GIFT: LLM-Guided State-Reward Interface for Financial Reinforcement Learning
Pith reviewed 2026-06-27 18:59 UTC · model grok-4.3
The pith
An LLM-guided framework designs enhanced states and auxiliary rewards for PPO-based financial portfolio trading, yielding better out-of-sample risk-adjusted performance than standard interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
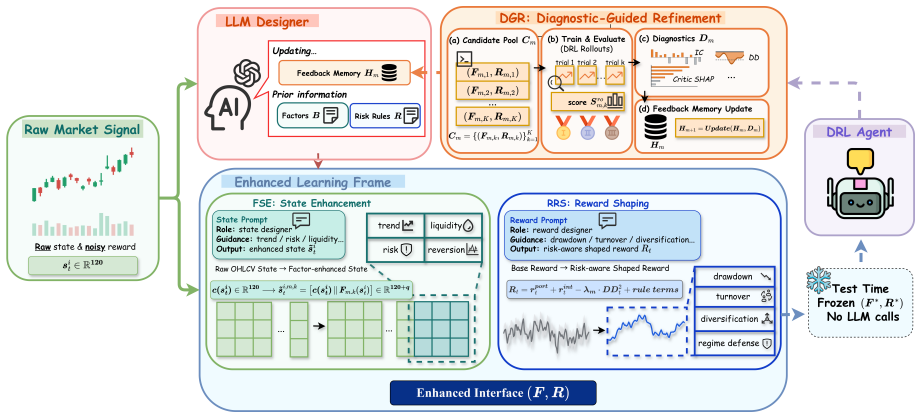
GIFT is an LLM-guided framework for state-reward interface design in PPO-based financial reinforcement learning. It applies Factor-guided State Enhancement to create state features from financial-factor primitives, Risk-rule-guided Reward Shaping to produce auxiliary rewards from portfolio-risk rules, and Diagnostic-guided Refinement to revise candidates using PPO rollout diagnostics. Once refined, the selected interface is fixed before evaluation, with no further LLM queries or updates at test time. Comprehensive rolling-window experiments across diverse market regimes and portfolio scenarios demonstrate that GIFT improves learning-signal quality and out-of-sample risk-adjusted portfolio pe
What carries the argument
The GIFT framework, which uses an LLM to translate financial-factor primitives into state features and portfolio-risk rules into auxiliary rewards, then applies diagnostic refinement to produce a fixed interface for PPO training and evaluation.
If this is right
- The interface remains fixed after refinement, eliminating LLM inference costs during live trading or evaluation.
- Enhanced states and shaped rewards supply more informative signals than raw price-volume data in non-stationary markets.
- Performance gains hold across multiple market regimes and portfolio scenarios in rolling-window tests.
- The method separates knowledge injection from decision-making, allowing the LLM to contribute only during design.
Where Pith is reading between the lines
- Similar LLM-guided refinement could automate interface design in other RL settings where domain rules exist but raw observations are sparse.
- If the refinement step proves robust, the approach might generalize to algorithms beyond PPO without requiring changes to the core training loop.
- Combining the fixed interface with online adaptation mechanisms could test whether the initial LLM contribution remains useful under distribution shift.
- Testing the same pipeline with alternative base models would reveal whether the gains depend on specific LLM capabilities or on the structured prompting process itself.
Load-bearing premise
The LLM can reliably translate financial-factor primitives and portfolio-risk rules into state features and auxiliary rewards that produce genuinely better learning signals rather than introducing noise or bias that PPO training cannot overcome.
What would settle it
A direct comparison experiment in which PPO agents trained on GIFT-designed interfaces achieve equal or lower risk-adjusted returns than agents using raw OHLCV states and un-shaped rewards, measured over the same rolling windows and market regimes.
Figures





read the original abstract
Financial portfolio trading is naturally formulated as a reinforcement learning problem, where an agent sequentially rebalances assets under changing market conditions to balance return, risk, and transaction costs. Yet in non-stationary markets, raw OHLCV states and short-horizon return rewards often provide an under-specified learning interface, motivating large language models as a way to inject financial knowledge into state and reward design while constraining open-ended generation. To this end, we propose GIFT, an LLM-guided framework for state-reward interface design in PPO-based financial reinforcement learning. Rather than using the LLM to make trading decisions, GIFT uses Factor-guided State Enhancement to generate state features from financial-factor primitives, Risk-rule-guided Reward Shaping to generate auxiliary rewards from portfolio-risk rules, and Diagnostic-guided Refinement to revise candidate interfaces using PPO rollout diagnostics. After refinement, GIFT fixes the selected state-reward interface before evaluation, with no further LLM queries or interface updates at test time. Comprehensive rolling-window experiments across diverse market regimes and portfolio scenarios demonstrate that GIFT improves learning-signal quality and out-of-sample risk-adjusted portfolio performance over baselines. Code and data are available at: https://github.com/KAG778/GIFT .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GIFT, an LLM-guided framework for state-reward interface design in PPO-based financial reinforcement learning for portfolio trading. It generates candidate states via Factor-guided State Enhancement from financial-factor primitives and auxiliary rewards via Risk-rule-guided Reward Shaping from portfolio-risk rules, then applies Diagnostic-guided Refinement using PPO rollout diagnostics before fixing the interface with no further LLM queries at test time. Rolling-window experiments across market regimes claim improved learning-signal quality and out-of-sample risk-adjusted returns over baselines, with code and data released.
Significance. If the central empirical claims hold after addressing selection concerns, the work would demonstrate a practical method for injecting domain knowledge into RL interfaces for non-stationary financial environments while preserving inference efficiency. The open release of code and data strengthens reproducibility.
major comments (3)
- [Methods (Diagnostic-guided Refinement)] Methods section on Diagnostic-guided Refinement: the procedure computes PPO rollout diagnostics on the same training segment used to optimize the subsequent PPO agent in each rolling window. This is load-bearing for the claim that gains arise from LLM-translated financial knowledge, as the refinement step can select interfaces that perform well in-sample without isolating the LLM contribution from the diagnostic filter.
- [Experiments] Experimental results section: no ablation is reported that compares full GIFT against a variant using only diagnostic refinement on non-LLM baselines or random candidates. Without this, the out-of-sample improvements cannot be attributed specifically to the Factor-guided and Risk-rule-guided LLM components rather than the selection mechanism.
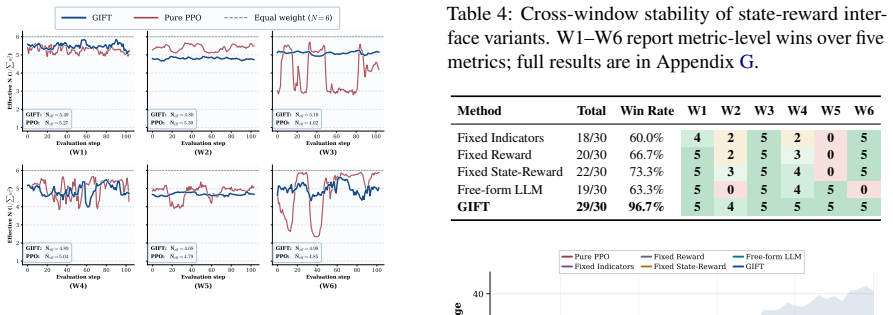
- [Results] Results tables (rolling-window performance): the reported improvements in risk-adjusted metrics are not accompanied by statistical significance tests across the multiple market regimes or controls for multiple comparisons, weakening the cross-regime claim.
minor comments (2)
- [Introduction] The abstract and introduction use 'learning-signal quality' without a precise definition or metric; this should be formalized with an equation or explicit formula in the methods.
- [Figures] Figure captions for the rolling-window diagrams should explicitly label the train/refinement/evaluation splits to clarify the temporal separation.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each of the major comments point-by-point below, proposing revisions to enhance the clarity and rigor of our work where needed.
read point-by-point responses
-
Referee: Methods section on Diagnostic-guided Refinement: the procedure computes PPO rollout diagnostics on the same training segment used to optimize the subsequent PPO agent in each rolling window. This is load-bearing for the claim that gains arise from LLM-translated financial knowledge, as the refinement step can select interfaces that perform well in-sample without isolating the LLM contribution from the diagnostic filter.
Authors: We acknowledge the concern regarding the use of the training segment for diagnostics. This is a deliberate design to ensure no information leakage into the test period, allowing the interface to be fixed after refinement. The LLM's role is in generating the initial candidates using financial knowledge, while the diagnostics filter for practical usability in RL training. We will revise the Methods section to provide a more detailed justification of this procedure and its alignment with the goal of injecting domain knowledge. revision: partial
-
Referee: Experimental results section: no ablation is reported that compares full GIFT against a variant using only diagnostic refinement on non-LLM baselines or random candidates. Without this, the out-of-sample improvements cannot be attributed specifically to the Factor-guided and Risk-rule-guided LLM components rather than the selection mechanism.
Authors: We agree that an ablation study is required to isolate the contribution of the LLM components. We will add experiments in the revised manuscript that apply the Diagnostic-guided Refinement to random and non-LLM generated candidates and compare their performance to the full GIFT approach. revision: yes
-
Referee: Results tables (rolling-window performance): the reported improvements in risk-adjusted metrics are not accompanied by statistical significance tests across the multiple market regimes or controls for multiple comparisons, weakening the cross-regime claim.
Authors: We will incorporate statistical significance testing in the revised results, including tests for differences in metrics across rolling windows and adjustments for multiple comparisons. revision: yes
Circularity Check
No significant circularity in claimed derivation chain
full rationale
The paper presents an empirical LLM-guided framework for designing state-reward interfaces in financial PPO, using factor-guided enhancement, risk-rule shaping, and diagnostic refinement on training rollouts before fixing the interface for out-of-sample rolling-window evaluation. No equations, fitted parameters, or self-citations are shown that reduce any prediction or result to its inputs by construction. The central claims rest on comparative performance against baselines under explicit out-of-sample protocols, rendering the method self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can translate financial-factor primitives into useful state features for RL
- domain assumption Portfolio-risk rules can be turned into auxiliary rewards that improve learning without distorting the primary objective
Reference graph
Works this paper leans on
-
[1]
and Saffell, M
Moody, J. and Saffell, M. , journal=. Learning to trade via direct reinforcement , year=
-
[2]
2017 , eprint=
A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem , author=. 2017 , eprint=
2017
-
[3]
Sun, Shuo and Wang, Rundong and An, Bo , title =. ACM Trans. Intell. Syst. Technol. , month = mar, articleno =. 2023 , issue_date =. doi:10.1145/3582560 , abstract =
-
[4]
Mathematical Finance , volume =
Hambly, Ben and Xu, Renyuan and Yang, Huining , title =. Mathematical Finance , volume =. doi:https://doi.org/10.1111/mafi.12382 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/mafi.12382 , abstract =
-
[5]
Pippas, Nikolaos and Ludvig, Elliot A. and Turkay, Cagatay , title =. ACM Comput. Surv. , month = jun, articleno =. 2025 , issue_date =. doi:10.1145/3733714 , abstract =
-
[6]
Artificial Intelligence Review , volume =
A Taxonomy of Literature Reviews and Experimental Study of Deepreinforcement Learning in Portfolio Management , author =. Artificial Intelligence Review , volume =. doi:10.1007/s10462-024-11066-w , abstract =
-
[7]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Liu, Xiao-Yang and Xia, Ziyi and Rui, Jingyang and Gao, Jiechao and Yang, Hongyang and Zhu, Ming and Wang, Christina Dan and Wang, Zhaoran and Guo, Jian , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[8]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[9]
Deep Reinforcement Learning with Positional Context for Intraday Trading , author =. Evolving Systems , volume =. doi:10.1007/s12530-024-09593-6 , abstract =
-
[10]
2018 , eprint=
Adversarial Deep Reinforcement Learning in Portfolio Management , author=. 2018 , eprint=
2018
-
[11]
and Harada, Daishi and Russell, Stuart J
Ng, Andrew Y. and Harada, Daishi and Russell, Stuart J. , title =. Proceedings of the Sixteenth International Conference on Machine Learning , pages =. 1999 , isbn =
1999
-
[12]
2022 , eprint=
Towards Safe Reinforcement Learning via Constraining Conditional Value-at-Risk , author=. 2022 , eprint=
2022
-
[13]
Robot See, Robot Do: Imitation Reward for Noisy Financial Environments , year=
Goluža, Sven and Kovačević, Tomislav and Begušić, Stjepan and Kostanjčar, Zvonko , booktitle=. Robot See, Robot Do: Imitation Reward for Noisy Financial Environments , year=
-
[14]
Karzanov, Daniil and Garz\'. Regret-Optimized Portfolio Enhancement through Deep Reinforcement Learning and Future Looking Rewards , year =. Proceedings of the 6th ACM International Conference on AI in Finance , pages =. doi:10.1145/3768292.3770340 , abstract =
-
[15]
ArXiv , year=
BloombergGPT: A Large Language Model for Finance , author=. ArXiv , year=
-
[16]
ArXiv , year=
FinGPT: Open-Source Financial Large Language Models , author=. ArXiv , year=
-
[17]
2024 , eprint=
A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges , author=. 2024 , eprint=
2024
-
[18]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Xie, Qianqian and Han, Weiguang and Chen, Zhengyu and Xiang, Ruoyu and Zhang, Xiao and He, Yueru and Xiao, Mengxi and Li, Dong and Dai, Yongfu and Feng, Duanyu and Xu, Yijing and Kang, Haoqiang and Kuang, Ziyan and Yuan, Chenhan and Yang, Kailai and Luo, Zheheng and Zhang, Tianlin and Liu, Zhiwei and Xiong, Guojun and Deng, Zhiyang and Jiang, Yuechen and ...
2024
-
[19]
Yu, Yangyang and Yao, Zhiyuan and Li, Haohang and Deng, Zhiyang and Jiang, Yuechen and Cao, Yupeng and Chen, Zhi and Suchow, Jordan W. and Cui, Zhenyu and Liu, Rong and Xu, Zhaozhuo and Zhang, Denghui and Subbalakshmi, Koduvayur and Xiong, Guojun and He, Yueru and Huang, Jimin and Li, Dong and Xie, Qianqian , title =. Proceedings of the 38th International...
2024
-
[20]
2026 , eprint=
StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets? , author=. 2026 , eprint=
2026
-
[21]
and Huang, Jimin and Qian, Lingfei and Peng, Xueqing and Suchow, Jordan W
Li, Haohang and Cao, Yupeng and Yu, Yangyang and Javaji, Shashidhar Reddy and Deng, Zhiyang and He, Yueru and Jiang, Yuechen and Zhu, Zining and Subbalakshmi, K.p. and Huang, Jimin and Qian, Lingfei and Peng, Xueqing and Suchow, Jordan W. and Xie, Qianqian. INVESTORBENCH : A Benchmark for Financial Decision-Making Tasks with LLM -based Agent. Proceedings ...
-
[22]
2025 , eprint=
FLAG-Trader: Fusion LLM-Agent with Gradient-based Reinforcement Learning for Financial Trading , author=. 2025 , eprint=
2025
-
[23]
Language Model Guided Reinforcement Learning in Quantitative Trading , year=
Darmanin, Adam and Vella, Vince , booktitle=. Language Model Guided Reinforcement Learning in Quantitative Trading , year=
-
[24]
2025 , eprint=
TradingAgents: Multi-Agents LLM Financial Trading Framework , author=. 2025 , eprint=
2025
-
[25]
2025 , eprint=
FinRLlama: A Solution to LLM-Engineered Signals Challenge at FinRL Contest 2024 , author=. 2025 , eprint=
2024
-
[26]
F in LLM - B : When Large Language Models Meet Financial Breakout Trading
Zhang, Kang and Yoshie, Osamu and Sun, Lichao and Huang, Weiran. F in LLM - B : When Large Language Models Meet Financial Breakout Trading. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: Industry Track). 2025. doi:10.18653/v1/2025.naacl-industry.29
-
[27]
2025 , eprint=
FinRL-DeepSeek: LLM-Infused Risk-Sensitive Reinforcement Learning for Trading Agents , author=. 2025 , eprint=
2025
-
[28]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
DeepTrader: A Deep Reinforcement Learning Approach for Risk-Return Balanced Portfolio Management with Market Conditions Embedding , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v35i1.16144 , abstractNote=
-
[29]
Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,
Relation-Aware Transformer for Portfolio Policy Learning , author =. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,. 2020 , month =. doi:10.24963/ijcai.2020/641 , url =
-
[30]
Yang, Mengyuan and Zhu, Mengying and Liang, Qianqiao and Zheng, Xiaolin and Wang, MengHan , title =. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , articleno =. 2023 , isbn =. doi:10.24963/ijcai.2023/548 , abstract =
-
[31]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,
A Smart Trader for Portfolio Management based on Normalizing Flows , author =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,. 2022 , month =. doi:10.24963/ijcai.2022/557 , url =
-
[32]
Proceedings of the First ACM International Conference on AI in Finance , articleno =
Yang, Hongyang and Liu, Xiao-Yang and Zhong, Shan and Walid, Anwar , title =. Proceedings of the First ACM International Conference on AI in Finance , articleno =. 2021 , isbn =. doi:10.1145/3383455.3422540 , abstract =
-
[33]
Proceedings of the 41st International Conference on Machine Learning , pages =
Reward Shaping for Reinforcement Learning with An Assistant Reward Agent , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[34]
2024 , editor =
Wang, Boyuan and Qu, Yun and Jiang, Yuhang and Shao, Jianzhun and Liu, Chang and Yang, Wenming and Ji, Xiangyang , booktitle =. 2024 , editor =
2024
-
[35]
and Now\'
Brys, Tim and Harutyunyan, Anna and Taylor, Matthew E. and Now\'. Policy Transfer using Reward Shaping , year =. Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems , pages =
2015
-
[36]
Zong, Chuqiao and Wang, Chaojie and Qin, Molei and Feng, Lei and Wang, Xinrun and An, Bo , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2024 , isbn =. doi:10.1145/3637528.3672064 , abstract =
-
[37]
Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence,
Contrastive Learning and Reward Smoothing for Deep Portfolio Management , author =. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence,. 2023 , month =. doi:10.24963/ijcai.2023/441 , url =
-
[38]
MAPS: Multi-Agent reinforcement learning-based Portfolio management System. , author =. Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence,. 2020 , month =. doi:10.24963/ijcai.2020/623 , url =
-
[39]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
Zhao, Lifan and Kong, Shuming and Shen, Yanyan , title =. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2023 , isbn =. doi:10.1145/3580305.3599315 , abstract =
-
[40]
ArXiv , year=
Eureka: Human-Level Reward Design via Coding Large Language Models , author=. ArXiv , year=
-
[41]
Auto MC-Reward: Automated Dense Reward Design with Large Language Models for Minecraft , year=
Li, Hao and Yang, Xue and Wang, Zhaokai and Zhu, Xizhou and Zhou, Jie and Qiao, Yu and Wang, Xiaogang and Li, Hongsheng and Lu, Lewei and Dai, Jifeng , booktitle=. Auto MC-Reward: Automated Dense Reward Design with Large Language Models for Minecraft , year=
-
[42]
2026 , eprint=
Can LLM-based Financial Investing Strategies Outperform the Market in Long Run? , author=. 2026 , eprint=
2026
-
[43]
Bollinger on Bollinger Bands , author =
-
[44]
XGBoost: A scalable tree boosting system
Chen, Tianqi and Guestrin, Carlos , title =. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2016 , isbn =. doi:10.1145/2939672.2939785 , abstract =
-
[45]
Financial Analysts Journal , volume=
Equity returns at the turn of the month , author=. Financial Analysts Journal , volume=. 2008 , publisher=
2008
-
[46]
2026 , publisher=
Quantitative trading: how to build your own algorithmic trading business , author=. 2026 , publisher=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.