A Continuous-Time Markov Chain Framework for Insertion Language Models
Pith reviewed 2026-06-27 17:10 UTC · model grok-4.3
The pith
Insertion language models arise as special cases of a continuous-time Markov chain denoising process on variable-length sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By formulating the noising process as a continuous-time Markov chain on the space of variable-length sequences, the authors derive a tractable denoising objective that recovers the original insertion dynamics and shows that previous formulations of ILMs can be viewed as special cases of this general framework.
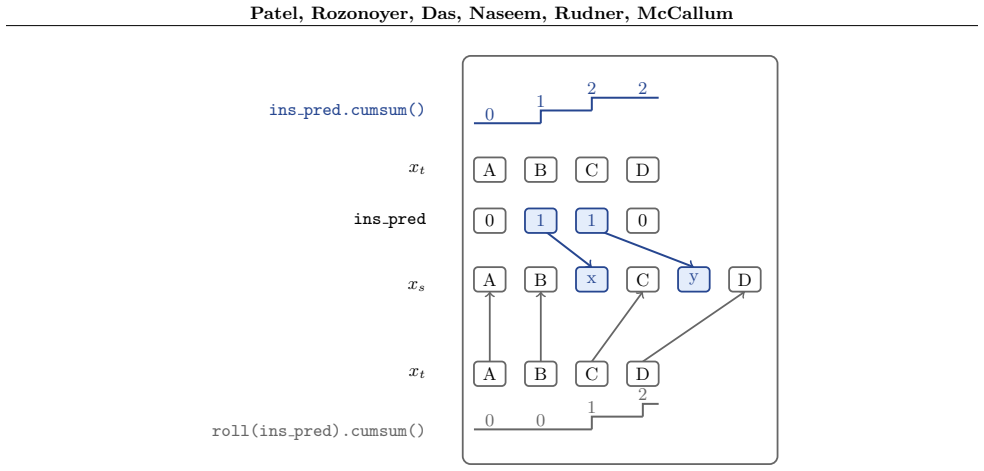
What carries the argument
The continuous-time Markov chain on variable-length sequences, whose transition rates are set to yield a tractable denoising objective that recovers insertion dynamics.
If this is right
- The approach retains the benefits of insertion-based generation over left-to-right generation and masked diffusion models on a synthetic planning task.
- In language modeling the diffusion-based approach is competitive with left-to-right generation and masked diffusion models.
- The framework supplies additional flexibility in sampling compared to existing insertion language models.
- All prior ILM formulations become recoverable as special cases inside the single CTMC denoising setup.
Where Pith is reading between the lines
- Different choices of transition rates in the CTMC could generate new families of insertion dynamics beyond those previously studied.
- The same first-principles construction might extend to other variable-length or tree-structured generation problems outside language.
- Links to existing diffusion models on discrete spaces could allow transfer of variance-reduction or sampling techniques developed elsewhere.
Load-bearing premise
The noising process on variable-length sequences can be exactly represented by a continuous-time Markov chain whose transition rates permit a tractable denoising objective that recovers the original insertion dynamics.
What would settle it
If training with the derived objective on sequences produced by a known insertion model fails to recover the same distribution under sampling, or if no choice of CTMC rates exactly matches the variable-length noising steps of prior ILMs, the unification claim would not hold.
Figures

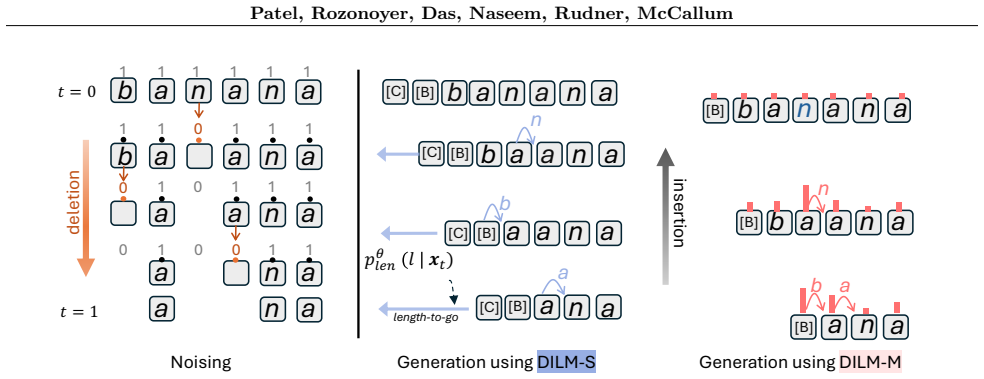
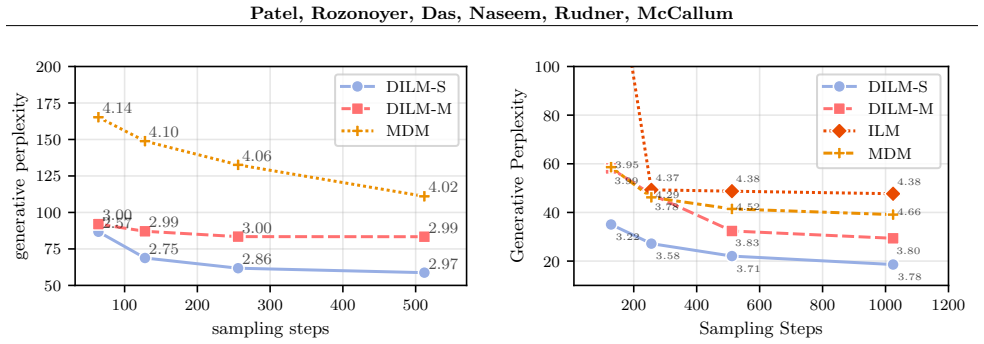

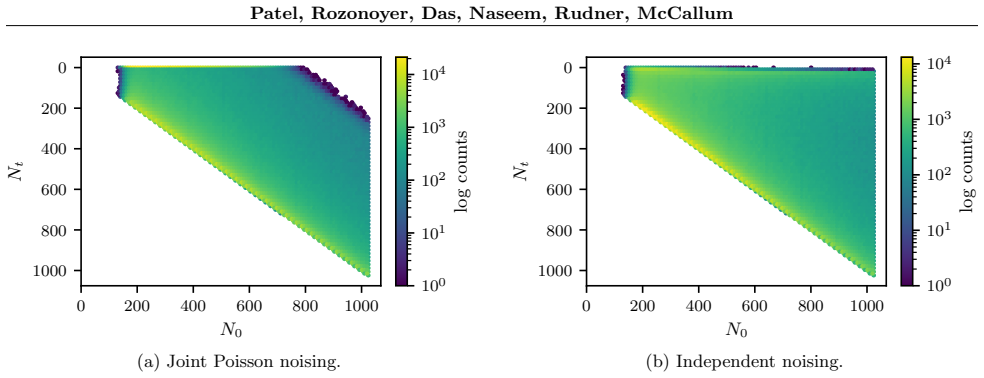
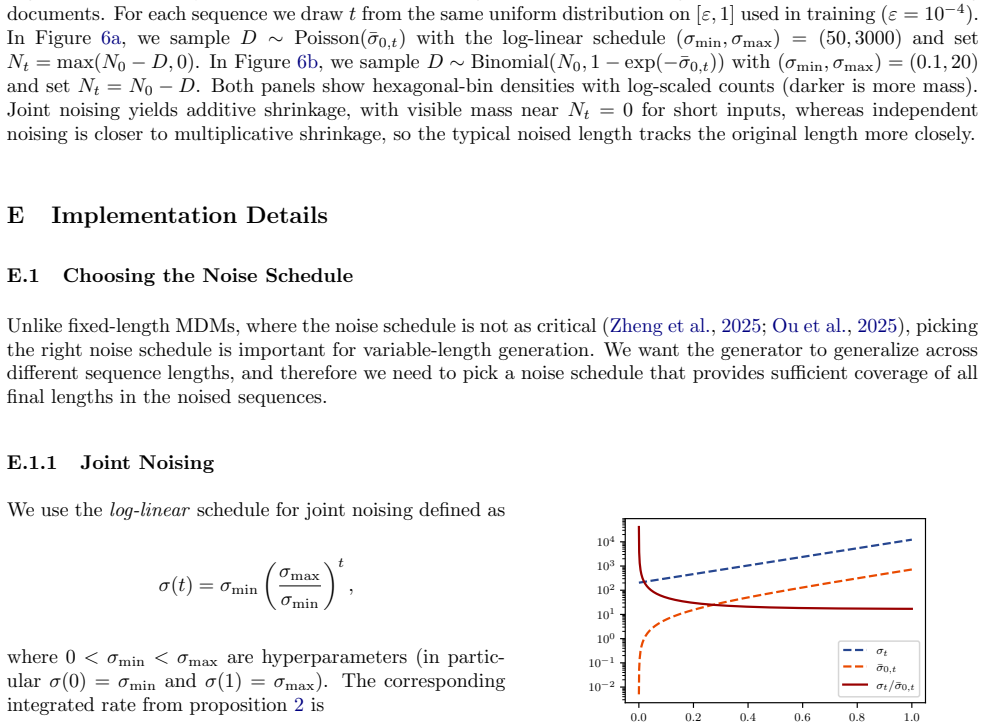
read the original abstract
Insertion Language Models (ILMs) offer several advantages over left-to-right generation and mask-based generation. However, existing formulations of insertion-based generation have largely been ad-hoc. In this paper, we derive a diffusion-style denoising objective for ILMs from first principles by formulating the noising process as a continuous-time Markov chain on the space of variable-length sequences. We show that previous formulations of ILMs can be viewed as special cases of this denoising framework. Through empirical evaluation on a synthetic planning task, we show that the proposed approach retains the benefits of insertion-based generation over left-to-right generation and masked diffusion models. In language modeling, our diffusion-based approach is competitive with left-to-right generation and masked diffusion models, while offering additional flexibility in sampling compared to existing insertion language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive a diffusion-style denoising objective for Insertion Language Models (ILMs) from first principles by formulating the noising process as a continuous-time Markov chain (CTMC) on the space of variable-length sequences. It shows that previous ILM formulations are special cases of this framework and provides empirical results on a synthetic planning task and language modeling, where the approach is competitive with left-to-right generation and masked diffusion models while offering sampling flexibility.
Significance. If the CTMC rate construction, forward process, and reverse-process objective hold, the work supplies a principled unification of ad-hoc ILM methods under a first-principles denoising framework. The explicit demonstration that prior formulations are special cases, together with the retention of insertion-generation benefits in experiments, constitutes a clear advance over existing diffusion and autoregressive approaches for variable-length sequence modeling.
Simulated Author's Rebuttal
We thank the referee for their positive review, accurate summary of our contributions, and recommendation to accept the manuscript. We are pleased that the referee recognizes the value of the first-principles CTMC derivation and the unification of prior ILM methods.
Circularity Check
No significant circularity; first-principles CTMC derivation is self-contained
full rationale
The paper formulates a continuous-time Markov chain on variable-length sequences to derive a denoising objective for insertion language models from first principles. It recovers prior ILM formulations as special cases without reducing any central claim to a fitted parameter, self-citation chain, or definitional equivalence. No load-bearing step equates the output to its inputs by construction; the rate construction and reverse-process objective stand independently of the target result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Yes] (b) An analysis of the properties and complexity (time, space, sample size) of any algorithm
For all models and algorithms presented, check if you include: (a) A clear description of the mathematical set- ting, assumptions, algorithm, and/or model. [Yes] (b) An analysis of the properties and complexity (time, space, sample size) of any algorithm. [Not Applicable] (c) (Optional) Anonymized source code, with specification of all dependencies, inclu...
-
[2]
[Yes] (b) Complete proofs of all theoretical results
For any theoretical claim, check if you include: (a) Statements of the full set of assumptions of all theoretical results. [Yes] (b) Complete proofs of all theoretical results. [Yes, we provide proofs for the new results and provide references for known results.] (c) Clear explanations of any assumptions. [Yes]
-
[3]
[Yes, the code used for this work is available at https://github.com/ dhruvdcoder/ctmc_dilm
For all figures and tables that present empirical results, check if you include: (a) The code, data, and instructions needed to reproduce the main experimental re- sults (either in the supplemental material or as a URL). [Yes, the code used for this work is available at https://github.com/ dhruvdcoder/ctmc_dilm. Appendix E con- tains some key implementati...
-
[4]
[Yes] (b) The license information of the assets, if ap- plicable
If you are using existing assets (e.g., code, data, models) or curating/releasing new assets, check if you include: (a) Citations of the creator If your work uses ex- isting assets. [Yes] (b) The license information of the assets, if ap- plicable. [Not Applicable] (c) New assets either in the supplemental mate- rial or as a URL, if applicable. [Yes, we pr...
-
[5]
[Not Applicable] (b) Descriptions of potential participant risks, with links to Institutional Review Board (IRB) approvals if applicable
If you used crowdsourcing or conducted research with human subjects, check if you include: (a) The full text of instructions given to partici- pants and screenshots. [Not Applicable] (b) Descriptions of potential participant risks, with links to Institutional Review Board (IRB) approvals if applicable. [Not Appli- cable] (c) The estimated hourly wage paid...
2013
-
[6]
Taylor expansion of log: log(1 + x) = x − x2 2 + x3 3 − · · · = x − x2 2 + o(x2) (4)
-
[7]
For a, b > 0, log(ab + o(a)) = log(a(b + o(1))) = log(a) + log(b + o(1)) = log(a) + log(b(1 + o(1))) = log(a) + log(b) + log(1 +o(1)) = log(a) + log(b) + o(1) (5)
-
[8]
With slight abuse of notation, we will denote the probability law of the noising process withq and its time-reversal with p
Bayes rule and the Markov property imply q(xk | xk+1, x0) = q(xk | x0) q(xk+1 | x0) q(xk+1 | xk) = r(k, k + 1)q(xk+1 | xk), (6) where we denote the ratio q(xk|x0) q(xk+1|x0) with r(k, k + 1). With slight abuse of notation, we will denote the probability law of the noising process withq and its time-reversal with p. To begin, recall that the discrete-time ...
2020
-
[9]
log ˆKt(x0[b], x0[a ∨ ek]) = X a∈Bn,m(x0,b) m+1X i=1 X k∈si(a) X w∈V δw(xk
-
[10]
log ˆKt(x0[b], x0[a ∨ ek]) CTMC F ramework for Insertion Language Models where ek ∈ Bn,1 is the vector of length n with all 0s except for the k-th position, Bn,m(x0, b) = {a ∈ Bn,m : x0[a] = x0[b]}, and si(a) is the set of indices of zeros in a that fall between the ( i − 1)-th and i-th 1s. The re- indexing in the third line above is justified by a biject...
-
[11]
log ˆKt(x0[b], x0[b ∨ ek]) (∗) ≈ σt ¯σ0,t E m,b (n − m) ˜Sn,m,σt 1 n − m m+1X i=1 X k∈si(b) X w∈V δw(xk
-
[12]
(15) (*) Here, in the second step, we invoke the following approximation
log ˆpθ ins(i, xk 0 | x0[b]) = σt ¯σ0,t E m,b (n − m) ˜Sn,m,σt X i∈[m+1], w∈V ptarget ins (i, w | x0, b) log ˆpθ ins(i, w | x0[b]) . (15) (*) Here, in the second step, we invoke the following approximation. We fix the alignment between the positions of the current sequence x0[b] and a predecessor state, and identify the predecessor statex0[b∨ek] by the in...
-
[13]
This is exact whenever the predecessor state determines a unique insertion location-token pair, and becomes approximate in the repeated-token case discussed below
Under this approximation, the reverse kernel ˆKt(x0[b], x0[b ∨ ek]) is replaced by the parameterized insertion probability ˆpθ ins(i, xk 0 | x0[b]). This is exact whenever the predecessor state determines a unique insertion location-token pair, and becomes approximate in the repeated-token case discussed below. If x = aa and y = aaa, then the same predece...
-
[14]
ˆλt(x) − σt ¯σ0,t L ˜Sm+L,m,σt log ˆλt(x) Xt = x # = ˆλt(x) − σt ¯σ0,t E
can be seen as the target joint probability distribution over positions and tokens. To see this, note that Pm+1 i=1 si(b) = n − m. Putting eq. (14) and eq. (15) together, we get the final expression. Remark 4 (Rao-Blackwellization). Instead of using the unbiased estimator obtained by fixing a = b, we could marginalize over all a ∈ Bn,m(x0, b) explicitly. ...
-
[15]
He’s not really going to have done his whole job in this case, and he has always said that, but he’s not talking about him,
for some k ∈ si(b), then Proposition 4 gives pt|0(y | x0) pt|0(x | x0) = ρm+1 t (1 − ρt)n−m−1 ρm t (1 − ρt)n−m = ρt 1 − ρt , and the forward deletion rate from y to x is σt. Hence every missing original index contributes the same coefficient γind t = σt ρt 1 − ρt . CTMC F ramework for Insertion Language Models As in Corollary 1, we now use the same approx...
2024
-
[16]
smart line,
per share for the quarter of the year. second quarter 2009 results are currently reported. was 346. 4 million. from $ 15. 7 million in the second quarter of 2009 and the first quarter of 2008. for the second quarter ended june,. quarter as compared to the same period in 2008. million from $ 46. 6 million for the same period in 2007. total revenue of $ 50....
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.