Streaming Video Generation with Streaming Force Control
Pith reviewed 2026-06-27 22:13 UTC · model grok-4.3
The pith
StreamForce is a single causal model that generates video streams responding instantly to time-varying local and global forces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StreamForce is a causal and unified model that responds instantly and coherently to both local and global, time-varying forces by using a unified force representation as a control signal and a distillation pipeline for force-controllable video generation, sustaining stable photometric and dynamic realism at up to 16.6 FPS.
What carries the argument
The unified force representation as a control signal combined with the distillation pipeline that trains the causal autoregressive model.
If this is right
- Supports both local and global forces in a single model without separate training.
- Achieves state-of-the-art force adherence and motion realism in streaming settings.
- Enables real-time generation at up to 16.6 FPS on a single GPU.
- Maintains coherence for time-varying forces through causal processing.
Where Pith is reading between the lines
- The distillation approach may transfer to other control signals such as velocity or object position in video models.
- Interactive applications could apply user-driven forces directly to ongoing video generation.
- Causal force control might integrate with physics simulators for more precise long-term predictions.
Load-bearing premise
A single distilled model with a unified force representation can maintain photometric and dynamic realism across arbitrary time-varying local and global forces without the separate training or non-causal processing used in prior work.
What would settle it
Running the model on a long sequence with rapidly alternating or conflicting local and global forces and measuring whether generated motion deviates from the input forces or loses visual consistency compared to specialized non-causal baselines.
Figures

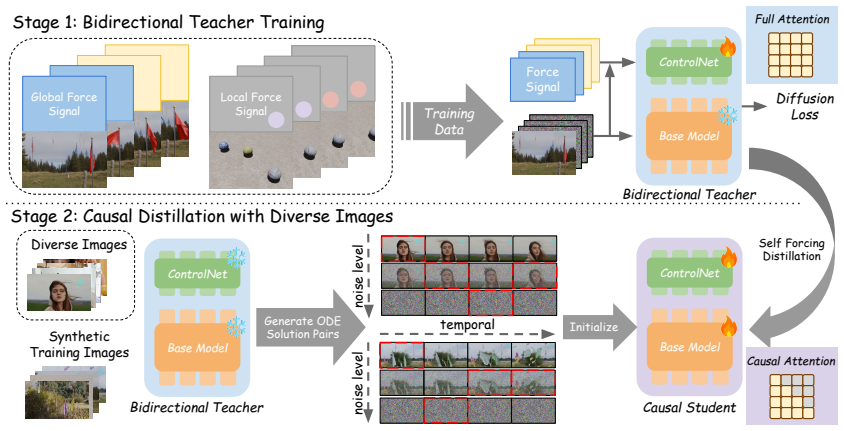

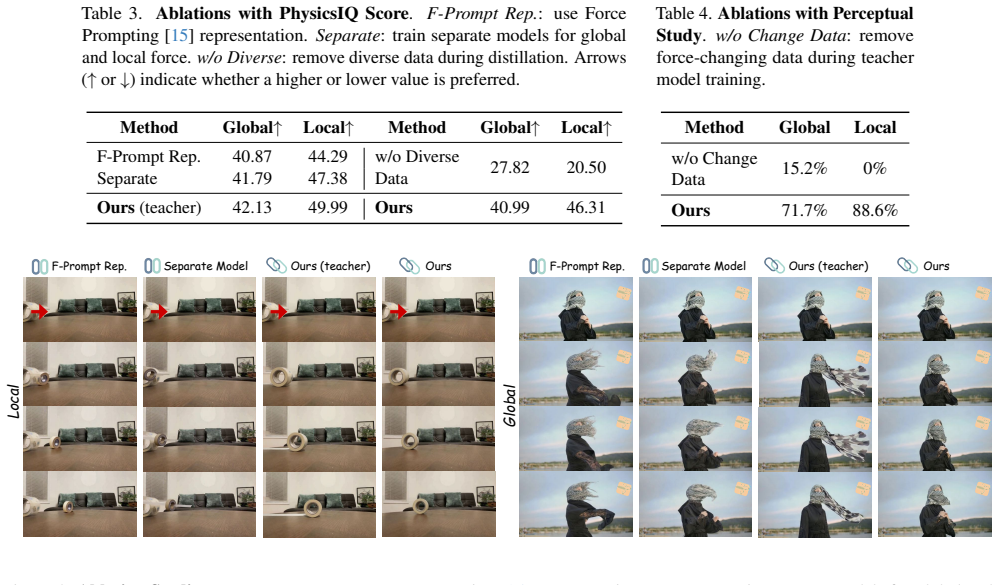




read the original abstract
We introduce StreamForce, a streaming video generation framework that enables physically grounded control through continuous force inputs. Unlike prior video models that train separate models for different force types, assume fixed forces, or rely on non-causal processing, StreamForce is a causal and unified model that responds instantly and coherently to both local and global, time-varying forces. To achieve this, we design a unified force representation as a control signal and develop a distillation pipeline for force-controllable video generation. Our model combines autoregressive efficiency with force responsiveness, sustaining stable photometric and dynamic realism. StreamForce runs at up to 16.6 FPS on a single GPU, achieving state-of-the-art performance in both force adherence and motion realism. Project website: https://neu-vi.github.io/StreamForce/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StreamForce, a streaming video generation framework for physically grounded control via continuous force inputs. It presents a causal unified model using a unified force representation and distillation pipeline that handles arbitrary local and global time-varying forces, combining autoregressive efficiency with force responsiveness while sustaining photometric and dynamic realism, and claims SOTA results in force adherence and motion realism at up to 16.6 FPS on a single GPU.
Significance. If supported by quantitative evidence in the full manuscript, the work would be significant for enabling real-time, causal force-controllable video synthesis in a single model, replacing the need for separate per-force-type models or non-causal processing used in prior work.
major comments (1)
- [Abstract] Abstract: the claim of 'achieving state-of-the-art performance in both force adherence and motion realism' together with the specific figure of 'up to 16.6 FPS' is presented without any quantitative metrics, baselines, error analysis, or comparison tables. This is load-bearing for the central claim of superiority and must be substantiated with concrete results from the full manuscript.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to address concerns about the substantiation of claims in the abstract. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'achieving state-of-the-art performance in both force adherence and motion realism' together with the specific figure of 'up to 16.6 FPS' is presented without any quantitative metrics, baselines, error analysis, or comparison tables. This is load-bearing for the central claim of superiority and must be substantiated with concrete results from the full manuscript.
Authors: We agree that the abstract, as currently written, summarizes the central claims at a high level without embedding specific metrics. The full manuscript substantiates these claims with quantitative results: Section 4 presents comparison tables against baselines for force adherence (using metrics such as force prediction error) and motion realism (via perceptual and dynamic consistency scores), along with runtime benchmarks confirming the 16.6 FPS figure on a single GPU. To address the concern directly, we will revise the abstract to incorporate key quantitative highlights and explicit references to the supporting tables and figures from the experiments section. revision: yes
Circularity Check
No significant circularity
full rationale
The abstract and description introduce StreamForce as a new causal unified model via a distillation pipeline for force-controllable video generation. No equations, fitted parameters, predictions, self-citations, uniqueness theorems, or ansatzes are presented that reduce any claimed result to its inputs by construction. The central claims rest on the proposed architecture and pipeline rather than any self-referential fitting or renaming of prior results. This is the most common honest finding for a methods paper whose derivation chain is not visible in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin- Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control.arXiv preprint arXiv:2407.12781, 2024. 3
arXiv 2024
-
[2]
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative ren- dering from a single video.arXiv preprint arXiv:2503.11647,
-
[3]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 18
Pith/arXiv arXiv 2025
-
[4]
Genie 3: A new frontier for world models, 2025
Philip J Ball, J Bauer, F Belletti, et al. Genie 3: A new frontier for world models, 2025. 2
2025
-
[5]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025. 2
2025
-
[6]
Simulation as an engine of physical scene understand- ing.Proceedings of the National Academy of Sciences, 110 (45):18327–18332, 2013
Peter W Battaglia, Jessica B Hamrick, and Joshua B Tenen- baum. Simulation as an engine of physical scene understand- ing.Proceedings of the National Academy of Sciences, 110 (45):18327–18332, 2013. 9
2013
-
[7]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2, 3
Pith/arXiv arXiv 2023
-
[8]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22563–22575, 2023. 2
2023
-
[9]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker- Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first Interna- tional Conference on Machine Learning, 2024. 3
2024
-
[10]
NeuMA: Neural material adaptor for visual grounding of intrinsic dynamics
Junyi Cao, Shanyan Guan, Yanhao Ge, Wei Li, Xiaokang Yang, and Chao Ma. NeuMA: Neural material adaptor for visual grounding of intrinsic dynamics. InThe Thirty-eighth Annual Conference on Neural Information Processing Sys- tems (NeurIPS), 2024. 3
2024
-
[11]
Physgen3d: Crafting a miniature interactive world from a single image
Boyuan Chen, Hanxiao Jiang, Shaowei Liu, Saurabh Gupta, Yunzhu Li, Hao Zhao, and Shenlong Wang. Physgen3d: Crafting a miniature interactive world from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6178–6189, 2025. 3
2025
-
[12]
Skyreels-a2: Compose anything in video diffusion transformers.arXiv preprint arXiv:2504.02436, 2025
Zhengcong Fei, Debang Li, Di Qiu, Jiahua Wang, Yikun Dou, Rui Wang, Jingtao Xu, Mingyuan Fan, Guibin Chen, Yang Li, et al. Skyreels-a2: Compose anything in video diffusion transformers.arXiv preprint arXiv:2504.02436, 2025. 3 10
arXiv 2025
-
[13]
Cat3d: Create anything in 3d with multi-view diffusion models.arXiv preprint arXiv:2405.10314, 2024
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models.arXiv preprint arXiv:2405.10314, 2024. 3
Pith/arXiv arXiv 2024
-
[14]
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, and Deqing Sun. Motion prompting: Controlling video generation with motion trajectories.arXiv preprint arXiv:2412.02700, 2024. 9
arXiv 2024
-
[15]
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force prompting: Video generation models can learn and gen- eralize physics-based control signals.arXiv preprint arXiv:2505.19386, 2025. 2, 3, 4, 5, 8, 16
arXiv 2025
-
[16]
Photorealistic video generation with diffusion models
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and José Lezama. Photorealistic video generation with diffusion models. In European Conference on Computer Vision, pages 393–411. Springer, 2024. 2, 3
2024
-
[17]
Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weiss- buch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024. 3
Pith/arXiv arXiv 2024
-
[18]
LTX-2: Efficient Joint Audio-Visual Foundation Model, 2026
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitter- man, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richard- son, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Sha- har Ar...
Pith/arXiv arXiv 2026
-
[19]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 2, 3
Pith/arXiv arXiv 2024
-
[20]
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source, real- time, and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025. 2
Pith/arXiv arXiv 2025
-
[21]
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022. 2
Pith/arXiv arXiv 2022
-
[22]
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video gen- eration via transformers.arXiv preprint arXiv:2205.15868,
-
[23]
Hao-Yu Hsu, Zhi-Hao Lin, Albert Zhai, Hongchi Xia, and Shenlong Wang. Autovfx: Physically realistic video edit- ing from natural language instructions.arXiv preprint arXiv:2411.02394, 2024. 3
arXiv 2024
-
[24]
Videomage: Multi-subject and motion customization of text-to-video dif- fusion models
Chi-Pin Huang, Yen-Siang Wu, Hung-Kai Chung, Kai-Po Chang, Fu-En Yang, and Yu-Chiang Frank Wang. Videomage: Multi-subject and motion customization of text-to-video dif- fusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17603–17612, 2025. 3
2025
-
[25]
Dreamphysics: Learning physical prop- erties of dynamic 3d gaussians with video diffusion priors
Tianyu Huang, Yihan Zeng, Hui Li, Wangmeng Zuo, and Rynson WH Lau. Dreamphysics: Learning physical prop- erties of dynamic 3d gaussians with video diffusion priors. arXiv preprint arXiv:2406.01476, 2024. 3
arXiv 2024
-
[26]
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autore- gressive video diffusion.arXiv preprint arXiv:2506.08009,
-
[27]
Phystwin: Physics-informed reconstruction and simulation of deformable objects from videos.ICCV, 2025
Hanxiao Jiang, Hao-Yu Hsu, Kaifeng Zhang, Hsin-Ni Yu, Shenlong Wang, and Yunzhu Li. Phystwin: Physics-informed reconstruction and simulation of deformable objects from videos.ICCV, 2025. 3
2025
-
[28]
Lifan Jiang, Shuang Chen, Boxi Wu, Xiaotong Guan, and Jiahui Zhang. Vidsketch: Hand-drawn sketch-driven video generation with diffusion control.arXiv preprint arXiv:2502.01101, 2025. 3
arXiv 2025
-
[29]
Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video generation.arXiv preprint arXiv:2312.14125, 2023. 3
Pith/arXiv arXiv 2023
-
[30]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2, 3
Pith/arXiv arXiv 2024
-
[31]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition.arXiv preprint arXiv:2506.17201, 2025. 2, 3
arXiv 2025
-
[32]
Wonderplay: Dynamic 3d scene generation from a single image and actions
Zizhang Li, Hong-Xing Yu, Wei Liu, Yin Yang, Charles Herrmann, Gordon Wetzstein, and Jiajun Wu. Wonderplay: Dynamic 3d scene generation from a single image and actions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9080–9090, 2025. 3
2025
-
[33]
Om- niphysGS: 3d constitutive gaussians for general physics-based dynamics generation
Yuchen Lin, Chenguo Lin, Jianjin Xu, and Yadong MU. Om- niphysGS: 3d constitutive gaussians for general physics-based dynamics generation. InThe Thirteenth International Confer- ence on Learning Representations, 2025. 3
2025
-
[34]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022. 5
Pith/arXiv arXiv 2022
-
[35]
Fangfu Liu, Hanyang Wang, Shunyu Yao, Shengjun Zhang, Jie Zhou, and Yueqi Duan. Physics3d: Learning physical properties of 3d gaussians via video diffusion.arXiv preprint arXiv:2406.04338, 2024. 3
arXiv 2024
-
[36]
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025. 2, 3, 20 11
Pith/arXiv arXiv 2025
-
[37]
Lijie Liu, Tianxiang Ma, Bingchuan Li, Zhuowei Chen, Jiawei Liu, Gen Li, Siyu Zhou, Qian He, and Xinglong Wu. Phantom: Subject-consistent video generation via cross- modal alignment.arXiv preprint arXiv:2502.11079, 2025. 3
arXiv 2025
-
[38]
Physgen: Rigid-body physics-grounded image-to- video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. Physgen: Rigid-body physics-grounded image-to- video generation. InEuropean Conference on Computer Vision, pages 360–378. Springer, 2024. 3
2024
-
[39]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 5
Pith/arXiv arXiv 2022
-
[40]
Xiaoyu Liu, Mingshuai Yao, Yabo Zhang, Xianhui Lin, Peiran Ren, Xiaoming Li, Ming Liu, and Wangmeng Zuo. Ani- mateanywhere: Rouse the background in human image ani- mation.arXiv preprint arXiv:2504.19834, 2025. 3
arXiv 2025
-
[41]
Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation.CVPR, 2025
Zhuoman Liu, Weicai Ye, Yan Luximon, Pengfei Wan, and Di Zhang. Unleashing the potential of multi-modal foundation models and video diffusion for 4d dynamic physical scene simulation.CVPR, 2025. 3
2025
-
[42]
Do generative video models understand physical principles?arXiv preprint arXiv:2501.09038, 2025
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles?arXiv preprint arXiv:2501.09038, 2025. 6, 7, 15
Pith/arXiv arXiv 2025
-
[43]
Optical-flow guided prompt optimization for coherent video generation
Hyelin Nam, Jaemin Kim, Dohun Lee, and Jong Chul Ye. Optical-flow guided prompt optimization for coherent video generation. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 7837–7846, 2025. 2
2025
-
[44]
Sora., 2024
OpenAI. Sora., 2024. 2, 3
2024
-
[45]
Yatian Pang, Bin Zhu, Bin Lin, Mingzhe Zheng, Francis EH Tay, Ser-Nam Lim, Harry Yang, and Li Yuan. Dreamdance: Animating human images by enriching 3d geometry cues from 2d poses.arXiv preprint arXiv:2412.00397, 2024. 3
arXiv 2024
-
[46]
Genie 2: A large-scale foundation world model,
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, Stephen Spencer, Jes- sica Yung, Michael Dennis, Sultan Kenjeyev, Shangbang Long, Vlad Mnih, Harris Chan, Maxime Gazeau, Bonnie Li, Fabio Pardo, Luyu Wang, Lei Zhang, Frederic Besse, Tim Harley, Ann...
-
[47]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[48]
Long-context state-space video world models.ICCV, 2025
Ryan Po, Yotam Nitzan, Richard Zhang, Berlin Chen, Tri Dao, Eli Shechtman, Gordon Wetzstein, and Xun Huang. Long-context state-space video world models.ICCV, 2025. 2
2025
-
[49]
Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih- Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
-
[50]
Language-driven physics-based scene synthesis and editing via feature splatting
Ri-Zhao Qiu, Ge Yang, Weijia Zeng, and Xiaolong Wang. Language-driven physics-based scene synthesis and editing via feature splatting. InEuropean Conference on Computer Vision (ECCV), 2024. 3
2024
-
[51]
Motionstream: Real-time video generation with interactive motion controls
Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, Jaesik Park, Eli Schechtman, and Xun Huang. Motionstream: Real-time video generation with interactive motion controls. arXiv preprint arXiv:2511.01266, 2025. 2, 3, 9
arXiv 2025
-
[52]
Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
-
[53]
Physmotion: Physics- grounded dynamics from a single image.arXiv preprint arXiv:2411.17189, 2024
Xiyang Tan, Ying Jiang, Xuan Li, Zeshun Zong, Tianyi Xie, Yin Yang, and Chenfanfu Jiang. Physmotion: Physics- grounded dynamics from a single image.arXiv preprint arXiv:2411.17189, 2024. 3
arXiv 2024
-
[54]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3, 5, 19
Pith/arXiv arXiv 2025
-
[55]
Chen Wang, Chuhao Chen, Yiming Huang, Zhiyang Dou, Yuan Liu, Jiatao Gu, and Lingjie Liu. Physctrl: Generative physics for controllable and physics-grounded video genera- tion.arXiv preprint arXiv:2509.20358, 2025. 3
arXiv 2025
-
[56]
Decoupledgaussian: Object-scene decoupling for physics-based interaction
Miaowei Wang, Yibo Zhang, Rui Ma, Weiwei Xu, Changqing Zou, and Daniel Morris. Decoupledgaussian: Object-scene decoupling for physics-based interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 3
2025
-
[57]
Yuqing Wang, Tianwei Xiong, Daquan Zhou, Zhijie Lin, Yang Zhao, Bingyi Kang, Jiashi Feng, and Xihui Liu. Loong: Gen- erating minute-level long videos with autoregressive language models.arXiv preprint arXiv:2410.02757, 2024. 3
arXiv 2024
-
[58]
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation,
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. MotionCtrl: A Unified and Flexible Motion Controller for Video Generation,
-
[59]
arXiv:2312.03641 null. 2
-
[60]
Scaling autoregressive video models.arXiv preprint arXiv:1906.02634, 2019
Dirk Weissenborn, Oscar Täckström, and Jakob Uszkor- eit. Scaling autoregressive video models.arXiv preprint arXiv:1906.02634, 2019. 3
arXiv 1906
-
[61]
Galileo: Perceiving physical object proper- ties by integrating a physics engine with deep learning
Jiajun Wu, Ilker Yildirim, Joseph J Lim, Bill Freeman, and Josh Tenenbaum. Galileo: Perceiving physical object proper- ties by integrating a physics engine with deep learning. InAd- vances in Neural Information Processing Systems (NeurIPS),
-
[62]
Physics 101: Learning physi- cal object properties from unlabeled videos
Jiajun Wu, Joseph J Lim, Hongyi Zhang, Joshua B Tenen- baum, and William T Freeman. Physics 101: Learning physi- cal object properties from unlabeled videos. InBritish Ma- chine Vision Conference (BMVC), 2016. 9
2016
-
[63]
Cat4d: Create anything in 4d with multi-view video diffusion models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 26057–26068, 2025. 3
2025
-
[64]
Video2game: Real-time, interactive, realistic and browser-compatible environment from a single video, 2024
Hongchi Xia, Zhi-Hao Lin, Wei-Chiu Ma, and Shenlong Wang. Video2game: Real-time, interactive, realistic and browser-compatible environment from a single video, 2024. 3 12
2024
-
[65]
Drawer: Digi- tal reconstruction and articulation with environment realism, 2025
Hongchi Xia, Entong Su, Marius Memmel, Arhan Jain, Ray- mond Yu, Numfor Mbiziwo-Tiapo, Ali Farhadi, Abhishek Gupta, Shenlong Wang, and Wei-Chiu Ma. Drawer: Digi- tal reconstruction and articulation with environment realism, 2025
2025
-
[66]
Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics- integrated 3d gaussians for generative dynamics.arXiv preprint arXiv:2311.12198, 2023
arXiv 2023
-
[67]
Physanimator: Physics-guided generative cartoon animation
Tianyi Xie, Yiwei Zhao, Ying Jiang, and Chenfanfu Jiang. Physanimator: Physics-guided generative cartoon animation. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 10793–10804, 2025. 3
2025
-
[68]
Yiming Xie, Chun-Han Yao, Vikram V oleti, Huaizu Jiang, and Varun Jampani. Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency.arXiv preprint arXiv:2407.17470, 2024. 2
arXiv 2024
-
[69]
Vid2sim: Realistic and interactive simulation from video for urban navigation.Preprint, 2024
Ziyang Xie, Zhizheng Liu, Zhenghao Peng, Wayne Wu, and Bolei Zhou. Vid2sim: Realistic and interactive simulation from video for urban navigation.Preprint, 2024. 3
2024
-
[70]
Tooncrafter: Gener- ative cartoon interpolation.ACM Transactions on Graphics (TOG), 43(6):1–11, 2024
Jinbo Xing, Hanyuan Liu, Menghan Xia, Yong Zhang, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Tooncrafter: Gener- ative cartoon interpolation.ACM Transactions on Graphics (TOG), 43(6):1–11, 2024. 3
2024
-
[71]
Motioncanvas: Cinematic shot design with controllable image-to-video generation
Jinbo Xing, Long Mai, Cusuh Ham, Jiahui Huang, Anirud- dha Mahapatra, Chi-Wing Fu, Tien-Tsin Wong, and Feng Liu. Motioncanvas: Cinematic shot design with controllable image-to-video generation. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–11, 2025. 3
2025
-
[72]
Videogpt: Video generation using vq-vae and transform- ers.arXiv preprint arXiv:2104.10157, 2021
Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srini- vas. Videogpt: Video generation using vq-vae and transform- ers.arXiv preprint arXiv:2104.10157, 2021. 3
Pith/arXiv arXiv 2021
-
[73]
Direct-a-video: Customized video generation with user- directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user- directed camera movement and object motion. InACM SIG- GRAPH 2024 Conference Papers, pages 1–12, 2024. 2, 3
2024
-
[74]
Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025. 3
Pith/arXiv arXiv 2025
-
[75]
Layeranimate: Layer-level control for animation
Yuxue Yang, Lue Fan, Zuzeng Lin, Feng Wang, and Zhaoxi- ang Zhang. Layeranimate: Layer-level control for animation. arXiv preprint arXiv:2501.08295, 2025. 3
arXiv 2025
-
[76]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2, 3
Pith/arXiv arXiv 2024
-
[77]
Yan: Foundational interactive video genera- tion.arXiv preprint arXiv:2508.08601, 2025
Deheng Ye, Fangyun Zhou, Jiacheng Lv, Jianqi Ma, Jun Zhang, Junyan Lv, Junyou Li, Minwen Deng, Mingyu Yang, Qiang Fu, et al. Yan: Foundational interactive video genera- tion.arXiv preprint arXiv:2508.08601, 2025. 2, 3
arXiv 2025
-
[78]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems, 37:47455– 47487, 2024. 3, 5, 20
2024
-
[79]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024. 3, 5, 20
2024
-
[80]
From slow bidirectional to fast autoregressive video diffusion mod- els
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Free- man, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion mod- els. InProceedings of the Computer Vision and Pattern Recog- nition Conference, pages 22963–22974, 2025. 2, 3, 5, 19
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.