FedSteer: Taming Extreme Gradient Staleness in Federated Learning with Corrective Projections and Caching
Pith reviewed 2026-06-27 17:30 UTC · model grok-4.3
The pith
Projecting active gradients onto a cached subspace reuses stale client updates without destabilizing federated training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a gradient subspace built from cached recent client gradients serves as a persistent low-dimensional representation of the optimization landscape; projecting an active client's gradient yields reusable coordinates that, when applied to the evolved subspace, correct stale updates from inactive clients and align them with the current objective.
What carries the argument
Corrective projection of client gradients onto a low-dimensional subspace derived from a cache of recent gradients, with coordinate reuse across subspace drift and selective client caching.
If this is right
- Training remains stable under extreme participation skew where prior reuse methods collapse.
- Accuracy improves by more than 7 percent relative to baselines in tested settings.
- Server memory is reduced by caching only a representative subset of clients.
- Stale updates can be retained and corrected rather than discarded.
Where Pith is reading between the lines
- The same projection-and-reuse pattern could apply to other distributed optimization problems that suffer from delayed or partial updates.
- Varying the subspace dimension would likely trade off representation fidelity against per-round computation.
- The approach may interact with existing momentum or variance-reduction techniques in federated settings.
Load-bearing premise
The subspace formed from cached gradients stays a faithful representation of the current landscape even after active clients have altered it.
What would settle it
A controlled experiment in which reusing coordinates on the drifted subspace yields lower final accuracy than simply discarding all stale gradients.
Figures



read the original abstract
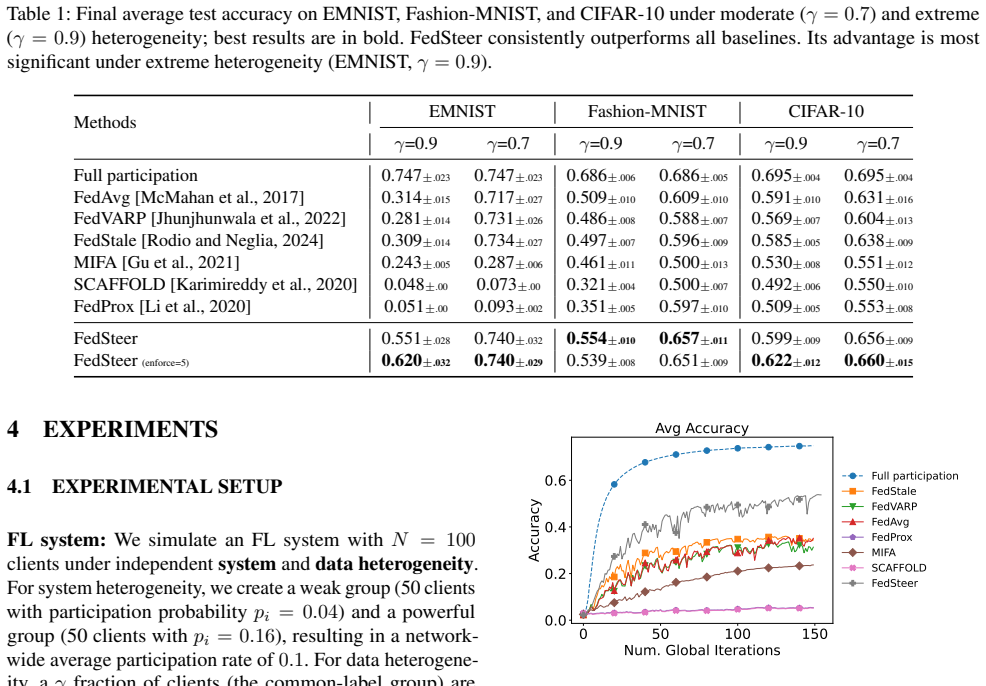
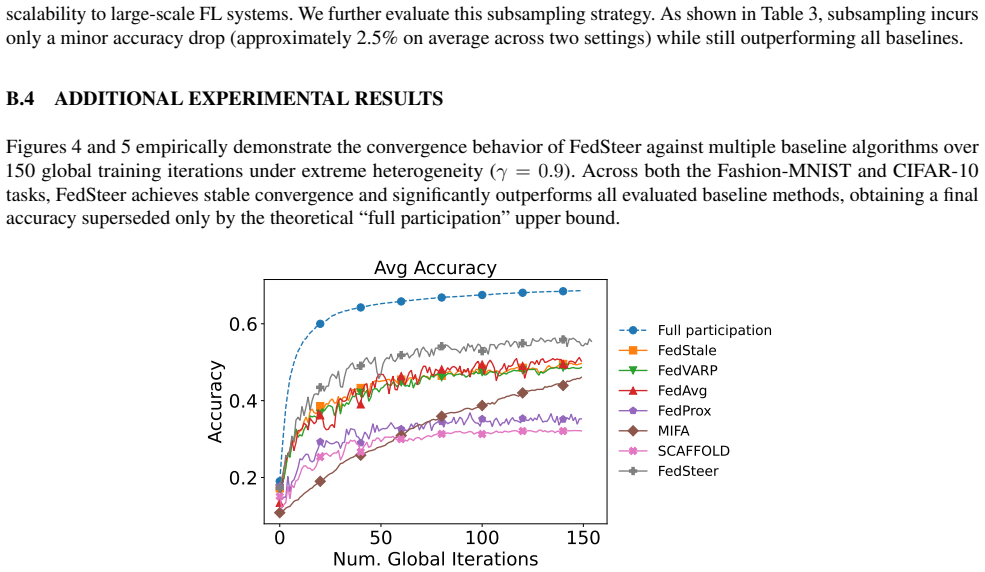
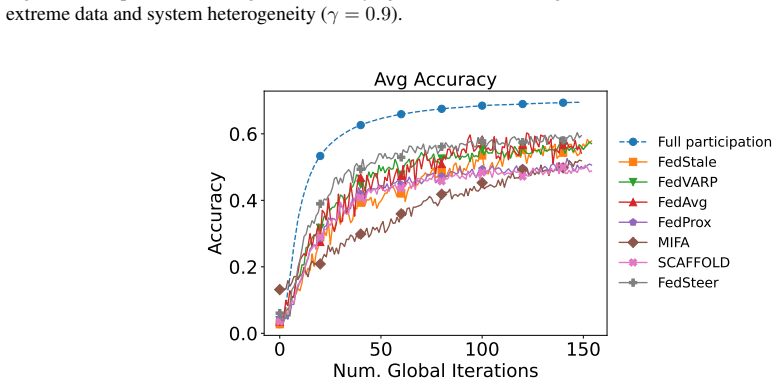
Federated learning (FL) is often subject to aggregation variance if clients do not consistently participate in training rounds. While reusing stale model updates from inactive clients is a common technique to reduce this variance, we find that with skewed client participation, the resulting update staleness can become severe enough to destabilize training. To remedy this, we propose FedSteer, a novel method that constructs a gradient subspace from a cache of recent client gradients to serve as a low-dimensional representation of the current optimization landscape. FedSteer projects an active client's true gradient onto this subspace to find a set of optimal coordinates. For an inactive client, FedSteer reuses these coordinates with the now-evolved subspace drifted by other active clients. This process effectively "steers" outdated gradients toward the current global objective. This is complemented by a selective caching strategy that identifies a representative client subset to form the subspace, reducing server memory. Experiments demonstrate that FedSteer significantly outperforms baselines, preventing performance collapse in challenging scenarios while delivering accuracy gains of over 7% in others.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FedSteer to address extreme gradient staleness in federated learning arising from skewed client participation. It constructs a low-dimensional gradient subspace from a cache of recent client gradients, projects an active client's gradient onto this subspace to obtain coordinates, and reuses those exact coordinates with the subspace after it has been updated by other clients to steer stale gradients from inactive clients. A selective caching strategy is used to maintain a representative subset and limit server memory. Experiments are reported to show that FedSteer outperforms baselines, prevents performance collapse under challenging participation patterns, and yields accuracy improvements exceeding 7% in other settings.
Significance. If the coordinate-reuse mechanism can be shown to preserve alignment with the current objective despite subspace drift, the approach would offer a targeted remedy for aggregation variance in non-uniform FL participation regimes, complementing existing staleness-handling techniques. The selective caching component additionally addresses practical memory constraints. The reported empirical gains suggest potential practical utility, though the absence of supporting analysis for the core reuse step limits the strength of the significance assessment at present.
major comments (1)
- [Abstract (projection and reuse step)] Abstract (paragraph describing the projection and reuse step): the central claim that reusing the fixed scalar coordinates obtained from projection onto the cached subspace continues to steer inactive-client gradients toward the current global objective after the basis has drifted lacks any supporting invariance argument, error bound, or stationarity condition. This reuse is load-bearing for the method's ability to tame staleness rather than merely mask it; without such justification the steered update can map to an arbitrary direction in the updated basis when client gradients are heterogeneous.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the core reuse mechanism. We agree that a formal justification is needed to substantiate the claim and will add supporting analysis in the revision.
read point-by-point responses
-
Referee: Abstract (paragraph describing the projection and reuse step): the central claim that reusing the fixed scalar coordinates obtained from projection onto the cached subspace continues to steer inactive-client gradients toward the current global objective after the basis has drifted lacks any supporting invariance argument, error bound, or stationarity condition. This reuse is load-bearing for the method's ability to tame staleness rather than merely mask it; without such justification the steered update can map to an arbitrary direction in the updated basis when client gradients are heterogeneous.
Authors: We acknowledge that the manuscript currently lacks an invariance argument, error bound, or stationarity condition for the coordinate-reuse step after subspace drift. This is a substantive gap. In the revised version we will add a dedicated theoretical subsection deriving a bound on directional misalignment under standard FL assumptions (bounded gradient heterogeneity and controlled subspace drift). The analysis will show that the reused coordinates remain aligned with the current objective up to an additive error term proportional to the drift magnitude and client dissimilarity, thereby distinguishing steering from masking. revision: yes
Circularity Check
No circularity: algorithmic proposal with empirical support only
full rationale
The paper presents FedSteer as a constructive algorithm: cache recent gradients to form a subspace, project active-client gradients to obtain coordinates, then reuse those fixed scalars on the updated subspace for inactive clients. No equations, fitted parameters, or derived quantities appear in the supplied text. The performance claims rest on experimental results rather than any reduction of a 'prediction' to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the coordinate-reuse step. The method is therefore self-contained as an engineering proposal whose validity is tested externally rather than defined into existence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A low-dimensional subspace constructed from cached recent gradients remains representative of the optimization landscape after drift by active clients.
invented entities (1)
-
gradient subspace from cached client updates
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2409.17446 , year=
Efficient federated learning against heterogeneous and non-stationary client unavailability , author=. arXiv preprint arXiv:2409.17446 , year=
-
[2]
Communication-Efficient Federated Learning for Resource-Constrained Edge Devices , year=
Lan, Guangchen and Liu, Xiao-Yang and Zhang, Yijing and Wang, Xiaodong , journal=. Communication-Efficient Federated Learning for Resource-Constrained Edge Devices , year=
-
[3]
arXiv preprint arXiv:2010.13723 , year=
Optimal client sampling for federated learning , author=. arXiv preprint arXiv:2010.13723 , year=
arXiv 2010
-
[4]
ICML , pages=
Nonconvex variance reduced optimization with arbitrary sampling , author=. ICML , pages=. 2019 , organization=
2019
-
[5]
Lin Wang and Yongxin Guo and Tao Lin and Xiaoying Tang , booktitle=
-
[6]
arXiv preprint arXiv:1905.10497 , year=
Fair resource allocation in federated learning , author=. arXiv preprint arXiv:1905.10497 , year=
arXiv 1905
-
[7]
IPSN , pages=
Fair Training of Multiple Federated Learning Models on Resource Constrained Network Devices , author=. IPSN , pages=
-
[8]
arXiv preprint arXiv:2010.01243 , year=
Client selection in federated learning: Convergence analysis and power-of-choice selection strategies , author=. arXiv preprint arXiv:2010.01243 , year=
arXiv 2010
-
[9]
arXiv preprint arXiv:2006.06954 , year=
Towards flexible device participation in federated learning for non-iid data , author=. arXiv preprint arXiv:2006.06954 , year=
arXiv 2006
-
[10]
IEEE INFOCOM 2022 , pages=
Tackling system and statistical heterogeneity for federated learning with adaptive client sampling , author=. IEEE INFOCOM 2022 , pages=. 2022 , organization=
2022
-
[11]
ICASSP , pages=
Optimal importance sampling for federated learning , author=. ICASSP , pages=. 2021 , organization=
2021
-
[12]
ICML , pages=
On the convergence of federated averaging with cyclic client participation , author=. ICML , pages=. 2023 , organization=
2023
-
[13]
ICASSP , pages=
A dynamic reweighting strategy for fair federated learning , author=. ICASSP , pages=. 2022 , organization=
2022
-
[14]
COMSNETS , pages=
Multi-model federated learning , author=. COMSNETS , pages=. 2022 , organization=
2022
-
[15]
EAI VALUETOOLS , pages=
Multi-model federated learning with provable guarantees , author=. EAI VALUETOOLS , pages=. 2022 , organization=
2022
-
[16]
Fair Concurrent Training of Multiple Models in Federated Learning , author=. arXiv:2404.13841 , year=
-
[17]
ICDCS , year=
Poster: Optimal Variance-Reduced Client Sampling for Multiple Models Federated Learning , author=. ICDCS , year=
-
[18]
AISTATS , pages=
Communication-efficient learning of deep networks from decentralized data , author=. AISTATS , pages=. 2017 , organization=
2017
-
[19]
arXiv preprint arXiv:1811.03604 , year=
Federated learning for mobile keyboard prediction , author=. arXiv preprint arXiv:1811.03604 , year=
-
[20]
2020 , organization=
Training keyword spotting models on non-iid data with federated learning , author=. 2020 , organization=
2020
-
[21]
ICASSP , pages=
Training speech recognition models with federated learning: A quality/cost framework , author=. ICASSP , pages=. 2021 , organization=
2021
-
[22]
arXiv preprint arXiv:1901.09888 , year=
Federated collaborative filtering for privacy-preserving personalized recommendation system , author=. arXiv preprint arXiv:1901.09888 , year=
Pith/arXiv arXiv 1901
-
[23]
IEEE Transactions on Parallel and Distributed Systems , volume=
Multi-task federated learning for personalised deep neural networks in edge computing , author=. IEEE Transactions on Parallel and Distributed Systems , volume=. 2021 , publisher=
2021
-
[24]
Advances in neural information processing systems , volume=
Federated multi-task learning , author=. Advances in neural information processing systems , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
Federated multi-objective learning , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
arXiv preprint arXiv:2007.15197 , year=
Communication-efficient federated learning via optimal client sampling , author=. arXiv preprint arXiv:2007.15197 , year=
arXiv 2007
-
[27]
AISTATS , pages=
Towards understanding biased client selection in federated learning , author=. AISTATS , pages=. 2022 , organization=
2022
-
[28]
arXiv preprint arXiv:2401.10765 , year=
Starlit: Privacy-Preserving Federated Learning to Enhance Financial Fraud Detection , author=. arXiv preprint arXiv:2401.10765 , year=
-
[29]
Baris Askin and Pranay Sharma and Carlee Joe-Wong and Gauri Joshi , booktitle=. Fed
-
[30]
IEEE TCCN , year=
Asynchronous multi-model dynamic federated learning over wireless networks: Theory, modeling, and optimization , author=. IEEE TCCN , year=
-
[31]
IEEE TPDS , volume=
Multi-Job Intelligent Scheduling With Cross-Device Federated Learning , author=. IEEE TPDS , volume=. 2022 , publisher=
2022
-
[32]
arXiv preprint arXiv:2405.04171 , year=
FedStale: leveraging stale client updates in federated learning , author=. arXiv preprint arXiv:2405.04171 , year=
-
[33]
Jhunjhunwala, Divyansh and Sharma, Pranay and Nagarkatti, Aushim and Joshi, Gauri , booktitle=. Fed
-
[34]
NeurIPS , year=
Fast federated learning in the presence of arbitrary device unavailability , author=. NeurIPS , year=
-
[35]
ICML , pages=
Scaffold: Stochastic controlled averaging for federated learning , author=. ICML , pages=. 2020 , organization=
2020
-
[36]
NIPS-W , year=
Automatic differentiation in PyTorch , author=. NIPS-W , year=
-
[37]
ECCV , year=
Identity mappings in deep residual networks , author=. ECCV , year=
-
[38]
IEEE/ACM ToN , year=
How valuable is your data? optimizing client recruitment in federated learning , author=. IEEE/ACM ToN , year=
-
[39]
ICML , pages=
Clustered sampling: Low-variance and improved representativity for clients selection in federated learning , author=. ICML , pages=. 2021 , organization=
2021
-
[40]
2018 , publisher=
Algebraic inequalities , author=. 2018 , publisher=
2018
-
[41]
ICMLA , pages=
Multi-Model-Based Federated Learning to Overcome Local Class Imbalance Issues , author=. ICMLA , pages=. 2023 , organization=
2023
-
[42]
CAMSAP , pages=
Multi-Model Federated Learning Optimization Based on Multi-Agent Reinforcement Learning , author=. CAMSAP , pages=. 2023 , organization=
2023
-
[43]
arXiv preprint arXiv:1906.04329 , year=
Federated learning for emoji prediction in a mobile keyboard , author=. arXiv preprint arXiv:1906.04329 , year=
Pith/arXiv arXiv 1906
-
[44]
ICML , pages=
SGD and Hogwild! convergence without the bounded gradients assumption , author=. ICML , pages=. 2018 , organization=
2018
-
[45]
2022 58th Annual Allerton Conference on Communication, Control, and Computing (Allerton) , pages=
Unbounded gradients in federated learning with buffered asynchronous aggregation , author=. 2022 58th Annual Allerton Conference on Communication, Control, and Computing (Allerton) , pages=. 2022 , organization=
2022
-
[46]
arXiv preprint arXiv:1710.06963 , year=
Learning differentially private recurrent language models , author=. arXiv preprint arXiv:1710.06963 , year=
-
[47]
International conference on artificial intelligence and statistics , pages=
Federated learning with buffered asynchronous aggregation , author=. International conference on artificial intelligence and statistics , pages=. 2022 , organization=
2022
-
[48]
2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS) , pages=
KAFL: Achieving high training efficiency for fast-k asynchronous federated learning , author=. 2022 IEEE 42nd International Conference on Distributed Computing Systems (ICDCS) , pages=. 2022 , organization=
2022
-
[49]
arXiv preprint arXiv:2406.02877 , year=
Fedstaleweight: Buffered asynchronous federated learning with fair aggregation via staleness reweighting , author=. arXiv preprint arXiv:2406.02877 , year=
-
[50]
IEEE transactions on information forensics and security , volume=
Federated learning with differential privacy: Algorithms and performance analysis , author=. IEEE transactions on information forensics and security , volume=. 2020 , publisher=
2020
-
[51]
ICML , year=
Understanding clipping for federated learning: Convergence and client-level differential privacy , author=. ICML , year=
-
[52]
Supplementary Material , url=
-
[53]
IEEE Internet Things J
A survey on federated learning for resource-constrained IoT devices , author=. IEEE Internet Things J. , volume=. 2021 , publisher=
2021
-
[54]
ICLR , year=
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training , author=. ICLR , year=
-
[55]
arXiv preprint arXiv:2504.05138 , year=
Towards optimal heterogeneous client sampling in multi-model federated learning , author=. arXiv preprint arXiv:2504.05138 , year=
-
[56]
Advances in neural information processing systems , volume=
SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives , author=. Advances in neural information processing systems , volume=
-
[57]
arXiv preprint arXiv:1903.03934 , year=
Asynchronous federated optimization , author=. arXiv preprint arXiv:1903.03934 , year=
arXiv 1903
-
[58]
IEEE Transactions on Parallel and Distributed Systems , volume=
Towards efficient and stable K-asynchronous federated learning with unbounded stale gradients on non-IID data , author=. IEEE Transactions on Parallel and Distributed Systems , volume=. 2022 , publisher=
2022
-
[59]
IEEE Transactions on Dependable and Secure Computing , volume=
Robust asynchronous federated learning with time-weighted and stale model aggregation , author=. IEEE Transactions on Dependable and Secure Computing , volume=. 2023 , publisher=
2023
-
[60]
arXiv preprint arXiv:1708.07747 , year=
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms , author=. arXiv preprint arXiv:1708.07747 , year=
-
[61]
2017 international joint conference on neural networks (IJCNN) , pages=
EMNIST: Extending MNIST to handwritten letters , author=. 2017 international joint conference on neural networks (IJCNN) , pages=. 2017 , organization=
2017
-
[62]
Proceedings of Machine learning and systems , volume=
Federated optimization in heterogeneous networks , author=. Proceedings of Machine learning and systems , volume=
-
[63]
2009 , publisher=
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
2009
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Confree: Conflict-free client update aggregation for personalized federated learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.