TraRA: Trajectory-level Recognition Aggregation for Video Text Spotting in Urban Surveillance
Pith reviewed 2026-06-27 22:09 UTC · model grok-4.3
The pith
Aggregating text recognition over full trajectories improves spotting accuracy in surveillance videos despite blur and occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
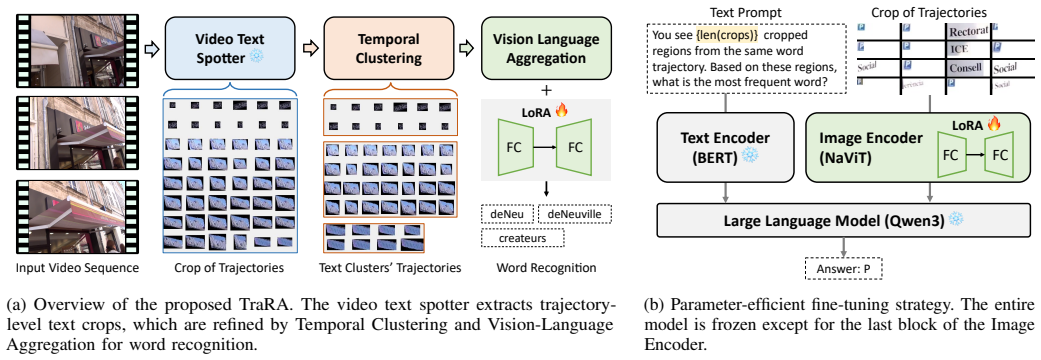
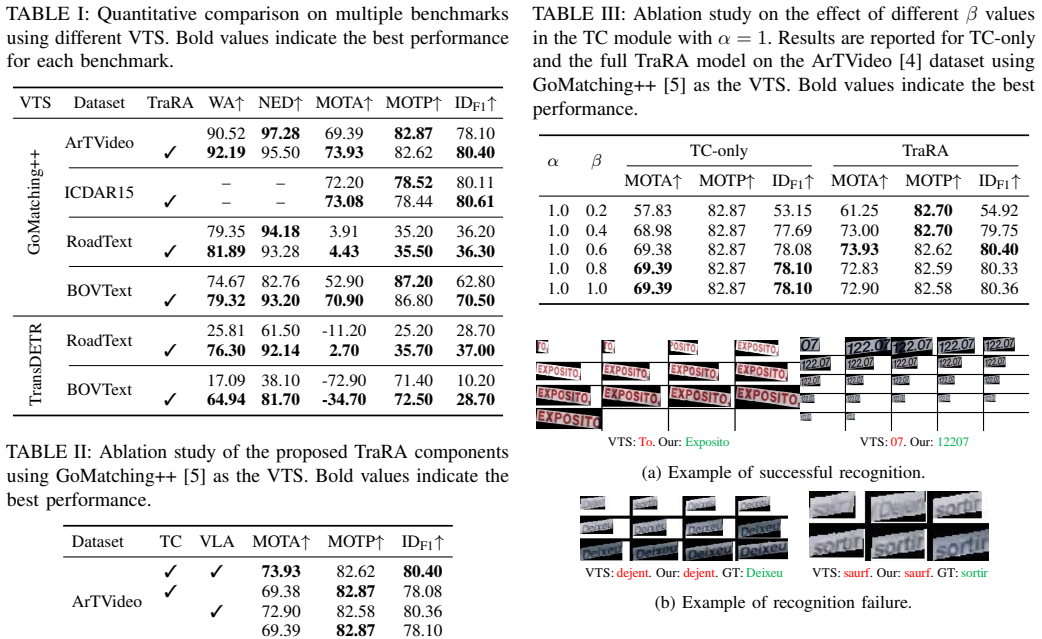
TraRA is a plug-and-play module that performs text recognition at the trajectory level by first using Temporal Clustering to group temporally and visually coherent text instances and then applying Vision-Language Aggregation, powered by a Low-Rank Adaptation-enhanced vision-language model, to combine visual cues and linguistic context across all frames in the trajectory, thereby delivering robust recognition under the motion blur, occlusion, and scale variation typical of urban surveillance video.
What carries the argument
Trajectory-level aggregation realized by Temporal Clustering for grouping coherent instances and Low-Rank Adaptation-enhanced Vision-Language Aggregation for cross-frame multimodal fusion.
If this is right
- Tracking and recognition metrics improve over prior state-of-the-art methods on RoadText, BOVText, ArTVideo, and ICDAR15.
- The approach functions as a drop-in addition to existing video text spotting pipelines.
- Performance gains arise specifically from exploiting both temporal consistency and multimodal vision-language information.
- The method mitigates the inconsistency caused by frame-independent recognition under surveillance conditions.
Where Pith is reading between the lines
- The same trajectory-aggregation pattern could be tested on other sequential recognition problems such as license-plate reading or scene-text translation in video.
- Replacing the low-rank adaptation with full fine-tuning or newer vision-language backbones might produce further gains, though at higher compute cost.
- In live surveillance deployments the added latency of clustering and aggregation would need direct measurement against the observed accuracy benefit.
Load-bearing premise
The temporal clustering step reliably isolates coherent text instances and the vision-language fusion step measurably improves recognition when cues are combined across frames.
What would settle it
An ablation study on the four benchmarks showing that disabling either the Temporal Clustering or the Vision-Language Aggregation module produces no statistically significant gain over existing frame-level video text spotting baselines.
Figures

read the original abstract
Video Text Spotting (VTS) is essential for urban surveillance and intelligent transportation systems, enabling automated reading of street signs, vehicle markings, and scene text in video streams. However, reliable recognition remains challenging due to dynamic video factors common in surveillance scenarios, including motion blur, occlusion, and scale variation, which degrade frame-level recognition. Existing VTS methods typically perform recognition independently on each frame, leading to inconsistent and inaccurate results across sequences. To address these limitations, we propose TraRA (Trajectory-level Recognition Aggregation for VTS), a plug-and-play method that performs trajectory-level text recognition by leveraging temporal and multimodal consistency. TraRA integrates two key modules: (1) the Temporal Clustering and (2) the Vision-Language Aggregation. The former refines noisy trajectories by grouping temporally and visually coherent text instances, while the latter employs a Low-Rank Adaptation-enhanced Vision-Language model to fuse visual cues with linguistic context across frames. By aggregating information over entire text trajectories, TraRA achieves robust text recognition even under challenging surveillance conditions. Extensive experiments on four public benchmarks, including road and urban scene datasets (RoadText, BOVText, ArTVideo, and ICDAR15), demonstrate that TraRA consistently improves tracking and recognition performance over state-of-the-art VTS methods. The source code is available at https://github.com/trid2912/TraRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TraRA, a plug-and-play method for video text spotting (VTS) that shifts from frame-independent recognition to trajectory-level aggregation. It introduces a Temporal Clustering module to refine noisy trajectories by grouping temporally and visually coherent instances, and a Vision-Language Aggregation module that uses a LoRA-enhanced vision-language model to fuse visual cues with linguistic context across frames. The approach is evaluated on four benchmarks (RoadText, BOVText, ArTVideo, ICDAR15), with claims of consistent improvements in tracking and recognition over state-of-the-art VTS methods under surveillance conditions such as motion blur and occlusion. Source code is provided via GitHub.
Significance. If the trajectory-level premise holds, TraRA could meaningfully advance robust VTS for urban surveillance and intelligent transportation by exploiting temporal and multimodal consistency. The availability of source code is a clear strength that supports reproducibility and future extensions.
major comments (1)
- [Experiments] The central claim requires that the Temporal Clustering module reliably produces coherent trajectories and the Vision-Language Aggregation module produces useful multimodal fusion that improves recognition under surveillance degradations. However, the manuscript reports only end-to-end benchmark gains on RoadText/BOVText/ArTVideo/ICDAR15 without module-level ablations, clustering-quality metrics, or controlled comparisons that isolate the aggregation effect from the LoRA-enhanced VLM itself (see abstract and experiments description).
minor comments (1)
- [Abstract] The abstract would benefit from quantitative statements on the magnitude of reported improvements rather than the qualitative claim of 'consistent improvements.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger module-level validation. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] The central claim requires that the Temporal Clustering module reliably produces coherent trajectories and the Vision-Language Aggregation module produces useful multimodal fusion that improves recognition under surveillance degradations. However, the manuscript reports only end-to-end benchmark gains on RoadText/BOVText/ArTVideo/ICDAR15 without module-level ablations, clustering-quality metrics, or controlled comparisons that isolate the aggregation effect from the LoRA-enhanced VLM itself (see abstract and experiments description).
Authors: We agree that the current experiments section focuses on end-to-end benchmark results and does not include dedicated module ablations or isolation studies. To strengthen the validation of the central claim, we will add: (1) quantitative clustering-quality metrics (e.g., temporal coherence and visual similarity scores) for the Temporal Clustering module, (2) ablation tables removing or replacing the Vision-Language Aggregation module, and (3) controlled comparisons of the LoRA-enhanced VLM against its base version within the aggregation pipeline. These additions will appear in a new subsection of the experiments and will be supported by the already-released source code. revision: yes
Circularity Check
No circularity; method is architectural with no derivations or fitted predictions.
full rationale
The manuscript describes a plug-and-play architecture (Temporal Clustering + LoRA-enhanced Vision-Language Aggregation) and reports end-to-end benchmark gains. No equations, parameter-fitting steps, uniqueness theorems, or self-citations are presented that would reduce any claimed result to its own inputs by construction. The central claim rests on empirical improvements rather than any self-referential derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scene text recognition for text-based traffic signs,
Y . Taki and E. Zemmouri, “Scene text recognition for text-based traffic signs,” inAdvances in Intelligent Traffic and Transportation Systems, 2023, pp. 67–77
2023
-
[2]
Scene text detection and recognition: The deep learning era,
S. Long, X. He, and C. Yao, “Scene text detection and recognition: The deep learning era,”International Journal of Computer Vision, vol. 129, no. 1, pp. 161–184, 2021
2021
-
[3]
End- to-end video text spotting with transformer,
W. Wu, Y . Cai, C. Shen, D. Zhang, Y . Fu, H. Zhou, and P. Luo, “End- to-end video text spotting with transformer,”International Journal of Computer Vision, vol. 132, no. 9, pp. 4019–4035, 2024
2024
-
[4]
GoMatching: A simple baseline for video text spotting via long and short term matching,
H. He, M. Ye, J. Zhang, J. Liu, B. Du, and D. Tao, “GoMatching: A simple baseline for video text spotting via long and short term matching,” Advances in Neural Information Processing Systems, vol. 37, pp. 25 663– 25 686, 2024
2024
-
[5]
GoMatching++: Parameter-and data-efficient arbitrary-shaped video text spotting and benchmarking,
H. He, J. Zhang, M. Ye, J. Liu, B. Du, and D. Tao, “GoMatching++: Parameter-and data-efficient arbitrary-shaped video text spotting and benchmarking,”arXiv preprint arXiv:2505.22228, 2025
arXiv 2025
-
[6]
DeepSolo: Let transformer decoder with explicit points solo for text spotting,
M. Ye, J. Zhang, S. Zhao, J. Liu, T. Liu, B. Du, and D. Tao, “DeepSolo: Let transformer decoder with explicit points solo for text spotting,” in Proc. of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 348–19 357
2023
-
[7]
Scene text recognition with permuted au- toregressive sequence models,
D. Bautista and R. Atienza, “Scene text recognition with permuted au- toregressive sequence models,” inProc. of the 14th European Conference on Computer Vision, 2022
2022
-
[8]
SVTR: Scene text recognition with a single visual model,
Y . Du, Z. Chen, C. Jia, X. Yin, T. Zheng, C. Li, Y . Du, and Y .-G. Jiang, “SVTR: Scene text recognition with a single visual model,” inProc. of the 31st International Joint Conference on Artificial Intelligence, 2022
2022
-
[9]
A bilingual, openworld video text dataset and end-to-end video text spotter with transformer,
W. Wu, Y . Cai, D. Zhang, S. Wang, Z. Li, J. Li, Y . Tang, and H. Zhou, “A bilingual, openworld video text dataset and end-to-end video text spotter with transformer,”Advances in Neural Information Processing Systems, vol. 34, 2021
2021
-
[10]
DSText V2: A comprehensive video text spotting dataset for dense and small text,
W. Wu, Y . Zhang, Y . He, L. Zhang, Z. Lou, H. Zhou, and X. Bai, “DSText V2: A comprehensive video text spotting dataset for dense and small text,”Pattern Recognition, vol. 149, p. 110177, 2024
2024
-
[11]
ICDAR 2015 competition on robust reading,
D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. Ghosh, A. Bagdanov, M. Iwamura, J. Matas, L. Neumann, V . R. Chandrasekhar, S. Luet al., “ICDAR 2015 competition on robust reading,” inProc. of the 13th International Conference on Document Analysis and Recognition, 2015, pp. 1156–1160
2015
-
[12]
Textssr: Diffusion-based data synthesis for scene text recognition,
X. Ye, Y . Du, Y . Tao, and Z. Chen, “Textssr: Diffusion-based data synthesis for scene text recognition,” inProc. of the 2025 IEEE/CVF International Conference on Computer Vision, 2025, pp. 17 464–17 473
2025
-
[13]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in Proc. of the 10th International Conference on Learning Representations, 2022
2022
-
[14]
Q-Adapter: Visual query adapter for extracting textually-related features in video captioning,
J. Chen, T. T. Nguyen, T. Komamizu, and I. Ide, “Q-Adapter: Visual query adapter for extracting textually-related features in video captioning,” inProceedings of the 7th ACM International Conference on Multimedia in Asia, 2025
2025
-
[15]
An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,
B. Shi, X. Bai, and C. Yao, “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, pp. 2298–2304, 2015
2015
-
[16]
Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition,
S. Fang, H. Xie, Y . Wang, Z. Mao, and Y . Zhang, “Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition,” inProc. of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7094–7103
2021
-
[17]
SVIPTR: Fast and efficient scene text recognition with vision permutable extractor,
X. Cheng, W. Zhou, X. Li, X. Chen, J. Yang, T. Li, and Z. Li, “SVIPTR: Fast and efficient scene text recognition with vision permutable extractor,” inProc. of the 33rd ACM International Conference on Information and Knowledge Management, 2024
2024
-
[18]
DiffusionSTR: Diffusion model for scene text recognition,
M. Fujitake, “DiffusionSTR: Diffusion model for scene text recognition,” inProc. of the 2023 IEEE International Conference on Image Processing, 2023, pp. 1585–1589
2023
-
[19]
Mask textspotter v3: Segmentation proposal network for robust scene text spotting,
M. Liao, G. Pang, J. Huang, T. Hassner, and X. Bai, “Mask textspotter v3: Segmentation proposal network for robust scene text spotting,” in Proc. of the 16th European conference on computer vision, 2020, pp. 706–722
2020
-
[20]
Swintextspotter: Scene text spotting via better synergy between text detection and text recognition,
M. Huang, Y . Liu, Z. Peng, C. Liu, D. Lin, S. Zhu, N. Yuan, K. Ding, and L. Jin, “Swintextspotter: Scene text spotting via better synergy between text detection and text recognition,” inProc. of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4593–4603
2022
-
[21]
FREE: A fast and robust end-to-end video text spotter,
Z. Cheng, J. Lu, B. Zou, L. Qiao, Y . Xu, S. Pu, Y . Niu, F. Wu, and S. Zhou, “FREE: A fast and robust end-to-end video text spotter,”IEEE Transactions on Image Processing, vol. 30, pp. 822–837, 2020
2020
-
[22]
CLIP4STR: A simple baseline for scene text recognition with pre-trained vision-language model,
S. Zhao, X. Wang, L. Zhu, and Y . Yang, “CLIP4STR: A simple baseline for scene text recognition with pre-trained vision-language model,”IEEE Transactions on Image Processing, vol. 33, pp. 6893–6904, 2023
2023
-
[23]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inProc. of the 38th International Conference on Machine Learning, 2021
2021
-
[24]
Nougat: Neural optical understanding for academic documents,
L. Blecher, G. Cucurull, T. Scialom, and R. Stojnic, “Nougat: Neural optical understanding for academic documents,” inProc. of the 2024 International Conference on Learning Representations, 2024
2024
-
[25]
S. Lu, Y . Li, Y . Xia, Y . Hu, S. Zhao, Y . Ma, Z. Wei, Y . Li, L. Duan, J. Zhao et al., “Ovis2.5 technical report,”arXiv preprint arXiv:2508.11737, 2025
Pith/arXiv arXiv 2025
-
[26]
VLMEvalKit: An open-source toolkit for evaluating large multi-modality models,
H. Duan, J. Yang, Y . Qiao, X. Fang, L. Chen, Y . Liu, X. Dong, Y . Zang, P. Zhang, J. Wanget al., “VLMEvalKit: An open-source toolkit for evaluating large multi-modality models,” inProc. of the 32nd ACM international conference on multimedia, 2024, pp. 11 198–11 201
2024
-
[27]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdul- mohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa et al., “Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[28]
Patch n’ pack: Navit, a vision transformer for any aspect ratio and resolution,
M. Dehghani, B. Mustafa, J. Djolonga, J. Heek, M. Minderer, M. Caron, A. Steiner, J. Puigcerver, R. Geirhos, I. M. Alabdulmohsin, A. Oliver, P. Padlewski, A. Gritsenko, M. Lucic, and N. Houlsby, “Patch n’ pack: Navit, a vision transformer for any aspect ratio and resolution,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 2252–2274
2023
-
[29]
Z. Bai, A. Yang, Y . Zheng, J. Ye, X. Ma, X. Wang, X. Wei, X. Fan, S. Zhanget al., “Qwen3 technical report,”arXiv preprint arXiv:2501.13694, 2025
arXiv 2025
-
[30]
RoadText-1K: Text detection & recognition dataset for driving videos,
S. Reddy, M. Mathew, L. Gomez, M. Rusinol, D. Karatzas, and C. Jawahar, “RoadText-1K: Text detection & recognition dataset for driving videos,” inProc. of the 2020 IEEE International Conference on Robotics and Automation, 2020, pp. 11 074–11 080
2020
-
[31]
Evaluating multiple object tracking performance: the clear mot metrics,
K. Bernardin and R. Stiefelhagen, “Evaluating multiple object tracking performance: the clear mot metrics,”EURASIP Journal on Image and Video Processing, vol. 2008, no. 1, p. 246309, 2008
2008
-
[32]
Performance measures and a data set for multi-target, multi-camera tracking,
E. Ristani, F. Solera, R. Zou, R. Cucchiara, and C. Tomasi, “Performance measures and a data set for multi-target, multi-camera tracking,” inProc. of the 14th European Conference on Computer Vision, 2016, pp. 17–35
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.