From 0-to-1 to 1-to-N: Reproducible Engineering Evidence for MetaAI Recursive Self-Design
Pith reviewed 2026-06-27 16:38 UTC · model grok-4.3
The pith
A four-criteria operational framework identifies recursive self-design in AI systems, with DGM supplying the clearest published evidence through benchmark gains after 80 iterations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
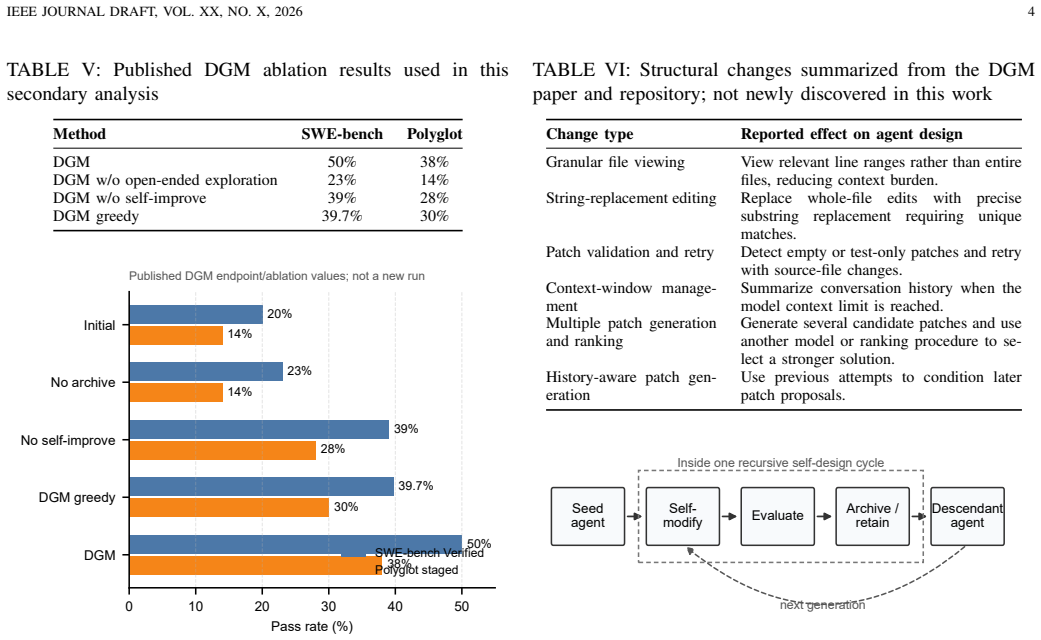
Recursive self-design can be identified in published systems by checking four criteria—an inspectable target system, a meta-level modifier, feedback-directed selection, and recursive continuation—and the Darwin Goedel Machine currently supplies the most direct evidence by demonstrating cumulative performance gains on software-engineering benchmarks after repeated self-modification cycles.
What carries the argument
The four-criteria operational evidence framework that maps published systems onto the definition of recursive self-design.
If this is right
- Systems that meet all four criteria are expected to exhibit cumulative gains on relevant benchmarks across iterations.
- Ablation results from DGM indicate that both open-ended exploration and self-improvement loops are required for the observed lifts.
- MetaAI-Mini supplies a concrete, HumanEval-based starting protocol that other groups can run to generate comparable data.
- Mapping additional systems such as STOP, Goedel Agent, and ShinkaEvolve against the same criteria produces a classification of current MetaAI efforts.
Where Pith is reading between the lines
- If the framework holds, future work could deliberately engineer systems to satisfy the four criteria from the outset rather than retrofitting them.
- The absence of a completed experimental run in the MetaAI-Mini release means the protocol itself must still be validated at scale by independent groups.
- The same criteria could be tested on non-code domains such as automated scientific workflow design to check whether the pattern generalizes.
Load-bearing premise
The four criteria are treated as an adequate operational definition that can reliably identify genuine recursive self-design when applied to published systems.
What would settle it
A system that satisfies all four criteria yet produces no measurable benchmark improvement after repeated self-modification iterations would falsify the central claim.
Figures
read the original abstract
Recursive self-design refers to AI-assisted modification of the mechanisms by which an AI system is built, evaluated, and improved. This paper treats MetaAI not as a mature paradigm, but as a working term for a human-seeded, AI-expanded development pattern in which the design space itself becomes a target of modification. We propose an operational evidence framework with four criteria: inspectable target system, meta-level modifier, feedback-directed selection, and recursive continuation. We then map public systems, including Darwin Goedel Machine (DGM), STOP, Goedel Agent, and ShinkaEvolve, against these criteria. DGM provides the most direct currently reported evidence: its published results show improvement from 20% to 50% on SWE-bench Verified and from 14.2% to 30.7% on full Polyglot after 80 iterations, with ablations suggesting that both open-ended exploration and self-improvement contribute. Finally, we provide MetaAI-Mini, a reproducible HumanEval-based protocol and codebase. Because no completed model run is included in this build, MetaAI-Mini is reported as a protocol rather than as an experimental result.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an operational evidence framework with four criteria (inspectable target system, meta-level modifier, feedback-directed selection, and recursive continuation) for identifying recursive self-design in AI systems. It maps several published systems against these criteria and identifies the Darwin Gödel Machine (DGM) as supplying the strongest evidence, citing published benchmark gains from 20% to 50% on SWE-bench Verified and from 14.2% to 30.7% on full Polyglot after 80 iterations, with ablations on exploration and self-improvement. The paper also presents MetaAI-Mini, a reproducible HumanEval-based protocol and codebase, explicitly noting that it is offered as a protocol rather than a completed experimental result.
Significance. If the four-criteria framework can be made sufficiently precise to distinguish recursive self-design from standard iterative optimization, the work could help standardize assessment of self-modifying AI claims and highlight the value of systems like DGM. The explicit provision of a codebase for the MetaAI-Mini protocol is a concrete strength that supports reproducibility efforts in the area.
major comments (1)
- [Section introducing the four criteria] The section introducing the four criteria: these criteria are stated at a high level without formal predicates, boundary cases, or explicit exclusion rules. As a result, a conventional evolutionary search or RL loop with a fixed outer mechanism could satisfy all four, which directly affects the load-bearing claim that DGM supplies the most direct evidence for genuine recursive self-design.
minor comments (1)
- [Abstract and conclusion] The abstract and conclusion should explicitly restate that all DGM benchmark numbers and ablation results are taken from prior published work rather than re-derived or extended in this manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the criteria section. We agree that greater precision is needed and will revise accordingly.
read point-by-point responses
-
Referee: [Section introducing the four criteria] The section introducing the four criteria: these criteria are stated at a high level without formal predicates, boundary cases, or explicit exclusion rules. As a result, a conventional evolutionary search or RL loop with a fixed outer mechanism could satisfy all four, which directly affects the load-bearing claim that DGM supplies the most direct evidence for genuine recursive self-design.
Authors: We agree that the four criteria are presented at a high level and currently lack formal predicates, boundary cases, and explicit exclusion rules. This limitation means that standard iterative optimization methods could plausibly satisfy them, weakening the distinction drawn for DGM. We will revise the section to add operational predicates (e.g., requiring that the meta-level modifier itself be subject to modification within the loop), boundary cases (e.g., fixed outer-loop RL vs. self-referential modification), and exclusion rules that rule out systems whose outer mechanism remains human-specified and static. The revised criteria will be used to re-evaluate the mapped systems, including DGM, to ensure the claim of strongest evidence is supported under the tightened definitions. revision: yes
Circularity Check
No circularity; framework maps external published results to author-defined criteria
full rationale
The paper proposes four criteria as an operational definition and applies the mapping to systems whose benchmark deltas (SWE-bench, Polyglot) are taken directly from independent prior publications. No equations, fitted parameters, self-citations, or internal derivations are present; the central claim rests on external data rather than reducing to quantities defined inside this manuscript. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Speculations concerning the first ultraintelligent machine,
I. J. Good, “Speculations concerning the first ultraintelligent machine,” inAdvances in Computers, F. L. Alt and M. Rubinoff, Eds. New York, NY , USA: Academic Press, 1965, vol. 6, pp. 31–88
1965
-
[2]
G ¨odel machines: Self-referential universal problem solvers making provably optimal self-improvements,
J. Schmidhuber, “G ¨odel machines: Self-referential universal problem solvers making provably optimal self-improvements,” 2003
2003
-
[3]
Bounded recursive self-improvement,
E. Nivel, K. R. Th ´orisson, B. R. Steunebrink, H. Dindo, G. Pezzulo et al., “Bounded recursive self-improvement,” 2013
2013
-
[4]
From seed ai to technological singularity via recursively self-improving software,
R. V . Yampolskiy, “From seed ai to technological singularity via recursively self-improving software,” 2015
2015
-
[5]
¨Uber formal unentscheidbare s ¨atze der Principia Mathemat- ica und verwandter systeme i,
K. G ¨odel, “ ¨Uber formal unentscheidbare s ¨atze der Principia Mathemat- ica und verwandter systeme i,”Monatshefte f ¨ur Mathematik und Physik, vol. 38, no. 1, pp. 173–198, 1931
1931
-
[6]
Hutter, L
F. Hutter, L. Kotthoff, and J. Vanschoren, Eds.,Automated Machine Learning: Methods, Systems, Challenges. Cham, Switzerland: Springer, 2019
2019
-
[7]
Neural architecture search with reinforcement learning,
B. Zoph and Q. V . Le, “Neural architecture search with reinforcement learning,” inProc. International Conference on Learning Representa- tions, 2017
2017
-
[8]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inProc. International Conference on Machine Learning, 2017, pp. 1126–1135
2017
-
[9]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yanget al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[10]
Introducing sakana ai’s recursive self-improvement (RSI) lab,
Sakana AI, “Introducing sakana ai’s recursive self-improvement (RSI) lab,” https://sakana.ai/rsi-lab/, 2026, accessed: 2026-06-07
2026
-
[11]
Darwin g ¨odel machine: Open-ended evolution of self-improving agents,
J. Zhang, S. Hu, C. Lu, R. Lange, and J. Clune, “Darwin g ¨odel machine: Open-ended evolution of self-improving agents,” 2025
2025
-
[12]
Darwin g ¨odel machine code repository,
——, “Darwin g ¨odel machine code repository,” https://github.com/ jennyzzt/dgm, 2025, accessed: 2026-06-05
2025
-
[13]
SWE- bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Peiet al., “SWE- bench: Can language models resolve real-world GitHub issues?” inProc. International Conference on Learning Representations, 2024
2024
-
[14]
SWE-bench Verified,
OpenAI, “SWE-bench Verified,” https://openai.com/index/ introducing-swe-bench-verified/, 2024, accessed: 2026-06-05
2024
-
[15]
Polyglot benchmark,
P. Gauthier, “Polyglot benchmark,” https://aider.chat/docs/leaderboards/, 2024, accessed: 2026-06-05
2024
-
[16]
Claude 3.5 sonnet,
Anthropic, “Claude 3.5 sonnet,” https://www.anthropic.com/news/ claude-3-5-sonnet, 2024, accessed: 2026-06-05
2024
-
[17]
Openai o3-mini,
OpenAI, “Openai o3-mini,” https://openai.com/index/openai-o3-mini/, 2025, accessed: 2026-06-05
2025
-
[18]
Self-taught optimizer (STOP): Recursively self-improving code generation,
E. Zelikman, E. Lorch, L. Mackey, and A. T. Kalai, “Self-taught optimizer (STOP): Recursively self-improving code generation,” inProc. Conference on Language Modeling, 2024
2024
-
[19]
Automated design of agentic systems,
S. Hu, C. Lu, and J. Clune, “Automated design of agentic systems,” 2024, arXiv:2408.08435; code: https://github.com/ShengranHu/ADAS
Pith/arXiv arXiv 2024
-
[20]
G¨odel agent: A self-referential agent framework for recursively self-improvement,
X. Yin, X. Wang, L. Pan, L. Lin, X. Wan, and W. Y . Wang, “G¨odel agent: A self-referential agent framework for recursively self-improvement,” inProc. 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, 2025, pp. 27 890–27 913
2025
-
[21]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” inAdvances in Neural Information Processing Systems, 2024, arXiv:2405.15793; code: https://github.com/SWE-agent/ SWE-agent
Pith/arXiv arXiv 2024
-
[22]
Shinkaevolve: Towards open- ended and sample-efficient program evolution,
R. T. Lange, Y . Imajuku, and E. Cetin, “Shinkaevolve: Towards open- ended and sample-efficient program evolution,” 2025
2025
-
[23]
Shinkaevolve code repository,
Sakana AI, “Shinkaevolve code repository,” https://github.com/ SakanaAI/ShinkaEvolve, 2025, accessed: 2026-06-07
2025
-
[24]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pintoet al., “Evaluating large language models trained on code,” 2021
2021
-
[25]
Humaneval dataset,
OpenAI, “Humaneval dataset,” https://github.com/openai/human-eval/ blob/master/data/HumanEval.jsonl.gz, 2021, accessed: 2026-06-05
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.