Constrained Dominant Sets for Multimodal Document Question Answering
Pith reviewed 2026-06-27 20:43 UTC · model grok-4.3
The pith
Constrained dominant sets on a query-augmented affinity graph select complementary evidence for multimodal document question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
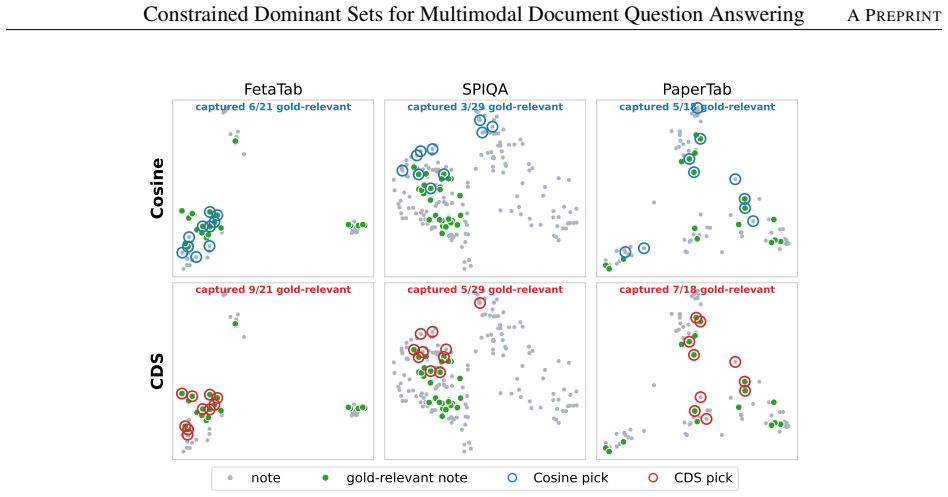
The central claim is that Constrained Dominant Set selection on a query-augmented affinity graph supplies three concrete advantages over similarity ranking: the query is encoded as a hard structural constraint so every selected element connects directly to it; the relevance-redundancy tradeoff is fixed by a spectral bound instead of hand-tuned parameters; and the selection reaches global equilibrium through replicator dynamics, avoiding heuristic distortions. The method is graph-based and training-free. With a fixed reader it reaches 66.99 average on VisDoMBench while lifting performance 37.1 points above the no-retrieval baseline on that benchmark and 4.8 points on MMLongBench-Doc.
What carries the argument
Constrained Dominant Set (CDS) selection on a query-augmented affinity graph, which treats the query as a structural anchor and uses spectral bounds plus replicator dynamics to enforce relevance without redundancy or manual tuning.
If this is right
- Every selected evidence item must connect directly to the query through the cluster anchor.
- Relevance-redundancy balance is fixed automatically by the spectral bound, removing manual trade-off parameters.
- The selection reaches global equilibrium via replicator dynamics rather than greedy heuristics.
- The method yields 66.99 average accuracy on VisDoMBench and lifts the no-retrieval baseline by 37.1 points on VisDoMBench and 4.8 points on MMLongBench-Doc.
Where Pith is reading between the lines
- The same graph construction could be tested on single-modality document QA to isolate whether the gains come from handling figures and captions.
- Because the approach needs no training, it offers a drop-in replacement for existing retrievers in production RAG pipelines.
- The spectral-bound mechanism might extend to other diversity-aware retrieval problems where parameter-free balance is required.
Load-bearing premise
The query-augmented affinity graph can be built so that Constrained Dominant Set selection automatically enforces a hard query constraint and sets the relevance-redundancy balance through its spectral bound.
What would settle it
Running the CDS retriever on VisDoMBench and obtaining scores no higher than the no-retrieval baseline or standard similarity retrievers would falsify the performance advantage.
Figures

read the original abstract
Long multimodal document question answering is limited by which evidence reaches the reader, rather than by the quantity retrieved. In lengthy documents, findings often recur across figures, captions, and introductory sentences, causing similarity based retrievers in modern multimodal retrieval-augmented generation (RAG) systems to allocate resources to near-duplicates while overlooking complementary evidence. This work introduces a retriever that selects evidence as a Constrained Dominant Set (CDS) on a query-augmented affinity graph, offering three advantages that similarity ranking does not. First, the query is encoded as a hard structural constraint, ensuring that every selected element is directly connected to the question through the cluster anchor. Second, the relevance-redundancy balance is determined automatically by a spectral bound, eliminating the need for manually tuned trade offs required by diversity-aware selectors. Third, the selection process achieves a global equilibrium via replicator dynamics, thereby avoiding the distortions introduced by greedy heuristics. The method is inherently graph-based and does not require training. Using a Qwen3-VL-32B reader, CDS establishes a new state of the art on VisDoMBench ($66.99$ average) and improves over the no-retrieval baseline by $37.1$ points on VisDoMBench and $4.8$ on MMLongBench-Doc.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Constrained Dominant Sets (CDS) on a query-augmented affinity graph as a training-free retriever for evidence selection in long multimodal document QA. It claims three advantages over similarity ranking: (1) the query acts as a hard structural constraint via the cluster anchor, (2) relevance-redundancy balance is set automatically by a spectral bound, and (3) selection reaches global equilibrium via replicator dynamics. Using a Qwen3-VL-32B reader, the method reports a new SOTA of 66.99 average on VisDoMBench and gains of 37.1 points on VisDoMBench and 4.8 points on MMLongBench-Doc over the no-retrieval baseline.
Significance. If the empirical gains and the three claimed properties hold under full implementation details, the work would offer a principled, parameter-free alternative to tuned diversity-aware retrievers in multimodal RAG. The training-free nature and grounding in standard CDS properties (hard constraint, spectral bound, replicator dynamics) constitute a clear strength.
major comments (2)
- [Abstract] Abstract: the central empirical claim (SOTA at 66.99 and the 37.1 / 4.8 point gains) is stated without any derivation, graph-construction details, ablation studies, or error analysis, so it is impossible to assess whether the data support the three advantages or the SOTA assertion.
- [Abstract] Abstract (weakest assumption): the claim that the query-augmented affinity graph plus CDS automatically enforces a hard query constraint, sets relevance-redundancy via spectral bound, and reaches equilibrium via replicator dynamics without training or manual tuning is asserted but not derived or illustrated with even a small example; this is load-bearing for all three listed advantages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for clearer support of the central claims. We address each point below and will revise the manuscript to improve clarity and accessibility while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (SOTA at 66.99 and the 37.1 / 4.8 point gains) is stated without any derivation, graph-construction details, ablation studies, or error analysis, so it is impossible to assess whether the data support the three advantages or the SOTA assertion.
Authors: The abstract serves as a concise summary; the full manuscript provides the requested details in Section 3.1 (graph construction), Section 3.2 (CDS formulation and properties), Section 4.3 (ablations), and Section 4.4 (error analysis). The reported SOTA of 66.99 and gains of 37.1 / 4.8 points are obtained with the Qwen3-VL-32B reader on VisDoMBench and MMLongBench-Doc. To address the concern, we will revise the abstract to briefly reference the key methodological components and direct readers to the relevant sections. revision: yes
-
Referee: [Abstract] Abstract (weakest assumption): the claim that the query-augmented affinity graph plus CDS automatically enforces a hard query constraint, sets relevance-redundancy via spectral bound, and reaches equilibrium via replicator dynamics without training or manual tuning is asserted but not derived or illustrated with even a small example; this is load-bearing for all three listed advantages.
Authors: These three properties are direct consequences of the CDS definition applied to the query-augmented graph, as formalized in Section 3.2: the query node serves as the cluster anchor (hard constraint), the spectral radius of the affinity matrix supplies the relevance-redundancy bound, and replicator dynamics converge to the equilibrium of the quadratic program. The manuscript cites the foundational CDS results for these guarantees. We agree that an explicit illustration would strengthen the exposition and will add a small synthetic example in the revised Section 3 demonstrating the process on a toy graph. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's core construction builds a query-augmented affinity graph and applies Constrained Dominant Set selection via replicator dynamics. The three listed advantages (hard query constraint via cluster anchor, spectral bound for relevance-redundancy, and global equilibrium) are presented as direct consequences of standard CDS properties rather than derived predictions or fitted parameters. No equations or steps are shown that reduce the output selection to the input by construction, and the reported gains (37.1 / 4.8 points, 66.99 SOTA) are empirical benchmark results. The method is explicitly training-free and graph-based with no load-bearing self-citations or ansatzes invoked in the abstract. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mmlongbench-doc: Benchmarking long-context document understanding with visualizations
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations. Advances in Neural Information Processing Systems, 37:95963–96010, 2024
2024
-
[2]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[3]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models.arXiv preprint arXiv:2407.01449, 2024
Pith/arXiv arXiv 2024
-
[4]
Visdom: Multi-document qa with visually rich elements using multimodal retrieval-augmented generation
Manan Suri, Puneet Mathur, Franck Dernoncourt, Kanika Goswami, Ryan A Rossi, and Dinesh Manocha. Visdom: Multi-document qa with visually rich elements using multimodal retrieval-augmented generation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Vo...
2025
-
[5]
Vidorag: Visual document retrieval-augmented generation via dynamic iterative reasoning agents
Qiuchen Wang, Ruixue Ding, Zehui Chen, Weiqi Wu, Shihang Wang, Pengjun Xie, and Feng Zhao. Vidorag: Visual document retrieval-augmented generation via dynamic iterative reasoning agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9124–9145, 2025
2025
-
[6]
Xueyao Wan and Hang Yu. Mmgraphrag: Bridging vision and language with interpretable multimodal knowledge graphs.arXiv preprint arXiv:2507.20804, 2025
arXiv 2025
-
[7]
Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3), 2024
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3), 2024
Pith/arXiv arXiv 2024
-
[8]
Rag-anything: All-in-one rag framework
Zirui Guo, Xubin Ren, Lingrui Xu, Jiahao Zhang, and Chao Huang. Rag-anything: All-in-one rag framework. arXiv preprint arXiv:2510.12323, 2025
arXiv 2025
-
[9]
Thang Nguyen, Peter Chin, and Yu-Wing Tai. Ma-rag: Multi-agent retrieval-augmented generation via collabora- tive chain-of-thought reasoning.arXiv preprint arXiv:2505.20096, 2025
arXiv 2025
-
[10]
Yaxin Du, Junru Song, Yifan Zhou, Cheng Wang, Jiahao Gu, Zimeng Chen, Menglan Chen, Wen Yao, Yang Yang, Ying Wen, et al. g2-Reader: Dual Evolving Graphs for Multimodal Document Comprehension.arXiv preprint arXiv:2601.22055, 2026
arXiv 2026
-
[11]
The use of mmr, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, pages 335–336, 1998
1998
-
[12]
Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2-3):123–286, 2012
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2-3):123–286, 2012. 9 Constrained Dominant Sets for Multimodal Document Question AnsweringA PREPRINT
2012
-
[13]
Fast greedy map inference for determinantal point process to improve recommendation diversity.Advances in neural information processing systems, 31, 2018
Laming Chen, Guoxin Zhang, and Eric Zhou. Fast greedy map inference for determinantal point process to improve recommendation diversity.Advances in neural information processing systems, 31, 2018
2018
-
[14]
Near-optimal map inference for determinantal point processes
Jennifer Gillenwater, Alex Kulesza, and Ben Taskar. Near-optimal map inference for determinantal point processes. Advances in Neural Information Processing Systems, 25, 2012
2012
-
[15]
Dominant-set clustering: A review.European Journal of Operational Research, 262(1):1–13, 2017
Samuel Rota Bulò and Marcello Pelillo. Dominant-set clustering: A review.European Journal of Operational Research, 262(1):1–13, 2017
2017
-
[16]
Dominant sets and pairwise clustering.IEEE transactions on pattern analysis and machine intelligence, 29(1):167–172, 2007
Massimiliano Pavan and Marcello Pelillo. Dominant sets and pairwise clustering.IEEE transactions on pattern analysis and machine intelligence, 29(1):167–172, 2007
2007
-
[17]
Interactive image segmentation using constrained dominant sets
Eyasu Zemene and Marcello Pelillo. Interactive image segmentation using constrained dominant sets. InEuropean Conference on Computer Vision, pages 278–294. Springer, 2016
2016
-
[18]
constrained
Eyasu Zemene Zemene, Leulseged Tesfaye Alemu, and Marcello Pelillo. Dominant sets for “constrained” image segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(10):2438–2451, 2018
2018
-
[19]
Replicator equations, maximal cliques, and graph isomorphism.Advances in Neural Information Processing Systems, 11, 1998
Marcello Pelillo. Replicator equations, maximal cliques, and graph isomorphism.Advances in Neural Information Processing Systems, 11, 1998
1998
-
[20]
Evolution towards the maximum clique.Journal of Global Optimization, 10(2):143–164, 1997
Immanuel M Bomze. Evolution towards the maximum clique.Journal of Global Optimization, 10(2):143–164, 1997
1997
-
[21]
Leulseged Tesfaye Alemu and Marcello Pelillo. Multi-feature fusion for image retrieval using constrained dominant sets.Image and Vision Computing, 94:103862, 2020. ISSN 0262-8856. doi: https://doi.org/ 10.1016/j.imavis.2019.103862. URL https://www.sciencedirect.com/science/article/pii/ S026288561930455X
-
[22]
Deep constrained dominant sets for person re-identification
Leulseged Tesfaye Alemu, Marcello Pelillo, and Mubarak Shah. Deep constrained dominant sets for person re-identification. InProceedings of the IEEE/CVF international conference on computer vision, pages 9855–9864, 2019
2019
-
[23]
Multi-target tracking in multiple non-overlapping cameras using fast-constrained dominant sets.International Journal of Computer Vision, 127(9):1303–1320, 2019
Yonatan Tariku Tesfaye, Eyasu Zemene, Andrea Prati, Marcello Pelillo, and Mubarak Shah. Multi-target tracking in multiple non-overlapping cameras using fast-constrained dominant sets.International Journal of Computer Vision, 127(9):1303–1320, 2019
2019
-
[24]
Large-scale image geo-localization using dominant sets.IEEE transactions on pattern analysis and machine intelligence, 41(1):148–161, 2018
Eyasu Zemene, Yonatan Tariku Tesfaye, Haroon Idrees, Andrea Prati, Marcello Pelillo, and Mubarak Shah. Large-scale image geo-localization using dominant sets.IEEE transactions on pattern analysis and machine intelligence, 41(1):148–161, 2018
2018
-
[25]
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding.arXiv preprint arXiv:2411.04952, 2024
arXiv 2024
-
[26]
A-mem: Agentic memory for llm agents.Advances in Neural Information Processing Systems, 38:17577–17604, 2026
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.Advances in Neural Information Processing Systems, 38:17577–17604, 2026
2026
-
[27]
Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[28]
Unifying multimodal retrieval via document screenshot embedding
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin. Unifying multimodal retrieval via document screenshot embedding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6492–6505, 2024
2024
-
[29]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[30]
M-longdoc: A benchmark for multimodal super-long document understanding and a retrieval-aware tuning framework
Yew Ken Chia, Liying Cheng, Hou Pong Chan, Maojia Song, Chaoqun Liu, Mahani Aljunied, Soujanya Poria, and Lidong Bing. M-longdoc: A benchmark for multimodal super-long document understanding and a retrieval-aware tuning framework. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9244–9261, 2025
2025
-
[31]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021
2021
-
[32]
Hierarchical multimodal transformers for multipage docvqa.Pattern Recognition, 144:109834, 2023
Rubèn Tito, Dimosthenis Karatzas, and Ernest Valveny. Hierarchical multimodal transformers for multipage docvqa.Pattern Recognition, 144:109834, 2023
2023
-
[33]
Slidevqa: A dataset for document visual question answering on multiple images
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, and Kuniko Saito. Slidevqa: A dataset for document visual question answering on multiple images. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13636–13645, 2023. 10 Constrained Dominant Sets for Multimodal Document Question AnsweringA PREPRINT
2023
-
[34]
Spiqa: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807–118833, 2024
Shraman Pramanick, Rama Chellappa, and Subhashini Venugopalan. Spiqa: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807–118833, 2024
2024
-
[35]
Uda: A benchmark suite for retrieval augmented generation in real-world document analysis.Advances in Neural Information Processing Systems, 37:67200–67217, 2024
Yulong Hui, Yao Lu, and Huanchen Zhang. Uda: A benchmark suite for retrieval augmented generation in real-world document analysis.Advances in Neural Information Processing Systems, 37:67200–67217, 2024
2024
-
[36]
Fetaqa: Free-form table question answering.Transactions of the Association for Computational Linguistics, 10:35–49, 2022
Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kry´sci´nski, Hailey Schoelkopf, Riley Kong, Xiangru Tang, et al. Fetaqa: Free-form table question answering.Transactions of the Association for Computational Linguistics, 10:35–49, 2022
2022
-
[37]
Shengzhi Li and Nima Tajbakhsh. Scigraphqa: A large-scale synthetic multi-turn question-answering dataset for scientific graphs.arXiv preprint arXiv:2308.03349, 2023
arXiv 2023
-
[38]
Longdocurl: a comprehensive multimodal long document benchmark integrating understanding, reasoning, and locating
Chao Deng, Jiale Yuan, Pi Bu, Peijie Wang, Zhong-Zhi Li, Jian Xu, Xiao-Hui Li, Yuan Gao, Jun Song, Bo Zheng, et al. Longdocurl: a comprehensive multimodal long document benchmark integrating understanding, reasoning, and locating. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1135–...
2025
-
[39]
Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
Charles Packer, Vivian Fang, Shishir G Patil, Kevin Lin, Sarah Wooders, and Joseph E Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[40]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024
2024
-
[41]
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, et al. Mineru: An open-source solution for precise document content extraction.arXiv preprint arXiv:2409.18839, 2024
Pith/arXiv arXiv 2024
-
[42]
Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
Pith/arXiv arXiv 2025
-
[43]
Zach Nussbaum, John X Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder.arXiv preprint arXiv:2402.01613, 2024
Pith/arXiv arXiv 2024
-
[44]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[45]
k-dpps: Fixed-size determinantal point processes
Alex Kulesza and Ben Taskar. k-dpps: Fixed-size determinantal point processes. InProceedings of the 28th International Conference on Machine Learning (ICML-11), pages 1193–1200, 2011
2011
-
[46]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[47]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[48]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[49]
Glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv e-prints, pages arXiv–2507, 2025
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv e-prints, pages arXiv–2507, 2025
2025
-
[50]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611–626, 2023. 11 Constrained Dominant Sets for Multimodal Document Questio...
2023
-
[51]
Identifying the most salient keywords (focus on nouns, verbs, and key concepts)
-
[52]
Extracting core themes, concepts and arguments
-
[53]
keywords
Creating relevant categorical tags Format the response as a JSON object: { "keywords": [ // specific, distinct keywords, ordered most->least important; // at least three, avoid redundancy ], "summary": // one sentence: main topic/domain + key points; concise , "tags": [ // broad categories/themes (domain, format, type); >=3, non-redundant,→ ] } Content fo...
-
[54]
Base the summary primarily on the visual evidence and the caption
Use the context ONLY to aid understanding of the image's role; do not quote or rely on it unless it aligns with what is visible or stated in the caption. Base the summary primarily on the visual evidence and the caption
-
[55]
Keywords MUST include exact in-image terms: labels, legends, axis titles, category names, and domain-specific terms; preserve their exact wording
-
[56]
Figure 1
If the caption has an index (e.g., "Figure 1", "Table 2"), begin the summary by formalizing it ("Figure X -- ...", "Table Y -- ...") then describe concisely. Format the response as a JSON object: { "keywords": [ // exact in-image labels/legends/axis titles/terms; >=3, non-redundant ],,→ "summary": // start with "Figure X -- ..."/"Table Y -- ..." if indexe...
-
[57]
Which neighboring notes should be linked to this note?
-
[58]
Should this note's summary/keywords be updated given those relationships?
-
[59]
suggested_connections
If so, what are the new summary and keywords? 19 Constrained Dominant Sets for Multimodal Document Question AnsweringA PREPRINT Connect two notes ONLY for a specific logical relationship: direct reference, causal, part-whole, conceptual elaboration, temporal sequence, contrastive/comparative, hierarchical, or contextual dependency. DO NOT connect notes th...
-
[60]
Do not invent facts
Use ONLY the provided context. Do not invent facts
-
[61]
Quote table numbers, figure numbers, named entities, and numeric values exactly.,→
-
[62]
Not found in the provided context
If the answer is not in the context, reply exactly: "Not found in the provided context."
-
[63]
<reason>detailed reason for your answer here</reason> <answer>the correct answer here</answer>
Answer concisely. No preamble. [User] Question: {question} Context: --- Note 1 (id=.., weight=.., type=text|image) --- {text passage OR image caption/summary + <image>} --- Note 2 ... --- ... Answer: Prompt: Single-VLM Baseline (no retrieval, chain-of-thought) Please read the following text and the attached images and answer the question below.,→ <text> {...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.