AUCp: Pseudo-AUC for Inference Model Selection with Unlabeled Validation Data in Abnormality Detection
Pith reviewed 2026-06-27 18:56 UTC · model grok-4.3
The pith
AUCp selects the best unsupervised abnormality detector by computing a pseudo-AUC that treats every unlabeled test sample as positive.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
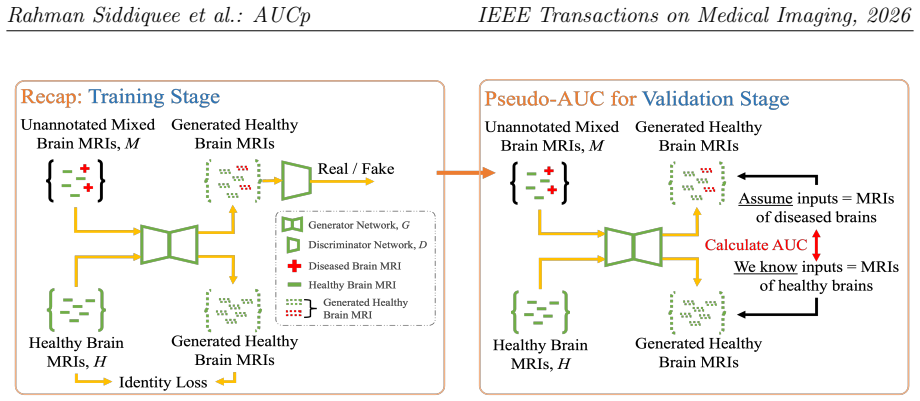
AUCp is obtained by setting the pseudo ground truth of all unannotated test samples to abnormal/positive and then applying the standard AUC formula. Given a large and representative training set of normal samples, model selection driven by these AUCp scores improves disease detection performance for unsupervised and self-supervised methods over conventional metrics.
What carries the argument
AUCp, the pseudo-AUC score formed by labeling every unlabeled test sample as positive and computing the usual area under the ROC curve.
If this is right
- AUCp identifies the optimal training iteration for inference without any annotated validation data.
- The same selection procedure works for both reconstruction-based unsupervised methods and self-supervised methods.
- Selecting with AUCp yields higher abnormality detection rates on neurologic and other medical image datasets than conventional metrics.
- The method removes the need for labeled validation sets while still producing models that generalize to real disease cases.
Where Pith is reading between the lines
- If the pseudo-labeling step remains reliable even when the test set contains a modest fraction of normal samples, AUCp could be applied in fully unlabeled clinical pipelines.
- The ranking produced by AUCp might transfer to anomaly detection tasks outside medical imaging if the training set of normal examples is sufficiently representative.
- One could measure how AUCp rankings degrade as the proportion of truly normal samples in the test set increases, providing a practical bound on its use.
Load-bearing premise
Treating every unlabeled test sample as positive produces AUC scores that correctly rank models by their true ability to separate normal from abnormal cases.
What would settle it
On a held-out labeled test set, the model chosen by highest AUCp performs worse at detecting abnormalities than the model chosen by lowest reconstruction error.
Figures




read the original abstract
Abnormality detection is a crucial yet challenging task in medical image analysis. Distinguishing abnormalities from normal data by learning to reconstruct normal-only data alleviates the reliance on labeled datasets. However, many studies, even if unsupervised, rely on a labeled validation set to select the best model for inference from multiple training iterations. For many diseases labeled data are unavailable and substantially time consuming to obtain. To address this, AUCp - a novel metric that supports abnormality detection for unsupervised and self-supervised methods is proposed. Instead of evaluating the realism of reconstructed images to select the best of model for inference, it focuses on actual detection performance and without requiring an annotated test set. Assuming the pseudo ground truth of all unannotated samples in the test set as abnormal/positive and using traditional AUC calculation, AUCp scores are derived. Given a large and representative training set of normal samples, we show mathematical and empirical evidence that model selection using AUCp scores improves disease detection in terms of unsupervised and self-supervised methods over conventional metrics. Using two unsupervised methods for neurologic disease detection and self-supervised methods on diverse datasets, our results demonstrate that the AUCp score effectively identifies the optimal model for inference, significantly enhancing abnormality and disease detection. The corresponding implementations are available in https://github.com/mahfuzmohammad/AUCp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AUCp, a pseudo-AUC metric for model selection in unsupervised and self-supervised abnormality detection. It assumes all unlabeled test samples are positive, computes AUC against scores from a normal-only training set, and claims that this yields better inference models than conventional metrics (e.g., reconstruction error) when a large representative normal training set is available. Mathematical derivations and empirical results on neurologic disease detection and diverse datasets are presented to support improved detection performance.
Significance. If the central claim is valid, AUCp would enable fully unsupervised model selection in medical imaging domains where labeled validation data are unavailable, addressing a practical bottleneck. The public GitHub implementation supports reproducibility. However, the significance is conditional on resolving whether the pseudo-label assumption preserves correct relative rankings.
major comments (3)
- [Abstract] Abstract: The central claim that 'model selection using AUCp scores improves disease detection' rests on the unquantified assumption that treating every test sample as positive produces rankings aligned with true performance. The skeptic analysis shows AUCp reduces to P(s(test) > s(train_normal)), which increases when a model raises scores on test-normals; this bias is load-bearing and requires explicit error analysis or bounds in the mathematical evidence.
- [Mathematical evidence] Mathematical evidence (referenced in abstract): The derivation must demonstrate that the induced ranking is insensitive to the fraction of normals in the test set, or provide conditions under which the bias does not alter model ordering. Without this, the evidence does not yet support the claim over conventional metrics.
- [Empirical results] Empirical results section: Experiments should include controlled ablations varying the proportion of normals in the test set and report how AUCp rankings deviate from ground-truth AUC rankings; current description does not address this.
minor comments (2)
- Notation for AUCp and the pseudo-ground-truth assumption should be formalized with an equation early in the paper for clarity.
- [Abstract] The abstract mentions 'two unsupervised methods' and 'self-supervised methods on diverse datasets' but does not name the specific methods or datasets; this should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each of the major comments point-by-point below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'model selection using AUCp scores improves disease detection' rests on the unquantified assumption that treating every test sample as positive produces rankings aligned with true performance. The skeptic analysis shows AUCp reduces to P(s(test) > s(train_normal)), which increases when a model raises scores on test-normals; this bias is load-bearing and requires explicit error analysis or bounds in the mathematical evidence.
Authors: We acknowledge the reduction of AUCp to P(s(test) > s(train_normal)) and the potential bias if scores on test-normals are raised. However, in the context of our assumption of a large representative normal training set, models trained to minimize reconstruction error on normals will assign consistently low scores to normal samples, whether in train or test. Raising scores on test-normals would contradict the training objective for a well-performing model. We will add an explicit error analysis and bounds on this bias in the mathematical section of the revised manuscript to quantify its impact on model rankings. revision: yes
-
Referee: [Mathematical evidence] Mathematical evidence (referenced in abstract): The derivation must demonstrate that the induced ranking is insensitive to the fraction of normals in the test set, or provide conditions under which the bias does not alter model ordering. Without this, the evidence does not yet support the claim over conventional metrics.
Authors: We agree that additional demonstration is needed. The current derivation relies on the representativeness of the normal training set to ensure that the pseudo-labeling does not distort relative model performance. In the revision, we will extend the mathematical evidence to include a proof or conditions showing when the ranking remains consistent regardless of the normal fraction in the test set, specifically under the large training set assumption. revision: yes
-
Referee: [Empirical results] Empirical results section: Experiments should include controlled ablations varying the proportion of normals in the test set and report how AUCp rankings deviate from ground-truth AUC rankings; current description does not address this.
Authors: We will incorporate controlled ablations in the empirical results section. These will vary the proportion of normal samples in the test set (simulating different abnormality prevalences) and compare the model rankings induced by AUCp against those from ground-truth AUC computed with true labels. This will empirically validate the robustness of AUCp rankings. revision: yes
Circularity Check
AUCp is defined by assuming all test samples positive, so its model ranking reduces by construction to separation from training normals rather than true abnormality detection.
specific steps
-
self definitional
[Abstract]
"Assuming the pseudo ground truth of all unannotated samples in the test set as abnormal/positive and using traditional AUC calculation, AUCp scores are derived. Given a large and representative training set of normal samples, we show mathematical and empirical evidence that model selection using AUCp scores improves disease detection in terms of unsupervised and self-supervised methods over conventional metrics."
AUCp is defined directly from the all-positive pseudo-label assumption on the test set. The claimed improvement in true detection performance therefore reduces to the input assumption itself: the metric rewards any model that raises anomaly scores across the entire test distribution (including any normals present) and provides no mechanism to distinguish true positives from false positives within the test set.
full rationale
The paper's central claim is that AUCp-based model selection improves true disease detection performance. However, AUCp is explicitly constructed from the pseudo-label assumption that every test sample is positive. This makes the metric equivalent to P(s(test) > s(train_normal)) by definition. Any mathematical or empirical demonstration that this selects better models for true (mixed) test performance therefore inherits the assumption without independent support, satisfying the self-definitional pattern. No other circularity patterns (self-citation chains, fitted predictions, etc.) are identifiable from the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption All unannotated samples in the test set can be treated as abnormal/positive for the purpose of computing a proxy AUC that ranks models by true detection performance.
Reference graph
Works this paper leans on
-
[1]
Exploiting structural consistency of chest anatomy for unsu- pervised anomaly detection in radiography images.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Tiange Xiang, Yixiao Zhang, Yongyi Lu, Alan Yuille, Chaoyi Zhang, Weidong Cai, and Zongwei Zhou. Exploiting structural consistency of chest anatomy for unsu- pervised anomaly detection in radiography images.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[2]
Learn- ing image representations for anomaly detection: application to discovery of histo- logical alterations in drug development.Medical Image Analysis, 92:103067, 2024
Igor Zingman, Birgit Stierstorfer, Charlotte Lempp, and Fabian Heinemann. Learn- ing image representations for anomaly detection: application to discovery of histo- logical alterations in drug development.Medical Image Analysis, 92:103067, 2024
2024
-
[3]
Alexander Frotscher, Jaivardhan Kapoor, Thomas Wolfers, and Christian F Baum- gartner. Unsupervisedanomalydetectionusingaggregatednormativediffusion.arXiv 29 Rahman Siddiquee et al.: AUCp IEEE Transactions on Medical Imaging, 2026 preprint arXiv:2312.01904, 2023
-
[4]
Masked autoencoders for unsupervised anomaly detec- tion in medical images.Procedia Computer Science, 225:969–978, 2023
Mariana-Iuliana Georgescu. Masked autoencoders for unsupervised anomaly detec- tion in medical images.Procedia Computer Science, 225:969–978, 2023
2023
-
[5]
Anatomy-aware self-supervised learning for anomaly detection in chest radiographs.Iscience, 26(7), 2023
Junya Sato, Yuki Suzuki, Tomohiro Wataya, Daiki Nishigaki, Kosuke Kita, Kazuki Yamagata, Noriyuki Tomiyama, and Shoji Kido. Anatomy-aware self-supervised learning for anomaly detection in chest radiographs.Iscience, 26(7), 2023
2023
-
[6]
Squid: Deep feature in-painting for unsupervised anomaly detection
Tiange Xiang, Yixiao Zhang, Yongyi Lu, Alan L Yuille, Chaoyi Zhang, Weidong Cai, and Zongwei Zhou. Squid: Deep feature in-painting for unsupervised anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23890–23901, 2023
2023
-
[7]
Unsupervised anomaly detection in 3d brain mri using deep learning with multi-task brain age prediction
Marcel Bengs, Finn Behrendt, Max-Heinrich Laves, Julia Krüger, Roland Opfer, and Alexander Schlaefer. Unsupervised anomaly detection in 3d brain mri using deep learning with multi-task brain age prediction. InMedical Imaging 2022: Computer- Aided Diagnosis, volume 12033, pages 305–309. SPIE, 2022
2022
-
[8]
Unsupervised anomaly detection in mr images using multicontrast information.Medical Physics, 48(11):7346–7359, 2021
Byungjai Kim, Kinam Kwon, Changheun Oh, and Hyunwook Park. Unsupervised anomaly detection in mr images using multicontrast information.Medical Physics, 48(11):7346–7359, 2021
2021
-
[9]
Anomaly detection in medical imaging with deep perceptual autoencoders.IEEE Access, 9:118571–118583, 2021
Nina Shvetsova, Bart Bakker, Irina Fedulova, Heinrich Schulz, and Dmitry V Dylov. Anomaly detection in medical imaging with deep perceptual autoencoders.IEEE Access, 9:118571–118583, 2021
2021
-
[10]
Anofpdm: Anomaly detection with forward process of diffusion models for brain mri
Yiming Che, Fazle Rafsani, Jay Shah, Md Mahfuzur Rahman Siddiquee, and Teresa Wu. Anofpdm: Anomaly detection with forward process of diffusion models for brain mri. InProceedings of the Winter Conference on Applications of Computer Vision, pages 1113–1122, 2025
2025
-
[11]
Clement Fung, Chen Qiu, Aodong Li, and Maja Rudolph. Model selection of anomaly detectors in the absence of labeled validation data.arXiv preprint arXiv:2310.10461, 2023
-
[12]
Sergio Naval Marimont and Giacomo Tarroni. Harder synthetic anomalies to improve ood detection in medical images.arXiv preprint arXiv:2308.01412, 2023
-
[13]
Yu Cai, Weiwen Zhang, Hao Chen, and Kwang-Ting Cheng. Medianomaly: A comparative study of anomaly detection in medical images.arXiv preprint arXiv:2404.04518, 2024. 30 Rahman Siddiquee et al.: AUCp IEEE Transactions on Medical Imaging, 2026
-
[14]
Md Mahfuzur Rahman Siddiquee, Jay Shah, Teresa Wu, Catherine Chong, Todd J Schwedt, Gina Dumkrieger, Simona Nikolova, and Baoxin Li. Brainomaly: Unsuper- vised neurologic disease detection utilizing unannotated t1-weighted brain mr images. arXiv preprint arXiv:2302.09200, 2023
-
[15]
Healthygan: Learning from unannotated medical images to detect anomalies associated with human disease
Md Mahfuzur Rahman Siddiquee, Jay Shah, Teresa Wu, Catherine Chong, Todd Schwedt, and Baoxin Li. Healthygan: Learning from unannotated medical images to detect anomalies associated with human disease. InInternational Workshop on Simulation and Synthesis in Medical Imaging, pages 43–54. Springer, 2022
2022
-
[16]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[17]
Cutpaste: Self- supervised learning for anomaly detection and localization
Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self- supervised learning for anomaly detection and localization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9664–9674, 2021
2021
-
[18]
De- tecting outliers with foreign patch interpolation.arXiv preprint arXiv:2011.04197, 2020
Jeremy Tan, Benjamin Hou, James Batten, Huaqi Qiu, and Bernhard Kainz. De- tecting outliers with foreign patch interpolation.arXiv preprint arXiv:2011.04197, 2020
-
[19]
Detecting outliers with poisson image interpolation
Jeremy Tan, Benjamin Hou, Thomas Day, John Simpson, Daniel Rueckert, and Bern- hard Kainz. Detecting outliers with poisson image interpolation. InMedical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part V 24, pages 581–591. Springer, 2021
2021
-
[20]
Natural syn- thetic anomalies for self-supervised anomaly detection and localization
Hannah M Schlüter, Jeremy Tan, Benjamin Hou, and Bernhard Kainz. Natural syn- thetic anomalies for self-supervised anomaly detection and localization. InEuropean Conference on Computer Vision, pages 474–489. Springer, 2022
2022
-
[21]
The international classification of headache disorders, 3rd edition.Cephalalgia, 38(1):1– 211, January 2018
Headache Classification Committee of the International Headache Society (IHS). The international classification of headache disorders, 3rd edition.Cephalalgia, 38(1):1– 211, January 2018
2018
-
[22]
31 Rahman Siddiquee et al.: AUCp IEEE Transactions on Medical Imaging, 2026
Ixi dataset.https://brain-development.org/ixi-dataset/. 31 Rahman Siddiquee et al.: AUCp IEEE Transactions on Medical Imaging, 2026
2026
-
[23]
Headache classifica- tion and automatic biomarker extraction from structural mris using deep learning
Md Mahfuzur Rahman Siddiquee, Jay Shah, Catherine Chong, Simona Nikolova, Gina Dumkrieger, Baoxin Li, Teresa Wu, and Todd J Schwedt. Headache classifica- tion and automatic biomarker extraction from structural mris using deep learning. Brain Communications, 5(1):fcac311, 2023
2023
-
[24]
Rsna pneumonia detection challenge
MD Anouk Stein, Carol Wu, Chris Carr, George Shih, Jamie Dulkowski, kalpathy, Leon Chen, Luciano Prevedello, MD Marc Kohli, Mark McDonald, Peter, Phil Culliton, Safwan Halabi MD, and Tian Xia. Rsna pneumonia detection challenge. https://kaggle.com/competitions/rsna-pneumonia-detection-challenge,
-
[25]
Nguyen, Julia Elliott, NguyenThanhNhan, and Phil Culliton
Duc Nguyen, DungNB, Ha Q. Nguyen, Julia Elliott, NguyenThanhNhan, and Phil Culliton. Vinbigdata chest x-ray abnormalities detection.https://kaggle.com/ competitions/vinbigdata-chest-xray-abnormalities-detection, 2020. Kag- gle
2020
-
[26]
Brain tumor mri dataset, 2021
Msoud Nickparvar. Brain tumor mri dataset, 2021
2021
-
[27]
Brain tumor detection.https://www.kaggle.com/datasets/ ahmedhamada0/brain-tumor-detection, 2021
Ahmed Hamada. Brain tumor detection.https://www.kaggle.com/datasets/ ahmedhamada0/brain-tumor-detection, 2021
2021
-
[28]
Abu-Naser
Ahmad Saleh, Rozana Sukaik, and Samy S. Abu-Naser. Brain tumor classification using deep learning. In2020 International Conference on Assistive and Rehabilitation Technologies (iCareTech), pages 131–136, 2020
2020
-
[29]
Enhanced performance of brain tumor classification via tumor region augmentation and partition.PLOS ONE, 10(10):1–13, 10 2015
Jun Cheng, Wei Huang, Shuangliang Cao, Ru Yang, Wei Yang, Zhaoqiang Yun, Zhijian Wang, and Qianjin Feng. Enhanced performance of brain tumor classification via tumor region augmentation and partition.PLOS ONE, 10(10):1–13, 10 2015
2015
-
[30]
Ujjwal Baid, Satyam Ghodasara, Suyash Mohan, Michel Bilello, Evan Calabrese, Errol Colak, Keyvan Farahani, Jayashree Kalpathy-Cramer, Felipe C Kitamura, Sarthak Pati, et al. The rsna-asnr-miccai brats 2021 benchmark on brain tumor seg- mentation and radiogenomic classification.arXiv preprint arXiv:2107.02314, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Attention based glaucoma detection: A large-scale database and cnn model
Liu Li, Mai Xu, Xiaofei Wang, Lai Jiang, and Hanruo Liu. Attention based glaucoma detection: A large-scale database and cnn model. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10563–10572, 2019
2019
-
[32]
Noel C. F. Codella, Veronica Rotemberg, Philipp Tschandl, M. Emre Celebi, Stephen W. Dusza, David A. Gutman, Brian Helba, Aadi Kalloo, Konstantinos Li- opyris, Michael A. Marchetti, Harald Kittler, and Allan Halpern. Skin lesion analysis 32 Rahman Siddiquee et al.: AUCp IEEE Transactions on Medical Imaging, 2026 toward melanoma detection 2018: A challenge...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.Jama, 318(22):2199–2210, 2017
Babak Ehteshami Bejnordi, Mitko Veta, Paul Johannes Van Diest, Bram Van Gin- neken, Nico Karssemeijer, Geert Litjens, Jeroen AWM Van Der Laak, Meyke Hermsen, Quirine F Manson, Maschenka Balkenhol, et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.Jama, 318(22):2199–2210, 2017
2017
-
[34]
Bmad: Benchmarks for medical anomaly detection
Jinan Bao, Hanshi Sun, Hanqiu Deng, Yinsheng He, Zhaoxiang Zhang, and Xingyu Li. Bmad: Benchmarks for medical anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4042– 4053, 2024
2024
-
[35]
Yu Cai, Hao Chen, Xin Yang, Yu Zhou, and Kwang-Ting Cheng. Dual-distribution discrepancy for anomaly detection in chest x-rays.arXiv preprint arXiv:2206.03935, 2022
-
[36]
Adversarially learned anomaly detection
Houssam Zenati, Manon Romain, Chuan-Sheng Foo, Bruno Lecouat, and Vijay Chandrasekhar. Adversarially learned anomaly detection. In2018 IEEE Interna- tional conference on data mining (ICDM), pages 727–736. IEEE, 2018
2018
-
[37]
Adversarially learned one-class classifier for novelty detection
Mohammad Sabokrou, Mohammad Khalooei, Mahmood Fathy, and Ehsan Adeli. Adversarially learned one-class classifier for novelty detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3379–3388, 2018
2018
-
[38]
f-anogan: Fast unsupervised anomaly detection with generative adversarial networks.Medical Image Analysis, 2019
Thomas Schlegl, Philipp Seeböck, Sebastian M Waldstein, Georg Langs, and Ursula Schmidt-Erfurth. f-anogan: Fast unsupervised anomaly detection with generative adversarial networks.Medical Image Analysis, 2019
2019
-
[39]
Ganomaly: Semi- supervised anomaly detection via adversarial training
Samet Akcay, Amir Atapour-Abarghouei, and Toby P Breckon. Ganomaly: Semi- supervised anomaly detection via adversarial training. InAsian conference on com- puter vision, pages 622–637. Springer, 2018
2018
-
[40]
Abnormality detection in chest x-ray images using uncertainty predic- tion autoencoders
Yifan Mao, Fei-Fei Xue, Ruixuan Wang, Jianguo Zhang, Wei-Shi Zheng, and Hong- mei Liu. Abnormality detection in chest x-ray images using uncertainty predic- tion autoencoders. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 529–538. Springer, 2020
2020
-
[41]
Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, and Anton van den Hengel. Memorizing normality to detect 33 Rahman Siddiquee et al.: AUCp IEEE Transactions on Medical Imaging, 2026 anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. InProceedings of the IEEE/CVF international conference...
2026
-
[42]
Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
Paul Bergmann, Sindy Löwe, Michael Fauser, David Sattlegger, and Carsten Ste- ger. Improving unsupervised defect segmentation by applying structural similarity to autoencoders.arXiv preprint arXiv:1807.02011, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Unsu- pervised anomaly localization with structural feature-autoencoders
Felix Meissen, Johannes Paetzold, Georgios Kaissis, and Daniel Rueckert. Unsu- pervised anomaly localization with structural feature-autoencoders. InInternational MICCAI Brainlesion Workshop, pages 14–24. Springer, 2022
2022
-
[44]
Mixture proportion estima- tion via kernel embeddings of distributions
Harish Ramaswamy, Clayton Scott, and Ambuj Tewari. Mixture proportion estima- tion via kernel embeddings of distributions. InInternational conference on machine learning, pages 2052–2060. PMLR, 2016
2052
-
[45]
Estimatingtheclasspriorand posterior from noisy positives and unlabeled data.Advances in neural information processing systems, 29, 2016
ShantanuJain, MarthaWhite, andPredragRadivojac. Estimatingtheclasspriorand posterior from noisy positives and unlabeled data.Advances in neural information processing systems, 29, 2016
2016
-
[46]
Estimating the class prior in positive and unlabeled data through decision tree induction
Jessa Bekker and Jesse Davis. Estimating the class prior in positive and unlabeled data through decision tree induction. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. 34
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.