Analyzing the Correlation Between Hallucinations and Knowledge Conflicts in Large Language Models
Pith reviewed 2026-06-27 18:42 UTC · model grok-4.3
The pith
Hallucination activation patterns in LLMs cannot be fully reduced to knowledge conflict representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
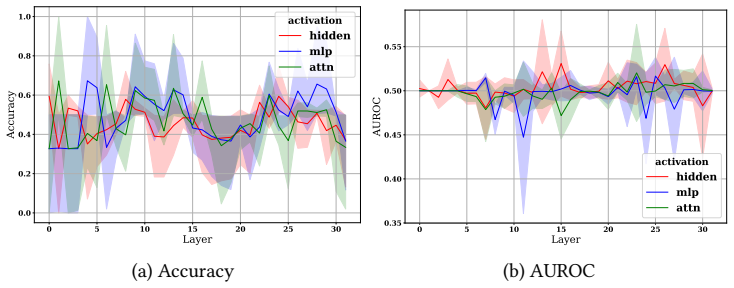
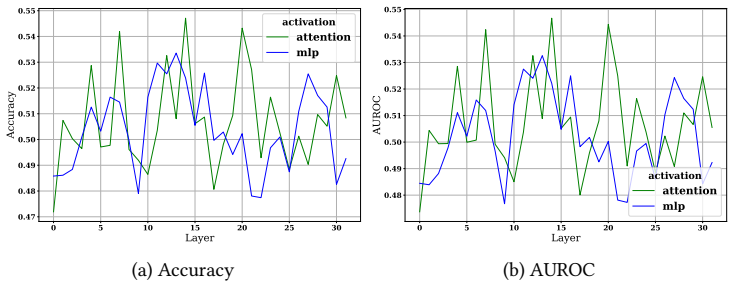
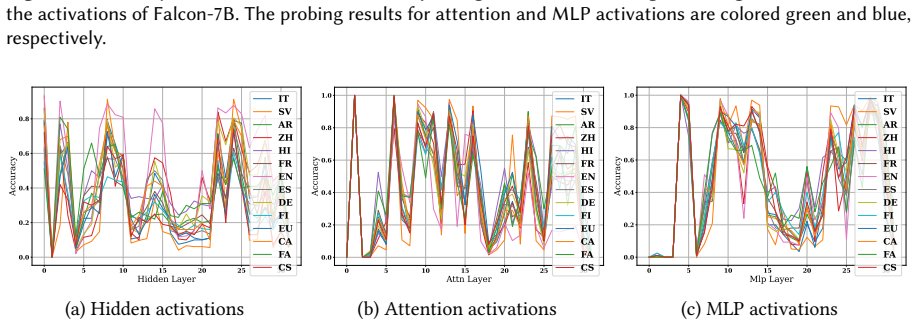
Although conceptually related, hallucination activation patterns cannot be fully reduced to or explained by knowledge conflict representations. Probing across hidden, attention, and MLP layers plus output logits on LLaMA-3-8B and Falcon-7B shows the representations stay distinguishable even when the tasks overlap.
What carries the argument
Probing techniques applied to hidden, attention, and MLP layer activations together with output logits to compare representations of hallucinations and knowledge conflicts.
If this is right
- Distinct internal mechanisms imply that mitigation strategies must target hallucinations and knowledge conflicts separately.
- Probing remains effective for interpretability work even when the two phenomena do not collapse into one.
- Fine-grained layer-wise analysis can continue to separate failure modes across languages and model sizes.
- Training data conflicts alone do not fully determine hallucination behavior during inference.
Where Pith is reading between the lines
- If the distinction holds, editing only conflicting facts in the training set will leave some hallucination pathways untouched.
- Future work could test whether the same separation appears when models are asked to resolve conflicts at inference time rather than in static probes.
- The result suggests that interpretability tools should track multiple distinct error signatures instead of assuming a single underlying cause.
Load-bearing premise
The chosen probing methods accurately isolate and separate the internal representations that belong to knowledge conflicts from those that belong to hallucinations.
What would settle it
A follow-up experiment that applies a new set of probes or a different architecture and finds that the same hallucination and conflict tasks now produce statistically indistinguishable activation patterns.
Figures
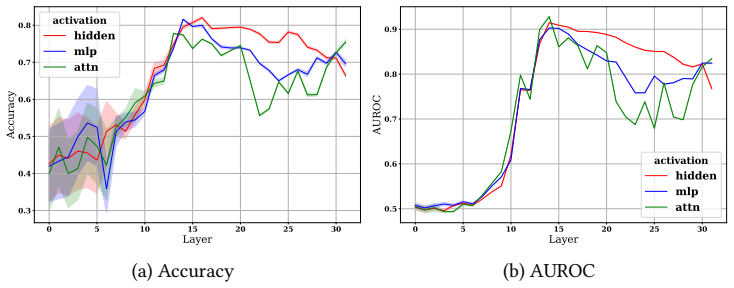
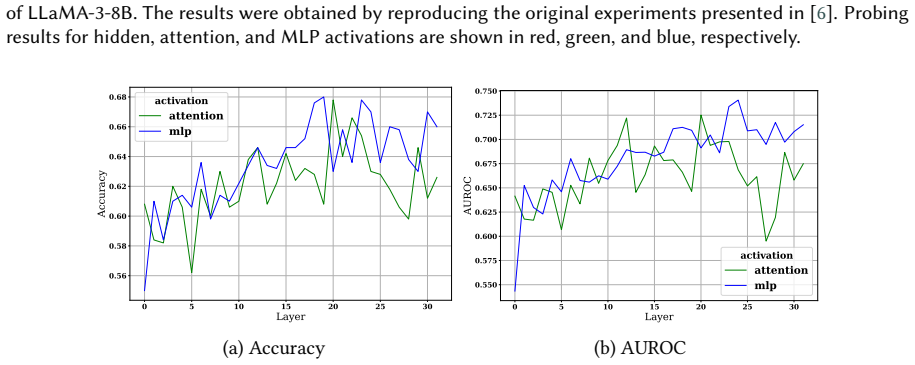
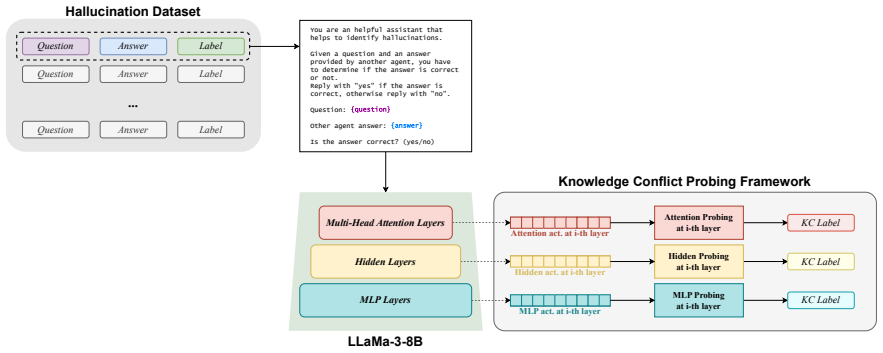
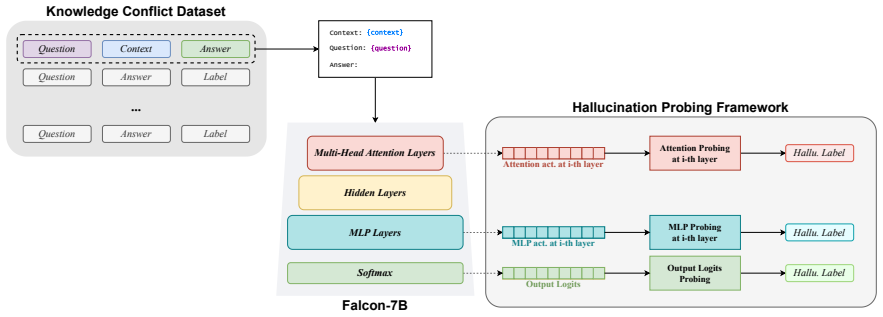
read the original abstract
Hallucinations -- factually incorrect or unverifiable outputs -- remain one of the most challenging limitations of Large Language Models (LLMs), especially in knowledge-intensive tasks. One proposed explanation is internal knowledge conflicts arising from fixed, outdated training data. This paper investigates whether internal representations linked to knowledge conflicts correlate with hallucination behaviors in LLMs. Using probing techniques inspired by two prior works, we analyzed activations from hidden, attention, and MLP layers, as well as output logits, across predefined tasks. We probed LLaMA-3-8B on hallucination detection benchmarks and Falcon-7B on a knowledge conflict dataset. Our findings show that, although conceptually related, hallucination activation patterns cannot be fully reduced to or explained by knowledge conflict representations. Nonetheless, probing proves a robust tool across multiple languages and activation types, supporting its role in improving LLM interpretability. This work advances the broader understanding of hallucinations in LLMs and underscores the value of fine-grained analysis of their internal behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that although hallucinations and knowledge conflicts are conceptually related in LLMs, their associated activation patterns cannot be fully reduced to or explained by each other. This is based on probing hidden, attention, and MLP layer activations plus output logits from LLaMA-3-8B on hallucination detection benchmarks and from Falcon-7B on a knowledge conflict dataset, with additional claims about probing robustness across languages and activation types.
Significance. If substantiated with appropriate controls, the result would indicate that hallucinations involve internal mechanisms distinct from knowledge conflicts, supporting targeted interpretability work. The multi-layer and multilingual probing approach would be a methodological strength if the cross-phenomenon comparison is valid.
major comments (2)
- [Abstract] Abstract: the central claim that hallucination activation patterns cannot be fully reduced to knowledge conflict representations requires evidence from within the same model and representational space, yet the study probes LLaMA-3-8B on one task and Falcon-7B on the other; any observed distinction could arise from differences in scale, architecture, pretraining, or tokenizer rather than the phenomena themselves.
- [Abstract / Methods] Experimental setup (inferred from abstract): no details are provided on how activations are aligned or compared across models, on statistical tests for reduction, or on controls for model-specific effects, which is load-bearing for the claim that patterns 'cannot be fully reduced'.
minor comments (1)
- [Abstract] The abstract states the models and tasks but does not clarify whether any cross-model alignment or shared-model control was performed.
Simulated Author's Rebuttal
We thank the referee for highlighting these methodological concerns, which directly impact the strength of our central claim. We agree that the cross-model design introduces confounds and that details on comparisons were insufficiently specified. Below we respond point-by-point and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that hallucination activation patterns cannot be fully reduced to knowledge conflict representations requires evidence from within the same model and representational space, yet the study probes LLaMA-3-8B on one task and Falcon-7B on the other; any observed distinction could arise from differences in scale, architecture, pretraining, or tokenizer rather than the phenomena themselves.
Authors: We agree that the use of distinct models (LLaMA-3-8B for hallucination benchmarks and Falcon-7B for the knowledge conflict dataset) prevents a direct comparison within a shared representational space and leaves open the possibility that observed differences stem from model-specific factors rather than the phenomena. Our model choices were dictated by the datasets employed in the cited prior works, but this does not resolve the issue. In revision we will qualify the abstract and discussion to present the non-reducibility finding as suggestive evidence across models rather than a definitive within-model result, and we will add an explicit limitations paragraph on this point. revision: partial
-
Referee: [Abstract / Methods] Experimental setup (inferred from abstract): no details are provided on how activations are aligned or compared across models, on statistical tests for reduction, or on controls for model-specific effects, which is load-bearing for the claim that patterns 'cannot be fully reduced'.
Authors: The full Methods section describes layer-wise activation extraction (hidden states, attention, MLP) and logit probing, yet we acknowledge that cross-model alignment procedures, the precise statistical tests used to evaluate reduction (e.g., correlation or accuracy-difference metrics), and explicit controls for model-specific effects were not detailed. We will expand the Methods and add an appendix specifying these elements, including any normalization steps and the quantitative criteria applied to assess whether hallucination patterns are reducible to knowledge-conflict representations. revision: yes
Circularity Check
Empirical probing study shows no definitional or self-referential circularity
full rationale
The paper conducts an empirical analysis by applying probing techniques to activations in LLaMA-3-8B (hallucination task) and Falcon-7B (knowledge conflict task), concluding that patterns are not fully reducible. No equations, fitted parameters renamed as predictions, or self-citation chains that bear the central load are described. The derivation relies on observed activation differences rather than any input being redefined as output. Minor self-citation risk exists only in the 'inspired by prior works' phrasing, but this does not reduce the claim by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Sun, Z. Lin, X. Wu, Hallucinations of large multimodal models: Problem and countermeasures, Information Fusion 118 (2025) 102970
2025
-
[2]
Huang, W
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, et al., A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions, ACM Transactions on Information Systems 43 (2025) 1–55
2025
-
[3]
J. Xie, K. Zhang, J. Chen, R. Lou, Y. Su, Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts, in: The Twelfth International Conference on Learning Representations, 2023
2023
-
[4]
J. Li, J. Chen, R. Ren, X. Cheng, W. X. Zhao, J.-Y. Nie, J.-R. Wen, The dawn after the dark: An em- pirical study on factuality hallucination in large language models, arXiv preprint arXiv:2401.03205 (2024)
arXiv 2024
-
[5]
Belinkov, Probing classifiers: Promises, shortcomings, and advances, Computational Linguistics 48 (2022) 207–219
Y. Belinkov, Probing classifiers: Promises, shortcomings, and advances, Computational Linguistics 48 (2022) 207–219
2022
-
[6]
Y. Zhao, X. Du, G. Hong, A. P. Gema, A. Devoto, H. Wang, X. He, K.-F. Wong, P. Min- ervini, Analysing the Residual Stream of Language Models Under Knowledge Conflicts, 2024. arXiv:2410.16090
arXiv 2024
-
[7]
Snyder, M
B. Snyder, M. Moisescu, M. B. Zafar, On early detection of hallucinations in factual question answering, in: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 2721–2732
2024
-
[8]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al., The Llama 3 Herd of Models, arXiv preprint arXiv:2407.21783 (2024)
Pith/arXiv arXiv 2024
-
[9]
Almazrouei, H
E. Almazrouei, H. Alobeidli, A. Alshamsi, A. Cappelli, R. Cojocaru, M. Debbah, E. Goffinet, D. Hes- low, J. Launay, Q. Malartic, B. Noune, B. Pannier, G. Penedo, Falcon-40B: an open large language model with state-of-the-art performance (2023)
2023
-
[10]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al., Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, Advances in neural information processing systems 36 (2023) 46595–46623
2023
-
[11]
S. S. Ravi, B. Mielczarek, A. Kannappan, D. Kiela, R. Qian, Lynx: An open source hallucination evaluation model, arXiv preprint arXiv:2407.08488 (2024)
arXiv 2024
-
[12]
J. Li, X. Cheng, W. X. Zhao, J.-Y. Nie, J.-R. Wen, HaluEval: A large-scale hallucination evaluation benchmark for large language models, arXiv preprint arXiv:2305.11747 (2023)
arXiv 2023
-
[13]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al., Retrieval-augmented generation for knowledge-intensive NLP tasks, Advances in neural information processing systems 33 (2020) 9459–9474
2020
-
[14]
O. Ram, Y. Levine, I. Dalmedigos, D. Muhlgay, A. Shashua, K. Leyton-Brown, Y. Shoham, In- context retrieval-augmented language models, Transactions of the Association for Computational Linguistics 11 (2023) 1316–1331
2023
-
[15]
Barnett, S
S. Barnett, S. Kurniawan, S. Thudumu, Z. Brannelly, M. Abdelrazek, Seven failure points when engineering a retrieval augmented generation system, in: Proceedings of the IEEE/ACM 3rd International Conference on AI Engineering-Software Engineering for AI, 2024, pp. 194–199
2024
-
[16]
A. Conneau, G. Kruszewski, G. Lample, L. Barrault, M. Baroni, What you can cram into a single vector: Probing sentence embeddings for linguistic properties, arXiv preprint arXiv:1805.01070 (2018)
Pith/arXiv arXiv 2018
-
[17]
Z. Allen-Zhu, Y. Li, Physics of language models: Part 1, learning hierarchical language structures, arXiv preprint arXiv:2305.13673 (2023)
arXiv 2023
-
[18]
Z. Allen-Zhu, Y. Li, Physics of language models: Part 3.1, knowledge storage and extraction, arXiv preprint arXiv:2309.14316 (2023)
arXiv 2023
-
[19]
Longpre, K
S. Longpre, K. Perisetla, A. Chen, N. Ramesh, C. DuBois, S. Singh, Entity-Based Knowledge Conflicts in Question Answering, in: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 2021, pp. 7052–7063
2021
-
[20]
M. Joshi, E. Choi, D. S. Weld, L. Zettlemoyer, Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension, arXiv preprint arXiv:1705.03551 (2017)
Pith/arXiv arXiv 2017
-
[21]
R. Vázquez, T. Mickus, E. Zosa, T. Vahtola, J. Tiedemann, A. Sinha, V. Segonne, F. Sánchez- Vega, A. Raganato, J. Libovick `y, et al., SemEval-2025 Task 3: Mu-SHROOM, the Multilingual Shared Task on Hallucinations and Related Observable Overgeneration Mistakes, arXiv preprint arXiv:2504.11975 (2025)
arXiv 2025
-
[22]
Kwiatkowski, J
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polo- sukhin, J. Devlin, K. Lee, et al., Natural questions: a benchmark for question answering research, Transactions of the Association for Computational Linguistics 7 (2019) 453–466
2019
-
[23]
A. G. Valerio, K. Trufanova, S. de Benedictis, G. Vessio, G. Castellano, From segmentation to explanation: Generating textual reports from MRI with LLMs, Computer Methods and Programs in Biomedicine 270 (2025) 108922
2025
-
[24]
Ullah, A
E. Ullah, A. Parwani, M. M. Baig, R. Singh, Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology–a recent scoping review, Diagnostic pathology 19 (2024) 43
2024
-
[25]
Sarker, R
A. Sarker, R. Zhang, Y. Wang, Y. Xiao, S. Das, D. Schutte, D. Oniani, Q. Xie, H. Xu, Natural Language Processing for Digital Health in the Era of Large Language Models, Yearbook of Medical Informatics 33 (2024) 229–240
2024
-
[26]
Ho, D.-T
H.-T. Ho, D.-T. Ly, L. V. Nguyen, Mitigating Hallucinations in Large Language Models for Ed- ucational Application, in: 2024 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), IEEE, 2024, pp. 1–4
2024
-
[27]
A. T. Neumann, Y. Yin, S. Sowe, S. Decker, M. Jarke, An LLM-driven chatbot in higher education for databases and information systems, IEEE Transactions on Education (2024)
2024
-
[28]
Chkirbene, R
Z. Chkirbene, R. Hamila, A. Gouissem, U. Devrim, Large language models (LLM) in industry: A survey of applications, challenges, and trends, in: 2024 IEEE 21st International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET), IEEE, 2024, pp. 229–234
2024
-
[29]
Laraspata, F
L. Laraspata, F. Cardilli, G. Castellano, G. Vessio, Enhancing human capital management through GPT-driven questionnaire generation, in: Proceedings of the Eighth Workshop on Natural Lan- guage for Artificial Intelligence (NL4AI 2024) co-located with 23th International Conference of the Italian Association for Artificial Intelligence (AIxIA 2024), CEUR-WS...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.