Calibrating Overconfidence Without Sacrificing Confidence: Probe-Conditioned Head Intervention for LLMs
Pith reviewed 2026-06-28 10:22 UTC · model grok-4.3
The pith
A frozen probe detects overconfident errors in LLMs and triggers conditional rescaling of attention heads to convert most wrong high-confidence answers to low while preserving nearly all correct ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Probe-Conditioned Head Intervention uses a frozen probe to identify likely wrong-but-confident responses and then conditionally rescales selected attention-head outputs during confidence generation, converting 82.2 percent of wrong-yes readouts to no on Qwen3-4B-Instruct while reducing ECE from 21.9 percent to 9.2 percent and damaging only 5.1 percent of correct-yes readouts.
What carries the argument
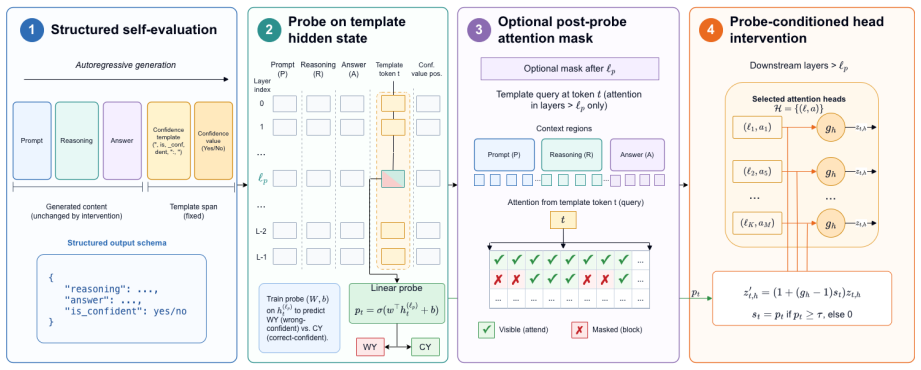
Probe-Conditioned Head Intervention (PCHI): a frozen probe detects likely wrong-but-confident cases and conditionally rescales downstream attention-head outputs only on those cases during confidence readout.
If this is right
- Readout-token intervention alone can flip most wrong high-confidence verbalizations without upstream changes.
- Joint intervention across multiple confidence-template tokens yields larger ECE drops than readout-token intervention alone.
- The method works on at least two 4B-scale models but shows model-dependent strength in upstream interventions.
- Selective internal rescaling can reduce overconfidence while limiting collateral damage to correct answers below 6 percent.
Where Pith is reading between the lines
- The approach may extend to multi-token confidence expressions if the probe can be trained on longer sequences.
- If the probe generalizes across tasks, the same heads could be reused for calibration on non-math domains without retraining.
- Combining PCHI with existing logit-level calibration methods could further tighten the remaining calibration gap.
- The method's reliance on a structured binary field suggests it may not directly transfer to free-form verbalized confidence without redesigning the probe targets.
Load-bearing premise
The frozen probe can reliably identify likely wrong-but-confident responses from the model's internal activations or outputs in a way that permits conditional head intervention without introducing false positives that would damage correct answers.
What would settle it
Run the same probe and intervention protocol on a new model and dataset where the probe's false-positive rate on correct answers exceeds 10 percent and measure whether the ECE reduction disappears or reverses.
Figures


read the original abstract
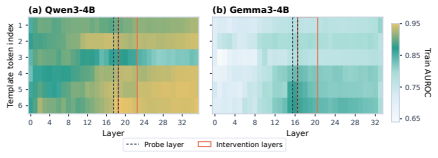
Large language models often express high confidence in answers that are wrong. Standard calibration remedies typically act globally or at the score level, reducing unwarranted confidence but also risking erosion of warranted confidence on correct answers. We introduce Probe-Conditioned Head Intervention (PCHI), an inference-time method that uses a frozen probe to detect likely wrong-but-confident responses and conditionally rescales downstream attention-head outputs during confidence generation. On Qwen3-4B-Instruct solving OpenMathInstruct problems with a structured binary confidence field, readout-token PCHI converts 82.2% of originally wrong-yes confidence readouts to $\texttt{no}$, while a joint intervention across upstream confidence-template tokens reduces ECE from 21.9% to 9.2% and damages only 5.1% of originally correct-yes readouts. The readout-token effect also appears on Gemma3-4B, though upstream interventions are weaker and more mask-dependent. These results show that verbalized overconfidence can be selectively reduced through conditionally applied internal intervention, partially decoupling the suppression of unwarranted confidence from the loss of warranted confidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Probe-Conditioned Head Intervention (PCHI), an inference-time method that trains a frozen probe on model activations to detect likely wrong-but-confident responses and then conditionally rescales attention-head outputs only for those cases during generation of a structured binary confidence field (yes/no). On Qwen3-4B-Instruct solving OpenMathInstruct problems, readout-token PCHI converts 82.2% of originally wrong-yes readouts to no; a joint upstream intervention on confidence-template tokens reduces ECE from 21.9% to 9.2% while damaging only 5.1% of originally correct-yes readouts. Weaker but directionally similar effects are reported for Gemma3-4B.
Significance. If the probe selectivity holds, PCHI would demonstrate a practical route to selective reduction of verbalized overconfidence that largely preserves warranted confidence, addressing a key limitation of global calibration methods. The concrete held-out percentages and ECE numbers on two 4B-scale models provide a falsifiable empirical anchor for the decoupling claim.
major comments (2)
- [Probe description and experimental setup sections] The headline selectivity result (5.1% damage to correct-yes readouts) is load-bearing for the central decoupling claim, yet the manuscript supplies no probe training protocol, no accuracy/precision/recall figures on the correct class, no cross-validation details, and no ablation that removes the probe while retaining the same head rescaling. Without these, the reported damage fraction cannot be attributed to the intervention rather than an unusually favorable probe. (Probe description and experimental setup sections.)
- [Results and intervention details sections] The joint upstream intervention is reported to reduce ECE from 21.9% to 9.2%, but the text does not specify how the intervention mask or scaling factors are chosen when multiple upstream tokens are involved, nor whether these choices were tuned on the same evaluation split used for the final ECE numbers. (Results and intervention details sections.)
minor comments (2)
- [Abstract] The abstract uses \texttt{no} without defining the exact token string or template format; this should be clarified in the methods for reproducibility.
- No mention of whether code, probe weights, or intervention hyperparameters will be released; adding this would strengthen the empirical contribution.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need for greater transparency around the probe and intervention details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Probe description and experimental setup sections] The headline selectivity result (5.1% damage to correct-yes readouts) is load-bearing for the central decoupling claim, yet the manuscript supplies no probe training protocol, no accuracy/precision/recall figures on the correct class, no cross-validation details, and no ablation that removes the probe while retaining the same head rescaling. Without these, the reported damage fraction cannot be attributed to the intervention rather than an unusually favorable probe. (Probe description and experimental setup sections.)
Authors: We agree that these details are necessary to substantiate the selectivity claim. In the revised manuscript we will add a dedicated subsection detailing the probe training protocol (including dataset construction, train/validation/test splits, loss, optimizer, and hyperparameters), report accuracy/precision/recall on the correct class, and include cross-validation results. We will also add an ablation that applies the identical head-rescaling procedure without the probe (i.e., unconditional or random intervention) to isolate the contribution of the probe's conditional signal. revision: yes
-
Referee: [Results and intervention details sections] The joint upstream intervention is reported to reduce ECE from 21.9% to 9.2%, but the text does not specify how the intervention mask or scaling factors are chosen when multiple upstream tokens are involved, nor whether these choices were tuned on the same evaluation split used for the final ECE numbers. (Results and intervention details sections.)
Authors: We will expand the intervention-details subsection to describe the exact rule used to construct the mask and select scaling factors across multiple upstream tokens. We will also state that all mask and scaling decisions were made on a held-out validation split that is disjoint from the test set on which the final ECE numbers are reported. revision: yes
Circularity Check
No circularity: empirical measurements on held-out outputs with no reduction to fitted parameters or self-citations
full rationale
The paper introduces PCHI as an inference-time method using a frozen probe for conditional head intervention and reports direct empirical results (82.2% conversion, ECE drop from 21.9% to 9.2%, 5.1% damage) on Qwen3-4B and Gemma3-4B with OpenMathInstruct. These are presented as measured outcomes on model outputs rather than quantities derived by the paper's equations from the same data or justified solely via self-citation. No load-bearing derivation step reduces by construction to inputs; the central claims rest on external benchmarks and held-out evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs , author=. 2024 , eprint=
2024
-
[2]
2017 , eprint=
On Calibration of Modern Neural Networks , author=. 2017 , eprint=
2017
-
[3]
2022 , eprint=
Sample-dependent Adaptive Temperature Scaling for Improved Calibration , author=. 2022 , eprint=
2022
-
[4]
2025 , eprint=
Causal Head Gating: A Framework for Interpreting Roles of Attention Heads in Transformers , author=. 2025 , eprint=
2025
-
[5]
2024 , journal =
OpenMathInstruct-2: Accelerating AI for Math with Massive Open-Source Instruction Data , author =. 2024 , journal =
2024
-
[6]
A survey of confidence estimation and calibration in large language models
Geng, Jiahui and Cai, Fengyu and Wang, Yuxia and Koeppl, Heinz and Nakov, Preslav and Gurevych, Iryna. A Survey of Confidence Estimation and Calibration in Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:...
-
[7]
2025 , eprint=
Taming Overconfidence in LLMs: Reward Calibration in RLHF , author=. 2025 , eprint=
2025
-
[8]
2024 , eprint=
Calibrating Language Models with Adaptive Temperature Scaling , author=. 2024 , eprint=
2024
-
[9]
2025 , eprint=
Programming Refusal with Conditional Activation Steering , author=. 2025 , eprint=
2025
-
[10]
Maraia, Gabriele and Ranaldi, Leonardo and Valentino, Marco and Zanzotto, Fabio Massimo. Can Activation Steering Generalize Across Languages? A Study on Syllogistic Reasoning in Language Models. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/202...
-
[11]
2026 , eprint=
Closing the Confidence-Faithfulness Gap in Large Language Models , author=. 2026 , eprint=
2026
-
[12]
2024 , eprint=
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
2024
-
[13]
2024 , eprint=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. 2024 , eprint=
2024
-
[14]
2025 , eprint=
Representation Engineering: A Top-Down Approach to AI Transparency , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
Taxonomy, Opportunities, and Challenges of Representation Engineering for Large Language Models , author=. 2025 , eprint=
2025
-
[16]
2026 , eprint=
How do LLMs Compute Verbal Confidence , author=. 2026 , eprint=
2026
-
[17]
2026 , eprint=
Wired for Overconfidence: A Mechanistic Perspective on Inflated Verbalized Confidence in LLMs , author=. 2026 , eprint=
2026
-
[18]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[19]
Gemma 3 , url=
Gemma , year=. Gemma 3 , url=
-
[20]
2022 , eprint=
Teaching Models to Express Their Uncertainty in Words , author=. 2022 , eprint=
2022
-
[21]
2022 , eprint=
Language Models (Mostly) Know What They Know , author=. 2022 , eprint=
2022
-
[22]
Calibrating LLM Confidence by Probing Perturbed Representation Stability
Khanmohammadi, Reza and Miahi, Erfan and Mardikoraem, Mehrsa and Kaur, Simerjot and Brugere, Ivan and Smiley, Charese and Thind, Kundan S and Ghassemi, Mohammad M. Calibrating LLM Confidence by Probing Perturbed Representation Stability. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnl...
-
[23]
2023 , eprint=
The Internal State of an LLM Knows When It's Lying , author=. 2023 , eprint=
2023
-
[24]
2024 , url =
Monte MacDiarmid and Timothy Maxwell and Nicholas Schiefer and Jesse Mu and Jared Kaplan and David Duvenaud and Sam Bowman and Alex Tamkin and Ethan Perez and Mrinank Sharma and Carson Denison and Evan Hubinger , title =. 2024 , url =
2024
-
[25]
Proceedings of EMNLP , year =
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author =. Proceedings of EMNLP , year =
-
[26]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , booktitle =. Can. 2024 , url =
2024
-
[27]
Interpreting
nostalgebraist , year =. Interpreting
-
[28]
Transformer Circuits Thread , year =
A Mathematical Framework for Transformer Circuits , author =. Transformer Circuits Thread , year =
-
[29]
Interpretability in the Wild: A Circuit for Indirect Object Identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle =. Interpretability in the Wild: A Circuit for Indirect Object Identification in. 2023 , url =
2023
-
[30]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Mathematical Problem Solving With the. 2021 , url =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.