Readable Yet Unpredictable: Rotated-Outcome Prediction in Vision-Language Models
Pith reviewed 2026-06-28 15:19 UTC · model grok-4.3
The pith
Vision-language models recognize rotated images when shown but fail to predict the rotated state from the original image alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
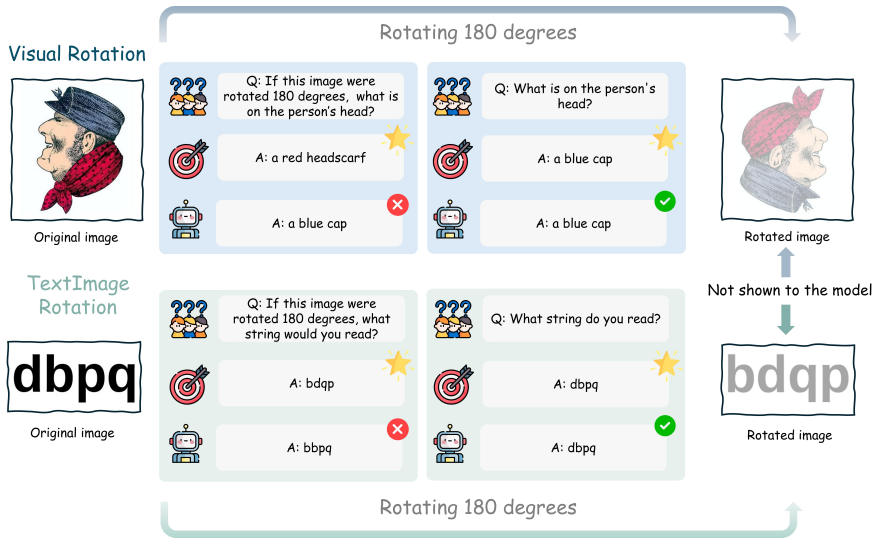
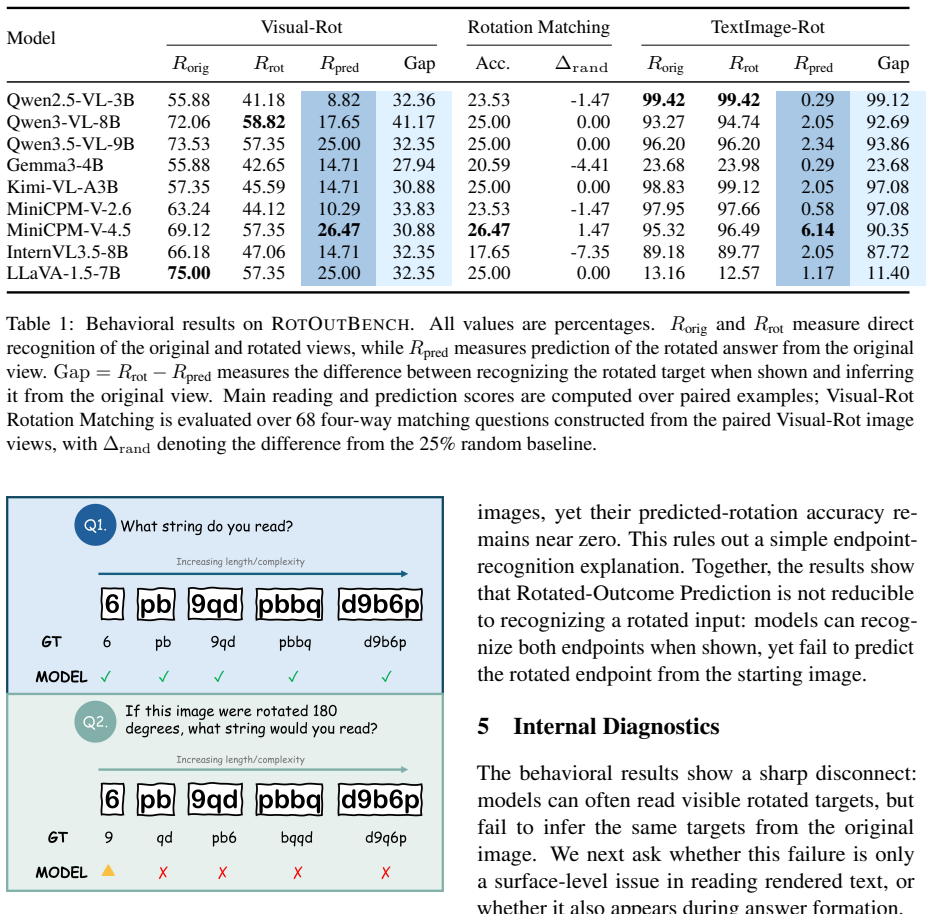
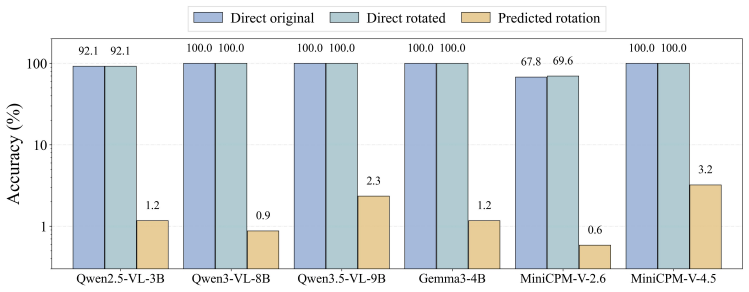
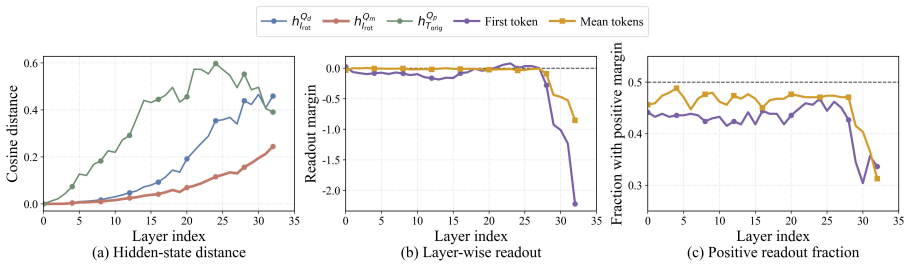
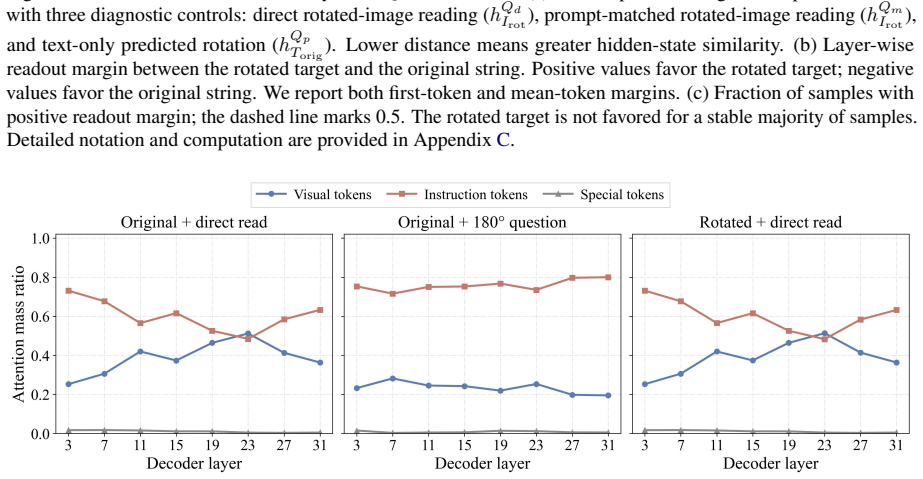
Current VLMs can recognize a transformed visual state when it is shown, but often fail to predict that state from the original view. On controlled text-image rotations in RotOutBench, predicted-rotation accuracy collapses to near zero even for models with high direct-reading accuracy. A model-level case study shows that the prediction state can approach a rotated-image reading state, while the final readout still shifts toward the original string.
What carries the argument
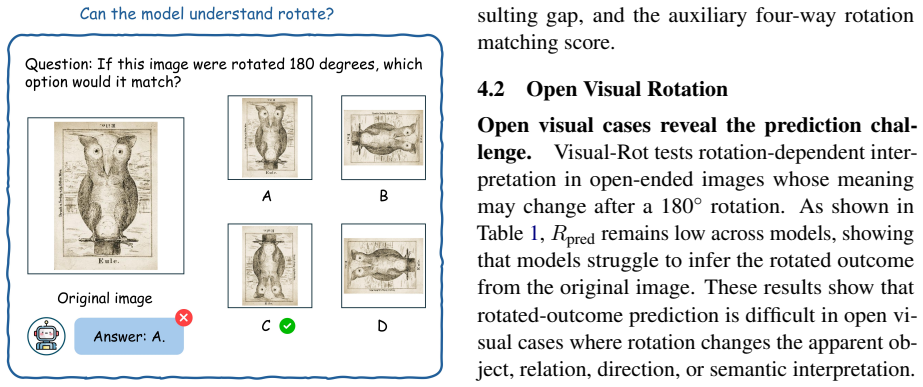
RotOutBench, a paired diagnostic benchmark that presents matched original and 180-degree rotated images to separate recognition from outcome prediction.
If this is right
- Prediction accuracy collapses to near zero on controlled text-image rotations despite high direct-reading performance.
- The internal prediction state approaches the rotated-image reading state, yet the final output readout reverts toward the original string.
- The failure appears across many current VLMs and holds for both open visual cases and text-specific rotations.
- Recognition of transformed content succeeds when the transformed image is provided directly, but the same transformation cannot be mentally applied from the original.
Where Pith is reading between the lines
- Architectures may need explicit mechanisms for simulating geometric transformations rather than relying on implicit pattern matching.
- Similar gaps could appear for other transformations such as scaling or reflection if tested with paired benchmarks.
- Training regimes that emphasize direct recognition may not automatically produce forward-simulation capabilities for visual changes.
Load-bearing premise
The paired design of the benchmark and the controlled rotations isolate prediction ability without being confounded by task misunderstanding, prompt effects, or orientation encoding differences.
What would settle it
A model achieving high accuracy on the rotated-outcome prediction tasks in RotOutBench while retaining high direct-recognition accuracy would falsify the central claim.
Figures

read the original abstract
Can vision-language models predict what a 180{\deg} rotation would reveal from the original image alone? We study this ability through Rotated-Outcome Prediction: given an original image, a model must answer what would be seen or read after a 180{\deg} in-plane rotation, without directly observing the rotated target. To isolate this gap, we introduce RotOutBench, a paired diagnostic benchmark spanning open visual cases and controlled text-image rotations. A sharp pattern emerges: many VLMs can recognize the relevant content when directly given either the original or rotated image, yet fail to infer the rotated result from the original image alone. On controlled text-image rotations, predicted-rotation accuracy collapses to near zero even for models with high direct-reading accuracy. A model-level case study further shows that the prediction state can approach a rotated-image reading state, while the final readout still shifts toward the original string. Current VLMs can recognize a transformed visual state when it is shown, but often fail to predict that state from the original view.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current vision-language models can recognize relevant content when directly shown either an original or 180°-rotated image, yet fail to predict the rotated outcome from the original image alone. This gap is isolated via the new paired benchmark RotOutBench, which includes open visual cases and controlled text-image rotations; on the latter, prediction accuracy collapses to near zero despite high direct-reading accuracy. A case study further indicates that internal states can approach rotated-image representations while the final output reverts toward the original string.
Significance. If the empirical pattern is robust, the result identifies a concrete limitation in VLMs' predictive visual reasoning, distinct from recognition. This could guide work on mental simulation and transformation-invariant reasoning; the paired benchmark design itself is a reusable diagnostic contribution.
major comments (2)
- [Benchmark and Experiments] Benchmark construction and evaluation protocol: the manuscript provides no dataset size, number of text-image pairs, sampling procedure, or statistical tests (e.g., confidence intervals or significance tests on the reported near-zero prediction accuracy). Without these, the strength of the central claim cannot be evaluated.
- [Experimental Design] Isolation of prediction from confounds: the paired design is asserted to isolate rotated-outcome prediction, yet no ablations, prompt-variation controls, or checks for task misunderstanding / orientation encoding differences are reported. This directly bears on whether the accuracy collapse reflects the claimed predictive deficit.
minor comments (1)
- [Abstract / Introduction] Model selection criteria and full list of evaluated VLMs are not stated in the abstract or early sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark reporting and experimental isolation. We address each major comment below and will incorporate the requested details and controls into the revised manuscript.
read point-by-point responses
-
Referee: [Benchmark and Experiments] Benchmark construction and evaluation protocol: the manuscript provides no dataset size, number of text-image pairs, sampling procedure, or statistical tests (e.g., confidence intervals or significance tests on the reported near-zero prediction accuracy). Without these, the strength of the central claim cannot be evaluated.
Authors: We agree that these details are necessary to evaluate the claims. The revised manuscript will report the full dataset size of RotOutBench, the exact number of text-image pairs in the controlled rotation subset, the sampling procedure (selection of text-containing images followed by 180° rotation pairing), and statistical analyses including confidence intervals and significance tests comparing direct-reading versus predicted-rotation accuracies. revision: yes
-
Referee: [Experimental Design] Isolation of prediction from confounds: the paired design is asserted to isolate rotated-outcome prediction, yet no ablations, prompt-variation controls, or checks for task misunderstanding / orientation encoding differences are reported. This directly bears on whether the accuracy collapse reflects the claimed predictive deficit.
Authors: We acknowledge that additional controls would strengthen the isolation argument. The revision will add prompt-variation ablations, explicit checks for task comprehension (e.g., direct queries about rotation understanding), and analysis of orientation encoding in internal states to rule out confounds and confirm that the observed collapse is attributable to the predictive deficit rather than other factors. revision: yes
Circularity Check
No significant circularity
full rationale
This paper presents an empirical benchmark study (RotOutBench) that contrasts direct recognition accuracy on original vs. rotated images against prediction accuracy from the original image alone. No mathematical derivation, fitted parameters, or load-bearing self-citation chain is present; the central claim is supported by direct experimental measurements on controlled text-image cases and is externally falsifiable via the benchmark itself. The analysis is self-contained against the introduced dataset and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716– 23736. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025a. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Shuai Bai, Keqin Chen, Xuej...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Gemma 3 technical re- port.Preprint, arXiv:2503.19786. Daniel Geng, Inbum Park, and Andrew Owens
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
InProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9161–9175
What’s “up” with vision-language models? investigat- ing their struggle with spatial reasoning. InProceed- ings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9161–9175. Kang-il Lee, Minbeom Kim, Seunghyun Yoon, Min- sung Kim, Dongryeol Lee, Hyukhun Koh, and Ky- omin Jung. 2025a. Vlind-bench: Measuring lan- guage priors ...
2023
-
[4]
In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 292–
Evaluating object hallucination in large vision-language models. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 292–
2023
-
[5]
InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045
Object hallu- cination in image captioning. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035–4045. Haz Sameen Shahgir, Khondker Salman Sayeed, Abhik Bhattacharjee, Wasi Uddin Ahmad, Yue Dong, and Rifat Shahriyar
2018
-
[6]
arXiv preprint arXiv:2403.15952
Illusionvqa: A challenging optical illusion dataset for vision language models. arXiv preprint arXiv:2403.15952. Takahiro Shirakawa and Seiichi Uchida
-
[7]
Mind the gap: Benchmarking spatial reasoning in vision-language models.arXiv preprint arXiv:2503.19707. Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, and 1 others
-
[8]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Vision Language Models are Biased
Vision language models are biased. arXiv preprint arXiv:2505.23941. 10 Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
In- ternvl3. 5: Advancing open-source multimodal mod- els in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265. Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800. Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, Bokai Xu, Junbo Cui, Yingjing Xu, Liqing Ruan, Luoyuan Zhang, Hanyu Liu, Jingkun Tang, Hongyuan Liu, Qining Guo, and 15 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe.Preprint, arXiv:2509.18154. Yichi Zhang, Jiayi Pan, Yuchen Zhou, Rui Pan, and Joyce Chai
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yiming Zhang, Zicheng Zhang, Xinyi Wei, Xiaohong Liu, Guangtao Zhai, and Xiongkuo Min
Grounding visual illusions in lan- guage: Do vision-language models perceive illusions like humans? InProceedings of the 2023 conference on empirical methods in natural language processing, pages 5718–5728. Yiming Zhang, Zicheng Zhang, Xinyi Wei, Xiaohong Liu, Guangtao Zhai, and Xiongkuo Min. 2025a. Illu- sionbench: A large-scale and comprehensive bench- ...
-
[14]
q”→target “b
For each model, we use its released checkpoint and the corresponding tokenizer and processor from the of- ficial or commonly used open-source implementa- tion. For models supported by VLMEvalKit (Duan et al., 2024), we use it for standardized inference; 15 the remaining models are evaluated with model- specific scripts under the same prompts, decod- ing s...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.