AetheRock: An Arm-Worn Robot Teaching System for Force-Guided Vision-Tactile Learning
Pith reviewed 2026-06-27 16:23 UTC · model grok-4.3
The pith
An arm-worn device with a modular fingertip sensor and pressure reader collects consistent force-vision-tactile data, while ForceVT uses force and vision signals to train tactile representations that remain effective across sensor variation
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
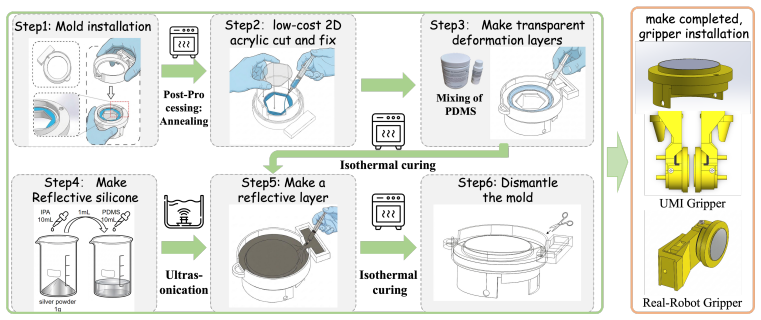
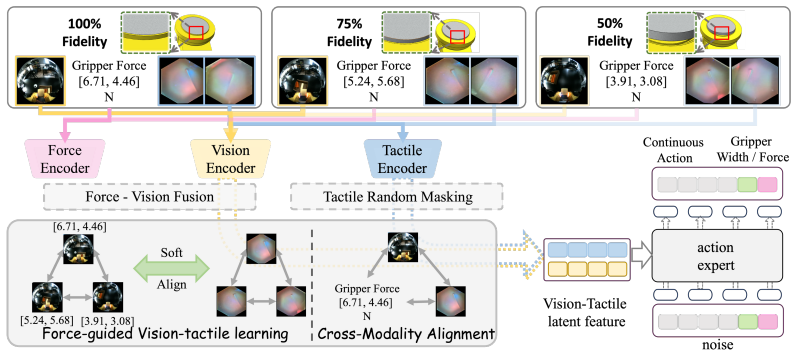
AetheRock is an arm-worn robot teaching system that integrates a modular GelSlim-MiniFab visuo-tactile sensor at the fingertip, a resistive pressure sensor at the human finger contact region, a customized PCB, and a wearable kit; paired with ForceVT, a representation learning framework that uses force and vision to guide fidelity-agnostic tactile learning, the combination yields qualified data efficiency in real-world experiments and mitigates performance losses caused by manufacturing and utilization inconsistencies in visuo-tactile sensors.
What carries the argument
AetheRock arm-worn collection hardware (modular fingertip visuo-tactile sensor plus resistive pressure sensor) together with the ForceVT force-and-vision-guided representation learner that produces tactile features usable across sensor instances.
If this is right
- Human demonstrations for contact-rich manipulation can be recorded with aligned force, vision, and tactile channels using a single wearable device.
- Tactile encoders trained under ForceVT remain effective even when the physical visuo-tactile sensor is replaced or varies in manufacturing quality.
- Data collection for robot learning no longer requires perfect sensor-to-sensor matching between training hardware and deployment hardware.
- Downstream policies for gripper-based tasks can be trained with higher sample efficiency because the collected demonstrations already contain consistent multimodal signals.
Where Pith is reading between the lines
- The same hardware-plus-guidance pattern could be adapted to other body-worn collection scenarios, such as full-hand or forearm sensing for bimanual tasks.
- ForceVT-style guidance might extend to additional modalities like audio or proprioception to further stabilize learning when any one sensor drifts.
- If the modular sensor design proves repeatable, open-source fabrication files could lower the barrier for other labs to replicate the data-collection setup.
Load-bearing premise
The assembled wearable kit and sensors can be worn by humans for extended collection sessions without degrading signal quality or causing discomfort that would alter natural demonstration behavior.
What would settle it
A side-by-side trial in which the same contact-rich task is learned from AetheRock-collected data versus data from a standard handheld gripper sensor, followed by a test where ForceVT-trained models are evaluated on tactile inputs from a second, physically different visuo-tactile sensor and performance is compared to an unguided baseline.
Figures











read the original abstract
Force and tactile sensing are indispensable in contact-rich manipulation. However, force-aware robot learning faces critical challenges due to the incompatible assembly of tactile and force sensors in handheld or wearable devices. To address these limitations, we first introduce AetheRock for gripper-force, vision, and tactile data collection, which is an arm-worn device featuring a modular and easily manufactured visuo-tactile sensor, GelSlim-MiniFab, at the fingertip, a resistive pressure sensor at the human finger contact region, a customized PCB module, and a wearable kit for comfortable and robust collection. Building on this, we propose ForceVT, a representation learning framework that uses force and vision to guide fidelity-agnostic tactile learning, enabling robust inference in any tactile situation. Real-world experiments show that AetheRock achieves qualified data efficiency and that ForceVT effectively alleviates inefficiencies when visuo-tactile sensors exhibit manufacturing and utilization inconsistencies. Overall, our work mitigates the limitations of gripper-force vision-tactile robot learning through innovative hardware design and algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AetheRock, an arm-worn device for collecting gripper-force, vision, and tactile data via a modular GelSlim-MiniFab visuo-tactile sensor at the fingertip, a resistive pressure sensor, customized PCB, and wearable kit. It proposes ForceVT, a representation learning framework using force and vision to guide fidelity-agnostic tactile learning for robustness to sensor inconsistencies. The authors claim real-world experiments demonstrate qualified data efficiency for AetheRock and that ForceVT mitigates inefficiencies arising from manufacturing and utilization inconsistencies in visuo-tactile sensors.
Significance. If the experimental claims hold with proper validation, the work could advance force-aware robot learning by offering a practical wearable hardware solution for data collection in contact-rich tasks and a learning method tolerant to sensor variability, addressing a recognized practical bottleneck in visuo-tactile manipulation.
major comments (2)
- [Abstract] Abstract: the central claims that 'real-world experiments show that AetheRock achieves qualified data efficiency' and 'ForceVT effectively alleviates inefficiencies' are asserted without any quantitative results, baselines, error bars, dataset sizes, statistical tests, or exclusion criteria, rendering the claims unevaluable from the provided text.
- [Hardware description] Hardware description (throughout): the validity of all experimental claims rests on the unvalidated premise that the GelSlim-MiniFab, resistive pressure sensor, PCB, and wearable kit can be repeatedly assembled and worn without degrading signals or comfort; no calibration data, inter-assembly consistency metrics, noise characterization, or human-factors validation are supplied, leaving open the possibility that assembly variations confound the ForceVT results with the manufacturing inconsistencies the method claims to address.
minor comments (1)
- [Abstract] The term 'qualified data efficiency' is imprecise and should be replaced with a concrete metric (e.g., samples per task success rate) in the abstract and results sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and hardware validation. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that 'real-world experiments show that AetheRock achieves qualified data efficiency' and 'ForceVT effectively alleviates inefficiencies' are asserted without any quantitative results, baselines, error bars, dataset sizes, statistical tests, or exclusion criteria, rendering the claims unevaluable from the provided text.
Authors: We agree that the abstract would benefit from explicit quantitative anchors. The full manuscript reports these details (dataset sizes, baselines, metrics with error bars, and statistical comparisons) in the experimental sections. We will revise the abstract to incorporate key quantitative highlights from those results while preserving its summary nature. revision: yes
-
Referee: [Hardware description] Hardware description (throughout): the validity of all experimental claims rests on the unvalidated premise that the GelSlim-MiniFab, resistive pressure sensor, PCB, and wearable kit can be repeatedly assembled and worn without degrading signals or comfort; no calibration data, inter-assembly consistency metrics, noise characterization, or human-factors validation are supplied, leaving open the possibility that assembly variations confound the ForceVT results with the manufacturing inconsistencies the method claims to address.
Authors: We acknowledge that explicit hardware validation data would strengthen the claims and reduce the risk of confounding. The current manuscript emphasizes the modular design to limit variations but does not include dedicated calibration or consistency metrics. We will add a hardware validation subsection reporting calibration procedures, inter-assembly repeatability, noise characterization, and participant comfort feedback collected during experiments. revision: yes
Circularity Check
No derivation chain or equations present; claims rest on hardware description and experiments
full rationale
The paper introduces hardware (AetheRock with GelSlim-MiniFab, resistive sensor, PCB, wearable kit) and a learning framework (ForceVT) but contains no equations, derivations, fitted parameters, or mathematical steps. The abstract and description focus on system assembly and experimental results for data efficiency. No self-citations, ansatzes, or predictions that reduce to inputs by construction are identifiable. The central claims are validated externally via real-world experiments rather than internal reduction, making the work self-contained against the circularity criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[2]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[3]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.pi 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[4]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[5]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffu- sion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009, 2025
2025
-
[6]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[7]
R. Punamiya, S. Kareer, Z. Liu, J. Citron, R.-Z. Qiu, X. Cai, A. Gavryushin, J. Chen, D. Li- conti, L. Y . Zhu, et al. Egoverse: An egocentric human dataset for robot learning from around the world.arXiv preprint arXiv:2604.07607, 2026
Pith/arXiv arXiv 2026
-
[8]
A. S. Chen, S. Nair, and C. Finn. Learning generalizable robotic reward functions from” in- the-wild” human videos.arXiv preprint arXiv:2103.16817, 2021
arXiv 2021
-
[9]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[10]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
Pith/arXiv arXiv 2024
-
[11]
H. Choi, Y . Hou, C. Pan, S. Hong, A. Patel, X. Xu, M. R. Cutkosky, and S. Song. In-the-wild compliant manipulation with umi-ft.arXiv preprint arXiv:2601.09988, 2026
arXiv 2026
-
[12]
Y . Xu, L. Wei, P. An, Q. Zhang, and Y .-L. Li. exumi: Extensible robot teaching system with action-aware task-agnostic tactile representation.arXiv preprint arXiv:2509.14688, 2025
arXiv 2025
-
[13]
X. Zhu, B. Huang, and Y . Li. Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper.Advances in Neural Information Processing Systems, 38: 153783–153812, 2026
2026
- [14]
-
[15]
S. Luo, Y . Li, Y . Hu, C. Yu, C. Xu, J. Zhang, G. Yao, T. Huang, R. He, and Z. Wang. Omniumi: Towards physically grounded robot learning via human-aligned multimodal interaction.arXiv preprint arXiv:2604.10647, 2026
Pith/arXiv arXiv 2026
-
[16]
L. Wu, C. Yu, J. Ren, L. Chen, Y . Jiang, R. Huang, G. Gu, and H. Li. Freetacman: Robot-free visuo-tactile data collection system for contact-rich manipulation.arXiv preprint arXiv:2506.01941, 2025. 10
arXiv 2025
- [17]
-
[18]
Zhaxizhuoma, K
Z. Zhaxizhuoma, K. Liu, C. Guan, Z. Jia, Z. Wu, X. Liu, T. Wang, S. Liang, P. Chen, P. Zhang, et al. Fastumi: A scalable and hardware-independent universal manipulation interface with dataset. InConference on Robot Learning, pages 3069–3093. PMLR, 2025
2025
-
[19]
J. Fang, W. Chen, H. Xue, F. Zhou, T. Le, Y . Wang, Y . Zhang, J. Lv, C. Wen, and C. Lu. Robopocket: Improve robot policies instantly with your phone.arXiv preprint arXiv:2603.05504, 2026
arXiv 2026
-
[20]
Z. Zhang, J. Ma, X. Yang, X. Wen, Y . Zhang, B. Li, Y . Qin, J. Liu, C. Zhao, L. Kang, et al. Touchguide: Inference-time steering of visuomotor policies via touch guidance.arXiv preprint arXiv:2601.20239, 2026
Pith/arXiv arXiv 2026
-
[21]
W. Liu, J. Wang, Y . Wang, W. Wang, and C. Lu. Forcemimic: Force-centric imitation learning with force-motion capture system for contact-rich manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 1105–1112. IEEE, 2025
2025
-
[22]
C. Lin, H. Zhang, J. Xu, L. Wu, and H. Xu. 9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation.IEEE Robotics and Automation Letters, 9(2):923–930, 2023
2023
-
[23]
Lambeta, P.-W
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, et al. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020
2020
-
[24]
W. Yuan, S. Dong, and E. H. Adelson. Gelsight: High-resolution robot tactile sensors for estimating geometry and force.Sensors, 17(12):2762, 2017
2017
-
[25]
Glauser, D
O. Glauser, D. Panozzo, O. Hilliges, and O. Sorkine-Hornung. Deformation capture via soft and stretchable sensor arrays.ACM Transactions on Graphics (TOG), 38(2):1–16, 2019
2019
-
[26]
T.-Y . Wu, L. Tan, Y . Zhang, T. Seyed, and X.-D. Yang. Capacitivo: Contact-based object recognition on interactive fabrics using capacitive sensing. InProceedings of the 33rd annual acm symposium on user interface software and technology, pages 649–661, 2020
2020
-
[27]
B. Xu, L. Zhong, G. Zhang, X. Liang, D. Virtue, R. Madan, and T. Bhattacharjee. Cushsense: Soft, stretchable, and comfortable tactile-sensing skin for physical human-robot interaction. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5694–5701. IEEE, 2024
2024
-
[28]
Sundaram, P
S. Sundaram, P. Kellnhofer, Y . Li, J.-Y . Zhu, A. Torralba, and W. Matusik. Learning the signatures of the human grasp using a scalable tactile glove.Nature, 569(7758):698–702, 2019
2019
-
[29]
Stassi, V
S. Stassi, V . Cauda, G. Canavese, and C. F. Pirri. Flexible tactile sensing based on piezoresistive composites: A review.Sensors, 14(3):5296–5332, 2014
2014
-
[30]
Zhang, P
C. Zhang, P. Hao, X. Cao, X. Hao, S. Cui, and S. Wang. Vtla: Vision-tactile-language- action model with preference learning for insertion manipulation.Biomimetic Intelligence and Robotics, page 100333, 2026
2026
- [31]
- [32]
-
[33]
X. Li, M. Cai, J. Xu, J. Zhu, H. Fan, Y . Shen, G. Ren, and H. Dong. At-vla: Adaptive tactile injection for enhanced feedback reaction in vision-language-action models.arXiv preprint arXiv:2605.07308, 2026
Pith/arXiv arXiv 2026
- [34]
-
[35]
K. Gubernatorov, M. Sannikov, I. Mikhalchuk, E. Kuznetsov, M. Artemov, O. F. Ouwatobi, M. Fernando, A. Asanov, Z. Guo, and D. Tsetserukou. Hapticvla: Contact-rich manipula- tion via vision-language-action model without inference-time tactile sensing.arXiv preprint arXiv:2603.15257, 2026
arXiv 2026
-
[36]
C. Morissette, A. Abyaneh, W.-D. Chang, A. Houssaini, D. Meger, H.-C. Lin, J. Tremblay, and G. Dudek. Tactile modality fusion for vision-language-action models.arXiv preprint arXiv:2603.14604, 2026
arXiv 2026
-
[37]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[38]
S. Liu, B. Li, K. Ma, L. Wu, H. Tan, X. Ouyang, H. Su, and J. Zhu. Rdt2: Exploring the scaling limit of umi data towards zero-shot cross-embodiment generalization.arXiv preprint arXiv:2602.03310, 2026
arXiv 2026
-
[39]
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu. Dexcap: Scalable and portable mocap data collection system for dexterous manipulation.arXiv preprint arXiv:2403.07788, 2024
arXiv 2024
-
[40]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[41]
J. Bi, K. Y . Ma, C. Hao, M. S. Zheng, and H. Soh. Vla-touch: Enhancing vision-language- action model with dual-level tactile feedback.IEEE Robotics and Automation Letters, 2026
2026
-
[42]
P. Hao, C. Zhang, D. Li, X. Cao, X. Hao, S. Cui, and S. Wang. Tla: Tactile-language-action model for contact-rich manipulation.arXiv preprint arXiv:2503.08548, 2025
arXiv 2025
-
[43]
J. Li, T. Wu, J. Zhang, Z. Chen, H. Jin, M. Wu, Y . Shen, Y . Yang, and H. Dong. Adaptive visuo- tactile fusion with predictive force attention for dexterous manipulation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3232–3239. IEEE, 2025
2025
-
[44]
S. Yu, K. Lin, A. Xiao, J. Duan, and H. Soh. Octopi: Object property reasoning with large tactile-language models.arXiv preprint arXiv:2405.02794, 2024
arXiv 2024
- [45]
-
[46]
J. Zhao, Y . Ma, L. Wang, and E. H. Adelson. Transferable tactile transformers for representa- tion learning across diverse sensors and tasks.arXiv preprint arXiv:2406.13640, 2024. 12
arXiv 2024
-
[47]
H. Choi, J. E. Low, T. M. Huh, S. Hong, G. A. Uribe, K. A. Hoffmann, J. Di, T. G. Chen, A. A. Stanley, and M. R. Cutkosky. Coinft: A coin-sized, capacitive 6-axis force torque sensor for robotic applications.arXiv preprint arXiv:2503.19225, 2025
arXiv 2025
-
[48]
S. Q. Liu and E. H. Adelson. Gelsight fin ray: Incorporating tactile sensing into a soft compli- ant robotic gripper. In2022 IEEE 5th International Conference on Soft Robotics (RoboSoft), pages 925–931. IEEE, 2022
2022
-
[49]
Zhao and E
J. Zhao and E. H. Adelson. Gelsight svelte: A human finger-shaped single-camera tactile robot finger with large sensing coverage and proprioceptive sensing. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8979–8984. IEEE, 2023
2023
-
[50]
S. Wang, Y . She, B. Romero, and E. Adelson. Gelsight wedge: Measuring high-resolution 3d contact geometry with a compact robot finger. In2021 IEEE international conference on robotics and automation (ICRA), pages 6468–6475. IEEE, 2021
2021
-
[51]
W. K. Do and M. Kennedy. Densetact: Optical tactile sensor for dense shape reconstruction. In 2022 International Conference on Robotics and Automation (ICRA), pages 6188–6194. IEEE, 2022
2022
-
[52]
M. H. Tippur and E. H. Adelson. Gelsight360: An omnidirectional camera-based tactile sensor for dexterous robotic manipulation. In2023 IEEE International Conference on Soft Robotics (RoboSoft), pages 1–8. IEEE, 2023. 13 A Task Definitions and Generalization Settings In this section, we first propose the generalization settings and then describe the task p...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.