Integrating gene regulatory priors into Transformer attention with scTransformer for interpretable scRNA-seq analysis
Pith reviewed 2026-06-27 14:09 UTC · model grok-4.3
The pith
Constraining Transformer attention to known gene regulatory structures produces more biologically meaningful representations for single-cell RNA analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
scTransformer is the first Transformer-based method that builds a priori knowledge of biological mechanisms into attention patterns by constraining information flow according to known regulatory structures; on a supervised cell-type classification task it improves accuracy over standard Transformers, produces better-separated cell-type embeddings, and yields attention patterns consistent with known regulatory programs.
What carries the argument
The constrained attention mechanism that restricts information flow between genes according to known regulatory structures.
If this is right
- Classification accuracy on cell-type labels rises relative to an unconstrained Transformer.
- Cell-type clusters become more clearly separated in the learned embedding space.
- Attention weights align with independently known gene regulatory programs.
- Interpretability improves while predictive performance is retained.
Where Pith is reading between the lines
- The same prior-constrained attention could be applied to other single-cell tasks such as trajectory inference or perturbation prediction.
- If attention still highlights edges absent from the prior, those edges could serve as hypotheses for new regulatory links.
- The method supplies one concrete route toward foundation models whose internal computations remain legible to biologists.
Load-bearing premise
The gene regulatory priors supplied to the model are accurate and complete enough for the given dataset and task that restricting attention to them helps rather than harms learning of task-relevant patterns.
What would settle it
On the same held-out single-nucleus dataset, a version of the model that receives the regulatory priors shows lower classification accuracy or attention weights that systematically contradict published regulatory interactions.
Figures

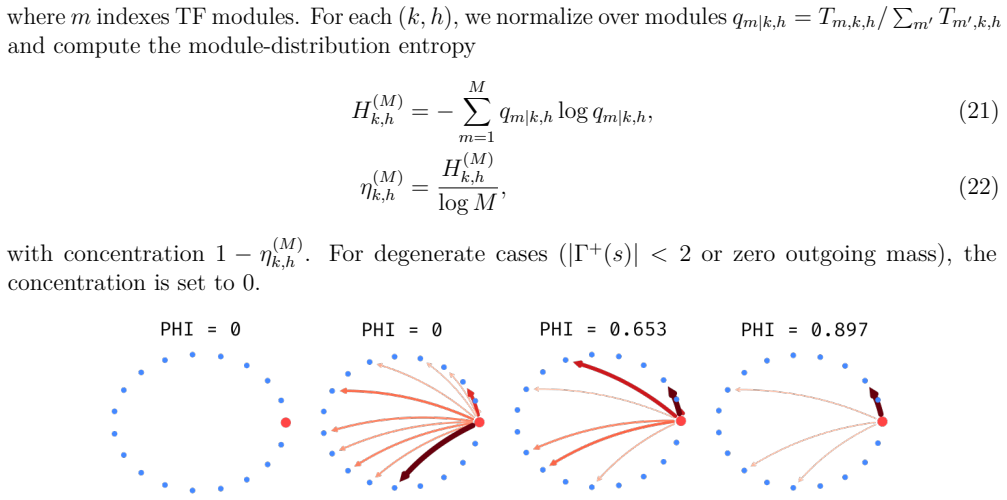

read the original abstract
Motivation: Transformer-based models are increasingly applied to large-scale single-cell transcriptomics, showing strong performance through self-supervised learning on millions of cells. However, most existing approaches treat genes as independent features, and largely ignore prior biological knowledge, which limits interpretability and robustness. In this paper, we explore whether explicitly incorporating gene regulatory information can improve both model performance and biological insight. Results: We present scTransformer, the first Transformer-based approach that builds a priori knowledge of biological mechanisms into the model's attention patterns. By constraining information flow according to known regulatory structures, the model learns representations that are more biologically meaningful. We evaluate scTransformer on a disease-relevant single-nucleus RNA-seq dataset using supervised cell-type classification. Compared to standard Transformers, our approach improves classification accuracy, enhances separation of cell types in embedding space, and produces attention patterns consistent with known regulatory programs. Overall, our results demonstrate that embedding biological structure into Transformer models can enhance interpretability without sacrificing performance, offering a principled step toward biologically grounded foundation models for single-cell omics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces scTransformer, a Transformer model for scRNA-seq analysis that incorporates gene regulatory network (GRN) priors by constraining attention patterns according to known regulatory structures. On a supervised cell-type classification task with a disease-relevant snRNA-seq dataset, it claims higher accuracy, better cell-type separation in embeddings, and attention weights consistent with known programs relative to standard Transformers, arguing that this yields more biologically meaningful representations without performance loss.
Significance. If the central claim holds after addressing evaluation gaps, the work would be significant for showing how external biological priors can be embedded into attention mechanisms to improve interpretability in single-cell foundation models. It directly targets the limitation of treating genes as independent features and provides a concrete mechanism for grounding Transformers in regulatory biology.
major comments (2)
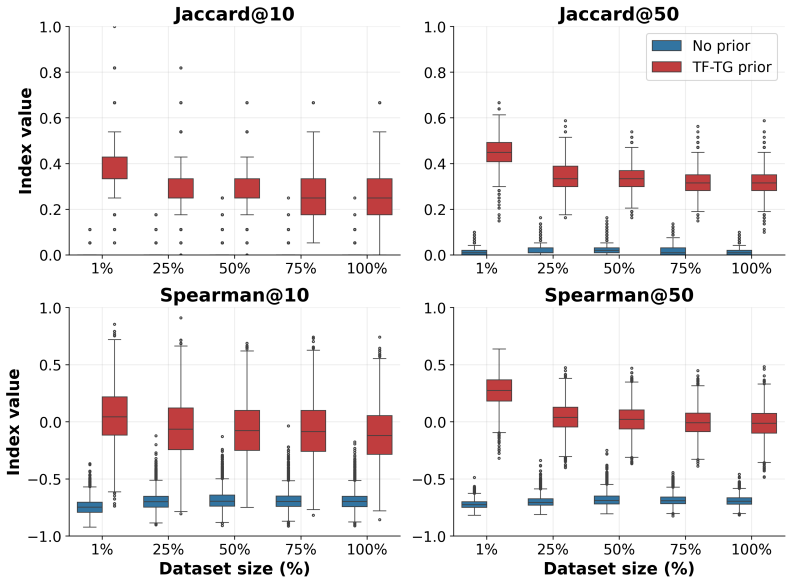
- [Results] Results section (evaluation on cell-type classification): the reported gains in accuracy and embedding separation are not tested against a sparsity-matched control using random or shuffled GRN masks of equivalent density. This control is required to establish that improvements arise from the biological content of the priors rather than from attention sparsity or regularization alone; without it the causal attribution to regulatory structure remains untested.
- [Methods] Methods section (attention mask construction): the manuscript does not specify how the GRN is converted into the attention mask, the density of the resulting mask, or whether the same mask is applied uniformly across heads/layers. These details are load-bearing for reproducing the claimed attention consistency with known programs and for assessing whether the prior is truly parameter-free.
minor comments (1)
- [Abstract] Abstract: quantitative metrics (accuracy deltas, embedding metrics, statistical tests) and the exact dataset identifier are omitted, which reduces clarity even for a high-level summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important gaps in our evaluation and methods description. We agree that addressing these points will strengthen the manuscript's claims regarding the role of biological priors. Below we respond point-by-point to the major comments and indicate the planned revisions.
read point-by-point responses
-
Referee: [Results] Results section (evaluation on cell-type classification): the reported gains in accuracy and embedding separation are not tested against a sparsity-matched control using random or shuffled GRN masks of equivalent density. This control is required to establish that improvements arise from the biological content of the priors rather than from attention sparsity or regularization alone; without it the causal attribution to regulatory structure remains untested.
Authors: We agree that a sparsity-matched control is necessary to isolate the contribution of the biological content in the GRN priors from the effects of attention sparsity alone. In the revised manuscript we will add experiments comparing scTransformer against models using random and shuffled GRN masks of matched density on the same supervised cell-type classification task, reporting accuracy, embedding separation metrics, and attention consistency. This will allow direct assessment of whether the observed gains are attributable to regulatory structure. revision: yes
-
Referee: [Methods] Methods section (attention mask construction): the manuscript does not specify how the GRN is converted into the attention mask, the density of the resulting mask, or whether the same mask is applied uniformly across heads/layers. These details are load-bearing for reproducing the claimed attention consistency with known programs and for assessing whether the prior is truly parameter-free.
Authors: We acknowledge that the current Methods section lacks these implementation details. In the revision we will explicitly describe the procedure for converting the GRN into the binary attention mask (including any thresholding or edge selection steps), report the resulting mask density, and state whether the identical mask is applied across all heads and layers or if head/layer-specific variations are used. These additions will enable full reproducibility and clarify the parameter-free nature of the prior. revision: yes
Circularity Check
No significant circularity; model uses external priors
full rationale
The paper defines scTransformer by imposing known external gene regulatory network structures as attention constraints in a Transformer. This architectural choice is independent of the target dataset and task outputs. Performance claims rest on supervised evaluation (cell-type classification accuracy, embedding separation) rather than any fitted parameter being relabeled as a prediction or any self-citation chain. The derivation chain is self-contained against external benchmarks and does not reduce by construction to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Known gene regulatory structures accurately reflect the biological mechanisms relevant to the dataset and task
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[2]
scgpt: toward building a foundation model for single-cell multi-omics using generative ai.Nature methods, 21(8):1470–1480, 2024
Haotian Cui, Chloe Wang, Hassaan Maan, Kuan Pang, Fengning Luo, Nan Duan, and Bo Wang. scgpt: toward building a foundation model for single-cell multi-omics using generative ai.Nature methods, 21(8):1470–1480, 2024
2024
-
[3]
Transfer learning enables predictions in network biology.Nature, 618(7965):616–624, 2023
Christina V Theodoris, Ling Xiao, Anant Chopra, Mark D Chaffin, Zeina R Al Sayed, Matthew C Hill, Helene Mantineo, Elizabeth M Brydon, Zexian Zeng, X Shirley Liu, et al. Transfer learning enables predictions in network biology.Nature, 618(7965):616–624, 2023
2023
-
[4]
Zero-shot evaluation reveals limitations of single-cell foundation models.Genome Biology, 26(1):101, 2025
Kasia Z Kedzierska, Lorin Crawford, Ava P Amini, and Alex X Lu. Zero-shot evaluation reveals limitations of single-cell foundation models.Genome Biology, 26(1):101, 2025
2025
-
[5]
Benchmark and integration of resources for the estimation of human transcription factor activities.Genome research, 29(8):1363–1375, 2019
Luz Garcia-Alonso, Christian H Holland, Mahmoud M Ibrahim, Denes Turei, and Julio Saez- Rodriguez. Benchmark and integration of resources for the estimation of human transcription factor activities.Genome research, 29(8):1363–1375, 2019
2019
-
[6]
Expanding the coverage of regulons from high-confidence prior knowledge for accurate estimation of transcription factor activities.Nucleic acids research, 51(20):10934–10949, 2023
Sophia Müller-Dott, Eirini Tsirvouli, Miguel Vazquez, Ricardo O Ramirez Flores, Pau Badia-i Mompel, Robin Fallegger, Dénes Türei, Astrid Lægreid, and Julio Saez-Rodriguez. Expanding the coverage of regulons from high-confidence prior knowledge for accurate estimation of transcription factor activities.Nucleic acids research, 51(20):10934–10949, 2023
2023
-
[7]
Scenic: single-cell regulatory network inference and clustering.Nature methods, 14(11):1083–1086, 2017
Sara Aibar, Carmen Bravo González-Blas, Thomas Moerman, Vân Anh Huynh-Thu, Hana Imrichova, Gert Hulselmans, Florian Rambow, Jean-Christophe Marine, Pierre Geurts, Jan Aerts, et al. Scenic: single-cell regulatory network inference and clustering.Nature methods, 14(11):1083–1086, 2017
2017
-
[8]
Transfer of regulatory knowledge from human to mouse for functional genomics analysis.Biochimica et Biophysica Acta (BBA)-Gene Regulatory Mechanisms, 1863(6):194431, 2020
Christian H Holland, Bence Szalai, and Julio Saez-Rodriguez. Transfer of regulatory knowledge from human to mouse for functional genomics analysis.Biochimica et Biophysica Acta (BBA)-Gene Regulatory Mechanisms, 1863(6):194431, 2020
2020
-
[9]
scbert as a large-scale pretrained deep language model for cell type annotation of single-cell rna-seq data.Nature machine intelligence, 4(10):852–866, 2022
Fan Yang, Wenchuan Wang, Fang Wang, Yuan Fang, Duyu Tang, Junzhou Huang, Hui Lu, and Jianhua Yao. scbert as a large-scale pretrained deep language model for cell type annotation of single-cell rna-seq data.Nature machine intelligence, 4(10):852–866, 2022
2022
-
[10]
scformer: a universal representation learning approach for single-cell data using transformers.bioRxiv, pages 2022–11, 2022
Haotian Cui, Chloe Wang, Hassaan Maan, Nan Duan, and Bo Wang. scformer: a universal representation learning approach for single-cell data using transformers.bioRxiv, pages 2022–11, 2022
2022
-
[11]
Population-scale cross-disorder atlas of the human prefrontal cortex at single-cell resolution.Scientific Data, 12(1):954, 2025
John F Fullard, Prashant Nm, Donghoon Lee, Deepika Mathur, Karen Therrien, Aram Hong, Clara Casey, Zhiping Shao, Marcela Alvia, Stathis Argyriou, et al. Population-scale cross-disorder atlas of the human prefrontal cortex at single-cell resolution.Scientific Data, 12(1):954, 2025. 13
2025
-
[12]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. On layer normalization in the transformer architecture. InInternational conference on machine learning, pages 10524–10533. PMLR, 2020
2020
-
[13]
Language modeling with gated convolutional networks
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. InInternational conference on machine learning, pages 933–941. PMLR, 2017
2017
-
[14]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020. 14 Supplementary Material This Supplementary Material reports the operational details underlying the experiments in the main text. It includes precise specifications of data preprocessing, batching construction, distributed training setup, and reproducibility controls. A...
work page internal anchor Pith review Pith/arXiv arXiv 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.