Unsupervised Style Representation Learning for AI-Text Detection via Paraphrase Inversion
Pith reviewed 2026-06-27 16:53 UTC · model grok-4.3
The pith
Training a style encoder to reconstruct human text from its machine paraphrase, with a frozen semantic encoder, produces unsupervised style features that support effective AI-text detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Style representations learned by inverting machine-generated paraphrases to recover human text, without authorship supervision, yield detectors that match supervised baselines in few-shot regimes and generalize better to unseen LLMs in zero-shot settings, while also transferring to authorship verification and style discrimination.
What carries the argument
A style encoder trained to reconstruct human-authored text from its machine-generated paraphrase while a semantic encoder is held frozen, thereby isolating non-semantic style features for reconstruction.
If this is right
- AI-text detection becomes possible without collecting authorship-labeled training data.
- Zero-shot detectors built on these features remain competitive with supervised classifiers on in-distribution data.
- The same representations improve robustness when the test distribution includes language models absent from training.
- The learned features transfer directly to authorship verification and fine-grained style classification without additional task-specific training.
Where Pith is reading between the lines
- The same inversion objective could be applied to separate style from content in other media such as code or speech.
- Because the method needs only paired human and paraphrased text, it may scale to much larger unlabeled corpora than label-dependent style detectors.
- If the frozen semantic encoder leaks residual style information, the learned features would mix semantic and stylistic signals and lose some of their claimed purity.
Load-bearing premise
Freezing the semantic encoder during training will cause the style encoder to capture only the non-semantic features required for accurate reconstruction.
What would settle it
A controlled experiment showing that the zero-shot DeepSVDD detector performs no better than a fully supervised baseline when tested on a fresh set of LLMs not seen during training would falsify the generalization advantage.
Figures

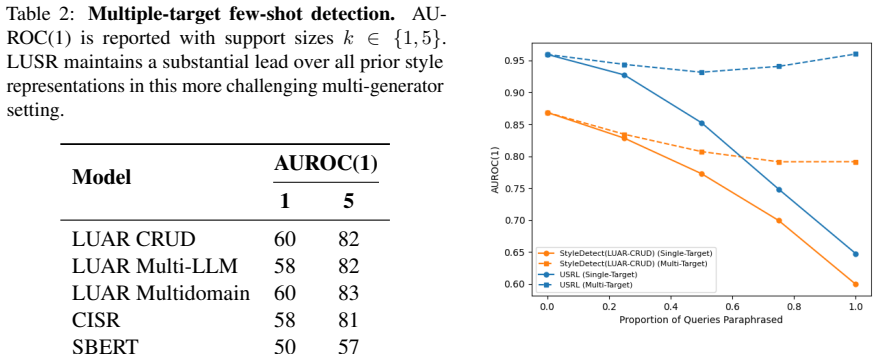
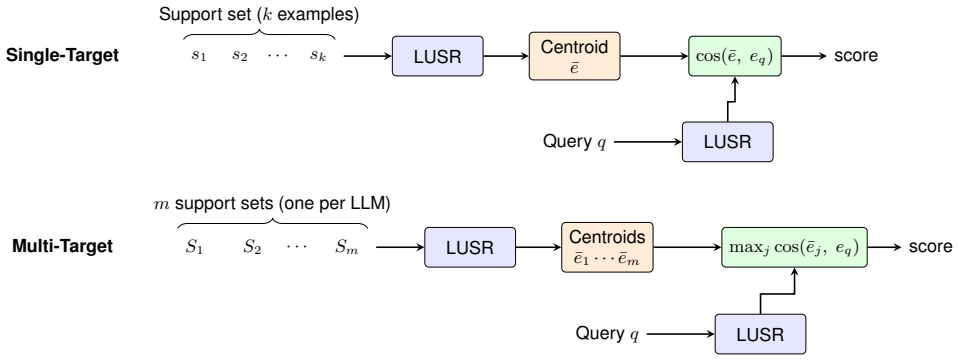
read the original abstract
The rapid development of large language models (LLMs) has raised concerns about misuse such as plagiarism, misinformation, and automated influence operations, motivating the need for robust detectors. Recent work has shown that neural representations of writing style are effective for detection and, crucially, robust to adversarial attacks that defeat most existing detectors. However, current style-based detectors rely on authorship labels for training, and are limited to few-shot inference for detection, requiring in-distribution samples that may not always be available. We learn discriminative style features without authorship labels by training a style encoder to reconstruct human-authored text from its machine-generated paraphrase; freezing a semantic encoder during training biases the style encoder to capture only the non-semantic features needed for reconstruction. We evaluate the learned representations via two detection strategies: a few-shot detector and a zero-shot DeepSVDD-based detector. Across benchmarks, our method matches or outperforms all baselines in the few-shot setting and, in the zero-shot regime, is competitive with fully supervised classifiers on in-distribution test data while generalizing better to unseen LLMs. Beyond detection, the learned representations generalize to unseen tasks, achieving competitive performance on authorship verification and fine-grained style discrimination despite never being trained on either objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an unsupervised approach to learning style representations for AI-text detection by training a style encoder to reconstruct human-authored text from machine-generated paraphrases, with a frozen semantic encoder intended to bias the style encoder toward non-semantic features. Representations are evaluated using few-shot and zero-shot (DeepSVDD) detectors, with claims of matching or outperforming baselines in few-shot settings, competitive zero-shot performance on in-distribution data with superior generalization to unseen LLMs, and transfer to authorship verification and fine-grained style tasks without task-specific training.
Significance. If the core mechanism holds and the reported performance generalizes, the work would be significant for enabling label-free style-based detection, addressing the limitation of prior methods that require authorship labels and improving robustness to unseen models. The paraphrase-inversion training signal offers a concrete path toward disentangling style without supervision, with potential broader impact on style-related tasks.
major comments (2)
- [Abstract] Abstract: The central claim that freezing the semantic encoder 'biases the style encoder to capture only the non-semantic features needed for reconstruction' is load-bearing for the unsupervised framing and all downstream performance claims, yet the manuscript provides no ablations, disentanglement metrics, or architecture details to verify that semantic leakage is prevented or that reconstruction requires style-specific features.
- [Abstract] Abstract (evaluation claims): The statements that the method 'matches or outperforms all baselines in the few-shot setting' and is 'competitive with fully supervised classifiers on in-distribution test data while generalizing better to unseen LLMs' in zero-shot are presented without reference to specific quantitative results, benchmark details, baseline implementations, or statistical significance tests, making it impossible to assess whether the data support the generalization advantage.
minor comments (1)
- The abstract would be clearer if it specified the number of benchmarks, the exact LLMs used for out-of-distribution testing, and the precise few-shot/zero-shot protocols.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address each major comment below and indicate where revisions will be made to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that freezing the semantic encoder 'biases the style encoder to capture only the non-semantic features needed for reconstruction' is load-bearing for the unsupervised framing and all downstream performance claims, yet the manuscript provides no ablations, disentanglement metrics, or architecture details to verify that semantic leakage is prevented or that reconstruction requires style-specific features.
Authors: We agree that the manuscript would be strengthened by additional evidence supporting the effect of freezing the semantic encoder. The current version describes the rationale in Section 3 but lacks explicit ablations. In the revised manuscript, we will add an ablation study (new Table or figure) comparing performance with and without freezing, as well as a quantitative analysis of semantic leakage using a pre-trained semantic similarity model on the style representations. We will also expand the architecture description in the main text for better accessibility. This addresses the concern directly. revision: yes
-
Referee: [Abstract] Abstract (evaluation claims): The statements that the method 'matches or outperforms all baselines in the few-shot setting' and is 'competitive with fully supervised classifiers on in-distribution test data while generalizing better to unseen LLMs' in zero-shot are presented without reference to specific quantitative results, benchmark details, baseline implementations, or statistical significance tests, making it impossible to assess whether the data support the generalization advantage.
Authors: The abstract provides a summary of results whose details are fully elaborated in the experimental sections of the manuscript, including quantitative tables, benchmark descriptions, baseline details, and significance tests. However, to make the abstract more self-contained as suggested, we will revise it to include brief quantitative anchors (e.g., specific performance deltas) while respecting length limits. This is a partial revision focused on the abstract. revision: partial
Circularity Check
No circularity; empirical training procedure with no derivations or self-referential reductions
full rationale
The paper describes an unsupervised training procedure that freezes a semantic encoder while training a style encoder on paraphrase reconstruction, then evaluates the resulting representations on detection tasks. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claim rests on experimental outcomes rather than any mathematical chain that reduces to its own inputs by construction. The freezing step is presented as a design choice whose effect is verified empirically, not assumed via prior self-citation or definition. This is the normal case of a self-contained empirical ML paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Freezing the semantic encoder during training forces the style encoder to learn only non-semantic features required for reconstruction
Reference graph
Works this paper leans on
-
[1]
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. 2024. Fast-detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature. In International Conference on Learning Representations, volume 2024, pages 24814--24836
2024
-
[4]
Canyu Chen and Kai Shu. 2024. https://openreview.net/forum?id=ccxD4mtkTU Can LLM -generated misinformation be detected? In The Twelfth International Conference on Learning Representations
2024
-
[6]
Steven Fincke and Elizabeth Boschee. 2024. https://arxiv.org/abs/2408.05192 Separating style from substance: Enhancing cross-genre authorship attribution through data selection and presentation . Preprint, arXiv:2408.05192
arXiv 2024
-
[7]
Frey and Delbert Dueck
Brendan J. Frey and Delbert Dueck. 2007. https://api.semanticscholar.org/CorpusID:6502291 Clustering by passing messages between data points . Science, 315:972 -- 976
2007
-
[8]
Sebastian Gehrmann, Hendrik Strobelt, and Alexander M Rush. 2019. Gltr: Statistical detection and visualization of generated text. In Proceedings of the 57th annual meeting of the association for computational linguistics: system demonstrations, pages 111--116
2019
-
[9]
Goldstein, Girish Sastry, Micah Musser, Renée DiResta, Matthew Gentzel, and Katerina Sedova
Josh A. Goldstein, Girish Sastry, Micah Musser, Renée DiResta, Matthew Gentzel, and Katerina Sedova. 2023. https://arxiv.org/abs/2301.04246 Generative language models and automated influence operations: Emerging threats and potential mitigations . Preprint, arXiv:2301.04246
arXiv 2023
-
[11]
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2024. Spotting llms with binoculars: zero-shot detection of machine-generated text. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org
2024
-
[12]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
-
[13]
Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. 2023. https://openreview.net/forum?id=QGrkbaan79 RADAR : Robust AI -text detection via adversarial learning . In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[16]
Patrick Juola and Efstathios Stamatatos. 2013. https://api.semanticscholar.org/CorpusID:4256462 Overview of the author identification task at PAN 2013 . In Conference and Labs of the Evaluation Forum
2013
-
[18]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/d89a66c7c80a29b1bdbab0f2a1a94af8-Paper.pdf Supervised contrastive learning . In Advances in Neural Information Processing Systems, volume 33, pages 18661--18673....
2020
-
[20]
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. 2023. A watermark for large language models. In International conference on machine learning, pages 17061--17084. PMLR
2023
-
[21]
Kalpesh Krishna, John Wieting, and Mohit Iyyer. 2020. Reformulating unsupervised style transfer as paraphrase generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 737--762
2020
-
[22]
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. 2024. https://arxiv.org/abs/2307.15593 Robust distortion-free watermarks for language models . Preprint, arXiv:2307.15593
arXiv 2024
-
[23]
Hyunseok Lee, Jihoon Tack, and Jinwoo Shin. 2024. https://openreview.net/forum?id=pW9Jwim918 Remodetect: Reward models recognize aligned LLM 's generations . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[31]
Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel M \"u ller, and Marius Kloft. 2018. https://proceedings.mlr.press/v80/ruff18a.html Deep one-class classification . In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pa...
2018
-
[32]
Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. 2025. https://arxiv.org/abs/2303.11156 Can ai-generated text be reliably detected? Preprint, arXiv:2303.11156
Pith/arXiv arXiv 2025
-
[33]
Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS'17, page 4080–4090, Red Hook, NY, USA. Curran Associates Inc
2017
-
[34]
Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, and Jasmine Wang. 2019. https://arxiv.org/abs/1908.09203 Release strategies and the social impacts of language models . Preprint, arXiv:1908.09203
Pith/arXiv arXiv 2019
-
[35]
Chen, Marcus Bishop, and Nicholas Andrews
Rafael Alberto Rivera Soto, Kailin Koch, Aleem Khan, Barry Y. Chen, Marcus Bishop, and Nicholas Andrews. 2024. https://openreview.net/forum?id=cWiEN1plhJ Few-shot detection of machine-generated text using style representations . In The Twelfth International Conference on Learning Representations
2024
-
[36]
Efstathios Stamatatos, Walter Daelemans, Ben Verhoeven, Martin Potthast, Benno Stein, Patrick Juola, Miguel A Sanchez-Perez, Alberto Barr \'o n-Cede \ n o, et al. 2014. Overview of the author identification task at PAN 2014. In CEUR workshop proceedings, volume 1180, pages 877--897. CEUR-WS
2014
-
[37]
Efstathios Stamatatos, Martin Potthast, Francisco Rangel, Paolo Rosso, and Benno Stein. 2015. Overview of the pan/clef 2015 evaluation lab. In International Conference of the Cross-Language Evaluation Forum for European Languages, pages 518--538. Springer
2015
-
[38]
Jinyan Su, Terry Yue Zhuo, Di Wang, and Preslav Nakov. 2023. https://openreview.net/forum?id=Dy2mbQIdMz Detect LLM : Leveraging log rank information for zero-shot detection of machine-generated text . In The 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[39]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2019. https://arxiv.org/abs/1807.03748 Representation learning with contrastive predictive coding . Preprint, arXiv:1807.03748
Pith/arXiv arXiv 2019
-
[40]
Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Chenxi Whitehouse, Osama Mohammed Afzal, Tarek Mahmoud, Alham Fikri Aji, and Preslav Nakov. 2024. https://aclanthology.org/2024.eacl-long.83 M4 : Multi-generator, multi-domain, and multi-lingual black-box machine-generated text detection . In Proceedings of the 18th Conf...
2024
-
[44]
A Survey on LLM -Generated Text Detection: Necessity, Methods, and Future Directions
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Derek F. Wong, and Lidia S. Chao. 2025. https://doi.org/10.1162/coli_a_00549 A survey on LLM -generated text detection: Necessity, methods, and future directions . Computational Linguistics, 51(1):275--338
-
[46]
Xianjun Yang, Wei Cheng, Yue Wu, Linda Ruth Petzold, William Yang Wang, and Haifeng Chen. 2024. https://openreview.net/forum?id=Xlayxj2fWp DNA - GPT : Divergent n-gram analysis for training-free detection of GPT -generated text . In The Twelfth International Conference on Learning Representations
2024
-
[47]
Cong Zeng, Shengkun Tang, Yuanzhou Chen, Zhiqiang Shen, Wenchao Yu, Xujiang Zhao, Haifeng Chen, Wei Cheng, and zhiqiang xu. 2025. https://openreview.net/forum?id=0XKZFK4hQt Human texts are outliers: Detecting LLM -generated texts via out-of-distribution detection . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[49]
Zhu, Biru and Yuan, Lifan and Cui, Ganqu and Chen, Yangyi and Fu, Chong and He, Bingxiang and Deng, Yangdong and Liu, Zhiyuan and Sun, Maosong and Gu, Ming. Beat LLM s at Their Own Game: Zero-Shot LLM -Generated Text Detection via Querying C hat GPT. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653...
-
[50]
Does It Capture STEL ? A Modular, Similarity-based Linguistic Style Evaluation Framework
Wegmann, Anna and Nguyen, Dong. Does It Capture STEL ? A Modular, Similarity-based Linguistic Style Evaluation Framework. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.569
-
[51]
RAID : A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors
Dugan, Liam and Hwang, Alyssa and Trhl \'i k, Filip and Zhu, Andrew and Ludan, Josh Magnus and Xu, Hainiu and Ippolito, Daphne and Callison-Burch, Chris. RAID : A Shared Benchmark for Robust Evaluation of Machine-Generated Text Detectors. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024....
-
[52]
S tyle D istance: Stronger Content-Independent Style Embeddings with Synthetic Parallel Examples
Patel, Ajay and Zhu, Jiacheng and Qiu, Justin and Horvitz, Zachary and Apidianaki, Marianna and McKeown, Kathleen and Callison-Burch, Chris. S tyle D istance: Stronger Content-Independent Style Embeddings with Synthetic Parallel Examples. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
-
[53]
A Deep Metric Learning Approach to Account Linking
Khan, Aleem and Fleming, Elizabeth and Schofield, Noah and Bishop, Marcus and Andrews, Nicholas. A Deep Metric Learning Approach to Account Linking. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.415
-
[54]
Wang, Zhengxiang and Tripto, Nafis Irtiza and Park, Solha and Li, Zhenzhen and Zhou, Jiawei. Catch Me If You Can? Not Yet: LLM s Still Struggle to Imitate the Implicit Writing Styles of Everyday Authors. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.532
-
[55]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[56]
Rivera Soto, Rafael Alberto and Chen, Barry Y. and Andrews, Nicholas. Mitigating Paraphrase Attacks on Machine-Text Detection via Paraphrase Inversion. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.227
-
[57]
Counterfactual Evaluation for Blind Attack Detection in LLM -based Evaluation Systems
Liu, Lijia and Kondo, Takumi and Atarashi, Kyohei and Takeuchi, Koh and Li, Jiyi and Saito, Shigeru and Kashima, Hisashi. Counterfactual Evaluation for Blind Attack Detection in LLM -based Evaluation Systems. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Asso...
-
[58]
Kim, Junghwan and Zhang, Haotian and Jurgens, David. Leveraging Multilingual Training for Authorship Representation: Enhancing Generalization across Languages and Domains. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1766
-
[59]
Same Author or Just Same Topic? Towards Content-Independent Style Representations
Wegmann, Anna and Schraagen, Marijn and Nguyen, Dong. Same Author or Just Same Topic? Towards Content-Independent Style Representations. Proceedings of the 7th Workshop on Representation Learning for NLP. 2022. doi:10.18653/v1/2022.repl4nlp-1.26
-
[60]
and Miano, Olivia Elizabeth and Ordonez, Juanita and Chen, Barry Y
Rivera-Soto, Rafael A. and Miano, Olivia Elizabeth and Ordonez, Juanita and Chen, Barry Y. and Khan, Aleem and Bishop, Marcus and Andrews, Nicholas. Learning Universal Authorship Representations. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.70
-
[61]
Li, Yafu and Li, Qintong and Cui, Leyang and Bi, Wei and Wang, Zhilin and Wang, Longyue and Yang, Linyi and Shi, Shuming and Zhang, Yue. MAGE : Machine-generated Text Detection in the Wild. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.3
-
[62]
Automatic Detection of Generated Text is Easiest when Humans are Fooled , booktitle =
Ippolito, Daphne and Duckworth, Daniel and Callison-Burch, Chris and Eck, Douglas. Automatic Detection of Generated Text is Easiest when Humans are Fooled. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.164
-
[63]
Huertas-Tato, Javier and Mart\'. Understanding writing style in social media with a supervised contrastively pre-trained transformer , year =. doi:10.1016/j.knosys.2024.111867 , journal =
-
[64]
International Conference of the Cross-Language Evaluation Forum for European Languages , pages=
Overview of the PAN/CLEF 2015 evaluation lab , author=. International Conference of the Cross-Language Evaluation Forum for European Languages , pages=. 2015 , organization=
2015
-
[65]
Overview of the author identification task at
Stamatatos, Efstathios and Daelemans, Walter and Verhoeven, Ben and Potthast, Martin and Stein, Benno and Juola, Patrick and Sanchez-Perez, Miguel A and Barr. Overview of the author identification task at. CEUR workshop proceedings , volume=. 2014 , organization=
2014
-
[66]
Bevendorff, Janek and Chulvi, Berta and De La Pe\. Overview of. Experimental IR Meets Multilinguality, Multimodality, and Interaction: 12th International Conference of the CLEF Association, CLEF 2021, Virtual Event, September 21–24, 2021, Proceedings , pages =. 2021 , isbn =. doi:10.1007/978-3-030-85251-1_26 , abstract =
-
[67]
Bevendorff, Janek and Ghanem, Bilal and Giachanou, Anastasia and Kestemont, Mike and Manjavacas, Enrique and Markov, Ilia and Mayerl, Maximilian and Potthast, Martin and Rangel, Francisco and Rosso, Paolo and Specht, G\". Overview of. Experimental IR Meets Multilinguality, Multimodality, and Interaction: 11th International Conference of the CLEF Associati...
-
[68]
Overview of the Author Identification Task at
Patrick Juola and Efstathios Stamatatos , booktitle=. Overview of the Author Identification Task at. 2013 , url=
2013
-
[69]
2024 , url=
Xianjun Yang and Wei Cheng and Yue Wu and Linda Ruth Petzold and William Yang Wang and Haifeng Chen , booktitle=. 2024 , url=
2024
-
[70]
Proceedings of the 57th annual meeting of the association for computational linguistics: system demonstrations , pages=
Gltr: Statistical detection and visualization of generated text , author=. Proceedings of the 57th annual meeting of the association for computational linguistics: system demonstrations , pages=
-
[71]
2019 , eprint=
Release Strategies and the Social Impacts of Language Models , author=. 2019 , eprint=
2019
-
[72]
2023 , url=
Xiaomeng Hu and Pin-Yu Chen and Tsung-Yi Ho , booktitle=. 2023 , url=
2023
-
[73]
ReMoDetect: Reward Models Recognize Aligned
Hyunseok Lee and Jihoon Tack and Jinwoo Shin , booktitle=. ReMoDetect: Reward Models Recognize Aligned. 2024 , url=
2024
-
[74]
Jinyan Su and Terry Yue Zhuo and Di Wang and Preslav Nakov , booktitle=. Detect. 2023 , url=
2023
-
[75]
Science , year=
Clustering by Passing Messages Between Data Points , author=. Science , year=
-
[76]
Proceedings of the National Academy of Sciences , volume =
Alex Reinhart and Ben Markey and Michael Laudenbach and Kachatad Pantusen and Ronald Yurko and Gordon Weinberg and David West Brown , title =. Proceedings of the National Academy of Sciences , volume =. 2025 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.2422455122 , abstract =
-
[77]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[78]
Human Texts Are Outliers: Detecting
Cong Zeng and Shengkun Tang and Yuanzhou Chen and Zhiqiang Shen and Wenchao Yu and Xujiang Zhao and Haifeng Chen and Wei Cheng and zhiqiang xu , booktitle=. Human Texts Are Outliers: Detecting. 2025 , url=
2025
-
[79]
Proceedings of the 35th International Conference on Machine Learning , pages =
Deep One-Class Classification , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[80]
2025 , eprint=
Language Models Optimized to Fool Detectors Still Have a Distinct Style (And How to Change It) , author=. 2025 , eprint=
2025
-
[81]
2023 , eprint=
Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations , author=. 2023 , eprint=
2023
-
[82]
Canyu Chen and Kai Shu , year=. Can. The Twelfth International Conference on Learning Representations , url=
-
[83]
Wong and Lidia S
Junchao Wu and Shu Yang and Runzhe Zhan and Yulin Yuan and Derek F. Wong and Lidia S. Chao , journal=. A Survey on. 2025 , publisher=
2025
-
[84]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Hans, Abhimanyu and Schwarzschild, Avi and Cherepanova, Valeriia and Kazemi, Hamid and Saha, Aniruddha and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[85]
The Thirteenth International Conference on Learning Representations , year=
Contextual Document Embeddings , author=. The Thirteenth International Conference on Learning Representations , year=
-
[86]
, title =
Li, Da and Zhang, Jianshu and Yang, Yongxin and Liu, Cong and Song, Yi-Zhe and Hospedales, Timothy M. , title =. The IEEE International Conference on Computer Vision (ICCV) , month =
-
[87]
Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =
Finn, Chelsea and Abbeel, Pieter and Levine, Sergey , title =. Proceedings of the 34th International Conference on Machine Learning - Volume 70 , pages =. 2017 , publisher =
2017
-
[88]
2024 , eprint=
Separating Style from Substance: Enhancing Cross-Genre Authorship Attribution through Data Selection and Presentation , author=. 2024 , eprint=
2024
-
[89]
and Yang, Shu and Yang, Xinyi and Yuan, Yulin and Chao, Lidia S
Wu, Junchao and Zhan, Runzhe and Wong, Derek F. and Yang, Shu and Yang, Xinyi and Yuan, Yulin and Chao, Lidia S. , booktitle =. DetectRL: Benchmarking LLM-Generated Text Detection in Real-World Scenarios , url =. doi:10.52202/079017-3186 , editor =
-
[90]
Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
Snell, Jake and Swersky, Kevin and Zemel, Richard , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[91]
Man, Hieu and Huu Nguyen, Thien , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , isbn =. doi:10.1145/3626772.3657956 , abstract =
-
[92]
Supervised Contrastive Learning , url =
Khosla, Prannay and Teterwak, Piotr and Wang, Chen and Sarna, Aaron and Tian, Yonglong and Isola, Phillip and Maschinot, Aaron and Liu, Ce and Krishnan, Dilip , booktitle =. Supervised Contrastive Learning , url =
-
[93]
2019 , eprint=
Representation Learning with Contrastive Predictive Coding , author=. 2019 , eprint=
2019
-
[94]
2024 , eprint=
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference , author=. 2024 , eprint=
2024
-
[95]
International Conference on Learning Representations , volume=
Fast-detectgpt: Efficient zero-shot detection of machine-generated text via conditional probability curvature , author=. International Conference on Learning Representations , volume=
-
[96]
International conference on machine learning , pages=
A watermark for large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[97]
2024 , eprint=
Robust Distortion-free Watermarks for Language Models , author=. 2024 , eprint=
2024
-
[98]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Reformulating unsupervised style transfer as paraphrase generation , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[99]
2025 , eprint=
Can AI-Generated Text be Reliably Detected? , author=. 2025 , eprint=
2025
-
[100]
The Twelfth International Conference on Learning Representations , year=
Few-Shot Detection of Machine-Generated Text using Style Representations , author=. The Twelfth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.