TLRD: Teaching LLMs to Reason over Tabular Data with Tri-Level Rationale Distillation
Pith reviewed 2026-06-27 19:35 UTC · model grok-4.3
The pith
Tri-level rationale distillation lets LLMs close the gap with tree ensembles on tabular data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that distilling a rationale corpus grounded in three complementary levels of evidence from a teacher model into student LLMs enables zero-overhead prediction and grounded explanation from raw features only, significantly closing the performance gap between LLMs and state-of-the-art tree ensembles on multiple domain datasets.
What carries the argument
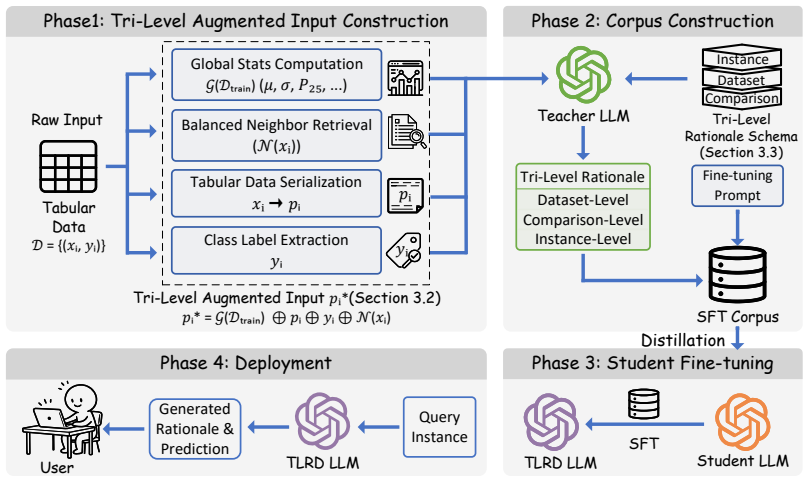
Tri-Level Rationale Distillation (TLRD), which synthesizes and transfers rationales at instance-level feature, dataset-level distributional context, and comparison-level retrieved neighbors to supervise LLM training.
If this is right
- LLMs achieve predictive performance close to state-of-the-art tree ensembles while adding readable explanations.
- Student models generate both predictions and explanations from raw features with no extra inference cost.
- The approach supplies case-specific references useful for high-stakes tabular decision-making.
- Label-only fine-tuning is replaced by structured rationale supervision that avoids catastrophic forgetting.
Where Pith is reading between the lines
- The same tri-level structure could be tested on other structured inputs such as time-series or graph data.
- Rationale quality could be measured by alignment with known causal mechanisms in the domain.
- The method might allow smaller LLMs to retain tabular competence across multiple downstream tasks.
Load-bearing premise
The high-capacity teacher model can reliably synthesize accurate non-misleading rationales at the three levels that transfer to student models without introducing harmful biases or noise.
What would settle it
An experiment in which TLRD-trained student models show no accuracy gain over label-only fine-tuned LLMs or produce explanations that contradict the actual feature contributions on held-out tabular data.
Figures


read the original abstract
Tabular data is a primary medium for storing real-world information, driving many industrial applications of machine learning. Traditional predictors achieve strong predictive performance but do not provide readable, case-specific explanations essential for decision-making. Large Language Models (LLMs) can naturally bridge this gap by generating predictions alongside explanations. However, dataset-specific patterns, such as feature distributions and interactions, make tabular data difficult for LLMs to understand and reason over, while label-only fine-tuning improves performance at the cost of catastrophic forgetting. To address this problem, we propose Tri-Level Rationale Distillation (TLRD), a framework that converts label-only tabular datasets into structured rationale supervision for LLMs. TLRD uses a high-capacity teacher to synthesize a rationale corpus grounded in three complementary levels of evidence: instance-level feature, dataset-level distributional context, and comparison-level retrieved neighbors, then distills the rationale into student LLMs, enabling zero-overhead prediction and grounded explanation from raw features only. Experiments on multiple domain datasets show that TLRD significantly closes the performance gap between LLMs and state-of-the-art tree ensembles while producing grounded and readable explanations, offering a valuable reference for high-stakes decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tri-Level Rationale Distillation (TLRD), in which a high-capacity teacher LLM synthesizes a rationale corpus for tabular datasets at three levels (instance-level feature attributions, dataset-level distributional context, and comparison-level neighbor retrieval) via prompting; this corpus is then distilled into student LLMs so that the students can produce both predictions and grounded explanations directly from raw features, closing the performance gap with tree ensembles while avoiding catastrophic forgetting from label-only fine-tuning.
Significance. If the central claim holds, TLRD would offer a practical route to equip LLMs with both competitive tabular performance and human-readable, multi-level explanations, addressing a long-standing limitation of LLMs on structured data and providing a reference method for high-stakes tabular applications where tree ensembles currently dominate.
major comments (1)
- [Section 3] Section 3: The method relies on the teacher LLM producing accurate, non-misleading rationales at all three levels, yet the description of rationale synthesis contains no human evaluation, ground-truth comparison against known feature importances, consistency checks across levels, or ablation on rationale quality. Because any systematic errors or hallucinations in the teacher rationales would be directly transferred to the student, the reported performance gains relative to tree ensembles cannot be confidently attributed to genuine reasoning improvement rather than spurious distillation.
minor comments (1)
- The abstract states that experiments were run on 'multiple domain datasets' but supplies no dataset names, sizes, or baseline details; these should be added to the abstract or a dedicated experimental-setup paragraph for reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the teacher-generated rationales. We address the concern point by point below.
read point-by-point responses
-
Referee: [Section 3] Section 3: The method relies on the teacher LLM producing accurate, non-misleading rationales at all three levels, yet the description of rationale synthesis contains no human evaluation, ground-truth comparison against known feature importances, consistency checks across levels, or ablation on rationale quality. Because any systematic errors or hallucinations in the teacher rationales would be directly transferred to the student, the reported performance gains relative to tree ensembles cannot be confidently attributed to genuine reasoning improvement rather than spurious distillation.
Authors: We agree that the absence of direct validation for the synthesized rationales is a limitation in the current manuscript. The performance improvements are demonstrated through end-to-end comparisons with tree ensembles and other baselines, but without explicit checks on rationale fidelity it is difficult to fully rule out spurious effects. In the revision we will add: (1) a human evaluation study on a random sample of 200 rationales across the three levels, with inter-annotator agreement; (2) consistency checks measuring agreement between instance-level attributions, dataset-level statistics, and neighbor comparisons; (3) an ablation that replaces teacher rationales with random or label-only text to quantify their contribution; and (4) experiments on two synthetic tabular datasets where ground-truth feature importances are known by construction. These additions will be placed in a new subsection of Section 3 and reported in the experimental results. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes TLRD as an empirical distillation pipeline: a high-capacity teacher LLM synthesizes tri-level rationales (instance, distributional, neighbor) via prompting, which are then used to fine-tune student LLMs. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear. The method is a standard teacher-student transfer setup whose performance claims rest on experimental results rather than any reduction of outputs to inputs by construction. The absence of mathematical structure makes the enumerated circularity patterns inapplicable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Finben: A holistic financial benchmark for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2512.13040 , year=
Understanding Structured Financial Data with LLMs: A Case Study on Fraud Detection , author=. arXiv preprint arXiv:2512.13040 , year=
-
[3]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
MedAssist: LLM-empowered medical assistant for assisting the Scrutinization and comprehension of electronic health records , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[4]
Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pages=
Xgboost: A scalable tree boosting system , author=. Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pages=
-
[5]
Advances in neural information processing systems , volume=
Lightgbm: A highly efficient gradient boosting decision tree , author=. Advances in neural information processing systems , volume=
-
[6]
Prokhorenkova, Liudmila and Gusev, Gleb and Vorobev, Aleksandr and Dorogush, Anna Veronika and Gulin, Andrey , journal=. Cat
-
[7]
Hegselmann, Stefan and Buendia, Alejandro and Lang, Hunter and Agrawal, Monica and Jiang, Xiaoyi and Sontag, David , booktitle =. Tab. 2023 , editor =
2023
-
[8]
International Conference on Intelligent Computing , pages=
Leveraging Large Language Models for Early Diagnosis of Inherited Metabolic Diseases Evaluation and Optimization , author=. International Conference on Intelligent Computing , pages=. 2025 , organization=
2025
-
[9]
arXiv preprint arXiv:2310.03266 , year=
Unipredict: Large language models are universal tabular classifiers , author=. arXiv preprint arXiv:2310.03266 , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Large scale transfer learning for tabular data via language modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Structgpt: A general framework for large language model to reason over structured data , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[12]
Utilizing Training Data to Improve
Gao, Chufan and Chen, Jintai and Sun, Jimeng , journal=. Utilizing Training Data to Improve
-
[13]
Schindler, G. Tab. arXiv preprint arXiv:2511.03570 , year=
-
[14]
An efficient retrieval-based method for tabular prediction with
Wu, Jie and Hou, Mengshu , booktitle=. An efficient retrieval-based method for tabular prediction with
-
[15]
1996 , howpublished =
Becker, Barry and Kohavi, Ronny , title =. 1996 , howpublished =
1996
-
[16]
2018 , howpublished =
Anna Montoya and inversion and KirillOdintsov and Martin Kotek , title =. 2018 , howpublished =
2018
-
[17]
Journal of Statistics Education , volume=
OkCupid data for introductory statistics and data science courses , author=. Journal of Statistics Education , volume=. 2015 , publisher=
2015
-
[18]
2019 , publisher=
ggplot2: elegant graphics for data analysis , author=. 2019 , publisher=
2019
-
[19]
R. Sparse spatial autoregressions , journal =. 1997 , issn =. doi:https://doi.org/10.1016/S0167-7152(96)00140-X , url =
-
[20]
Information fusion , volume=
Tabular data: Deep learning is not all you need , author=. Information fusion , volume=. 2022 , publisher=
2022
-
[21]
Advances in neural information processing systems , volume=
Why do tree-based models still outperform deep learning on typical tabular data? , author=. Advances in neural information processing systems , volume=
-
[22]
Noah Hollmann and Samuel M. Tab. The Eleventh International Conference on Learning Representations , year=
-
[23]
Yury Gorishniy and Akim Kotelnikov and Artem Babenko , booktitle=. Tab. 2025 , url=
2025
-
[24]
Forty-second International Conference on Machine Learning , year=
Are Large Language Models Ready for Multi-Turn Tabular Data Analysis? , author=. Forty-second International Conference on Machine Learning , year=
-
[25]
How well do
Wolff, Cornelius and Hulsebos, Madelon , booktitle=. How well do
-
[26]
Beyond Labels: Explanatory Collapse due to Instruction Tuning in Protein
Yang, Yining and Huang, Ruihong and Shen, Yang , booktitle=. Beyond Labels: Explanatory Collapse due to Instruction Tuning in Protein
-
[27]
IEEE Transactions on Audio, Speech and Language Processing , year=
An empirical study of catastrophic forgetting in large language models during continual fine-tuning , author=. IEEE Transactions on Audio, Speech and Language Processing , year=
-
[28]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[29]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[30]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Teaching small language models to reason , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[31]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
-
[32]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[33]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[34]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[35]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[36]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[37]
Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Optuna: A next-generation hyperparameter optimization framework , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[38]
Nick Erickson and Lennart Purucker and Andrej Tschalzev and David Holzm. Tab. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[39]
BioMed research international , volume=
Impact of HbA1c measurement on hospital readmission rates: analysis of 70,000 clinical database patient records , author=. BioMed research international , volume=. 2014 , publisher=
2014
-
[40]
Yi-Siang Wang and Kuan-Yu Chen and Yu-Chen Den and Darby Tien-Hao Chang , year=. Boost. 2605.06117 , archivePrefix=
-
[41]
Hase, Peter and Zhang, Shiyue and Xie, Harry and Bansal, Mohit. Leakage-Adjusted Simulatability: Can Models Generate Non-Trivial Explanations of Their Behavior in Natural Language?. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.390
-
[42]
G raph N arrator: Generating Textual Explanations for Graph Neural Networks
Pan, Bo and Xiong, Zhen and Wu, Guanchen and Zhang, Zheng and Zhang, Yifei and Hu, Yuntong and Zhao, Liang. G raph N arrator: Generating Textual Explanations for Graph Neural Networks. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.2
-
[43]
SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models
Manakul, Potsawee and Liusie, Adian and Gales, Mark. S elf C heck GPT : Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.557
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.