Addressing Market Regime Changes and Heavy-Tailed Returns in Portfolio Optimization via Bayesian VAR and Elliptical Black-Litterman
Pith reviewed 2026-06-27 17:38 UTC · model grok-4.3
The pith
BAVAR-BLED embeds regime-aware Bayesian vector autoregression priors into an elliptical Black-Litterman model inside TD3 reinforcement learning to handle market shifts and fat-tailed returns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BAVAR captures multi-scale temporal features to generate adaptive, regime-aware estimates of return expectations and dispersion matrices that serve as priors for BLED; BLED then employs Student's t-distributions for realistic fat-tail modeling, with transformer-based view construction and CNN-based risk-aversion estimation modifying allocation decisions within the TD3 architecture.
What carries the argument
The BAVAR-BLED algorithm, which supplies BAVAR-derived regime-aware priors to BLED's elliptical-distribution framework inside a TD3 reinforcement-learning policy.
If this is right
- Allocations become sensitive to detected market regimes rather than treating all historical data uniformly.
- Return and risk estimates incorporate heavier tails, reducing over-exposure during extreme events.
- View construction and risk aversion adjust automatically via learned transformer and CNN modules.
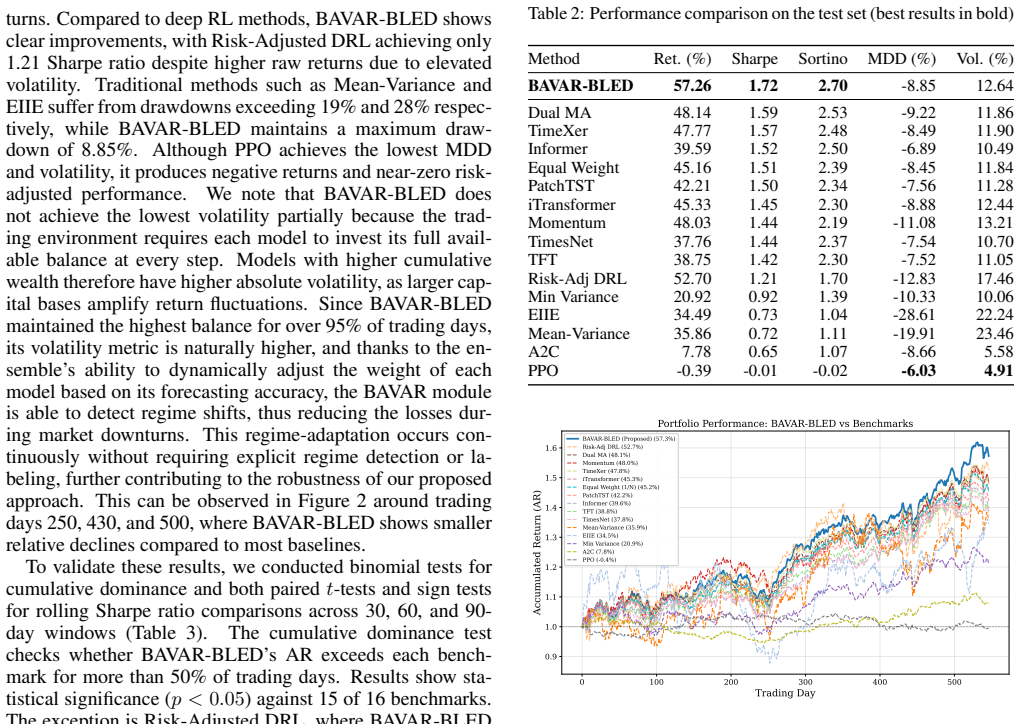
- The combined model yields higher realized Sharpe and Sortino ratios than prior DRL or mean-variance baselines on the tested DJIA panel.
Where Pith is reading between the lines
- The same prior-construction step could be inserted into other reinforcement-learning portfolio agents without changing their core policy networks.
- Extending the temporal scales inside BAVAR might improve detection of slower structural breaks such as regulatory regime shifts.
- Replacing the Student's t assumption in BLED with other elliptical distributions would allow direct comparison of tail modeling choices on the same DJIA panel.
Load-bearing premise
That the BAVAR-derived regime-aware estimates of return expectations and dispersion matrices produce allocation decisions that generalize beyond the specific decade of DJIA data used for evaluation.
What would settle it
Retraining and testing the identical BAVAR-BLED pipeline on a later out-of-sample decade or on a different equity universe and observing that Sharpe and Sortino ratios fall below the strongest baseline methods.
Figures

read the original abstract
Deep reinforcement learning (DRL) frameworks for portfolio optimization have shown promise for their ability to learn allocation rules dynamically from market data. However, these models fail to account for fat-tailed returns, which characterize actual market behavior with more frequent extreme events. Furthermore, historical data is treated homogeneously, without accounting for temporal importance, leading models to fail during regime changes. We propose a new BAVAR-BLED algorithm that combines methods derived from Bayesian-Averaging Vector Autoregressive (BAVAR) and the Black-Litterman model using Elliptical Distributions (BLED) within a TD3 architecture. BAVAR captures a set of vector autoregressive representations that consider multi-scale temporal features, enabling adaptive allocation decisions based on regime-aware estimates of return expectations and dispersion matrices. These estimates serve as prior inputs to BLED, a model that uses Student's t-distributions, allowing for more realistic fat tail return estimates. The BAVAR-BLED algorithm uses transformer networks for view construction and CNNs for risk-aversion estimates, which modify dynamic allocation decisions based on market conditions. An evaluation of 29 Dow Jones Industrial Average constituents over a decade-long market period shows that BAVAR-BLED significantly outperforms state-of-the-art methods, achieving Sharpe and Sortino ratios of 1.72 and 2.70, respectively, and total returns of 57.26%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the BAVAR-BLED algorithm, which combines Bayesian-Averaging Vector Autoregressive (BAVAR) models to produce regime-aware estimates of returns and dispersion matrices via multi-scale temporal averaging, with an Elliptical Black-Litterman model (BLED) that employs Student's t-distributions to capture fat-tailed returns; these priors are fed into a TD3 reinforcement learning policy that additionally uses transformers for view construction and CNNs for risk-aversion estimation. The central empirical claim is that this hybrid approach significantly outperforms state-of-the-art methods on 29 Dow Jones Industrial Average constituents over a single decade-long period, delivering a Sharpe ratio of 1.72, Sortino ratio of 2.70, and total return of 57.26%.
Significance. If the outperformance result is shown to hold under proper out-of-sample protocols, the work would be significant for the DRL portfolio optimization literature by supplying a concrete mechanism for injecting regime detection and heavy-tail modeling into allocation policies, potentially improving robustness during non-stationary market conditions.
major comments (2)
- [Abstract] Abstract: The reported Sharpe (1.72), Sortino (2.70), and total-return (57.26%) figures are presented with no accompanying description of train/test splits, held-out periods, number of observed regime transitions, or statistical significance tests. This is load-bearing for the central claim because the abstract supplies no basis on which to judge whether the metrics reflect generalization or quantities fitted during model development.
- [Evaluation section] Evaluation section: The back-test is performed on one contiguous decade of 29 DJIA names without reference to walk-forward analysis, rolling windows, or multiple distinct market regimes. Given that the number of observable regime transitions in a single decade is small, this design cannot separate the claimed generalization of the BAVAR-derived priors from period-specific serial correlation or kurtosis patterns captured by the model.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the clarity of our empirical claims and the robustness of the evaluation design. We address each major comment below and commit to revisions that improve transparency without altering the core methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported Sharpe (1.72), Sortino (2.70), and total-return (57.26%) figures are presented with no accompanying description of train/test splits, held-out periods, number of observed regime transitions, or statistical significance tests. This is load-bearing for the central claim because the abstract supplies no basis on which to judge whether the metrics reflect generalization or quantities fitted during model development.
Authors: We agree that the abstract should supply sufficient context for the reported metrics. The current abstract is intentionally concise, but the Evaluation section of the manuscript describes the decade-long back-test on the 29 DJIA constituents. In the revised manuscript we will expand the abstract to include a brief statement on the train/test split, held-out periods, and the fact that statistical significance was assessed relative to baselines. revision: yes
-
Referee: [Evaluation section] Evaluation section: The back-test is performed on one contiguous decade of 29 DJIA names without reference to walk-forward analysis, rolling windows, or multiple distinct market regimes. Given that the number of observable regime transitions in a single decade is small, this design cannot separate the claimed generalization of the BAVAR-derived priors from period-specific serial correlation or kurtosis patterns captured by the model.
Authors: The single-decade contiguous back-test was chosen to provide sufficient data for training the TD3 policy while still encompassing multiple market conditions (e.g., debt-ceiling events, oil shocks, and the onset of COVID-19) that the BAVAR multi-scale averaging is intended to detect as regime shifts. We nevertheless recognize that this design does not fully isolate generalization from period-specific patterns. We will therefore revise the Evaluation section to incorporate walk-forward analysis using rolling windows and to report the number of regime transitions identified within each window. revision: yes
Circularity Check
No circularity in derivation; empirical evaluation stands on external data benchmark
full rationale
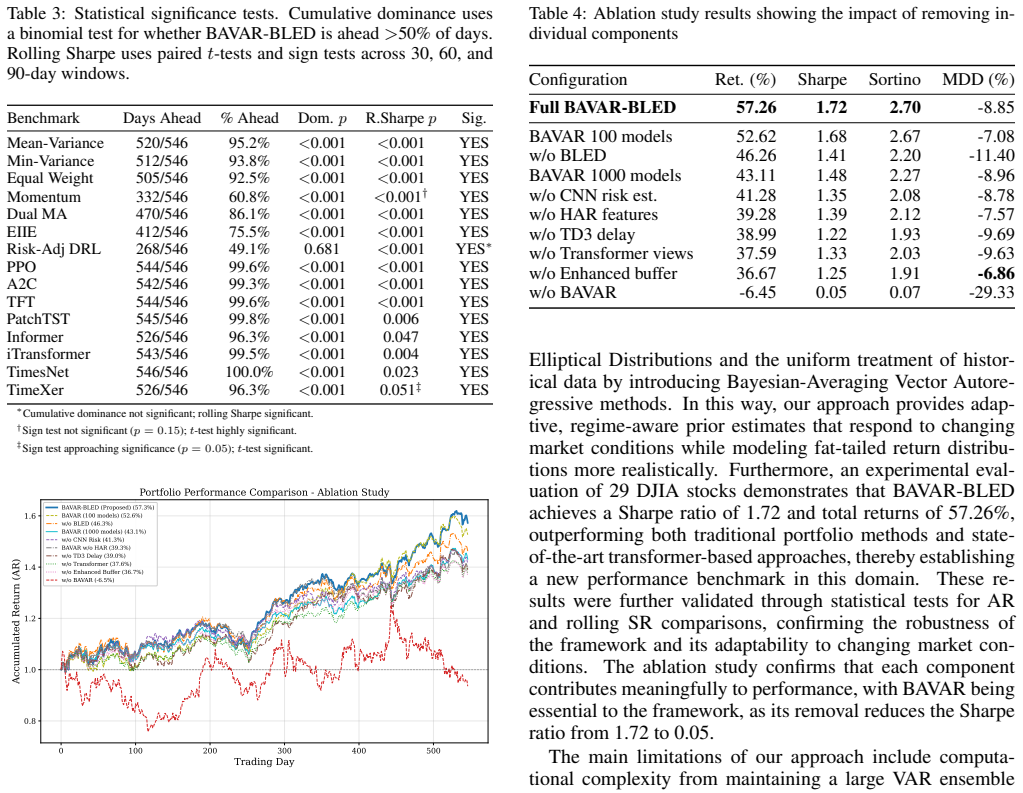
The paper's core contribution is an algorithmic combination of BAVAR for regime-aware priors and BLED for elliptical (Student-t) dispersion, embedded in a TD3 policy network, with performance measured on a fixed decade of 29 DJIA constituents. No equations, parameter-fitting steps, or self-citation chains are described in the abstract that would reduce any claimed prediction or uniqueness result to the input data by construction. The reported Sharpe/Sortino/return figures are presented as evaluation outcomes on an observable market dataset rather than quantities algebraically equivalent to fitted parameters or renamed known patterns. The single-contiguous-period nature of the test raises generalization questions but does not constitute a circular derivation under the enumerated patterns.
Axiom & Free-Parameter Ledger
free parameters (3)
- BAVAR scale and lag parameters
- BLED degrees of freedom and risk-aversion parameters
- TD3, transformer, and CNN hyperparameters
axioms (2)
- domain assumption Market returns admit a vector autoregressive representation at multiple temporal scales
- domain assumption Asset returns follow elliptical distributions (Student's t) that adequately capture heavy tails
Reference graph
Works this paper leans on
-
[1]
Portfolio choices with many big models
[Anderson and Cheng, 2022] Evan Anderson and Ai-ru Cheng. Portfolio choices with many big models. Management Science, 68(1):690–715,
2022
-
[2]
Algorithms for hyper- parameter optimization
[Bergstraet al., 2011 ] James Bergstra, R ´emi Bardenet, Yoshua Bengio, and Bal ´azs K ´egl. Algorithms for hyper- parameter optimization. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K.Q. Weinberger, editors, Advances in Neural Information Processing Systems, volume
2011
-
[3]
Global portfolio optimization.Financial analysts journal, 48(5):28–43,
[Black and Litterman, 1992] Fischer Black and Robert Lit- terman. Global portfolio optimization.Financial analysts journal, 48(5):28–43,
1992
-
[4]
Risk-adjusted deep re- inforcement learning for portfolio optimization: A multi- reward approach.International Journal of Computational Intelligence Systems, 18(1):126,
[Choudharyet al., 2025 ] Himanshu Choudhary, Arishi Orra, Kartik Sahoo, and Manoj Thakur. Risk-adjusted deep re- inforcement learning for portfolio optimization: A multi- reward approach.International Journal of Computational Intelligence Systems, 18(1):126,
2025
-
[5]
A simple approximate long- memory model of realized volatility.Journal of financial econometrics, 7(2):174–196,
[Corsi, 2009] Fulvio Corsi. A simple approximate long- memory model of realized volatility.Journal of financial econometrics, 7(2):174–196,
2009
-
[6]
Model averaging in ecology: A review of bayesian, information-theoretic, and tactical approaches for predictive inference.Ecological monographs, 88(4):485–504,
[Dormannet al., 2018 ] Carsten F Dormann, Justin M Cal- abrese, Gurutzeta Guillera-Arroita, Eleni Matechou, V olker Bahn, Kamil Barto´n, Colin M Beale, Simone Ciuti, Jane Elith, Katharina Gerstner, et al. Model averaging in ecology: A review of bayesian, information-theoretic, and tactical approaches for predictive inference.Ecological monographs, 88(4):485–504,
2018
-
[7]
Deep learning with long short-term memory net- works for financial market predictions.European journal of operational research, 270(2):654–669,
[Fischer and Krauss, 2018] Thomas Fischer and Christopher Krauss. Deep learning with long short-term memory net- works for financial market predictions.European journal of operational research, 270(2):654–669,
2018
-
[8]
[Frazziniet al., 2018 ] Andrea Frazzini, Ronen Israel, and Tobias J Moskowitz.Trading costs, volume 3229719. SSRN,
2018
-
[9]
Addressing function approximation error in actor-critic methods
[Fujimotoet al., 2018 ] Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. InInternational conference on ma- chine learning, pages 1587–1596. PMLR,
2018
-
[10]
Application of deep q- network in portfolio management
[Gaoet al., 2020 ] Ziming Gao, Yuan Gao, Yi Hu, Zhengy- ong Jiang, and Jionglong Su. Application of deep q- network in portfolio management. In2020 5th IEEE In- ternational Conference on Big Data Analytics (ICBDA), pages 268–275. IEEE,
2020
-
[11]
A framework of hierarchical deep q-network for portfolio management
[Gaoet al., 2021 ] Yuan Gao, Ziming Gao, Yi Hu, Sifan Song, Zhengyong Jiang, and Jionglong Su. A framework of hierarchical deep q-network for portfolio management. InICAART (2), pages 132–140,
2021
-
[12]
Mspm: A modularized and scalable multi-agent reinforcement learning-based system for financial portfo- lio management.Plos one, 17(2):e0263689,
[Huang and Tanaka, 2022] Zhenhan Huang and Fumihide Tanaka. Mspm: A modularized and scalable multi-agent reinforcement learning-based system for financial portfo- lio management.Plos one, 17(2):e0263689,
2022
-
[13]
Bayesian model averaging for analysis of lattice field the- ory results.Physical Review D, 103(11):114502,
[Jay and Neil, 2021] William I Jay and Ethan T Neil. Bayesian model averaging for analysis of lattice field the- ory results.Physical Review D, 103(11):114502,
2021
-
[14]
A portfolio model with risk control policy based on deep re- inforcement learning.Mathematics, 11(1):19,
[Jiang and Wang, 2022] Caiyu Jiang and Jianhua Wang. A portfolio model with risk control policy based on deep re- inforcement learning.Mathematics, 11(1):19,
2022
-
[15]
A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem
[Jianget al., 2017 ] Zhengyao Jiang, Dixing Xu, and Jinjun Liang. A deep reinforcement learning framework for the financial portfolio management problem.arXiv preprint arXiv:1706.10059,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Testing new property of elliptical model for stock returns distribution,
[Koldanov, 2019] Petr Koldanov. Testing new property of elliptical model for stock returns distribution,
2019
-
[17]
Multi-tail generalized ellip- tical distributions for asset returns.The Econometrics Journal, 12(2):272–291,
[Kringet al., 2009 ] Sebastian Kring, Svetlozar T Rachev, Markus H ¨ochst¨otter, Frank J Fabozzi, and Michele Leonardo Bianchi. Multi-tail generalized ellip- tical distributions for asset returns.The Econometrics Journal, 12(2):272–291,
2009
-
[18]
Temporal fusion transformers for interpretable multi-horizon time series forecasting.Inter- national journal of forecasting, 37(4):1748–1764,
[Limet al., 2021 ] Bryan Lim, Sercan ¨O Arık, Nicolas Lo- eff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting.Inter- national journal of forecasting, 37(4):1748–1764,
2021
-
[19]
Maximum drawdown.Risk Magazine, 17(10):99–102,
[Magdon-Ismail and Atiya, 2004] Malik Magdon-Ismail and Amir F Atiya. Maximum drawdown.Risk Magazine, 17(10):99–102,
2004
-
[20]
Portfolio selection
[Markowitz, 1952] Harry Markowitz. Portfolio selection. The Journal of Finance, 7(1):77–91,
1952
-
[21]
Deep reinforcement learning-based portfolio optimization with black-litterman model under elliptical distributions
[Mikriukovet al., 2025 ] Daniil Mikriukov, Ruoyu Sun, and Zhengyong Jiang. Deep reinforcement learning-based portfolio optimization with black-litterman model under elliptical distributions. In De-Shuang Huang, Chuanlei Zhang, Qinhu Zhang, and Yijie Pan, editors,Advanced In- telligent Computing Technology and Applications, pages 273–284, Singapore,
2025
-
[22]
[Nieet al., 2023 ] Yuqi Nie, Nam H
Springer Nature Singapore. [Nieet al., 2023 ] Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers,
2023
-
[23]
The distribution of stock returns.Journal of the american statistical associa- tion, 67(340):807–812,
[Officer, 1972] Robert Rupert Officer. The distribution of stock returns.Journal of the american statistical associa- tion, 67(340):807–812,
1972
-
[24]
Stable-baselines3: Reliable reinforcement learning implementations.Journal of machine learning research, 22(268):1–8,
[Raffinet al., 2021 ] Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations.Journal of machine learning research, 22(268):1–8,
2021
-
[25]
The sharpe ratio.Journal of Portfolio Management, 21(1):49–58,
[Sharpe, 1994] William F Sharpe. The sharpe ratio.Journal of Portfolio Management, 21(1):49–58,
1994
-
[26]
A multi-agent deep reinforcement learning framework for algorithmic trading in financial markets
[Shavandi and Khedmati, 2022] Ali Shavandi and Majid Khedmati. A multi-agent deep reinforcement learning framework for algorithmic trading in financial markets. Expert Systems with Applications, 208:118124,
2022
-
[27]
From deterministic to stochastic: an in- terpretable stochastic model-free reinforcement learning framework for portfolio optimization.Applied Intelli- gence, 53(12):15188–15203,
[Songet al., 2023 ] Zitao Song, Yining Wang, Pin Qian, Sifan Song, Frans Coenen, Zhengyong Jiang, and Jion- glong Su. From deterministic to stochastic: an in- terpretable stochastic model-free reinforcement learning framework for portfolio optimization.Applied Intelli- gence, 53(12):15188–15203,
2023
-
[28]
Performance measurement in a downside risk framework
[Sortino and Price, 1994] Frank A Sortino and Lee N Price. Performance measurement in a downside risk framework. the Journal of Investing, 3(3):59–64,
1994
-
[29]
Combining transformer based deep reinforcement learning with black-litterman model for portfolio optimization.Neural Computing and Applications, 36(32):20111–20146,
[Sunet al., 2024 ] Ruoyu Sun, Angelos Stefanidis, Zhengy- ong Jiang, and Jionglong Su. Combining transformer based deep reinforcement learning with black-litterman model for portfolio optimization.Neural Computing and Applications, 36(32):20111–20146,
2024
-
[30]
Timexer: Empow- ering transformers for time series forecasting with exoge- nous variables.Advances in Neural Information Process- ing Systems, 37:469–498,
[Wanget al., 2024 ] Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Guo Qin, Haoran Zhang, Yong Liu, Yunzhong Qiu, Jianmin Wang, and Mingsheng Long. Timexer: Empow- ering transformers for time series forecasting with exoge- nous variables.Advances in Neural Information Process- ing Systems, 37:469–498,
2024
-
[31]
Timesnet: Temporal 2d-variation modeling for general time series analysis,
[Wuet al., 2023 ] Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. Timesnet: Temporal 2d-variation modeling for general time series analysis,
2023
-
[32]
A black–litterman asset allocation model under elliptical distributions.Quantitative Finance, 15(3):509–519,
[Xiao and Valdez, 2015] Yugu Xiao and Emiliano A Valdez. A black–litterman asset allocation model under elliptical distributions.Quantitative Finance, 15(3):509–519,
2015
-
[33]
Deep reinforcement learning based on transformer and u-net framework for stock trading
[Yanget al., 2023 ] Bing Yang, Ting Liang, Jian Xiong, and Chong Zhong. Deep reinforcement learning based on transformer and u-net framework for stock trading. Knowledge-Based Systems, 262:110211,
2023
-
[34]
Finbpm: A framework for portfolio management-based financial in- vestor behavior perception model
[Zhanget al., 2024 ] Zhilu Zhang, Procheta Sen, Zimu Wang, Ruoyu Sun, Zhengyong Jiang, and Jionglong Su. Finbpm: A framework for portfolio management-based financial in- vestor behavior perception model. InProceedings of the 18th Conference of the European Chapter of the Associ- ation for Computational Linguistics (Volume 1: Long Pa- pers), pages 246–257,
2024
-
[35]
Informer: Beyond efficient transformer for long sequence time-series forecasting
[Zhouet al., 2021 ] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wan- cai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 11106–11115,
2021
-
[36]
Enhanc- ing portfolio optimization with transformer-gan integra- tion: A novel approach in the black-litterman framework, 2024
[Zhu and Yen, 2024] Enmin Zhu and Jerome Yen. Enhanc- ing portfolio optimization with transformer-gan integra- tion: A novel approach in the black-litterman framework, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.