Few-step Cofolding with All-Atom Flow Maps
Pith reviewed 2026-06-27 18:37 UTC · model grok-4.3
The pith
DeCAF distills all-atom cofolding diffusion models into flow maps that match teacher accuracy with 5x fewer inference steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
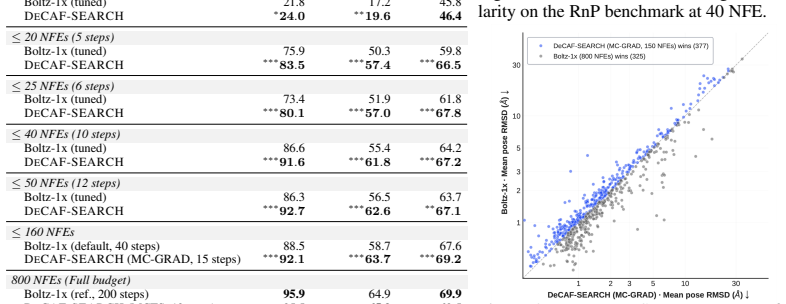
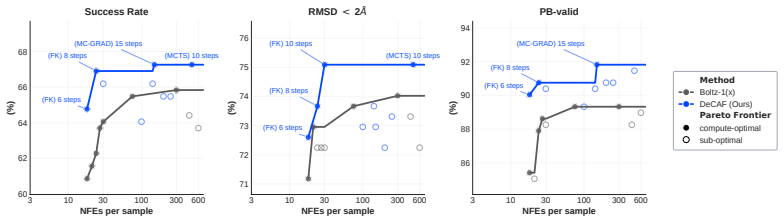
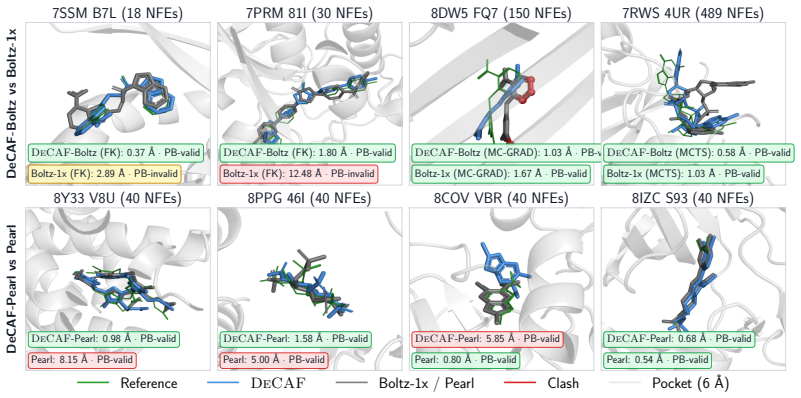
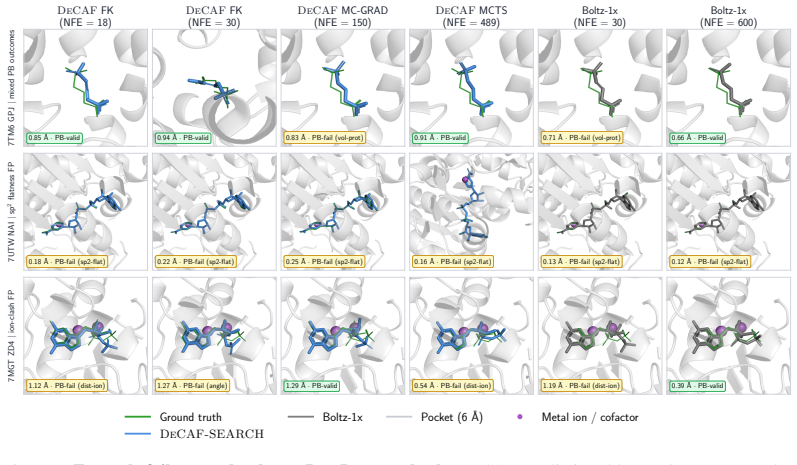
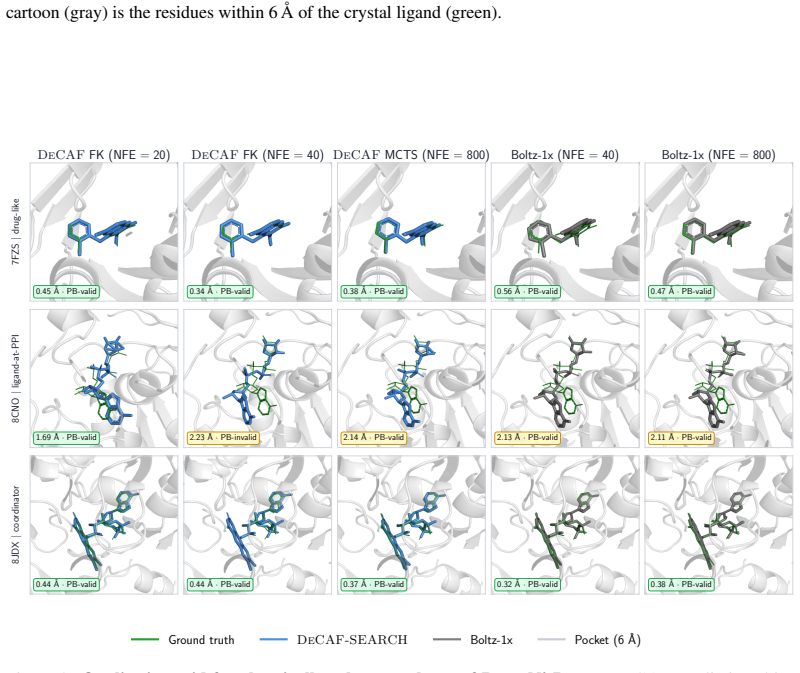
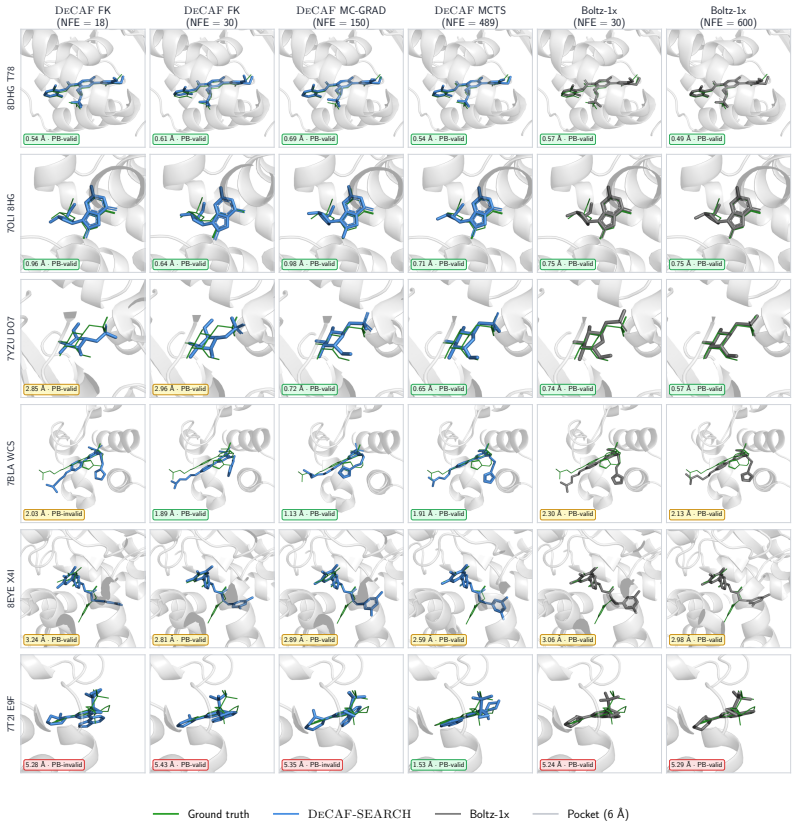
DeCAF-Boltz statistically improves over Boltz-1x in RMSD and physical validity at strict NFE budgets, and DeCAF-Pearl matches its teacher on success rate while using 5x fewer NFEs.
What carries the argument
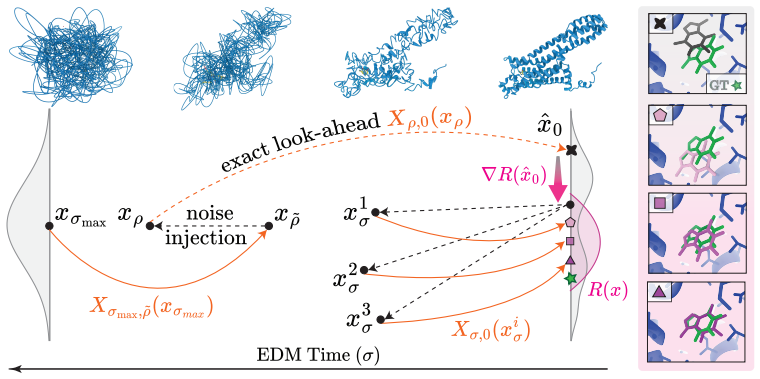
Denoiser-based flow map with endpoint losses that support SE(3) rigid alignment, plus a change of variables to operate in sigma-space noise schedules of EDM-style architectures.
If this is right
- All-atom cofolding models can be deployed at inference budgets previously limited to coarse-grained or single-structure predictors.
- Reward-guided search becomes feasible inside the flow-map lookahead without the cost of full diffusion trajectories.
- Direct distillation from any EDM-style pretrained cofolding checkpoint is possible without retraining the teacher.
- Pareto frontiers for accuracy versus compute shift leftward across the full range of NFE budgets.
Where Pith is reading between the lines
- The same denoiser-flow recipe could be applied to other diffusion-based structure generators such as small-molecule conformer models or RNA folding.
- If SE(3) alignment proves critical, future flow-map work on rigid bodies may adopt the same endpoint-loss pattern by default.
- Low-NFE sampling opens the door to coupling cofolding with online experimental feedback loops that were previously too slow.
Load-bearing premise
Endpoint losses plus SE(3) rigid alignment during distillation are enough to keep the distilled flow map as accurate as the original diffusion teacher.
What would settle it
A head-to-head comparison at 1-4 NFEs on PoseBusters or Runs N' Poses where DeCAF-Pearl success rate falls below the Pearl teacher or DeCAF-Boltz RMSD exceeds Boltz-1x.
Figures


read the original abstract
All-atom generative modeling of 3D biomolecular complexes has emerged as the dominant paradigm for predicting the structure of proteins and protein-ligand systems. Generating structures at the atomic level of fidelity, however, typically requires expensive iterative diffusion rollouts, making both conventional deployment and inference-time search techniques computationally costly. In this paper, we introduce the Denoiser Cofolding All-Atom Flowmap (DeCAF) framework for distilling state-of-the-art all-atom cofolding models into all-atom flow maps that produce high-quality samples in only a few inference steps. We build DeCAF on a denoiser-based formulation of flow maps with endpoint losses that naturally support SE(3) rigid alignment, which we show is critical for training accurate models. We further derive a simple change of variables that lets DeCAF operate in the {\sigma}-space noise schedule of EDM-style architectures, enabling direct distillation from pretrained cofolding diffusion models. Equipped with DeCAF's flowmap lookahead, we introduce a purpose-built inference-time framework that improves sampling through reward-guided search. Empirically, DeCAF-Boltz statistically improves over Boltz-1x in both accuracy (RMSD) and physical validity scores of protein-ligand poses at strict NFE budgets on the challenging Runs N' Poses, while also showing a more optimal Pareto frontier across all inference compute budgets on PoseBusters. Distilling the state-of-the-art Pearl cofolding model, DeCAF-Pearl outperforms diffusion-based cofolding models and matches its teacher on success rate while using 5x fewer NFEs. We release our code at https://github.com/genesistherapeutics/decaf.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the DeCAF framework for distilling pretrained all-atom cofolding diffusion models (e.g., Pearl, Boltz-1x) into few-step flow-map generators. It uses a denoiser-based flow-map formulation with endpoint losses that support SE(3) rigid alignment, derives a change-of-variables to EDM-style σ-space for direct distillation, and adds a reward-guided inference-time search procedure. Central empirical claims are that DeCAF-Pearl matches its teacher's success rate at 5× fewer NFEs while DeCAF-Boltz improves RMSD and physical validity over Boltz-1x at strict NFE budgets on Runs N' Poses and shows a better Pareto frontier on PoseBusters; code is released at https://github.com/genesistherapeutics/decaf.
Significance. If the distillation preserves the teacher's distribution without material degradation, the work would meaningfully reduce the inference cost of all-atom generative cofolding, enabling faster deployment and search. The explicit release of code is a positive contribution to reproducibility. The technical adaptation of flow maps to SE(3)-equivariant all-atom settings is a natural extension of existing flow-matching literature, but the significance hinges on whether the reported gains are robust.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the headline claims of statistical improvement in RMSD/validity and exact matching of teacher success rate are presented without reported dataset splits, number of independent runs, p-values, or ablation controls on the distillation procedure; this information is load-bearing for assessing whether the gains are reliable or subject to post-hoc selection.
- [§3.1–3.2] §3.1–3.2 (Denoiser-based flow map and endpoint losses): the claim that endpoint losses plus SE(3) rigid alignment suffice to transfer the teacher's marginals is central to the matching-performance result, yet the change-of-variables is only a reparameterization and endpoint losses do not explicitly constrain intermediate trajectory marginals; no verification (e.g., KL divergence or marginal matching plots) is shown that the learned vector field reproduces the diffusion teacher's distribution at non-endpoint times.
- [§4.3] §4.3 (Reward-guided search): the inference-time framework is presented as improving sampling, but the manuscript does not report an ablation isolating the contribution of the flow-map lookahead versus the reward model itself, which is required to substantiate that the few-step generator enables the reported search gains.
minor comments (3)
- [§3.1] Notation for the σ-space change of variables could be clarified with an explicit equation relating the flow-map velocity to the EDM denoiser output.
- [Figure 3] Figure captions for the Pareto curves should state the exact NFE values used and whether error bars reflect standard error over multiple seeds.
- [§2] The manuscript cites prior flow-matching and cofolding works but omits discussion of recent few-step diffusion distillation methods outside biomolecular modeling; a brief comparison paragraph would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our results. We address each major point below and indicate revisions to be incorporated in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the headline claims of statistical improvement in RMSD/validity and exact matching of teacher success rate are presented without reported dataset splits, number of independent runs, p-values, or ablation controls on the distillation procedure; this information is load-bearing for assessing whether the gains are reliable or subject to post-hoc selection.
Authors: We agree that these details are important for assessing reliability. In the revised manuscript we will explicitly state the dataset splits, report means and standard deviations over multiple independent runs, include p-values for the reported comparisons, and add ablation controls on key distillation hyperparameters. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2 (Denoiser-based flow map and endpoint losses): the claim that endpoint losses plus SE(3) rigid alignment suffice to transfer the teacher's marginals is central to the matching-performance result, yet the change-of-variables is only a reparameterization and endpoint losses do not explicitly constrain intermediate trajectory marginals; no verification (e.g., KL divergence or marginal matching plots) is shown that the learned vector field reproduces the diffusion teacher's distribution at non-endpoint times.
Authors: Endpoint losses with SE(3) alignment are intended to match the teacher's terminal marginals, while the flow-matching objective enforces trajectory consistency by construction. The empirical success-rate parity with the teacher at 5× fewer steps provides indirect evidence of distribution preservation. We will add a clarifying discussion of this point and, where space allows, supplementary marginal-consistency diagnostics at intermediate times. revision: partial
-
Referee: [§4.3] §4.3 (Reward-guided search): the inference-time framework is presented as improving sampling, but the manuscript does not report an ablation isolating the contribution of the flow-map lookahead versus the reward model itself, which is required to substantiate that the few-step generator enables the reported search gains.
Authors: We agree that isolating the lookahead contribution would strengthen the claim. In the revised manuscript we will include an ablation that compares the full reward-guided search against (i) the reward model paired with standard few-step sampling and (ii) the flow map without the lookahead component. revision: yes
Circularity Check
No circularity: empirical distillation validated against external teachers
full rationale
The paper frames DeCAF as a distillation procedure from pretrained external cofolding diffusion models (Pearl, Boltz) into flow maps, with performance measured by direct comparison on held-out benchmarks (Runs N' Poses, PoseBusters) at fixed NFE budgets. The change-of-variables to EDM σ-space and endpoint-loss + SE(3) alignment are presented as enabling reparameterization and training choices; success is shown empirically rather than derived by construction. No equations reduce reported RMSD/success-rate metrics to quantities defined inside the paper, and no load-bearing self-citations or uniqueness theorems are invoked. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ISSN 1755-4349. doi: 10.1038/nchem.1243. URLhttp://dx.doi.org/10.1038/nchem.1243. N. M. Boffi, M. S. Albergo, and E. Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models.Transactions on Machine Learning Research, 2025a. ISSN 2835-8856. N. M. Boffi, M. S. Albergo, and E. Vanden-Eijnden. How to buil...
-
[2]
URL https://www.biorxiv.org/content/10.1101/2024.10.10.615955v1
doi: 10.1101/2024.10.10.615955. URL https://www.biorxiv.org/content/10.1101/2024.10.10.615955v1. A. J. Bose, T. Akhound-Sadegh, G. Huguet, K. Fatras, J. Rector-Brooks, C.-H. Liu, A. C. Nica, M. Korablyov, M. Bronstein, and A. Tong. Se (3)-stochastic flow matching for protein backbone generation.arXiv preprint arXiv:2310.02391,
-
[3]
doi: 10.1039/D3SC04185A. L. Cao, I. Goreshnik, B. Coventry, J. B. Case, L. Miller, L. Kozodoy, R. E. Chen, L. Carter, A. C. Walls, Y .-J. Park, E.-M. Strauch, L. Stewart, M. S. Diamond, D. Veesler, and D. Baker. De novo design of picomolar sars-cov-2 miniprotein inhibitors.Science, 370(6515):426–431,
-
[4]
K. Didi, Z. Zhang, G. Zhou, D. Reidenbach, Z. Cao, S. Cha, T. Geffner, C. Dallago, J. Tang, M. M. Bronstein, et al. Scaling atomistic protein binder design with generative pretraining and test-time compute.arXiv preprint arXiv:2603.27950,
-
[5]
T. Geffner, K. Didi, Z. Cao, D. Reidenbach, Z. Zhang, C. Dallago, E. Kucukbenli, K. Kreis, and A. Vahdat. La-proteina: Atomistic protein generation via partially latent flow matching.arXiv preprint arXiv:2507.09466, 2025a. T. Geffner, K. Didi, Z. Zhang, D. Reidenbach, Z. Cao, J. Yim, M. Geiger, C. Dallago, E. Kucukbenli, A. Vahdat, et al. Proteina: Scalin...
-
[6]
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He. Mean flows for one-step generative modeling. In Advances in Neural Information Processing Systems (NeurIPS), 2025a. Z. Geng, Y . Lu, Z. Wu, E. Shechtman, J. Z. Kolter, and K. He. Improved mean flows: On the challenges of fastforward generative models.arXiv preprint arXiv:2512.02012, 2025b. J. Ho and T. Sa...
Pith/arXiv arXiv 2021
-
[7]
P. Holderrieth, D. Chen, L. Eyring, I. Shah, G. Anantharaman, Y . He, Z. Akata, T. Jaakkola, N. M. Boffi, and M. Simchowitz. Diamond maps: Efficient reward alignment via stochastic flow maps. arXiv preprint arXiv:2602.05993, 2026a. P. Holderrieth, U. Singer, T. Jaakkola, R. T. Q. Chen, Y . Lipman, and B. Karrer. GLASS flows: Effi- cient inference for rewa...
-
[8]
V . Jain, K. Sareen, M. Pedramfar, and S. Ravanbakhsh. Diffusion tree sampling: Scalable inference- time alignment of diffusion models.arXiv preprint arXiv:2506.20701,
- [9]
-
[10]
C. Lee, J. Yoo, M. Agarwal, S. Shah, J. Huang, A. Raghunathan, S. Hong, N. M. Boffi, and J. Kim. Flow map language models: One-step language modeling via continuous denoising.arXiv preprint arXiv:2602.16813,
-
[11]
Y . Lu, S. Lu, Q. Sun, H. Zhao, Z. Jiang, X. Wang, T. Li, Z. Geng, and K. He. One-step latent-free image generation with pixel mean flows.arXiv preprint arXiv:2601.22158,
-
[12]
P. Potaptchik, A. Saravanan, A. Mammadov, A. Prat, M. S. Albergo, and Y . W. Teh. Meta flow maps enable scalable reward alignment.arXiv preprint arXiv:2601.14430, 2026a. 13 P. Potaptchik, J. Yim, A. Saravanan, P. Holderrieth, E. Vanden-Eijnden, and M. S. Albergo. Discrete flow maps.arXiv preprint arXiv:2604.09784, 2026b. J. Rector-Brooks, T. Lambert, M. S...
-
[13]
D. Roos, O. Davis, F. Eijkelboom, M. Bronstein, M. Welling,˙I. ˙I. Ceylan, L. Ambrogioni, and J.-W. van de Meent. Categorical flow maps.arXiv preprint arXiv:2602.12233,
-
[14]
A. Sabour, M. S. Albergo, C. Domingo-Enrich, N. M. Boffi, S. Fidler, K. Kreis, and E. Vanden- Eijnden. Test-time scaling of diffusions with flow maps.arXiv preprint arXiv:2511.22688, 2025a. A. Sabour, S. Fidler, and K. Kreis. Align your flow: Scaling continuous-time flow map distillation, 2025b. URLhttps://arxiv.org/abs/2506.14603. D.-A. Silva, S. Yu, U. ...
-
[15]
R. Singhal, Z. Horvitz, R. Teehan, M. Ren, Z. Yu, K. McKeown, and R. Ranganath. A general frame- work for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848,
-
[16]
Škrinjar, J
P. Škrinjar, J. Eberhardt, J. Durairaj, and T. Schwede. Have protein-ligand co-folding methods moved beyond memorisation?BioRxiv, pages 2025–02,
2025
-
[17]
P. Team, Y . Zhang, C. Gong, H. Zhang, W. Ma, Z. Liu, X. Chen, J. Guan, L. Wang, Y . Yang, et al. Protenix-v1: Toward high-accuracy open-source biomolecular structure prediction.bioRxiv, pages 2026–02,
2026
- [18]
-
[19]
Wohlwend, G
J. Wohlwend, G. Corso, S. Passaro, N. Getz, M. Reveiz, K. Leidal, W. Swiderski, L. Atkinson, T. Portnoi, I. Chinn, et al. Boltz-1 democratizing biomolecular interaction modeling.BioRxiv, pages 2024–11,
2024
-
[20]
J. Yim, A. Campbell, A. Y . Foong, M. Gastegger, J. Jiménez-Luna, S. Lewis, V . G. Satorras, B. S. Veeling, R. Barzilay, T. Jaakkola, et al. Fast protein backbone generation with se (3) flow matching. arXiv preprint arXiv:2310.05297,
-
[21]
As a slight extension of algorithm 2, we realized that the gradient estimate in∇ xσ0 R(xσ0)can be a noisy estimate of the optimal guidance direction
P p=1 14: Compute particle scoresR (p) ˆx(p) 0 ,∀p 15: ifSEARCH=MCTSthen 16: X ← X ∪ T 17: Update weights of all(x, m)∈ T▷backup 18: Draw(x (p) σi , i)∼ Xaccording to UCT,∀p 19: else ifSEARCH=FKthen▷ K= 1, soTholds one entry per particle 20: (x(p) σi , i)←the entry ofTfor particlep,∀p 21: ifsmodL= 0then 22: Resample{x (p) σi }P p=1 with weights∝R (p) 23: ...
2025
-
[22]
Boltz-1x (default)
γRMSD<2↑PB Valid↑Success Rate↑ 0.375.3 89.2 65.2 0.575.690.365.9 0.772.8 90.3 63.8 1.070.390.761.3 5 10 20 Sampling steps 60 65 70 75 80Success Rate (%) 74.4 75.2 76.2 72.2 74.8 75.2 Boltz-1 @ 200 steps (76.2%) DeCAF (Ours) Boltz-1 Figure 6: RMSD <2 Å best@5 on PoseBusters. DECAF (FlowMap sampler Alg. 1, γ=0) vs Boltz-1 (ODE) at matched sampling steps; da...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.