Goal Sets, Not Goal States: Queryable Robot Goals through Goal-Set Hindsight Relabeling
Pith reviewed 2026-06-27 16:05 UTC · model grok-4.3
The pith
Goal-Set Hindsight Relabeling lets one offline-trained checkpoint answer multiple goal predicates by taking a binary query on success variables at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
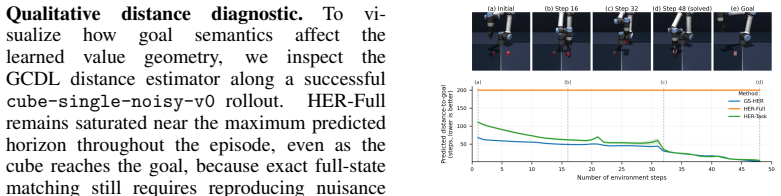
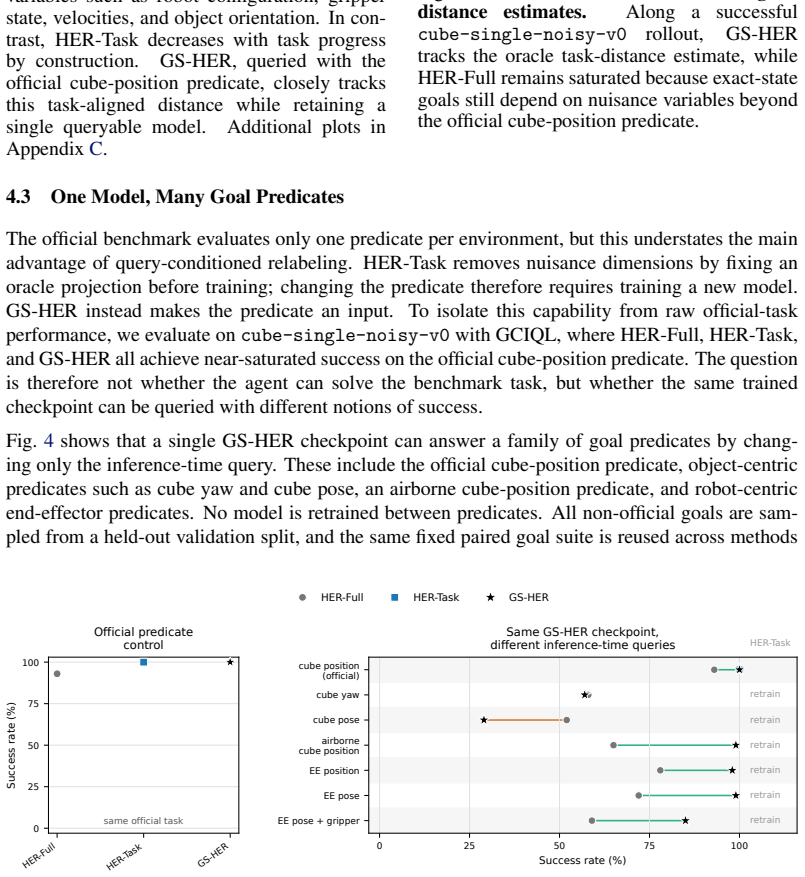
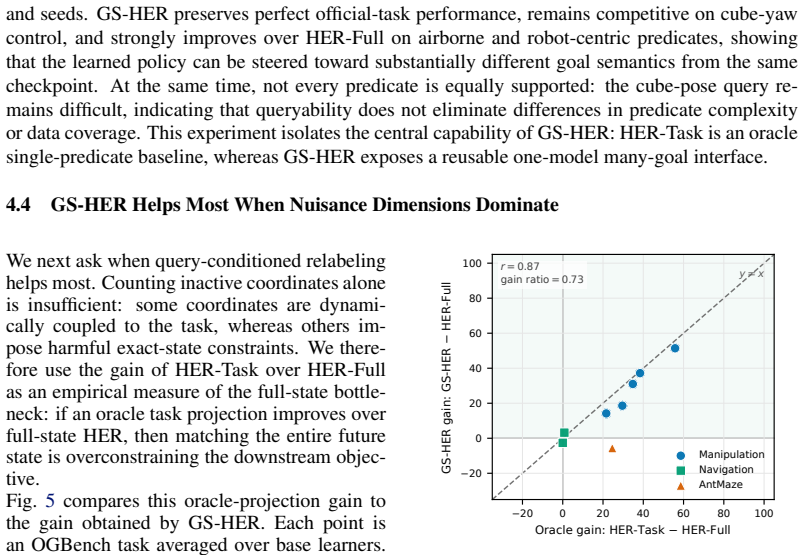
GS-HER is a predicate-level generalization of HER in which achieved states certify query-defined goal sets rather than singleton goal states. A binary query specifies which variables define success, making the goal predicate an inference-time input while leaving the underlying offline GCRL algorithm unchanged. This improves performance when full-state goals are bottlenecked by nuisance dimensions and turns hindsight relabeling into a reusable goal interface: one checkpoint can answer multiple robot goal predicates without retraining.
What carries the argument
Goal-Set Hindsight Relabeling (GS-HER), which replaces exact-state goal relabeling with query-defined goal sets that achieved states can satisfy.
If this is right
- Performance improves across OGBench tasks and five offline goal-conditioned learners when full-state goals are bottlenecked by nuisance dimensions.
- Hindsight relabeling becomes a reusable goal interface.
- One checkpoint can answer multiple robot goal predicates without retraining.
- The underlying offline GCRL algorithm and its training procedure stay unchanged.
Where Pith is reading between the lines
- The separation of the success predicate from the learned policy could simplify switching between related tasks after deployment.
- The same query mechanism might extend to other forms of experience relabeling that currently tie labels to full states.
- It opens a path for policies to respond to partial or context-dependent success criteria without additional offline data.
Load-bearing premise
The binary query specifying success variables can be supplied at inference time without requiring any change to the underlying offline GCRL algorithm or its training procedure.
What would settle it
An experiment on the OGBench tasks with the five offline goal-conditioned learners in which GS-HER produces no performance gain over standard HER when nuisance dimensions are present, or in which applying the binary query requires retraining the model.
Figures



read the original abstract
Hindsight relabeling usually turns achieved future states into exact goals, which can overconstrain offline robot learning when task success depends only on a subset of the state. We propose Goal-Set Hindsight Relabeling (GS-HER), a predicate-level generalization of HER in which achieved states certify query-defined goal sets rather than singleton goal states. A binary query specifies which variables define success, making the goal predicate an inference-time input while leaving the underlying offline GCRL algorithm unchanged. Across OGBench tasks and five offline goal-conditioned learners, GS-HER improves performance when full-state goals are bottlenecked by nuisance dimensions and turns hindsight relabeling into a reusable goal interface: one checkpoint can answer multiple robot goal predicates without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Goal-Set Hindsight Relabeling (GS-HER) as a predicate-level generalization of hindsight experience replay (HER) for offline goal-conditioned reinforcement learning. Rather than relabeling achieved states to exact singleton goal states, GS-HER relabels them to goal sets defined by a binary query over success variables. This makes the goal predicate an inference-time input that leaves the underlying offline GCRL algorithm and training procedure unchanged. The method is evaluated on OGBench tasks across five offline goal-conditioned learners and is claimed to improve performance when full-state goals are bottlenecked by nuisance dimensions while enabling one trained checkpoint to answer multiple robot goal predicates without retraining.
Significance. If the central claims hold, GS-HER would provide a reusable goal interface that mitigates over-constraining in offline GCRL and increases the flexibility of trained checkpoints for multi-predicate robot tasks. The approach directly addresses a practical bottleneck in goal-conditioned learning when only a subset of state dimensions matters for success.
major comments (2)
- [Abstract] Abstract: the claim that 'the binary query specifying success variables can be supplied at inference time while leaving the underlying offline GCRL algorithm unchanged' is load-bearing for the reusable-interface result. Standard GCRL conditions policies and critics on full goal states; supporting arbitrary binary masks at inference requires either additional conditioning on the mask or a query-dependent goal encoding, both of which alter the input interface or training distribution relative to the baseline algorithm.
- [Abstract] Abstract: the reported 'consistent gains across OGBench and five learners' are stated without any quantitative results, error bars, or implementation details. This prevents verification that the gains are attributable to the goal-set formulation rather than other factors and undermines assessment of the central performance claim.
minor comments (1)
- The abstract is clear on the high-level motivation but would benefit from a single sentence distinguishing GS-HER from prior set-based or predicate-based relabeling methods.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address each major comment below with point-by-point responses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the binary query specifying success variables can be supplied at inference time while leaving the underlying offline GCRL algorithm unchanged' is load-bearing for the reusable-interface result. Standard GCRL conditions policies and critics on full goal states; supporting arbitrary binary masks at inference requires either additional conditioning on the mask or a query-dependent goal encoding, both of which alter the input interface or training distribution relative to the baseline algorithm.
Authors: We agree that the original wording in the abstract overstates the case. GS-HER does introduce a query-dependent goal encoding to enable inference-time predicates, which modifies the input interface relative to standard GCRL baselines. The core training procedure of the underlying offline GCRL algorithm (actor-critic updates, etc.) remains unchanged, with the query used only for offline relabeling. We will revise the abstract to clarify this distinction and remove the claim that the algorithm is left entirely unchanged. revision: yes
-
Referee: [Abstract] Abstract: the reported 'consistent gains across OGBench and five learners' are stated without any quantitative results, error bars, or implementation details. This prevents verification that the gains are attributable to the goal-set formulation rather than other factors and undermines assessment of the central performance claim.
Authors: We acknowledge that the abstract presents the performance claim without supporting numbers. The full manuscript contains tables and figures with quantitative results, error bars, and implementation details for all five learners on OGBench. In the revision we will add concise quantitative highlights to the abstract where space permits, while ensuring they accurately reflect the full results. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents GS-HER as a direct conceptual generalization of hindsight experience replay to goal sets specified by binary queries at inference time. No equations, fitted parameters, or derivation steps are shown that reduce any claimed result to its own inputs by construction. The central assertion that the underlying offline GCRL algorithm and training procedure remain unchanged is a design statement about the method's interface, not a mathematical derivation or self-referential fit. The work is therefore self-contained as a proposed extension rather than a tautological renaming or self-citation load-bearing argument.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Offline GCRL algorithms can be left unchanged while only the relabeling step is modified.
Reference graph
Works this paper leans on
-
[1]
Andrychowicz, F
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. To- bin, O. Pieter Abbeel, and W. Zaremba. Hindsight experience replay.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Schaul, D
T. Schaul, D. Horgan, K. Gregor, and D. Silver. Universal value function approximators. In International conference on machine learning, pages 1312–1320. PMLR, 2015
2015
-
[3]
S. Park, K. Frans, B. Eysenbach, and S. Levine. Ogbench: Benchmarking offline goal- conditioned rl. InInternational Conference on Learning Representations, volume 2025, pages 94937–94982, 2025
2025
-
[4]
L. P. Kaelbling. Learning to achieve goals. InIJCAI, volume 2, pages 1094–8, 1993
1993
-
[5]
Lynch, M
C. Lynch, M. Khansari, T. Xiao, V . Kumar, J. Tompson, S. Levine, and P. Sermanet. Learning latent plans from play. InConference on robot learning, pages 1113–1132. Pmlr, 2020
2020
- [6]
-
[7]
Y . Ding, C. Florensa, P. Abbeel, and M. Phielipp. Goal-conditioned imitation learning.Ad- vances in neural information processing systems, 32, 2019
2019
-
[8]
Offline Reinforcement Learning with Implicit Q-Learning
I. Kostrikov, A. Nair, and S. Levine. Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Eysenbach, T
B. Eysenbach, T. Zhang, S. Levine, and R. R. Salakhutdinov. Contrastive learning as goal- conditioned reinforcement learning.Advances in Neural Information Processing Systems, 35: 35603–35620, 2022
2022
-
[10]
S. Park, D. Ghosh, B. Eysenbach, and S. Levine. Hiql: Offline goal-conditioned rl with latent states as actions.Advances in Neural Information Processing Systems, 36:34866–34891, 2023
2023
-
[11]
A. V . Nair, V . Pong, M. Dalal, S. Bahl, S. Lin, and S. Levine. Visual reinforcement learning with imagined goals.Advances in neural information processing systems, 31, 2018
2018
- [12]
-
[13]
Florensa, D
C. Florensa, D. Held, X. Geng, and P. Abbeel. Automatic goal generation for reinforcement learning agents. InInternational conference on machine learning, pages 1515–1528. PMLR, 2018
2018
- [14]
-
[15]
Gehring, G
J. Gehring, G. Synnaeve, A. Krause, and N. Usunier. Hierarchical skills for efficient explo- ration.Advances in Neural Information Processing Systems, 34:11553–11564, 2021
2021
-
[16]
Hafner, K.-H
D. Hafner, K.-H. Lee, I. Fischer, and P. Abbeel. Deep hierarchical planning from pixels. Advances in Neural Information Processing Systems, 35:26091–26104, 2022. 9
2022
-
[17]
Chebotar, K
Y . Chebotar, K. Hausman, Y . Lu, T. Xiao, D. Kalashnikov, J. Varley, A. Irpan, B. Eysenbach, R. C. Julian, C. Finn, et al. Actionable models: Unsupervised offline reinforcement learning of robotic skills. InInternational Conference on Machine Learning, pages 1518–1528. PMLR, 2021
2021
-
[18]
R. S. Sutton, D. Precup, and S. Singh. Between mdps and semi-mdps: A framework for tem- poral abstraction in reinforcement learning.Artificial intelligence, 112(1-2):181–211, 1999
1999
-
[19]
Bacon, J
P.-L. Bacon, J. Harb, and D. Precup. The option-critic architecture. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
2017
-
[20]
Nachum, S
O. Nachum, S. S. Gu, H. Lee, and S. Levine. Data-efficient hierarchical reinforcement learning. Advances in neural information processing systems, 31, 2018
2018
-
[21]
Diversity is All You Need: Learning Skills without a Reward Function
B. Eysenbach, A. Gupta, J. Ibarz, and S. Levine. Diversity is all you need: Learning skills without a reward function.arXiv preprint arXiv:1802.06070, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [22]
- [23]
-
[24]
Unsupervised Control Through Non-Parametric Discriminative Rewards
D. Warde-Farley, T. Van de Wiele, T. Kulkarni, C. Ionescu, S. Hansen, and V . Mnih. Unsupervised control through non-parametric discriminative rewards.arXiv preprint arXiv:1811.11359, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [25]
-
[26]
Near-Optimal Representation Learning for Hierarchical Reinforcement Learning
O. Nachum, S. Gu, H. Lee, and S. Levine. Near-optimal representation learning for hierarchical reinforcement learning.arXiv preprint arXiv:1810.01257, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Co-Reyes, Y
J. Co-Reyes, Y . Liu, A. Gupta, B. Eysenbach, P. Abbeel, and S. Levine. Self-consistent trajec- tory autoencoder: Hierarchical reinforcement learning with trajectory embeddings. InInterna- tional conference on machine learning, pages 1009–1018. PMLR, 2018
2018
-
[28]
Mendonca, O
R. Mendonca, O. Rybkin, K. Daniilidis, D. Hafner, and D. Pathak. Discovering and achieving goals via world models.Advances in neural information processing systems, 34:24379–24391, 2021. 10 A Main Results Table Table 1:Main OGBench results.Average binary success rate (%) across the five official test-time goals for each task and backbone. We compare full-...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.