REFLECT: Intervention-Supported Error Attribution for Silent Failures in LLM Agent Traces
Pith reviewed 2026-06-27 16:42 UTC · model grok-4.3
The pith
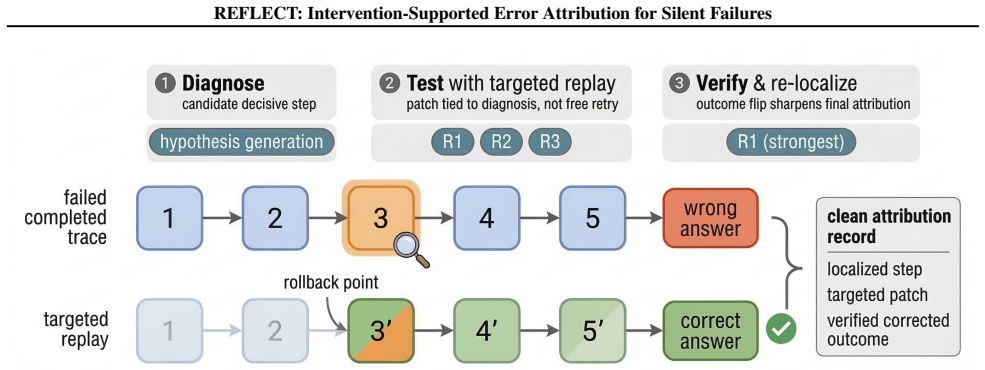
REFLECT locates silent errors in LLM agent traces by testing interventions on candidate steps and using outcome changes to refine the diagnosis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By closing the loop between diagnosis and intervention outcome, REFLECT achieves the highest localization accuracy among same-auditor methods on four benchmarks, with largest gains on structured tool-use traces and usable attribution even absent ground-truth answers.
What carries the argument
The outcome-flip verification from diagnosis-specific patches applied in controlled replays, which supplies contrastive evidence to refine the error attribution.
If this is right
- Error localization improves most on traces that involve structured tool calls and actions.
- Attribution remains possible and actionable when ground-truth answers are not available.
- The method applies across multiple domains of multi-hop reasoning tasks.
- Diagnoses become more reliable by incorporating empirical verification from replays.
Where Pith is reading between the lines
- If the intervention reliably identifies errors, it could support iterative self-improvement in agent systems.
- Similar feedback mechanisms might apply to other sequential decision processes beyond LLM agents.
- Testing on traces with injected known errors could validate the outcome flip assumption directly.
Load-bearing premise
Applying a diagnosis-specific patch in replay produces an outcome change that correctly signals the original error step without introducing unrelated new errors or biases.
What would settle it
Finding cases where the outcome flips after patching a step that was not the actual error, or fails to flip when it was, would disprove the validity of the attribution refinement.
Figures

read the original abstract
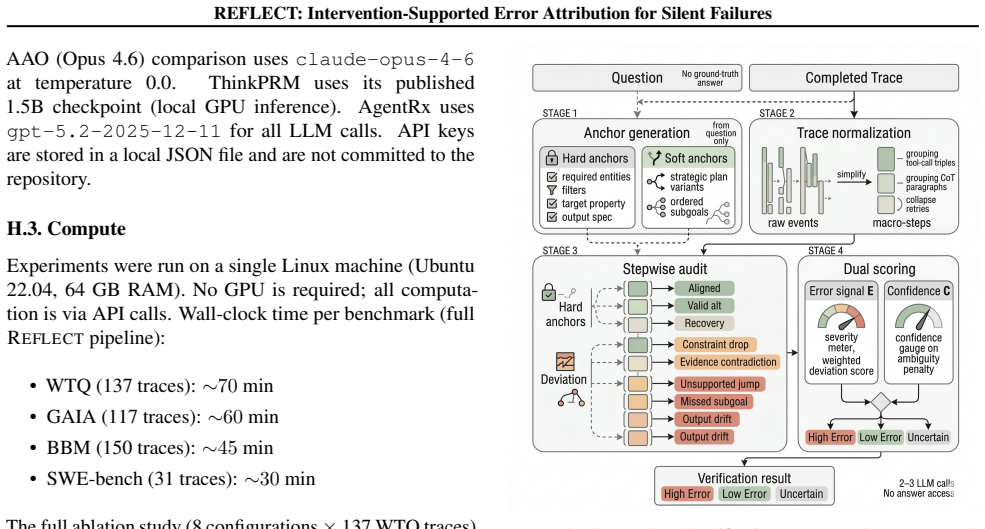
Large language model (LLM) agents now solve complex tasks through long plan-and-execution traces, yet the ability to locate errors in a completed traces still lags far behind, especially in the \emph{silent failure} regime. Existing approaches predict suspect steps via classifiers or LLM judges, or recover correct answers via retry, but none feed the intervention outcome back to \emph{refine the attribution itself}. We propose \methodname, a method that closes this gap by diagnosing a candidate error step, testing it through controlled replay with a diagnosis-specific patch, and using the verified outcome flip as contrastive evidence to refine the final attribution. Across four localization benchmarks spanning multi-hop reasoning across domains, \methodname achieves the highest localization accuracy among same-auditor methods across all four benchmarks, with the largest gains on structured tool-use traces, while providing actionable localization even when ground-truth answers are unavailable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REFLECT, a method for error attribution in LLM agent traces that focuses on silent failures. It diagnoses candidate error steps, applies diagnosis-specific patches during controlled replay, and uses verified outcome flips as contrastive evidence to refine the final attribution. The central empirical claim is that REFLECT achieves the highest localization accuracy among same-auditor methods across four multi-hop reasoning benchmarks spanning domains, with the largest gains on structured tool-use traces, while remaining actionable even without ground-truth answers.
Significance. If the replay-based feedback loop reliably isolates the original error without confounding from intervention side-effects, REFLECT would represent a meaningful advance in localizing errors within long LLM agent traces by closing the loop between diagnosis and verifiable outcome. The reported gains on tool-use traces and the ability to operate without ground truth would be practically useful for debugging complex agent behaviors.
major comments (1)
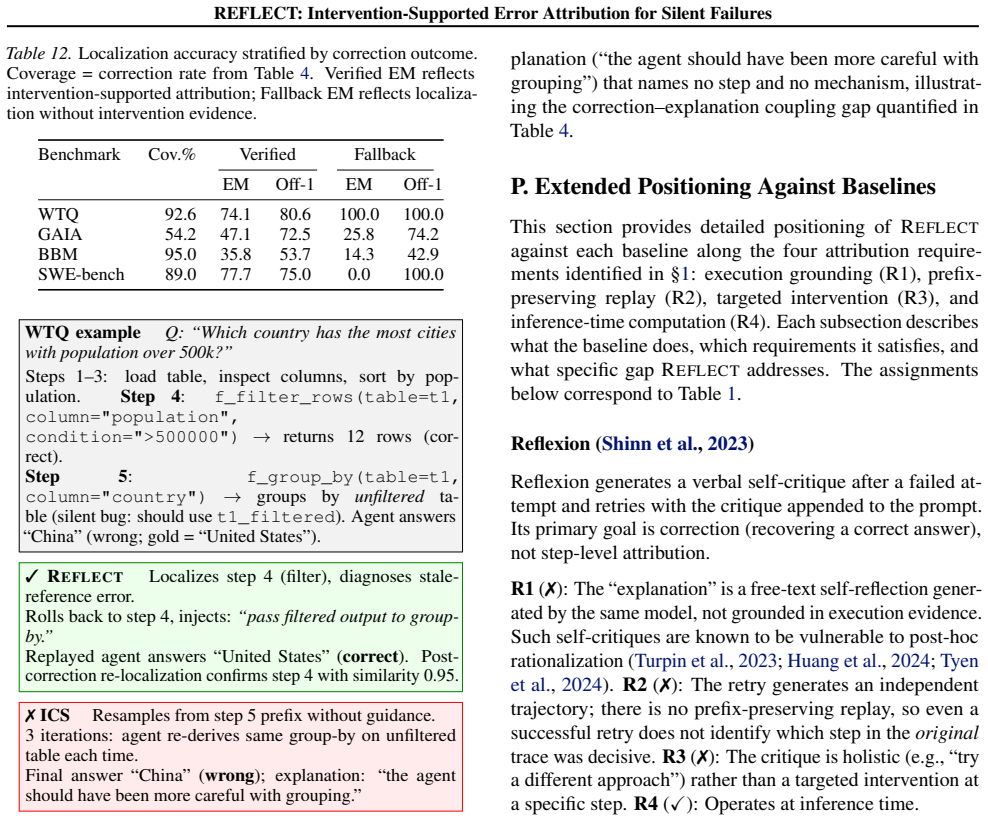
- [Abstract (method description)] The validity of treating an outcome flip after a diagnosis-specific patch as contrastive evidence for the original error step is load-bearing for the highest-accuracy claim (especially on silent failures). The abstract states that the method 'tests it through controlled replay with a diagnosis-specific patch, and using the verified outcome flip as contrastive evidence,' yet provides no description of patch minimality, replay isolation guarantees, or controls for intervention artifacts; without these, the flip could arise from altered execution paths or new failure modes rather than correction of the suspected step.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of methodological safeguards around the intervention-based evidence. The concern is well-taken and directly affects the interpretability of our highest-accuracy claims. We address it point-by-point below and commit to revisions that strengthen the presentation without altering the underlying experiments.
read point-by-point responses
-
Referee: The validity of treating an outcome flip after a diagnosis-specific patch as contrastive evidence for the original error step is load-bearing for the highest-accuracy claim (especially on silent failures). The abstract states that the method 'tests it through controlled replay with a diagnosis-specific patch, and using the verified outcome flip as contrastive evidence,' yet provides no description of patch minimality, replay isolation guarantees, or controls for intervention artifacts; without these, the flip could arise from altered execution paths or new failure modes rather than correction of the suspected step.
Authors: We agree that the abstract is too terse on these safeguards. The full manuscript (Section 3.2) specifies that patches are constructed to be minimal—altering only the output of the diagnosed step while preserving all prior trace context—and that replays are executed in a deterministic, isolated simulator that prevents downstream path divergence. Section 4.1 further reports control experiments in which non-error steps receive identical patches; outcome flips occur at significantly lower rates, providing evidence against artifact-driven flips. Nevertheless, because the abstract is the primary claim-bearing text, we will revise it to include a concise clause on minimality and isolation. This is a clarification rather than a change to the method or results. revision: yes
Circularity Check
No circularity; method relies on external replay outcomes
full rationale
The paper describes an empirical intervention-based attribution procedure that diagnoses candidate steps, applies patches in replay, and uses observed outcome flips as contrastive evidence. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations are present in the provided text. The central claim rests on external verification signals rather than any reduction of predictions to inputs by construction, satisfying the default expectation of non-circularity for methodological papers without mathematical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accessed 2026-02-26
URL http://data.europa.eu/eli/reg/ 2024/1689/oj. Accessed 2026-02-26. Gartner. Gartner survey finds just 15% of IT application leaders are considering, piloting, or deploying fully au- tonomous AI agents. https://www.gartner. com/en/newsroom/press-releases/ 2025-09-30-gartner-survey-finds-just-15-percent-of-it-application-leaders-are-considering-piloting-...
2024
-
[2]
Accessed 2026-03-14. Guo, D., DeepSeek-AI, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025. 8 REFLECT: Intervention-Supported Error Attribution for Silent Failures Guo, T., Chen, X., Wang, Y ., Chang, R., Pei, S., Chawla, N. V ., Wiest, O., and Zhang, X. Large language model ...
Pith/arXiv arXiv 2026
-
[3]
Online edition accessed 2026-02-26
URL https://sre.google/sre-book/ postmortem-culture/. Online edition accessed 2026-02-26. Ma, M., Zhang, J., Yang, F., Kang, Y ., Lin, Q., Rajmo- han, S., and Zhang, D. Dover: Intervention-driven auto debugging for llm multi-agent systems.arXiv preprint arXiv:2512.06749, 2025. Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, ...
arXiv 2026
-
[4]
GAIA: a benchmark for General AI Assistants
URL https://openreview.net/forum? id=S37hOerQLB. Mialon, G., Fourrier, C., Swift, C., Wolf, T., LeCun, Y ., and Scialom, T. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983, 2023. URL https://arxiv.org/abs/2311.12983. Moshkovich, D., Mulian, H., Zeltyn, S., Eder, N., Skar- bovsky, I., and Abitbol, R. Beyond black-box bench- mark...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3115/v1/p15-1142 2023
-
[5]
ROOT CAUSE: Why the agent chose wrongly
-
[6]
What EXACTLY to do instead
-
[7]
What the agent must NEVER do
-
[8]
root_cause
expected_next_tool: first tool token (e.g., f_sort_by), or null Respond in JSON: { "root_cause": "<explanation>", "correction_instruction": "<specific instruction>", "forbidden_actions": ["<action>", ...], "expected_next_tool": "<tool or null>", "confidence": <0.0-1.0> 11 REFLECT: Intervention-Supported Error Attribution for Silent Failures } A.4. Faithfu...
-
[9]
Does it follow the correction?
-
[10]
Does it violate any forbidden action?
-
[11]
is_faithful
Is it relevant, or has the agent drifted? Respond in JSON: { "is_faithful": <true or false>, "violation_reason": "<or null>", "violation_type": "<one of: repeats_original_error, ignores_instruction, uses_forbidden_action, unrelated_drift, or null>" } A.5. Repair System Injection Injected as a system message into the agent’s context at the rollback point. ...
2026
-
[12]
Which country has the most cities with population over 500k?
and use a span-tree structure; they are sourced from the TRAIL benchmark (Deshpande et al., 2025). We load 117 failing traces from data/trail/manifest.json. GAIA conversation states require special handling: spans are converted to LangGraph-compatible message for- mat by mapping each span to an assistant message (with tool calls) and a tool response messa...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.