Diffusion Language Model Parallel Decoding via Product-of-Experts Bridge
Pith reviewed 2026-06-27 19:45 UTC · model grok-4.3
The pith
Product-of-Experts bridge enables diffusion language models to decode in parallel while recovering at least 95 percent of autoregressive model performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
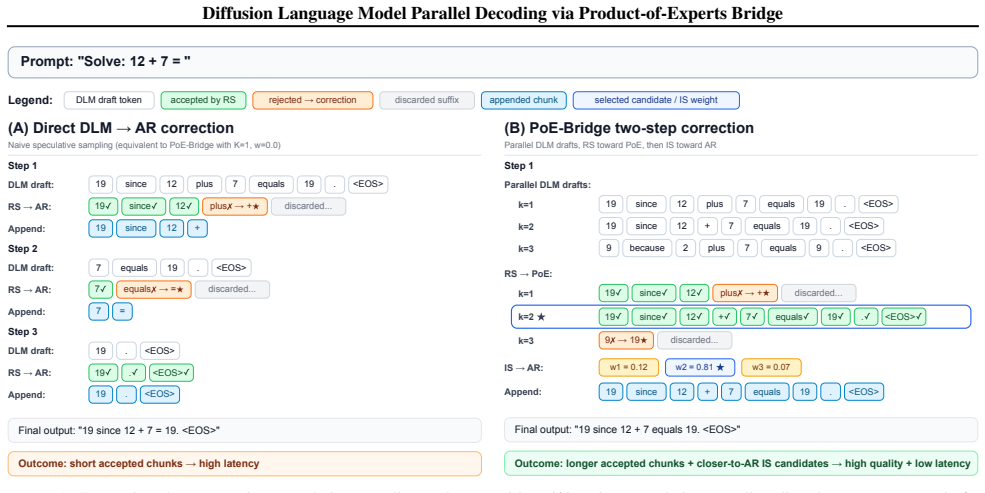
PoE-Bridge constructs an intermediate distribution as the product of experts from the DLM proposal and AR target. Multiple continuations are drafted in parallel using the DLM, rejection sampling verifies and shifts them toward the PoE, and importance sampling further aligns them with the AR target. Additional techniques include mixed-temperature sampling for diversity and elastic rejection windows to minimize wasted computation. This framework achieves significantly improved accuracy with a 5 times speedup over standard DLM decoding and recovers at least 95 percent of the target AR model's performance on challenging tasks.
What carries the argument
The intermediate Product-of-Experts distribution that serves as a bridge for rejection and importance sampling between the diffusion language model proposal and the autoregressive target.
If this is right
- Parallel decoding with the PoE bridge advances most of the quality gap to autoregressive models on math and coding.
- The method maintains efficiency while improving accuracy through the two-stage sampling correction.
- Mixed-temperature sampling increases output diversity without sacrificing the performance gains.
- Elastic rejection windows reduce the computational waste in verification steps.
Where Pith is reading between the lines
- The approach may apply to other generative model pairs where one is fast but approximate and the other is accurate but sequential.
- It could influence the design of hybrid decoding algorithms for future large language models balancing speed and quality.
- Empirical results on specific tasks suggest potential for broader application if the sampling efficiency holds across domains.
Load-bearing premise
An intermediate Product-of-Experts distribution from the DLM proposal and AR target can be sampled efficiently via rejection-plus-importance procedures without needing too many particles or introducing bias that blocks recovery of AR performance.
What would settle it
Observing that the rejection sampling step requires a number of particles that makes the overall computation slower than standard autoregressive decoding, or that the generated outputs fall short of 95 percent AR performance recovery on the mathematical reasoning and coding benchmarks.
Figures
read the original abstract
Diffusion language models (DLMs) offer substantial speed advantages through parallel decoding, but the lack of token dependencies limits generation quality compared to autoregressive (AR) models. Recent progress attempts to bridge the gap via importance sampling, with DLM being the proposal and AR being the target. However, due to the huge gap between their distributions, the sampling requires a large number of particles and is thus expensive to compute. In this paper, we introduce PoE-Bridge, a novel decoding framework that drastically improves generation speed and accuracy by introducing an intermediate distribution to bridge the gap. The distribution is constructed as a Product-of-Experts (PoE) of the DLM proposal and the AR target. With the intermediate distribution, we first use the DLM to draft multiple continuations in parallel, then apply rejection sampling to verify the drafted tokens and move the resulting candidates toward the PoE. We then use importance sampling to further correct the PoE-aligned candidates toward the AR target. We further propose several improved techniques, including mixed-temperature sampling for enhanced diversity and elastic rejection windows for reducing wasted verification. Empirically, PoE-Bridge achieves significantly improved accuracy with $5\times$ speedup over the standard DLM decoding approach, and recovers at least 95% of the target AR model's performance, efficiently advancing most of the quality gap on challenging mathematical reasoning and coding tasks. Our code is available at https://github.com/juntongshi48/poe-bridge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PoE-Bridge, a decoding framework for diffusion language models that constructs an intermediate Product-of-Experts distribution from the DLM proposal and AR target. It uses parallel DLM drafting, followed by rejection sampling to align candidates with the PoE and importance sampling to correct toward the AR target, augmented by mixed-temperature sampling and elastic rejection windows. The central empirical claim is a 5× speedup over standard DLM decoding while recovering at least 95% of AR model performance on mathematical reasoning and coding tasks.
Significance. If the sampling procedure can be shown to achieve the claimed recovery without prohibitive particle counts or uncontrolled bias, the work would meaningfully advance parallel decoding by narrowing the quality gap between fast DLMs and slower AR models. Code availability is a strength that aids reproducibility.
major comments (3)
- [Abstract] Abstract: the claim that the two-stage rejection-plus-importance procedure recovers ≥95% of AR performance rests on the assumption that the PoE intermediate can be sampled efficiently; no particle counts, effective sample sizes, or importance-weight variance are reported, leaving open whether the procedure avoids the 'large number of particles' problem explicitly noted for standard importance sampling.
- [§3.2] §3.2 (PoE sampling procedure): the rejection step that 'moves the resulting candidates toward the PoE' followed by importance correction to the AR target is load-bearing for both the speedup and accuracy claims, yet the manuscript supplies no analysis of acceptance rates, residual bias after the second stage, or how the mixed-temperature parameters affect weight variance.
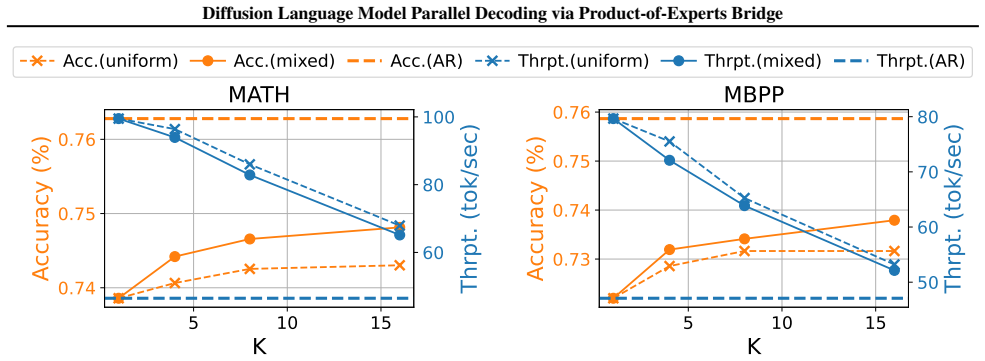
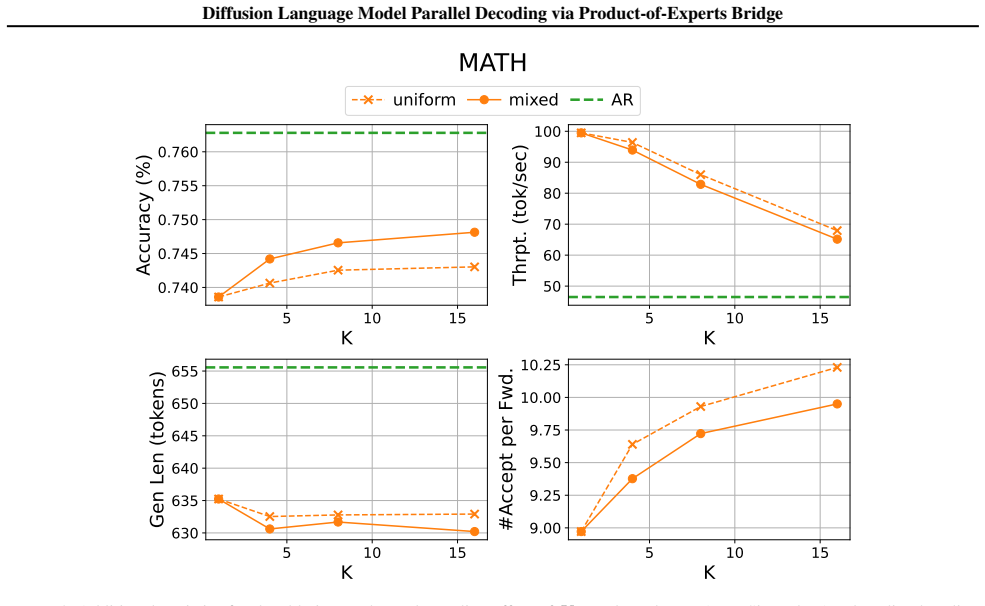
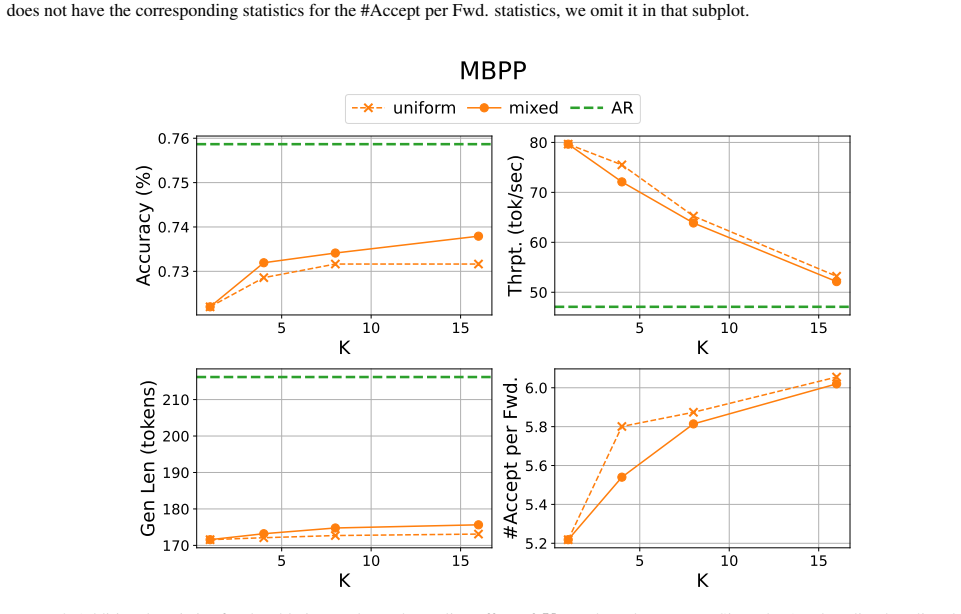
- [§4] §4 (Experiments): the headline numbers (5× speedup, 95% recovery) are presented without ablations isolating the contribution of the PoE bridge versus the auxiliary techniques, without statistical significance tests, and without error analysis on the mathematical-reasoning and coding tasks, making it impossible to verify that the central claim holds.
minor comments (2)
- The abstract states that code is available but does not indicate the license or whether the released repository contains the exact experimental configurations used for the reported numbers.
- [§3] Notation for the PoE distribution p_PoE(x) = p_DLM(x) · p_AR(x) / Z is introduced without an explicit normalizing-constant discussion or reference to how Z is handled in the rejection and importance steps.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our sampling procedure and experimental validation. We address each major comment below and commit to revisions that will strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the two-stage rejection-plus-importance procedure recovers ≥95% of AR performance rests on the assumption that the PoE intermediate can be sampled efficiently; no particle counts, effective sample sizes, or importance-weight variance are reported, leaving open whether the procedure avoids the 'large number of particles' problem explicitly noted for standard importance sampling.
Authors: We agree that these efficiency metrics are necessary to substantiate the claim. In the revised manuscript we will report the number of particles used, effective sample sizes, and importance-weight variance for the math and coding experiments, directly comparing them to the direct importance-sampling baseline to show that the PoE bridge materially reduces the particle requirement. revision: yes
-
Referee: [§3.2] §3.2 (PoE sampling procedure): the rejection step that 'moves the resulting candidates toward the PoE' followed by importance correction to the AR target is load-bearing for both the speedup and accuracy claims, yet the manuscript supplies no analysis of acceptance rates, residual bias after the second stage, or how the mixed-temperature parameters affect weight variance.
Authors: We acknowledge the absence of this analysis. Section 3.2 will be expanded with (i) empirical acceptance rates for the rejection step, (ii) an assessment of residual bias after the importance-sampling correction, and (iii) an ablation of mixed-temperature settings and their effect on weight variance. These additions will quantify the contribution of each stage. revision: yes
-
Referee: [§4] §4 (Experiments): the headline numbers (5× speedup, 95% recovery) are presented without ablations isolating the contribution of the PoE bridge versus the auxiliary techniques, without statistical significance tests, and without error analysis on the mathematical-reasoning and coding tasks, making it impossible to verify that the central claim holds.
Authors: We agree that the experimental section requires greater rigor. The revised §4 will include (a) ablations that isolate the PoE bridge from mixed-temperature sampling and elastic rejection windows, (b) statistical significance tests (paired t-tests across seeds), and (c) per-task error bars or variance across runs. These changes will allow readers to verify the reported speed-up and recovery figures. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces PoE-Bridge as a new intermediate distribution (DLM proposal × AR target) and describes a two-stage correction (rejection sampling followed by importance sampling) plus auxiliary techniques such as mixed-temperature sampling. No equation or claim reduces by construction to a fitted parameter renamed as a prediction, nor does any load-bearing step rely on a self-citation chain whose cited result is itself unverified. The performance numbers are presented as empirical outcomes of the sampling procedure rather than algebraic identities; the central assumption (efficient sampling from the PoE without prohibitive particle counts or uncontrolled bias) is stated explicitly and left open to external verification via the released code. The derivation therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- mixed-temperature sampling parameters
axioms (1)
- standard math Rejection sampling and importance sampling can be applied sequentially to move samples from the DLM proposal through the PoE toward the AR target without prohibitive variance.
invented entities (1)
-
Product-of-Experts bridge distribution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[2]
2024 , eprint=
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement , author=. 2024 , eprint=
2024
-
[3]
2024 , eprint=
Qwen2.5-Coder Technical Report , author=. 2024 , eprint=
2024
-
[4]
arXiv preprint arXiv:2108.07732 , year=
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[5]
2025 , eprint=
Dream 7B: Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[6]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[7]
arXiv preprint arXiv:2103.03874 , year=
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
-
[8]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[9]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Large Language Diffusion Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[10]
Accelerating Diffusion
Daniel Mingyi Israel and Guy Van den Broeck and Aditya Grover , booktitle=. Accelerating Diffusion. 2025 , url=
2025
-
[11]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Simple and Effective Masked Diffusion Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[12]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[13]
Advances in Neural Information Processing Systems , editor=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[14]
Advances in Neural Information Processing Systems , editor=
A Continuous Time Framework for Discrete Denoising Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[15]
2024 , url=
Discrete Diffusion Language Modeling by Estimating the Ratios of the Data Distribution , author=. 2024 , url=
2024
-
[16]
Veach, Eric and Guibas, Leonidas J. , title =. 1995 , isbn =. doi:10.1145/218380.218498 , booktitle =
-
[17]
Artificial Neural Networks, 1999
Products of experts , author =. Artificial Neural Networks, 1999. ICANN 99. Ninth International Conference on (Conf. Publ. No. 470) , volume =. 1999 , organization =
1999
-
[18]
doi:10.5281/zenodo.10256836 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[19]
2025 , eprint=
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation , author=. 2025 , eprint=
2025
-
[20]
2023 , eprint=
Accelerating Large Language Model Decoding with Speculative Sampling , author=. 2023 , eprint=
2023
-
[21]
Proceedings of the 40th International Conference on Machine Learning , pages =
Fast Inference from Transformers via Speculative Decoding , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[22]
The Thirteenth International Conference on Learning Representations , year=
Energy-Based Diffusion Language Models for Text Generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
The Thirteenth International Conference on Learning Representations , year=
Faster Cascades via Speculative Decoding , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
and Ben-Nun, Tal and Cardei, Michael and Kailkhura, Bhavya and Fioretto, Ferdinando
Christopher, Jacob K and Bartoldson, Brian R. and Ben-Nun, Tal and Cardei, Michael and Kailkhura, Bhavya and Fioretto, Ferdinando. Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Tec...
-
[25]
2025 , eprint=
Reviving Any-Subset Autoregressive Models with Principled Parallel Sampling and Speculative Decoding , author=. 2025 , eprint=
2025
-
[26]
2024 , eprint=
ParallelSpec: Parallel Drafter for Efficient Speculative Decoding , author=. 2024 , eprint=
2024
-
[27]
International Conference on Learning Representations , year=
Non-Autoregressive Neural Machine Translation , author=. International Conference on Learning Representations , year=
-
[28]
Mask-Predict: Parallel Decoding of Conditional Masked Language Models , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
2019
-
[29]
International Conference on Learning Representations , year=
Step-unrolled Denoising Autoencoders for Text Generation , author=. International Conference on Learning Representations , year=
-
[30]
arXiv preprint arXiv:2302.05737 , year=
A reparameterized discrete diffusion model for text generation , author=. arXiv preprint arXiv:2302.05737 , year=
-
[31]
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade , author=. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages=
2021
-
[32]
NIPS , year=
Attention is All you Need , author=. NIPS , year=
-
[33]
Transformers: State-of-the-Art Natural Language Processing
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[34]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[35]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[36]
Nature , volume=
Solving olympiad geometry without human demonstrations , author=. Nature , volume=. 2024 , publisher=
2024
-
[37]
arXiv preprint arXiv:2308.12950 , year=
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
-
[38]
Accelerating
Nadav Timor and Jonathan Mamou and Daniel Korat and Moshe Berchansky and Gaurav Jain and Oren Pereg and Moshe Wasserblat and David Harel , booktitle=. Accelerating. 2025 , url=
2025
-
[39]
2025 , eprint=
TiDAR: Think in Diffusion, Talk in Autoregression , author=. 2025 , eprint=
2025
-
[40]
The Fourteenth International Conference on Learning Representations , year=
Speculative Speculative Decoding , author=. The Fourteenth International Conference on Learning Representations , year=
-
[41]
Luc Devroye , title =. 1986 , edition =. doi:10.1007/978-1-4613-8643-8 , pages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.