POTATR: A Lightweight Image-to-Graph Model for Page-Level Table Extraction
Pith reviewed 2026-06-27 17:05 UTC · model grok-4.3
The pith
A 29M-parameter image-to-graph model extracts tables from document pages with higher accuracy than frontier systems while running over 130 times faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
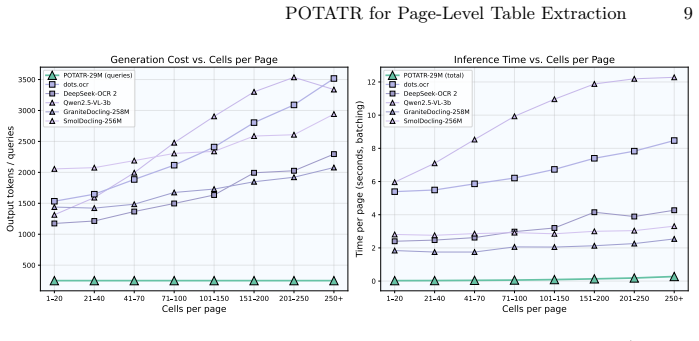
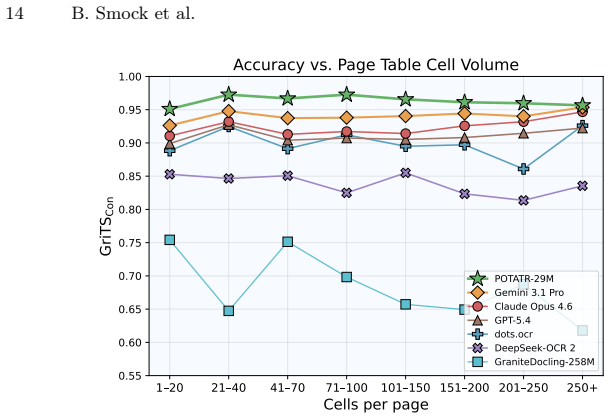
POTATR is a 29 million parameter image-to-graph model that extends the Table Transformer for contextualized page-level table extraction, achieving a GriTS_Con of 0.964 on the PubTables-v2 Single Pages benchmark while running over 130 times faster and at roughly 300 times lower cost than the compared models.
What carries the argument
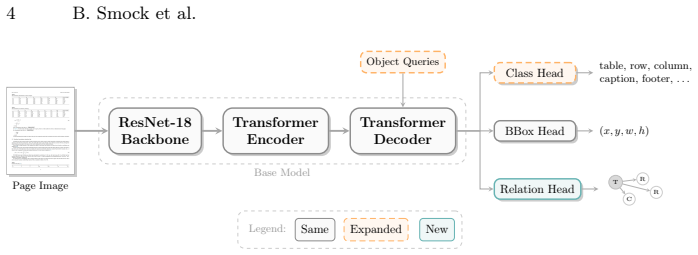
The image-to-graph architecture that maps a page image to a graph of table elements, each with an associated bounding box, extending TATR to incorporate page-level context.
If this is right
- Enables unified page-level table extraction with direct visual verification through bounding boxes.
- Supports composition with external OCR systems to handle scanned documents.
- Extends to full-document extraction by applying cross-page merging techniques to its outputs.
Where Pith is reading between the lines
- The speed and cost profile could allow table extraction to run on-device rather than through cloud APIs.
- Spatially grounded graph outputs may simplify downstream tasks such as layout analysis or information retrieval.
- The same lightweight image-to-graph pattern might apply to other structured elements like forms or diagrams.
Load-bearing premise
The PubTables-v2 Single Pages benchmark together with the chosen comparison models provide a fair and representative test of contextual page-level table extraction under consistent conditions.
What would settle it
A controlled re-evaluation on the same benchmark where POTATR fails to exceed the accuracy of the tested frontier models or loses its reported speed and cost advantage.
Figures

read the original abstract
Large-scale document processing requires contextually aware table extraction (TE) that is both accurate and efficient. Yet current approaches require billions of parameters, hundreds of autoregressive steps, or costly API inference. Motivated by this, we introduce the Page-Object Table Transformer (POTATR), a lightweight 29M parameter image-to-graph model that extends the Table Transformer (TATR) for contextualized page-level TE. POTATR outperforms all models tested on the PubTables-v2 Single Pages benchmark -- including frontier MLLMs -- achieving $\textrm{GriTS}_\textrm{Con}$ of 0.964 while running over 130$\times$ faster at roughly 300$\times$ lower cost. Further, POTATR's output is spatially grounded: every recognized element has a bounding box, enabling visual verification and geometric text assignment. As a result, POTATR performs unified page-level TE while composing with other models, enabling extension to scanned documents via external OCR and to full-document TE via techniques like cross-page merging. Code and models will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces POTATR, a 29M-parameter image-to-graph model extending the Table Transformer (TATR) for contextual page-level table extraction from document images. It claims state-of-the-art performance on the PubTables-v2 Single Pages benchmark, achieving GriTS_Con of 0.964 while outperforming all tested models including frontier MLLMs, with reported speedups of over 130× and cost reductions of roughly 300×. The model outputs spatially grounded elements with bounding boxes, supports composition with external OCR or cross-page merging, and is positioned as a lightweight alternative for large-scale document processing.
Significance. If the benchmark comparisons hold under identical conditions, the result would be significant for efficient document AI: it demonstrates that a compact, non-autoregressive image-to-graph architecture can match or exceed much larger MLLMs on contextual table extraction while enabling visual verification and modular extension to scanned or multi-page documents. The release of code and models would further support reproducibility.
major comments (2)
- [Experiments] Experiments section (benchmark comparison): The central claim of outperforming frontier MLLMs on GriTS_Con (0.964) and the associated 130× speed / 300× cost advantages rests on the PubTables-v2 Single Pages evaluation being performed under fully consistent conditions. The manuscript must explicitly document the MLLM evaluation protocol, including input representation (raw page images), prompting strategy, output parsing into the required graph format, exact test-set splits, and the GriTS_Con implementation used, to substantiate direct numerical comparisons.
- [Methods / Experiments] Methods and Experiments: Training details (data splits, augmentation, loss weighting for the graph prediction head, and hyperparameter choices) are referenced only at a high level. Because the performance numbers are the primary evidence for the efficiency-accuracy tradeoff, these details are load-bearing and must be provided to allow verification that the reported gains are not artifacts of differential training or post-processing.
minor comments (2)
- [Abstract] Abstract and introduction: The phrase 'outperforms all models tested' should be qualified to 'all models evaluated in this study' to avoid implying exhaustive coverage of the literature.
- [Introduction] Notation: The distinction between GriTS_Con and other GriTS variants should be defined on first use with a brief equation or reference to the original metric definition.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will revise the manuscript to provide the requested documentation and details.
read point-by-point responses
-
Referee: [Experiments] Experiments section (benchmark comparison): The central claim of outperforming frontier MLLMs on GriTS_Con (0.964) and the associated 130× speed / 300× cost advantages rests on the PubTables-v2 Single Pages evaluation being performed under fully consistent conditions. The manuscript must explicitly document the MLLM evaluation protocol, including input representation (raw page images), prompting strategy, output parsing into the required graph format, exact test-set splits, and the GriTS_Con implementation used, to substantiate direct numerical comparisons.
Authors: We agree that explicit documentation of the MLLM evaluation protocol is required to substantiate the comparisons. In the revised manuscript we will add a dedicated subsection in Experiments that specifies input representation (raw page images), prompting strategy, output parsing into graph format, exact test-set splits, and the GriTS_Con implementation used for every model, including the frontier MLLMs. revision: yes
-
Referee: [Methods / Experiments] Methods and Experiments: Training details (data splits, augmentation, loss weighting for the graph prediction head, and hyperparameter choices) are referenced only at a high level. Because the performance numbers are the primary evidence for the efficiency-accuracy tradeoff, these details are load-bearing and must be provided to allow verification that the reported gains are not artifacts of differential training or post-processing.
Authors: We acknowledge that training details are currently high-level. In the revised manuscript we will expand the Methods and Experiments sections with full specifications of data splits, augmentation, loss weighting for the graph prediction head, and hyperparameter choices so that the reported performance can be verified and shown not to result from differential training or post-processing. revision: yes
Circularity Check
No circularity; performance claims rest on external benchmark measurements
full rationale
The paper introduces POTATR as an extension of prior TATR work and reports direct empirical results (GriTS_Con, speed, cost) on the external PubTables-v2 Single Pages benchmark against other models. No equations, fitted parameters, or self-citations are presented as load-bearing derivations that reduce the central claims to tautologies or self-definitions. All key metrics are stated as measured quantities under the benchmark protocol, with no renaming of known results or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[2]
In: International Conference on Document Analysis and Recognition
Baek, Y., Nam, D., Surh, J., Shin, S., Kim, S.: TRACE: table reconstruction aligned to corner and edges. In: International Conference on Document Analysis and Recognition. pp. 472–489. Springer (2023)
2023
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2.5-VL technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: ECCV
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: ECCV. pp. 213–229 (2020)
2020
-
[5]
In: International Conference on Document Analysis and Recognition
Choi, Y.Y., Kim, T., Kim, N., Lee, T., Joe, S.: End to end table transformer. In: International Conference on Document Analysis and Recognition. pp. 331–345. Springer (2024)
2024
-
[6]
PaddleOCR 3.0 Technical Report
Cui, C., Sun, T., Lin, M., Gao, T., Zhang, Y., Liu, J., Wang, X., Zhang, Z., Zhou, C., Liu, H., et al.: PaddleOCR 3.0 technical report. arXiv preprint arXiv:2507.05595 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
IBM-Granite: Granite Docling.https://huggingface.co/ibm-granite/granite- docling-258M(2025)
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Im, J., Nam, J., Park, N., Lee, H., Park, S.: EGTR: Extracting graph from trans- former for scene graph generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24229–24238 (2024)
2024
-
[9]
JaidedAI: EasyOCR (09 2024),https://github.com/JaidedAI/EasyOCR
2024
-
[10]
dots.ocr: Multilingual document layout parsing in a single vision-language model, 2025
Li, Y., Yang, G., Liu, H., Wang, B., Zhang, C.: dots.ocr: Multilingual document layout parsing in a single vision-language model. arXiv preprint arXiv:2512.02498 (2025)
-
[11]
Luccioni,A.S.,Jernite,Y.,Strubell,E.:Powerhungryprocessing:Wattsdrivingthe cost of ai deployment? In: Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT). pp. 85–99. ACM (2024)
2024
-
[12]
Smock et al
Mindee: docTR: Document text recognition.https://github.com/mindee/doctr (2021) 12 B. Smock et al
2021
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Nassar, A., Livathinos, N., Lysak, M., Staar, P.: Tableformer: Table structure un- derstanding with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4614–4623 (2022)
2022
-
[14]
arXiv preprint arXiv:2503.11576 (2025)
Nassar, A., Marafioti, A., Omenetti, M., Lysak, M., Livathinos, N., Auer, C., Morin, L., de Lima, R.T., Kim, Y., Gurbuz, A.S., et al.: SmolDocling: An ultra- compact vision-language model for end-to-end multi-modal document conversion. arXiv preprint arXiv:2503.11576 (2025)
-
[15]
In: 2019 international conference on document analysis and recognition (ICDAR)
Paliwal, S.S., Vishwanath, D., Rahul, R., Sharma, M., Vig, L.: Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images. In: 2019 international conference on document analysis and recognition (ICDAR). pp. 128–133. IEEE (2019)
2019
-
[16]
Poznanski, J., Rangapur, A., Borchardt, J., Dunkelberger, J., Huff, R., Lin, D., Wilhelm, C., Lo, K., Soldaini, L.: olmocr: Unlocking trillions of tokens in pdfs with vision language models. arXiv preprint arXiv:2502.18443 (2025)
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops
Prasad, D., Gadpal, A., Kapadni, K., Visave, M., Sultanpure, K.: CascadeTabNet: An approach for end to end table detection and structure recognition from image- based documents. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. pp. 572–573 (2020)
2020
-
[18]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Rausch, J., Martinez, O., Bissig, F., Zhang, C., Feuerriegel, S.: Docparser: Hierar- chical document structure parsing from renderings. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 4328–4338 (2021)
2021
-
[19]
In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR)
Schreiber, S., Agne, S., Wolf, I., Dengel, A., Ahmed, S.: DeepDeSTR: Deep learning for detection and structure recognition of tables in document images. In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR). vol. 1, pp. 1162–1167. IEEE (2017)
2017
-
[20]
In: European Conference on Computer Vision
Shit, S., Koner, R., Wittmann, B., Paetzold, J., Ezhov, I., Li, H., Pan, J., Shar- ifzadeh, S., Kaissis, G., Tresp, V., et al.: Relationformer: A unified framework for image-to-graph generation. In: European Conference on Computer Vision. pp. 422–439. Springer (2022)
2022
-
[21]
PubTables-v2: A new large-scale dataset for full-page and multi-page table extraction
Smock, B., Faucon-Morin, V., Sokolov, M., Liang, L., Khanam, T., Ramesh, A., Courtland, M.: PubTables-v2: A new large-scale dataset for full-page and multi- page table extraction. arXiv preprint arXiv:2512.10888 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Smock, B., Pesala, R., Abraham, R.: PubTables-1M: Towards comprehensive ta- ble extraction from unstructured documents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4634–4642 (June 2022)
2022
-
[23]
In: International Conference on Document Analysis and Recog- nition
Smock, B., Pesala, R., Abraham, R.: Aligning benchmark datasets for table struc- ture recognition. In: International Conference on Document Analysis and Recog- nition. pp. 371–386. Springer (2023)
2023
-
[24]
In: International Conference on Document Analysis and Recognition
Smock, B., Pesala, R., Abraham, R.: GriTS: Grid table similarity metric for ta- ble structure recognition. In: International Conference on Document Analysis and Recognition. pp. 535–549. Springer (2023)
2023
-
[25]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
arXiv preprint arXiv:2502.09927 (2025)
Team, G.V., Karlinsky, L., Arbelle, A., Daniels, A., Nassar, A., Alfassi, A., Wu, B., Schwartz, E., Joshi, D., Kondic, J., et al.: Granite vision: a lightweight, open-source multimodal model for enterprise intelligence. arXiv preprint arXiv:2502.09927 (2025)
-
[27]
DeepSeek-OCR: Contexts Optical Compression
Wei, H., Sun, Y., Li, Y.: Deepseek-ocr: Contexts optical compression. arXiv preprint arXiv:2510.18234 (2025) POTATR for Page-Level Table Extraction 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Deepseek-ocr 2: Visual causal flow.arXiv preprint arXiv:2601.20552, 2026
Wei, H., Sun, Y., Li, Y.: Deepseek-ocr 2: Visual causal flow. arXiv preprint arXiv:2601.20552 (2026)
-
[29]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Zheng, X., Burdick, D., Popa, L., Zhong, X., Wang, N.X.R.: Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 697–706 (2021)
2021
-
[30]
In: European conference on computer vision
Zhong, X., ShafieiBavani, E., Jimeno Yepes, A.: Image-based table recognition: data, model, and evaluation. In: European conference on computer vision. pp. 564–580. Springer (2020)
2020
-
[31]
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable DETR: Deformable transformers for end-to-end object detection. In: ICLR (2021) 14 B. Smock et al. 1 20 21 40 41 70 71 100 101 150 151 200 201 250 250+ Cells per page 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 1.00GriTSCon Accuracy vs. Page T able Cell Volume POTATR-29M Gemini 3.1 Pro Claude ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.