LOTTERY: Learning from Reference-Only Samples in Two-Sample Testing under Size Asymmetry
Pith reviewed 2026-06-27 18:15 UTC · model grok-4.3
The pith
Abundant reference samples allow learning and uncertainty-weighting multiple representations for type-I-controlled two-sample tests even with few query samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using abundant reference data, we learn reference-dependent representations that summarize salient structure of the reference distribution and provide informative signals for detecting departures. We incorporate a collection of representation families that capture both global and local structure, and adaptively weight them using only reference samples via an uncertainty-guided principle. Theoretically, we establish permutation-based type I error control and show consistency of the aggregated test: as the sample sizes grow, the test power converges to one whenever the representation set contains at least one consistent representation.
What carries the argument
Uncertainty-guided aggregation of multiple reference-dependent representation families learned and weighted exclusively from reference samples.
If this is right
- The procedure controls type I error exactly via permutations despite data-driven weighting from reference data.
- Test power converges to one with growing sample sizes provided the representation collection includes at least one consistent member.
- The method applies directly to few-shot query regimes where data splitting would leave too few samples for reliable testing.
- Empirical aggregation of global and local representations yields competitive power on benchmarks while keeping type I error at the nominal level.
Where Pith is reading between the lines
- The same reference-only weighting principle could be tested in other adaptive statistics where one sample is plentiful.
- If multiple representation families are available, the consistency guarantee suggests that adding more families cannot hurt the asymptotic power result.
- In applications the approach implies that effort should shift toward collecting high-quality reference data rather than balancing the two samples.
Load-bearing premise
The uncertainty-guided weighting of representations can be performed using only reference samples while preserving the permutation-based type I error control and without introducing dependence on the query sample.
What would settle it
A simulation study in which the empirical type I error of the aggregated test exceeds the nominal level under the null after the reference-only weighting step is applied.
Figures
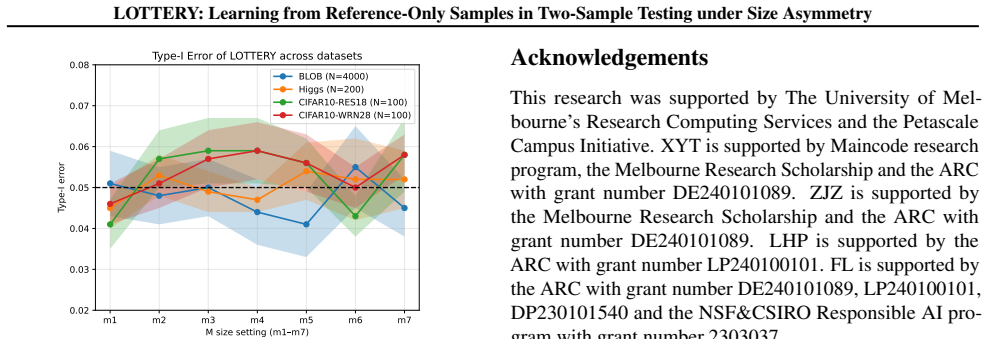
read the original abstract
Data-adaptive two-sample testing assesses if two samples come from the same distribution, using a discrepancy learned from the data (e.g., via kernel-based feature representations). Such methods typically rely on data splitting to decouple learning from testing and control type I error. However, this paradigm is ill-suited to few-shot settings with severe sample-size imbalance: abundant reference samples are available, while only a handful of query samples arrive. In this paper, we show how this imbalance can be leveraged constructively. Using abundant reference data, we learn reference-dependent representations that summarize salient structure of the reference distribution and provide informative signals for detecting departures. We incorporate a collection of representation families that capture both global and local structure, and adaptively weight them using only reference samples via an uncertainty-guided principle. Theoretically, we establish permutation-based type I error control and show consistency of the aggregated test: as the sample sizes grow, the test power converges to one whenever the representation set contains at least one consistent representation. Empirically, our aggregation achieves strong performance across a range of benchmarks while retaining type I error control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LOTTERY, a method for two-sample testing under severe size asymmetry (abundant reference samples, few query samples). It learns reference-dependent representations from the reference data alone to capture global and local structure, applies uncertainty-guided weighting computed exclusively from reference samples, and aggregates the weighted representations into a test statistic. The central claims are permutation-based type I error control together with consistency: as sample sizes grow, power converges to 1 whenever the representation collection contains at least one consistent representation. Empirical results are asserted to show strong performance across benchmarks while retaining type I control.
Significance. If the type I control and consistency results hold, the work offers a constructive use of reference-query imbalance that avoids data splitting, which is a common practical limitation in few-shot adaptive testing. The reference-only weighting and multi-family representation approach could extend existing permutation and kernel-based testing frameworks to imbalanced regimes.
major comments (2)
- [Abstract] Abstract: the claim of permutation-based type I error control is asserted but the abstract supplies no explicit statement of the permutation mechanism (e.g., whether weights are recomputed inside each permutation or treated as fixed) nor any argument that the uncertainty-guided weights remain ancillary under the null. This leaves open the possibility that data-dependent selection or normalization in the weighting step breaks exchangeability of the combined sample, invalidating exact finite-sample control even when no query data enters the weights.
- [Abstract] Abstract / theoretical claims: consistency is stated to hold 'whenever the representation set contains at least one consistent representation,' yet the abstract gives neither the precise definition of the representation families nor the uncertainty principle used for weighting. Without these, it is impossible to verify whether the aggregation preserves the consistency property or whether additional conditions on the weighting are required.
minor comments (1)
- [Abstract] The abstract refers to 'a range of benchmarks' and 'strong performance' without naming the datasets, baselines, or metrics; this makes the empirical contribution difficult to evaluate from the summary alone.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the specific comments on the abstract. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of permutation-based type I error control is asserted but the abstract supplies no explicit statement of the permutation mechanism (e.g., whether weights are recomputed inside each permutation or treated as fixed) nor any argument that the uncertainty-guided weights remain ancillary under the null. This leaves open the possibility that data-dependent selection or normalization in the weighting step breaks exchangeability of the combined sample, invalidating exact finite-sample control even when no query data enters the weights.
Authors: We agree the abstract is terse on this mechanism. In the manuscript the weights are computed exclusively from reference samples (Section 3.1) and are held fixed across all permutations (Section 3.2); because they are ancillary under the null they do not affect exchangeability of the pooled sample. We will revise the abstract to state explicitly that weights are reference-only and fixed. revision: yes
-
Referee: [Abstract] Abstract / theoretical claims: consistency is stated to hold 'whenever the representation set contains at least one consistent representation,' yet the abstract gives neither the precise definition of the representation families nor the uncertainty principle used for weighting. Without these, it is impossible to verify whether the aggregation preserves the consistency property or whether additional conditions on the weighting are required.
Authors: The representation families (global and local) and the uncertainty weighting rule are defined in Sections 2 and 3.1; Theorem 4.2 proves that the aggregation is consistent whenever at least one representation is consistent, with no further conditions on the weights. We will add a brief clause in the abstract referencing these definitions and the theorem. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on establishing permutation-based type I error control for an aggregated test that uses reference-only uncertainty-guided weighting of representations, followed by a consistency result. No equations or steps are shown that reduce a claimed prediction or guarantee to a fitted parameter or self-citation by construction. The abstract and description invoke standard permutation testing ideas without visible self-definitional loops or renaming of known results as new derivations. This is the common case of a self-contained theoretical argument.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The representation set contains at least one consistent representation for the departure of interest
- standard math Permutation tests on the aggregated statistic control type I error at the nominal level
Reference graph
Works this paper leans on
-
[1]
Test , volume = 27, number = 4, pages =
Exact testing with random permutations , author =. Test , volume = 27, number = 4, pages =
-
[2]
ICML , year =
Unsupervised Deep Embedding for Clustering Analysis , author =. ICML , year =
-
[3]
Journal of computational and applied mathematics , volume=
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , author=. Journal of computational and applied mathematics , volume=. 1987 , publisher=
1987
-
[4]
, author=
Improved deep embedded clustering with local structure preservation. , author=. IJCAI , year=
-
[5]
JMLR , volume=
A kernel two-sample test , author=. JMLR , volume=
-
[6]
AISTATS , year=
A witness two-sample test , author=. AISTATS , year=
-
[7]
ICML , year=
Learning deep kernels for non-parametric two-sample tests , author=. ICML , year=
-
[8]
NeurIPS , year=
Interpretable distribution features with maximum testing power , author=. NeurIPS , year=
-
[9]
AISTATS , year=
Two-sample testing using deep learning , author=. AISTATS , year=
-
[10]
NeurIPS , year=
Failing loudly: An empirical study of methods for detecting dataset shift , author=. NeurIPS , year=
-
[11]
ACM Computing Surveys , volume=
Anomaly detection: A survey , author=. ACM Computing Surveys , volume=
-
[12]
Journal of Biopharmaceutical Statistics , volume=
Detecting early signals of unexpected adverse events , author=. Journal of Biopharmaceutical Statistics , volume=
-
[13]
ICML , year=
Kernelized Stein discrepancy tests of goodness-of-fit for time-to-event data , author=. ICML , year=
-
[14]
2005 , publisher=
Algorithmic learning in a random world , author=. 2005 , publisher=
2005
-
[15]
Annals of Statistics , volume=
Testing for outliers with conformal p-values , author=. Annals of Statistics , volume=
-
[16]
Machine Learning , volume=
Support vector data description , author=. Machine Learning , volume=
-
[17]
ICML , year=
Deep one-class classification , author=. ICML , year=
-
[18]
1980 , publisher=
Approximation theorems of mathematical statistics , author=. 1980 , publisher=
1980
-
[19]
2005 , publisher=
Testing statistical hypotheses , author=. 2005 , publisher=
2005
-
[20]
Annals of Statistics , volume=
Classification accuracy as a proxy for two-sample testing , author=. Annals of Statistics , volume=
-
[21]
Proceedings of the National Institute of Sciences of India , volume=
On the generalized distance in statistics , author=. Proceedings of the National Institute of Sciences of India , volume=
-
[22]
PNAS , volume=
Deep conformal prediction: An overview , author=. PNAS , volume=
-
[23]
JMLR , volume=
Hilbert space embeddings and metrics on probability measures , author=. JMLR , volume=
-
[24]
Smola, Alex and Gretton, Arthur and Song, Le and Sch. A. ALT , year=
-
[25]
NeurIPS , year=
Kernel measures of conditional dependence , author=. NeurIPS , year=
-
[26]
2002 , publisher=
Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond , author=. 2002 , publisher=
2002
-
[27]
Foundations and Trends in Machine Learning , volume=
Kernel mean embedding of distributions: A review and beyond , author=. Foundations and Trends in Machine Learning , volume=
-
[28]
2013 , publisher=
Permutation Tests: A Practical Guide to Resampling Methods for Testing Hypotheses , author=. 2013 , publisher=
2013
-
[29]
2005 , publisher=
Permutation, parametric and bootstrap tests of hypotheses , author=. 2005 , publisher=
2005
-
[30]
SIGMOD , year=
Breunig, Markus M and Kriegel, Hans-Peter and Ng, Raymond T and Sander, J. SIGMOD , year=
-
[31]
Journal of Statistical Planning and Inference , volume=
Energy statistics: A class of statistics based on distances , author=. Journal of Statistical Planning and Inference , volume=
-
[32]
JMLR , volume=
Schrab, Antonin and Kim, Ilmun and Albert, M. JMLR , volume=
-
[33]
Annals of Statistics , volume=
Multivariate analysis by data depth: descriptive statistics, graphics and inference , author=. Annals of Statistics , volume=
-
[34]
AAAI , year=
On the decreasing power of kernel and distance based nonparametric hypothesis tests in high dimensions , author=. AAAI , year=
-
[35]
ICLR , year=
Revisiting classifier two-sample tests , author=. ICLR , year=
-
[36]
2004 , publisher=
Reproducing Kernel Hilbert Spaces in Probability and Statistics , author=. 2004 , publisher=
2004
-
[37]
Neural Computation , volume=
Estimating the support of a high-dimensional distribution , author=. Neural Computation , volume=
-
[38]
NeurIPS , year=
Deep anomaly detection using geometric transformations , author=. NeurIPS , year=
-
[39]
Journal of Multivariate Analysis , volume=
On a new multivariate two-sample test , author=. Journal of Multivariate Analysis , volume=
-
[40]
The Annals of Statistics , pages=
Detection of an anomalous cluster in a network , author=. The Annals of Statistics , pages=
-
[41]
Philosophical Transactions of the Royal Society of London
On the problem of the most efficient tests of statistical hypotheses , author=. Philosophical Transactions of the Royal Society of London. , volume=
-
[42]
Understanding Machine Learning: From Theory to Algorithms , author =
-
[43]
ICLR , year =
Understanding Deep Learning Requires Rethinking Generalization , author =. ICLR , year =
-
[44]
Behavior Research Methods , year =
The Brunner--Munzel Test and Its Permutation Version for Stochastic Equality , author =. Behavior Research Methods , year =
-
[45]
ICLR , year =
Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy , author =. ICLR , year =
-
[46]
NeurIPS , year =
A Wild Bootstrap for Degenerate Kernel Tests , author =. NeurIPS , year =
-
[47]
CVPR , year =
Neural Mean Discrepancy for Efficient Out-of-Distribution Detection , author =. CVPR , year =
-
[48]
CODASPY , year=
Membership inference attacks and defenses in classification models , author=. CODASPY , year=
-
[49]
ICML , year=
Maximum mean discrepancy test is aware of adversarial attacks , author=. ICML , year=
-
[50]
NeurIPS , year=
Cadet: Fully self-supervised out-of-distribution detection with contrastive learning , author=. NeurIPS , year=
-
[51]
SIGMOD , year=
Efficient algorithms for mining outliers from large data sets , author=. SIGMOD , year=
-
[52]
CVPR , year=
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics , author=. CVPR , year=
-
[53]
On the Exploration of Local Significant Differences For Two-Sample Test , year =
Zhou, Zhijian and Ni, Jie and Yao, Jia-He and Gao, Wei , booktitle =. On the Exploration of Local Significant Differences For Two-Sample Test , year =
-
[54]
Nature Communications , author=
Searching for exotic particles in high-energy physics with deep learning , volume=. Nature Communications , author=
-
[55]
UAI , year=
A Unified Data Representation Learning for Non-parametric Two-sample Testing , author=. UAI , year=
-
[56]
Proceedings of the IEEE , volume=
A unifying review of deep and shallow anomaly detection , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[57]
AAAI , year=
Deep one-class classification via interpolated gaussian descriptor , author=. AAAI , year=
-
[58]
arXiv preprint arXiv:1702.06280 , year=
On the (statistical) detection of adversarial examples , author=. arXiv preprint arXiv:1702.06280 , year=
-
[59]
CVPR , year=
H2ST: Hierarchical Two-Sample Tests for Continual Out-of-Distribution Detection , author=. CVPR , year=
-
[60]
ICLR , year=
Detecting machine-generated texts by multi-population aware optimization for maximum mean discrepancy , author=. ICLR , year=
-
[61]
ICLR , year=
Intriguing properties of neural networks , author=. ICLR , year=
-
[62]
Foundations and Trends
Trustworthy machine learning: From data to models , author=. Foundations and Trends
-
[63]
NeurIPS , year=
MMD-FUSE: Learning and combining kernels for two-sample testing without data splitting , author=. NeurIPS , year=
-
[64]
ICML , year=
DROCC: Deep robust one-class classification , author=. ICML , year=
-
[65]
ICLR , year=
Explainable Deep One-Class Classification , author=. ICLR , year=
-
[66]
ICLR , year=
Deep autoencoding gaussian mixture model for unsupervised anomaly detection , author=. ICLR , year=
-
[67]
ICLR , year=
SSD: A Unified Framework for Self-Supervised Outlier Detection , author=. ICLR , year=
-
[68]
Learning Multiple Layers of Features from Tiny Images , author=
-
[69]
CVPR , year=
Deep Residual Learning for Image Recognition , author=. CVPR , year=
-
[70]
BMVC , year=
Wide Residual Networks , author=. BMVC , year=
-
[71]
ICLR , year=
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. ICLR , year=
-
[72]
arXiv preprint arXiv:1707.07269 , year=
Large sample analysis of the median heuristic , author=. arXiv preprint arXiv:1707.07269 , year=
-
[73]
2025 , booktitle=
DUAL: Learning Diverse Kernels for Aggregated Two-sample and Independence Testing , author=. 2025 , booktitle=
2025
-
[74]
2025 , booktitle=
Anchor-based Maximum Discrepancy for Relative Similarity Testing , author=. 2025 , booktitle=
2025
-
[75]
arXiv preprint arXiv:2502.02970 , year=
Membership inference attack should move on to distributional statistics for distilled generative models , author=. arXiv preprint arXiv:2502.02970 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.