benchmarks at 50% success rate measure meaningful no-CoT reasoning ability comparable to human task time.
Forward citations
Cited by 1 Pith paper
-
How Transparent is DiffusionGemma?
DiffusionGemma matches Gemma 4 in variable transparency and monitorability after applying an interpretable token bottleneck, despite higher naive serial depth, and shows novel phenomena such as non-chronological reasoning.
Reference graph
Works this paper leans on
-
[1]
OpenAI, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondrich,...
Pith/arXiv arXiv 2024
-
[2]
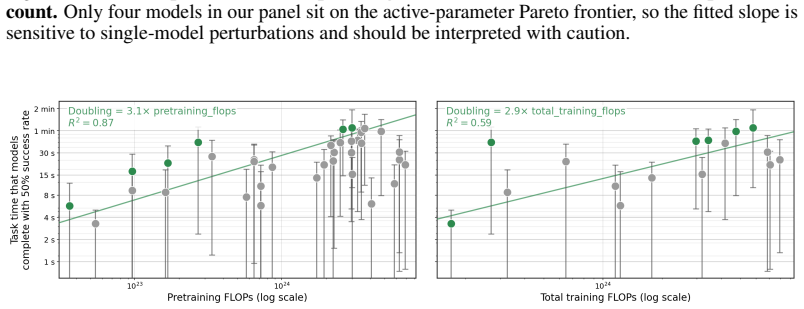
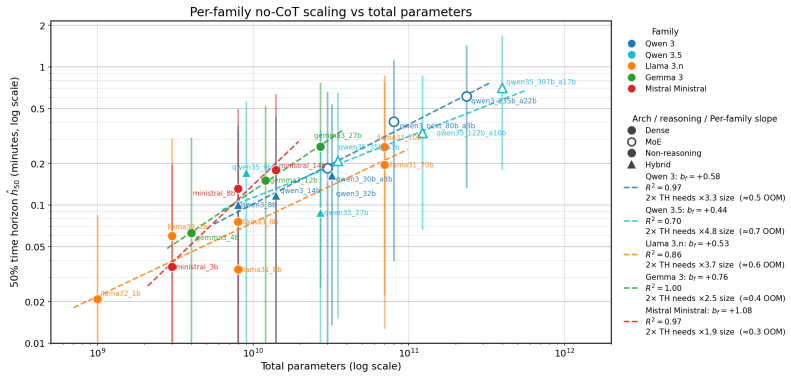
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, 11 Chong Ruan, Dama...
Pith/arXiv arXiv 2025
-
[3]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety, 2025
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, Scott Emmons, Owain Evans, David Farhi, Ryan Greenblatt, Dan Hendrycks, Marius Hobbhahn, Evan Hubinger, Geoffrey Irving, Erik Jenner, Daniel Kokotajlo, Victoria Krakovna, Shane Legg, David Lindner, David Luan, Aleksand...
Pith/arXiv arXiv 2025
-
[4]
Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi
Bowen Baker, Joost Huizinga, Leo Gao, Zehao Dou, Melody Y . Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi. Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation, 2025. URL https://arxiv.org/abs/ 2503.11926
Pith/arXiv arXiv 2025
-
[5]
CoT Red-Handed: Stress Testing Chain-of-Thought Monitoring,
Benjamin Arnav, Pablo Bernabeu-Pérez, Nathan Helm-Burger, Tim Kostolansky, Hannes Whit- tingham, and Mary Phuong. CoT Red-Handed: Stress Testing Chain-of-Thought Monitoring,
-
[6]
URLhttps://arxiv.org/abs/2505.23575
-
[7]
Bowman, and Evan Hubinger
Ryan Greenblatt, Carson Denison, Benjamin Wright, Fabien Roger, Monte MacDiarmid, Sam Marks, Johannes Treutlein, Tim Belonax, Jack Chen, David Duvenaud, Akbir Khan, Julian Michael, Sören Mindermann, Ethan Perez, Linda Petrini, Jonathan Uesato, Jared Kaplan, Buck Shlegeris, Samuel R. Bowman, and Evan Hubinger. Alignment faking in large language models,
-
[8]
URLhttps://arxiv.org/abs/2412.14093
-
[9]
Unfaithfulness
METR. CoT May Be Highly Informative Despite “Unfaithfulness”. https://metr.org/ blog/2025-08-08-cot-may-be-highly-informative-despite-unfaithfulness/ , August 2025
2025
-
[10]
A Survey on Latent Reasoning, 2025
Rui-Jie Zhu, Tianhao Peng, Tianhao Cheng, Xingwei Qu, Jinfa Huang, Dawei Zhu, Hao Wang, Kaiwen Xue, Xuanliang Zhang, Yong Shan, Tianle Cai, Taylor Kergan, Assel Kembay, Andrew Smith, Chenghua Lin, Binh Nguyen, Yuqi Pan, Yuhong Chou, Zefan Cai, Zhenhe Wu, Yongchi Zhao, Tianyu Liu, Jian Yang, Wangchunshu Zhou, Chujie Zheng, Chongxuan Li, Yuyin Zhou, Zhoujun...
arXiv 2025
-
[11]
Scott Emmons, Erik Jenner, David K. Elson, Rif A. Saurous, Senthooran Rajamanoharan, Heng Chen, Irhum Shafkat, and Rohin Shah. When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors, 2025. URLhttps://arxiv.org/abs/2507.05246
arXiv 2025
-
[12]
Frontier Models are Capable of In-context Scheming, 2025
Alexander Meinke, Bronson Schoen, Jérémy Scheurer, Mikita Balesni, Rusheb Shah, and Marius Hobbhahn. Frontier Models are Capable of In-context Scheming, 2025. URL https: //arxiv.org/abs/2412.04984
Pith/arXiv arXiv 2025
-
[13]
How will we update about scheming? https://blog.redwoodresearch
Ryan Greenblatt. How will we update about scheming? https://blog.redwoodresearch. org/p/how-will-we-update-about-scheming , January 2025. Redwood Research blog. Cross-posted on LessWrong
2025
-
[14]
A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, et al. A careful examination of large language model performance on grade school arithmetic.Advances in Neural Information Processing Systems, 37:46819–46836, 2024
2024
-
[15]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A Graduate-Level Google-Proof Q&A Benchmark, 2023. URLhttps://arxiv.org/abs/2311.12022
Pith/arXiv arXiv 2023
-
[16]
Ziegler, Elizabeth Barnes, and Lawrence Chan
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney V on Arx, Ryan Bloom, Thomas Broadley, Haoxing Du, Brian Goodrich, Nikola Jurkovic, Luke Harold Miles, Seraphina Nix, Tao Lin, Neev Parikh, David Rein, Lucas Jun Koba Sato, Hjalmar Wijk, Daniel M. Ziegler, Elizabeth Barnes, and Lawrence...
arXiv 2026
-
[17]
Inspect AI: Framework for Large Language Model Evaluations, 2024
UK AI Security Institute. Inspect AI: Framework for Large Language Model Evaluations, 2024. URLhttps://github.com/UKGovernmentBEIS/inspect_ai
2024
-
[18]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[19]
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models, 2025
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, Chenyang Shao, Yuwei Yan, Qinglong Yang, Yiwen Song, Sijian Ren, Xinyuan Hu, Yu Li, Jie Feng, Chen Gao, and Yong Li. Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models, 2025. URLhtt...
Pith/arXiv arXiv 2025
-
[20]
Stress Testing Deliberative Alignment for Anti-Scheming Training, 2025
Bronson Schoen, Evgenia Nitishinskaya, Mikita Balesni, Axel Højmark, Felix Hofstätter, Jérémy Scheurer, Alexander Meinke, Jason Wolfe, Teun van der Weij, Alex Lloyd, Nicholas Goldowsky-Dill, Angela Fan, Andrei Matveiakin, Rusheb Shah, Marcus Williams, Amelia Glaese, Boaz Barak, Wojciech Zaremba, and Marius Hobbhahn. Stress Testing Deliberative Alignment f...
arXiv 2025
-
[21]
All Code, No Thought: Current Language Models Struggle to Reason in Ciphered Language, 2025
Shiyuan Guo, Henry Sleight, and Fabien Roger. All Code, No Thought: Current Language Models Struggle to Reason in Ciphered Language, 2025. URL https://arxiv.org/abs/ 2510.09714
arXiv 2025
-
[22]
Training Large Language Models to Reason in a Continuous Latent Space, 2025
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training Large Language Models to Reason in a Continuous Latent Space, 2025. URL https://arxiv.org/abs/2412.06769
Pith/arXiv arXiv 2025
-
[23]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations, 2024
Jeffrey Cheng and Benjamin Van Durme. Compressed Chain of Thought: Efficient Reasoning Through Dense Representations, 2024. URLhttps://arxiv.org/abs/2412.13171
Pith/arXiv arXiv 2024
-
[24]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up Test- Time Compute with Latent Reasoning: A Recurrent Depth Approach, 2025. URL https: //arxiv.org/abs/2502.05171. 13
Pith/arXiv arXiv 2025
-
[25]
Implicit Chain of Thought Reasoning via Knowledge Distillation, 2023
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit Chain of Thought Reasoning via Knowledge Distillation, 2023. URL https://arxiv.org/abs/2311.01460
arXiv 2023
-
[26]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, 2024
Yuntian Deng, Yejin Choi, and Stuart Shieber. From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step, 2024. URLhttps://arxiv.org/abs/2405.14838
Pith/arXiv arXiv 2024
-
[27]
Reasoning Models Can Be Effective Without Thinking, 2025
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reasoning Models Can Be Effective Without Thinking, 2025. URL https://arxiv.org/abs/2504. 09858
2025
-
[28]
Jacob Pfau, William Merrill, and Samuel R. Bowman. Let’s Think Dot by Dot: Hidden Computation in Transformer Language Models, 2024. URL https://arxiv.org/abs/2404. 15758
2024
-
[29]
Beyond Chains of Thought: Benchmarking Latent-Space Reasoning Abilities in Large Language Models, 2025
Thilo Hagendorff and Sarah Fabi. Beyond Chains of Thought: Benchmarking Latent-Space Reasoning Abilities in Large Language Models, 2025. URL https://arxiv.org/abs/2504. 10615
2025
-
[30]
Quantifying the Necessity of Chain of Thought through Opaque Serial Depth, 2026
Jonah Brown-Cohen, David Lindner, and Rohin Shah. Quantifying the Necessity of Chain of Thought through Opaque Serial Depth, 2026. URLhttps://arxiv.org/abs/2603.09786
arXiv 2026
-
[31]
Do Large Language Models Latently Perform Multi-Hop Reasoning?, 2025
Sohee Yang, Elena Gribovskaya, Nora Kassner, Mor Geva, and Sebastian Riedel. Do Large Language Models Latently Perform Multi-Hop Reasoning?, 2025. URLhttps://arxiv.org/ abs/2402.16837
arXiv 2025
-
[32]
Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, 2025
Sohee Yang, Nora Kassner, Elena Gribovskaya, Sebastian Riedel, and Mor Geva. Do Large Language Models Perform Latent Multi-Hop Reasoning without Exploiting Shortcuts?, 2025. URLhttps://arxiv.org/abs/2411.16679
arXiv 2025
-
[33]
Layer-Order Inversion: Rethinking Latent Multi-Hop Reasoning in Large Language Models, 2026
Xukai Liu, Ye Liu, Jipeng Zhang, Yanghai Zhang, Kai Zhang, and Qi Liu. Layer-Order Inversion: Rethinking Latent Multi-Hop Reasoning in Large Language Models, 2026. URL https://arxiv.org/abs/2601.03542
arXiv 2026
-
[34]
How does time horizon vary across domains? https://metr
Vincent Cheng Thomas Kwa. How does time horizon vary across domains? https://metr. org/blog/2025-07-14-how-does-time-horizon-vary-across-domains/, 07 2025
2025
-
[35]
Offensive Cybersecurity Time Horizons
Jack Payne, Jeremy Miller, and Sean Peters. Offensive Cybersecurity Time Horizons. Re- search note, Lyptus Research, April 2026. URLhttps://lyptusresearch.org/research/ offensive-cyber-time-horizons
2026
-
[36]
A Rosetta Stone for AI Benchmarks, 2025
Anson Ho, Jean-Stanislas Denain, David Atanasov, Samuel Albanie, and Rohin Shah. A Rosetta Stone for AI Benchmarks, 2025. URLhttps://arxiv.org/abs/2512.00193
arXiv 2025
-
[37]
Arc-agi- 2: A new challenge for frontier ai reasoning systems, 2026
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. Arc-agi- 2: A new challenge for frontier ai reasoning systems, 2026. URL https://arxiv.org/abs/ 2505.11831
Pith/arXiv arXiv 2026
-
[38]
Findings from the first shared task on automated prediction of difficulty and response time for multiple-choice questions
Victoria Yaneva, Kai North, Peter Baldwin, Le An Ha, Saed Rezayi, Yiyun Zhou, Sag- nik Ray Choudhury, Polina Harik, and Brian Clauser. Findings from the first shared task on automated prediction of difficulty and response time for multiple-choice questions. In Ekaterina Kochmar, Marie Bexte, Jill Burstein, Andrea Horbach, Ronja Laarmann-Quante, Anaïs Tack...
2024
-
[39]
Competition-Level Code Generation with AlphaCode.arXiv preprint arXiv:2203.07814, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel Mankowitz, Esme Sutherland Robson, Pushmeet...
Pith/arXiv arXiv 2022
-
[40]
Joel L. Horowitz. Bootstrap methods in econometrics.Annual Review of Economics, 11(V olume 11, 2019):193–224, 2019. ISSN 1941-1391. doi: https://doi.org/10.1146/ annurev-economics-080218-025651. URL https://www.annualreviews.org/content/ journals/10.1146/annurev-economics-080218-025651
-
[41]
Rae, Oriol Vinyals, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
Pith/arXiv arXiv 2022
-
[42]
Data on AI models
Epoch AI. Data on AI models. https://epoch.ai/data/ai-models?view=table&tab= notable, 2024. Accessed: 2026-05-07
2024
-
[43]
Artificial Analysis Intelligence Index (v4.0)
Artificial Analysis. Artificial Analysis Intelligence Index (v4.0). https:// artificialanalysis.ai/models/open-source, 2026. Accessed: 2026-04-28
2026
-
[44]
Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
-
[45]
URLhttps://arxiv.org/abs/2412.19437
-
[46]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
Pith/arXiv arXiv 2025
-
[47]
On the Measure of Intelligence, 2019
François Chollet. On the Measure of Intelligence, 2019. URL https://arxiv.org/abs/ 1911.01547
Pith/arXiv arXiv 2019
-
[48]
CTRL-ALT-DECEIT: Sabotage Evaluations for Automated AI R&D, 2025
Francis Rhys Ward, Teun van der Weij, Hanna Gábor, Sam Martin, Raja Mehta Moreno, Harel Lidar, Louis Makower, Thomas Jodrell, and Lauren Robson. CTRL-ALT-DECEIT: Sabotage Evaluations for Automated AI R&D, 2025. URLhttps://arxiv.org/abs/2511.09904
arXiv 2025
-
[49]
HCAST: Human-Calibrated Autonomy Software Tasks, 2025
David Rein, Joel Becker, Amy Deng, Seraphina Nix, Chris Canal, Daniel O’Connel, Pip Arnott, Ryan Bloom, Thomas Broadley, Katharyn Garcia, Brian Goodrich, Max Hasin, Sami Jawhar, Megan Kinniment, Thomas Kwa, Aron Lajko, Nate Rush, Lucas Jun Koba Sato, Sydney V on Arx, Ben West, Lawrence Chan, and Elizabeth Barnes. HCAST: Human-Calibrated Autonomy Software ...
arXiv 2025
-
[50]
Neacs, u, Harry Mayne, Ryan Othniel Kearns, Andrew M
Jude Khouja, Lingyi Yang, Karolina Korgul, Simeon Hellsten, Vlad A. Neacs, u, Harry Mayne, Ryan Othniel Kearns, Andrew M. Bean, and Adam Mahdi. LINGOLY-TOO: Disentangling Reasoning from Knowledge with Templatised Orthographic Obfuscation. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=CQIkN2uuBr
2026
-
[51]
LinuxArena: A Control Setting for AI Agents in Live Production Software Environments, 2026
Tyler Tracy, Ram Potham, Nick Kuhn, Myles Heller, Anshul Khandelwal, Cody Rushing, Henri Lemoine, Miguel Brandao, Tomas Turlik, Adam Hanson, Josh Hills, Amy Ngo, Ram Rachum, Nik Mitchell, Falko Galperin, Oscar Sykes, Pip Arnott, Samuel Prieto Lima, Carlos Giudice, Matt Goldwater, Daniel Popp, Drew de Wet, Ruben Castaing, Qi Guo, Douw Marx, Benjamin Shaffr...
Pith/arXiv arXiv 2026
-
[52]
Nl2bash: A corpus and semantic parser for natural language interface to the linux operating system
Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D Ernst. Nl2bash: A corpus and semantic parser for natural language interface to the linux operating system. InProceedings of the eleventh international conference on language resources and evaluation (LREC 2018), 2018
2018
-
[53]
16 SHADE-Arena: Evaluating Sabotage and Monitoring in LLM Agents, 2025
Jonathan Kutasov, Yuqi Sun, Paul Colognese, Teun van der Weij, Linda Petrini, Chen Bo Calvin Zhang, John Hughes, Xiang Deng, Henry Sleight, Tyler Tracy, Buck Shlegeris, and Joe Benton. 16 SHADE-Arena: Evaluating Sabotage and Monitoring in LLM Agents, 2025. URL https: //arxiv.org/abs/2506.15740
arXiv 2025
-
[54]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
Pith/arXiv arXiv 2026
-
[55]
Solim LeGris, Wai Keen V ong, Brenden M. Lake, and Todd M. Gureckis. H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark, 2024. URLhttps://arxiv.org/abs/2409.01374
arXiv 2024
-
[56]
ARC-AGI-2 Human Testing Dataset
ARC Prize Foundation. ARC-AGI-2 Human Testing Dataset. https://huggingface.co/ datasets/arcprize/arc_agi_2_human_testing, 2025. Accessed: 2026-04-30
2025
-
[57]
Lichess puzzle database, 2026
Lichess. Lichess puzzle database, 2026. URL https://database.lichess.org/#puzzles. Accessed: 2026-03-01
2026
-
[58]
William G. Chase and Herbert A. Simon. Perception in chess.Cognitive Psychology, 4(1): 55–81, 1973. ISSN 0010-0285. doi: https://doi.org/10.1016/0010-0285(73)90004-2. URL https://www.sciencedirect.com/science/article/pii/0010028573900042
-
[59]
Recent LLMs can use filler tokens or problem repeats to improve (no-CoT) math performance
Ryan Greenblatt. Recent LLMs can use filler tokens or problem repeats to improve (no-CoT) math performance. https://blog.redwoodresearch.org/p/ recent-llms-can-use-filler-tokens , December 2025. Redwood Research blog. Cross- posted on LessWrong
2025
-
[60]
New York Times Crosswords (JSON Archive)
Dylan O’Shea. New York Times Crosswords (JSON Archive). https://github.com/ doshea/nyt_crosswords, 2017. GitHub repository. Contains NYT crossword puzzles since 1977 in JSON format. Accessed: 2026-04-30
2017
-
[61]
XW Stats: New York Times Crossword Solve Statistics
Dodge, Matt. XW Stats: New York Times Crossword Solve Statistics. https://xwstats. com/, 2026. Provides crowd-sourced solve times and statistics for NYT crossword puzzles. Accessed: 2026-04-30
2026
-
[62]
KenKen Puzzle Official Site: Free Math Puzzles That Make You Smarter
KenKen Puzzle, LLC. KenKen Puzzle Official Site: Free Math Puzzles That Make You Smarter. https://www.kenkenpuzzle.com/, 2026. Accessed: 2026-03-01
2026
-
[63]
Hale, and Hannah Rose Kirk
Andrew Michael Bean, Simeon Hellsten, Harry Mayne, Jabez Magomere, Ethan A Chi, Ryan Andrew Chi, Scott A. Hale, and Hannah Rose Kirk. LINGOLY: A Benchmark of Olympiad-Level Linguistic Reasoning Puzzles in Low Resource and Extinct Languages. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URLhttps...
2024
-
[64]
Past challenge puzzles: How far can you go? https: //www.uklo.org/past-exam-papers/, 2023
United Kingdom Linguistics Olympiad. Past challenge puzzles: How far can you go? https: //www.uklo.org/past-exam-papers/, 2023. Accessed: 2026-04-27
2023
-
[65]
Recent LLMs can do 2-hop and 3-hop latent (no CoT) reasoning on natural facts
Ryan Greenblatt. Recent LLMs can do 2-hop and 3-hop latent (no CoT) reasoning on natural facts. https://blog.redwoodresearch.org/p/ recent-llms-can-do-2-hop-and-3-hop , January 2026. Redwood Research blog post. Accessed: 2026-04-30. 17
2026
-
[66]
Logic Puzzles by Puzzle Baron
Puzzle Baron. Logic Puzzles by Puzzle Baron. https://logic.puzzlebaron.com/, 2026. Accessed: 2026-03-01
2026
-
[67]
Simon Baron-Cohen, Alan M. Leslie, and Uta Frith. Does the autistic child have a “the- ory of mind” ?Cognition, 21(1):37–46, 1985. ISSN 0010-0277. doi: https://doi. org/10.1016/0010-0277(85)90022-8. URL https://www.sciencedirect.com/science/ article/pii/0010027785900228
-
[68]
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 158–167, Vancouver, Canada, 2017. Association for Computational Linguistics
2017
-
[69]
Hidden in Plain Text: Emergence & Mitigation of Steganographic Collusion in LLMs, 2025
Yohan Mathew, Ollie Matthews, Robert McCarthy, Joan Velja, Christian Schroeder de Witt, Dy- lan Cope, and Nandi Schoots. Hidden in Plain Text: Emergence & Mitigation of Steganographic Collusion in LLMs, 2025. URLhttps://arxiv.org/abs/2410.03768
arXiv 2025
-
[70]
Sheng-Wei Wang. A Dataset of Sudoku Puzzles With Difficulty Metrics Experienced by Human Players.IEEE Access, 12:104254–104262, 2024. doi: 10.1109/ACCESS.2024.3434632
-
[71]
ReAct: Synergizing Reasoning and Acting in Language Models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models, 2023. URL https: //arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[72]
Specific impairments of planning.Philosophical Transactions of the Royal Society of London
Timothy Shallice. Specific impairments of planning.Philosophical Transactions of the Royal Society of London. B, Biological Sciences, 298(1089):199–209, 1982. doi: 10.1098/rstb.1982. 0082
-
[73]
Geoff Ward and Alan Allport. Planning and problem solving using the five-disc Tower of London task.The Quarterly Journal of Experimental Psychology Section A, 50(1):49–78, 1997. doi: 10.1080/027249897392224
-
[74]
Adrian M. Owen, John J. Downes, Barbara J. Sahakian, Charles E. Polkey, and Trevor W. Robbins. Planning and spatial working memory following frontal lobe lesions in man.Neu- ropsychologia, 28(10):1021–1034, 1990. doi: 10.1016/0028-3932(90)90137-D
-
[75]
Christoph P. Kaller, Josef M. Unterrainer, Benjamin Rahm, and Ulrike Halsband. The impact of problem structure on planning: Insights from the Tower of London task.Cognitive Brain Research, 20(3):462–472, 2004. doi: 10.1016/j.cogbrainres.2004.04.002
-
[76]
Sharlene D. Newman, Patricia A. Carpenter, Sashank Varma, and Marcel Adam Just. Frontal and parietal participation in problem solving in the Tower of London: fMRI and computational modeling of planning and high-level perception.Neuropsychologia, 41(12):1668–1682, 2003. doi: 10.1016/S0028-3932(03)00091-5
-
[77]
Olli Järviniemi and Evan Hubinger. Uncovering Deceptive Tendencies in Language Models: A Simulated Company AI Assistant, 2024. URLhttps://arxiv.org/abs/2405.01576. 18 Appendix Appendix contents A Additional results 21 A.1 Time and Token Horizon Results . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 A.2 Comparison to Kwa et al.’s THs . . . . . . ...
arXiv 2024
-
[78]
35%), which exhibit slower TH scaling as shown above
A larger fraction of hybrid-reasoning models are MoEs (60% vs. 35%), which exhibit slower TH scaling as shown above
-
[79]
A leave-one-out fit with Gemma 4 31B removed reduces the doubling factor to6.6×while increasing theR 2 value from 0.68 to 0.93
The outlier performance of Gemma 4 31B has substantial influence on the trend of hybrid- reasoning models. A leave-one-out fit with Gemma 4 31B removed reduces the doubling factor to6.6×while increasing theR 2 value from 0.68 to 0.93
-
[80]
minutes": <number>}. The user message containsNin-context examples in the format --- Example i --- Task: <problem> Human solve time: {
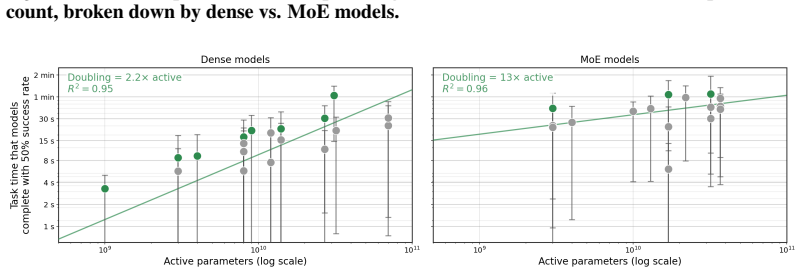
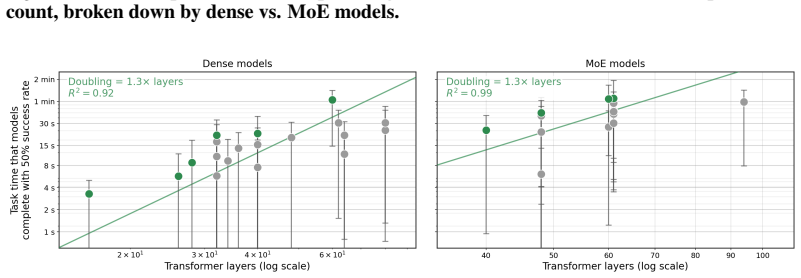
Reasoning training may reduce models’ propensity to answer questions with a single token, meaning that our tasks are further out-of-distribution for hybrid-reasoning models. However, we observe that despite a >50× gap in RL compute between DeepSeek V3 and DeepSeek Figure 36:No-CoT performance in open-weight models as a function of layer count, broken down...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.