DECSELFMASK: Leveraging Unlabeled Text via Self-Relevance-Guided Masking for Decoder-Only Classification
Pith reviewed 2026-06-27 16:34 UTC · model grok-4.3
The pith
Decoder-only models improve classification by reconstructing relevance-masked segments from unlabeled clinical notes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
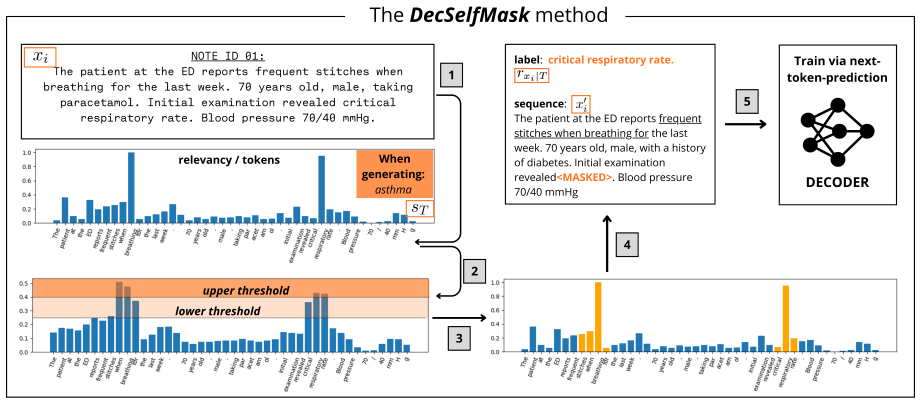
DecSelfMask creates self-supervised examples by using relevance attribution methods to identify and mask portions of unannotated texts that matter for a downstream task, then trains the decoder-only model to reconstruct those portions via next-token prediction, with the hypothesis that the resulting examples convey useful structural and semantic knowledge about the unlabeled data.
What carries the argument
Relevance-guided masking, which selects task-relevant text segments via attribution and masks them for reconstruction-based self-supervised training.
If this is right
- The method yields consistent gains on the 136 tasks, exceeding standard fine-tuning by 19.9 Macro F1 points.
- It also surpasses synthetic label generation by 12.5 points and continual pretraining by 6.3 points.
- Benefits appear across five decoder-only models of different scales and families.
- A probing analysis supports the utility of the generated self-supervised examples.
- The approach leverages the same unlabeled corpus for both masking and evaluation.
Where Pith is reading between the lines
- The masking strategy might transfer to other low-label domains such as legal or scientific text classification.
- Combining relevance masking with existing continual pretraining pipelines could compound the observed gains.
- Extending the relevance attribution step to multilingual or cross-domain unlabeled data would test broader applicability.
- If the attribution method itself is replaced by simpler heuristics, performance differences would isolate the contribution of the relevance step.
Load-bearing premise
Masking and reconstructing task-relevant parts of unlabeled texts produces training signals that improve downstream classification performance.
What would settle it
Running the full pipeline on the 136 clinical-note tasks and finding no Macro F1 gain or a loss relative to standard supervised fine-tuning would falsify the central claim.
Figures





read the original abstract
Classification tasks require annotated data, which can often be expensive, time-consuming, or even unfeasible to collect. This is the case of the medical domain, where large datasets often have few annotated examples. To address this, we propose DecSelfMask (Decoder Self-learning by Masking), an approach to enhance decoder-only performance on classification tasks. We build on common self-learning approaches by leveraging a model to create training examples from unlabeled data to propose a novel relevance-guided masking strategy. We use relevance attribution methods to determine what portions of unannotated texts are relevant for a task. We then create self-supervised training examples by masking out those portions, training the model to reconstruct them via next-token-prediction. We hypothesize that those examples convey knowledge about the structure and semantics of unannotated data that can be useful for downstream performance. We test our approach on 136 tasks from a collection of 1.9M clinical notes from an Italian hospital. We quantify DecSelfMask's impact on downstream tasks on 5 models of different scales and families, including a probing analysis. Experiments show consistent gains, outperforming standard supervised fine-tuning approaches (+19.9 points in Macro F1), synthetic label generation (+12.5), and continual pretraining (+6.3), as well as common baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DecSelfMask, a decoder-only self-learning method that applies relevance attribution to unlabeled clinical notes to identify task-relevant text spans, masks those spans, and trains the model via next-token prediction to reconstruct them. It evaluates the approach on 136 classification tasks derived from 1.9M Italian hospital notes across five models of varying scales, reporting consistent Macro F1 gains of +19.9 over standard supervised fine-tuning, +12.5 over synthetic label generation, and +6.3 over continual pretraining.
Significance. If the gains are shown to stem specifically from the relevance-guided masking rather than uncontrolled differences in data volume, token count, or training schedule, the method could provide a scalable way to improve low-resource classification in domains with abundant unlabeled text but scarce annotations, such as clinical NLP.
major comments (2)
- [Abstract] Abstract: the central claim of a +6.3 Macro F1 improvement over continual pretraining is load-bearing for the paper's contribution, yet the description does not specify whether the continual-pretraining baseline uses the identical 1.9M notes, the same total token count, the same masking ratio, or the same learning-rate schedule; without such controls the incremental value of relevance attribution cannot be isolated.
- [Abstract] Abstract (hypothesis paragraph): the claim that relevance-guided masking examples 'convey knowledge about the structure and semantics of unannotated data' is not directly tested against a random-masking or standard causal-LM baseline on the same unlabeled corpus; this leaves open whether any form of additional next-token training on the notes would produce comparable downstream gains.
minor comments (1)
- [Abstract] The abstract mentions 'a probing analysis' but provides no details on what is probed or how it supports the main results; this should be expanded in the methods or results section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for clearer experimental controls and hypothesis testing. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a +6.3 Macro F1 improvement over continual pretraining is load-bearing for the paper's contribution, yet the description does not specify whether the continual-pretraining baseline uses the identical 1.9M notes, the same total token count, the same masking ratio, or the same learning-rate schedule; without such controls the incremental value of relevance attribution cannot be isolated.
Authors: We agree that the abstract should explicitly note the matched conditions to isolate the contribution of relevance-guided masking. The full manuscript describes that the continual pretraining baseline was run on the identical 1.9M notes with matched total token counts and learning-rate schedules; the masking ratio applies only to DecSelfMask and is not relevant to the baseline. We will revise the abstract to state these controls clearly. revision: yes
-
Referee: [Abstract] Abstract (hypothesis paragraph): the claim that relevance-guided masking examples 'convey knowledge about the structure and semantics of unannotated data' is not directly tested against a random-masking or standard causal-LM baseline on the same unlabeled corpus; this leaves open whether any form of additional next-token training on the notes would produce comparable downstream gains.
Authors: The reported +6.3 Macro F1 improvement is measured against continual pretraining, which constitutes standard causal-LM (next-token prediction) training on the identical unlabeled corpus without relevance guidance. This comparison directly supports that the relevance-guided masking provides benefits beyond generic additional training. While an explicit random-masking ablation is not included, the existing baseline addresses the core concern; we will revise the abstract's hypothesis paragraph to emphasize this distinction. revision: partial
Circularity Check
No circularity: empirical method with independent experimental validation
full rationale
The paper proposes DecSelfMask, a relevance-guided masking procedure for self-supervised training on unlabeled clinical notes, followed by fine-tuning on downstream classification tasks. All reported gains (+19.9 Macro F1 over supervised fine-tuning, +6.3 over continual pretraining) are measured against external baselines on held-out annotated data. No equations, fitted parameters, or self-citations are presented as load-bearing derivations; the central hypothesis is tested via direct comparison rather than being presupposed by the method's definition. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Next-token prediction on masked text segments can transfer useful knowledge to downstream classification
- ad hoc to paper Relevance attribution methods can identify task-relevant text portions without task labels
invented entities (1)
-
relevance-guided masking strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2nd Clinical Natural Language Processing Workshop, pages 72–78, Minneapolis, Minnesota, USA
Publicly available clin- ical BERT embeddings. InProceedings of the 2nd Clinical Natural Language Processing Workshop, pages 72–78, Minneapolis, Minnesota, USA. Associ- ation for Computational Linguistics. Christopher M. Bishop. 2006.Pattern Recognition and Machine Learning. Springer, Berlin. Jean-Philippe Corbeil, Amin Dada, Jean-Michel At- tendu, Asma B...
2006
-
[2]
BERT: Pre-training of deep bidirectional transformers for language under- standing. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. David D...
2019
-
[3]
InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 14168–14181, Bangkok, Thailand
Looking right is sometimes right: Investigating the capabilities of decoder-only LLMs for sequence labeling. InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 14168–14181, Bangkok, Thailand. Association for Computational Linguistics. Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R. Costa-jussà
2024
-
[4]
A primer on the in- ner workings of transformer-based language models. Preprint, arXiv:2405.00208. Pietro Ferrazzi, Mattia Franzin, Alberto Lavelli, and Bernardo Magnini. 2026a. Small llms for medical nlp: a systematic analysis of few-shot, constraint decoding, fine-tuning and continual pre-training in italian.Preprint, arXiv:2602.17475. Pietro Ferrazzi, ...
arXiv 2026
-
[5]
InProceedings of the 2022 Conference on Empirical Methods in Nat- ural Language Processing, pages 1107–1119, Abu Dhabi, United Arab Emirates
Zero-shot text classification with self-training. InProceedings of the 2022 Conference on Empirical Methods in Nat- ural Language Processing, pages 1107–1119, Abu Dhabi, United Arab Emirates. Association for Com- putational Linguistics. Shahriar Golchin, Mihai Surdeanu, Nazgol Tavabi, and Ata Kiapour
2022
-
[6]
InProceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023), pages 13–21, Toronto, Canada
Do not mask randomly: Effective domain-adaptive pre-training by masking in-domain keywords. InProceedings of the 8th Workshop on Representation Learning for NLP (RepL4NLP 2023), pages 13–21, Toronto, Canada. Association for Com- putational Linguistics. Yuxian Gu, Zhengyan Zhang, Xiaozhi Wang, Zhiyuan Liu, and Maosong Sun
2023
-
[7]
InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6966–6974, Online
Train no evil: Selective masking for task-guided pre-training. InProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6966–6974, Online. Association for Computational Linguistics. Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
2020
-
[8]
InFindings of the Association for Computational Linguistics: NAACL 2025, pages 2795–2808, Albuquerque, New Mexico
Semi-supervised fine- tuning for large language models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 2795–2808, Albuquerque, New Mexico. Association for Computational Linguistics. Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie-Yan Liu
2025
-
[9]
InProceedings of the Seventh Italian Conference on Computational Linguistics (CLiC-it 2020), pages 190–196
The e3c project: Collection and annotation of a multi- lingual corpus of clinical cases. InProceedings of the Seventh Italian Conference on Computational Linguistics (CLiC-it 2020), pages 190–196. Avital Oliver, Augustus Odena, Colin Raffel, Ekin Do- gus Cubuk, and Ian Goodfellow
2020
-
[10]
InFindings of the Association for Computa- tional Linguistics: ACL 2025, pages 19889–19913, Vienna, Austria
How do LLMs acquire new knowledge? a knowledge circuits perspective on continual pre- training. InFindings of the Association for Computa- tional Linguistics: ACL 2025, pages 19889–19913, Vienna, Austria. Association for Computational Lin- guistics. Nafis Sadeq, Canwen Xu, and Julian McAuley
2025
-
[11]
InProceedings of the 2022 Conference on Empirical Methods in Natu- ral Language Processing, pages 5866–5878, Abu Dhabi, United Arab Emirates
InforMask: Unsupervised informative masking for language model pretraining. InProceedings of the 2022 Conference on Empirical Methods in Natu- ral Language Processing, pages 5866–5878, Abu Dhabi, United Arab Emirates. Association for Com- putational Linguistics. Stefan Schweter
2022
-
[12]
InInternational Conference on Learning Representa- tions, volume 2024, pages 25055–25083
Quantifying language models'sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. InInternational Conference on Learning Representa- tions, volume 2024, pages 25055–25083. Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, ...
2024
-
[13]
Medgemma technical report. Preprint, arXiv:2507.05201. Zhengxiang Shi, Francesco Tonolini, Nikolaos Aletras, Emine Yilmaz, Gabriella Kazai, and Yunlong Jiao
-
[14]
InFindings of the Association for Computational Linguistics: ACL 2023, pages 5614– 5634, Toronto, Canada
Rethinking semi-supervised learning with lan- guage models. InFindings of the Association for Computational Linguistics: ACL 2023, pages 5614– 5634, Toronto, Canada. Association for Computa- tional Linguistics. Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfoh...
2023
-
[15]
InProceedings of the 2008 Conference on Empirical Methods in Natural Language Process- ing, pages 254–263, Honolulu, Hawaii
Cheap and fast – but is it good? evaluating non-expert annotations for natural lan- guage tasks. InProceedings of the 2008 Conference on Empirical Methods in Natural Language Process- ing, pages 254–263, Honolulu, Hawaii. Association for Computational Linguistics. Jesper E. van Engelen and Holger H. Hoos
2008
-
[16]
InInternational Conference on Learning Representations, volume 2024, pages 21875–21895
Efficient streaming lan- guage models with attention sinks. InInternational Conference on Learning Representations, volume 2024, pages 21875–21895. Artur Yakimovich, Anaël Beaugnon, Yi Huang, and Elif Ozkirimli
2024
-
[17]
Predicting annotation difficulty to improve task routing and model perfor- mance for biomedical information extraction. InPro- ceedings of the 2019 Conference of the North Amer- ican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1471–1480, Min- neapolis, Minnesota. Associatio...
2019
-
[18]
InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7190–7202, Online and Punta Cana, Dominican Republic
On the influence of masking policies in intermediate pre-training. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7190–7202, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. Kayo Yin and Graham Neubig
2021
-
[19]
InPro- ceedings of the 2022 Conference on Empirical Meth- ods in Natural Language Processing, pages 184–198, Abu Dhabi, United Arab Emirates
Interpreting lan- guage models with contrastive explanations. InPro- ceedings of the 2022 Conference on Empirical Meth- ods in Natural Language Processing, pages 184–198, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Xiaojin Zhu
2022
-
[20]
duration of the patient’s consciousness recovery
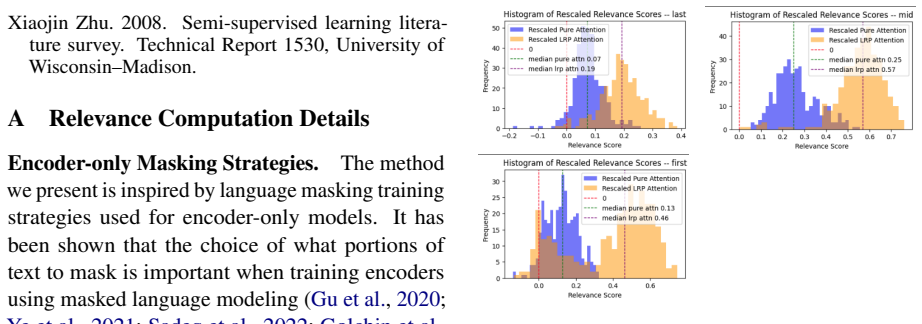
Semi-supervised learning litera- ture survey. Technical Report 1530, University of Wisconsin–Madison. A Relevance Computation Details Encoder-only Masking Strategies.The method we present is inspired by language masking training strategies used for encoder-only models. It has been shown that the choice of what portions of text to mask is important when tr...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.