When Design Rules Break: Benchmark Composition Determines Whether Label Informativeness Predicts GNN Aggregator Choice
Pith reviewed 2026-06-27 16:52 UTC · model grok-4.3
The pith
Benchmark composition determines whether label informativeness predicts GNN aggregator choice
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
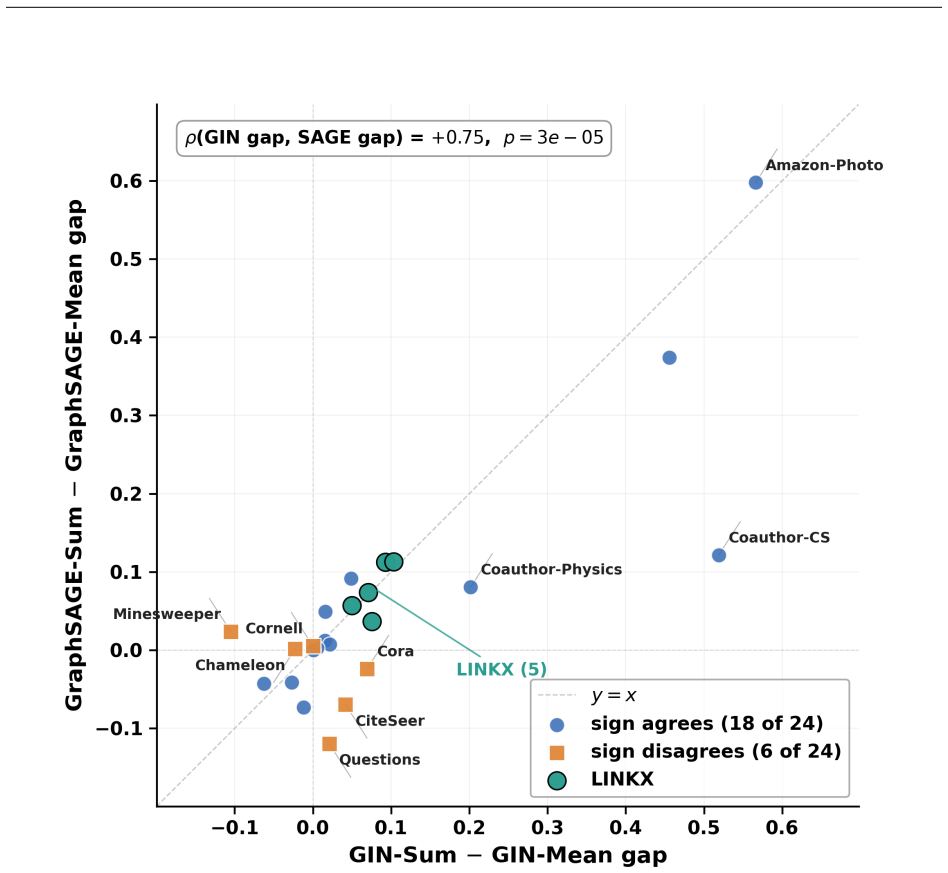
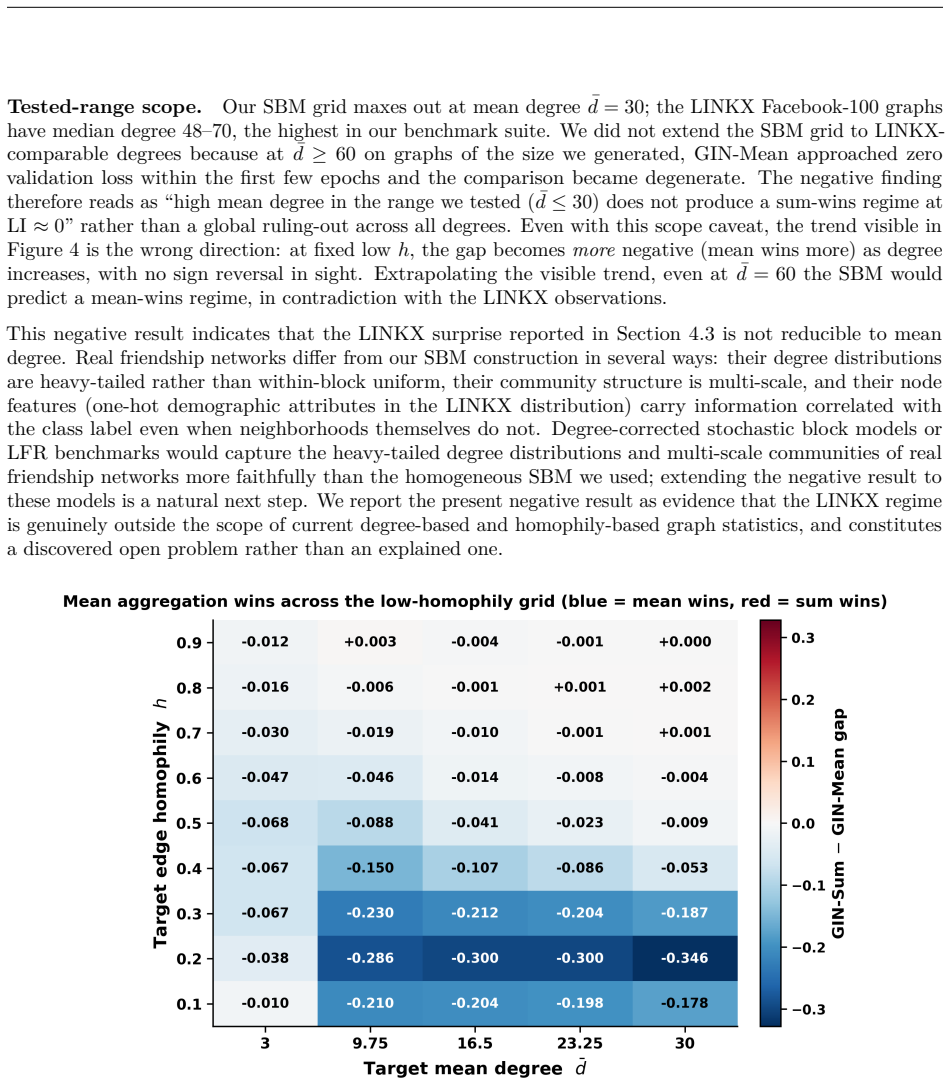
Label informativeness predicts the GIN-Sum versus GIN-Mean performance gap well on legacy benchmarks but degrades substantially when Facebook-100 graphs are included. In these dense friendship networks, near-zero label informativeness coexists with a strong preference for sum aggregation, producing gains of 7-10% and up to 13% under extended training. Stochastic block model ablations, including degree-corrected variants, fail to reproduce this behavior, indicating that mean degree alone does not explain the effect. Among several label-independent graph statistics, the spectral gap uniquely distinguishes these graphs from other low-informativeness datasets, with the effect localized to one-ho
What carries the argument
The performance gap between sum and mean aggregation (in GIN and related models) and its correlation with label informativeness, which holds or fails depending on the composition of the benchmark suite.
If this is right
- Edge homophily is only weakly predictive of the sum versus mean gap across the full set of datasets.
- The spectral gap distinguishes Facebook-100 graphs from other low-informativeness datasets, and the aggregator effect is localized to one-hop neighborhoods.
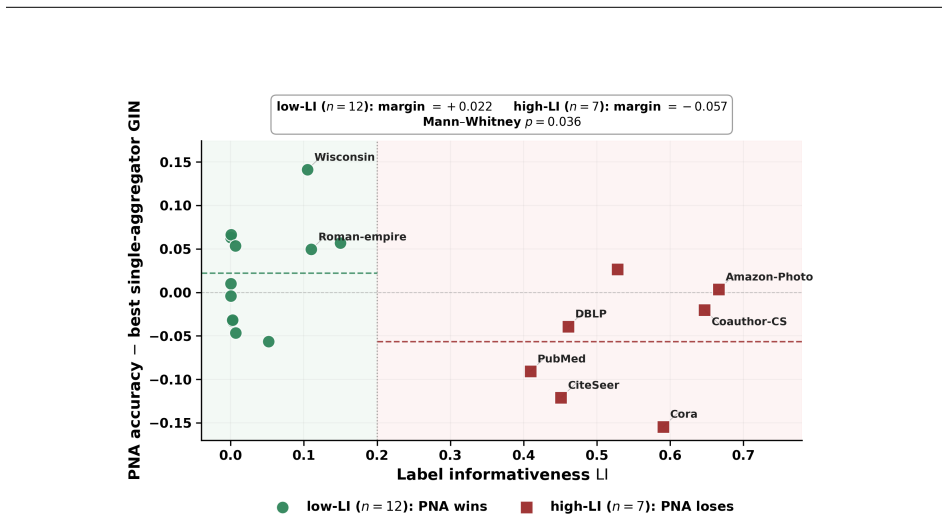
- PNA can underperform the best single-aggregator GIN on standard citation benchmarks.
- Training length interacts with aggregator choice, with extended training amplifying the sum advantage on Facebook-100 graphs.
Where Pith is reading between the lines
- Adaptive aggregation methods will need to target the specific properties of dense friendship networks rather than relying on label informativeness alone.
- Other real-world social graphs with similar spectral properties may exhibit the same sum preference even when label informativeness is low.
- GNN evaluation suites should deliberately include multiple benchmark regimes to expose when design rules fail to generalize.
- The interaction between training schedule and aggregator performance suggests that longer training could be used as a simple way to exploit sum aggregation in certain low-informativeness settings.
Load-bearing premise
Stochastic block models with degree correction adequately isolate basic statistics such as mean degree from whatever produces the Facebook-100 sum preference.
What would settle it
An experiment that tunes a degree-corrected stochastic block model to also match the spectral gap of Facebook-100 graphs and then checks whether the sum preference appears on the generated graphs.
Figures

read the original abstract
We examine whether graph neural network (GNN) design rules generalize across benchmark families by studying aggregator selection (sum, mean, max) on 24 node-classification datasets spanning citation, heterophilic, LINKX Facebook-100, co-purchase, and co-authorship graphs. Edge homophily is only weakly predictive of the GIN-Sum versus GIN-Mean performance gap. Label informativeness predicts this gap well on legacy benchmarks but degrades substantially when Facebook-100 graphs are included. In these dense friendship networks, near-zero label informativeness coexists with a strong preference for sum aggregation, producing gains of 7-10% and up to 13% under extended training. Stochastic block model ablations, including degree-corrected variants matching Facebook-100 degree scales, fail to reproduce this behavior, indicating that mean degree alone does not explain the effect. Among several label-independent graph statistics, the spectral gap uniquely distinguishes these graphs from other low-informativeness datasets, with the effect localized to one-hop neighborhoods and replicated across architectures. We further identify training regimes that interact with aggregator choice and show that PNA can underperform the best single-aggregator GIN on standard citation benchmarks. Our results suggest that benchmark composition, rather than numerical insufficiency, determines whether design rules appear to generalize, and that the Facebook-100 regime provides a concrete target for future adaptive aggregation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether GNN aggregator selection rules (sum vs. mean vs. max) generalize across benchmark families by evaluating node classification performance on 24 datasets spanning citation networks, heterophilic graphs, LINKX Facebook-100, co-purchase, and co-authorship graphs. It reports that edge homophily is only weakly predictive of the GIN-Sum vs. GIN-Mean gap, while label informativeness predicts the gap well on legacy benchmarks but loses predictive power when Facebook-100 graphs are added. In these dense friendship networks, near-zero label informativeness coexists with a strong sum preference yielding 7-10% gains (up to 13% under extended training). Degree-corrected SBM ablations matching Facebook-100 degree scales fail to reproduce the sum preference. Among label-independent statistics, spectral gap uniquely distinguishes the Facebook-100 regime, with the effect localized to one-hop neighborhoods and replicated across architectures. The paper concludes that benchmark composition, rather than numerical insufficiency, determines whether design rules appear to generalize.
Significance. If the results hold, the work provides concrete evidence that benchmark composition can determine the apparent validity of GNN design heuristics, identifying the Facebook-100 regime as a distinct target for adaptive aggregation methods. Strengths include the scale of the empirical evaluation (24 datasets), the use of SBM ablations to test structural explanations, comparisons of multiple label-independent statistics, and replication across architectures and training regimes. This supplies a falsifiable, regime-specific target rather than relying solely on existing benchmarks.
major comments (2)
- [SBM ablations] § on SBM ablations: The central claim that mean degree alone does not explain the Facebook-100 sum preference rests on the reported failure of degree-corrected SBMs (matching FB-100 degree scales) to reproduce the observed behavior. However, the paper identifies spectral gap as the unique distinguisher among label-independent statistics; without reporting whether the SBM variants reproduce the spectral-gap distribution (or other one-hop neighborhood statistics) of the real Facebook-100 graphs, the isolation of mean degree remains incomplete and the residual preference could still be attributable to unmatched structural properties.
- [Results on performance gaps] Results on performance gaps (Facebook-100 rows): The reported gains of 7-10% (up to 13% under extended training) for sum aggregation are presented as evidence of a distinct regime, but the manuscript provides no error bars, run-to-run standard deviations, or statistical significance tests. Given that the load-bearing claim concerns both the existence and magnitude of these gaps when label informativeness is near zero, the absence of these details leaves the reliability of the effect sizes and cross-dataset comparisons open to question.
minor comments (2)
- [Abstract and methods] The abstract states that the effect is 'localized to one-hop neighborhoods' but the main text should explicitly define how this localization was measured (e.g., via modified neighborhood statistics or ablation on k-hop subgraphs) to allow replication.
- [Tables/figures] Table or figure captions for the 24-dataset results should include the exact number of runs per entry and whether the same random seeds were used across aggregators.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of our empirical claims. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [SBM ablations] § on SBM ablations: The central claim that mean degree alone does not explain the Facebook-100 sum preference rests on the reported failure of degree-corrected SBMs (matching FB-100 degree scales) to reproduce the observed behavior. However, the paper identifies spectral gap as the unique distinguisher among label-independent statistics; without reporting whether the SBM variants reproduce the spectral-gap distribution (or other one-hop neighborhood statistics) of the real Facebook-100 graphs, the isolation of mean degree remains incomplete and the residual preference could still be attributable to unmatched structural properties.
Authors: We agree that verifying whether the degree-corrected SBMs match the spectral gap (and other one-hop statistics) of the Facebook-100 graphs is necessary to fully isolate mean degree as an explanation. In the revised manuscript, we will add a direct comparison of the spectral gap distributions between the real Facebook-100 graphs and the generated SBM variants, along with any other relevant neighborhood statistics. This will clarify whether the residual sum preference can be attributed to unmatched structural properties. revision: yes
-
Referee: [Results on performance gaps] Results on performance gaps (Facebook-100 rows): The reported gains of 7-10% (up to 13% under extended training) for sum aggregation are presented as evidence of a distinct regime, but the manuscript provides no error bars, run-to-run standard deviations, or statistical significance tests. Given that the load-bearing claim concerns both the existence and magnitude of these gaps when label informativeness is near zero, the absence of these details leaves the reliability of the effect sizes and cross-dataset comparisons open to question.
Authors: We acknowledge that reporting error bars, run-to-run standard deviations, and statistical significance tests is essential for substantiating the performance gaps on Facebook-100. In the revised version, we will include these details: mean accuracies with standard deviations over multiple random seeds, and paired statistical tests (e.g., t-tests) for the key sum vs. mean comparisons. This will support the reported gains of 7-10% (up to 13% under extended training) with appropriate measures of reliability. revision: yes
Circularity Check
No circularity: purely empirical benchmark comparison with no derivations or fitted reductions
full rationale
The paper conducts an empirical study comparing GNN aggregator performance (sum/mean/max) across 24 public datasets and SBM variants. All central claims rest on observed accuracy differences, label informativeness correlations, and failure of degree-matched SBMs to reproduce Facebook-100 behavior. No equations, parameter fits, or derivations are present that could reduce a prediction to its input by construction. No self-citations are invoked as load-bearing uniqueness theorems. The work is self-contained against external benchmarks and does not rename known results or smuggle ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard GNN training assumptions such as consistent hyperparameter choices across datasets
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[2]
International Conference on Learning Representations (ICLR) , year=
Graph Attention Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Inductive Representation Learning on Large Graphs , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[4]
International Conference on Learning Representations (ICLR) , year=
How Powerful are Graph Neural Networks? , author=. International Conference on Learning Representations (ICLR) , year=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Principal Neighbourhood Aggregation for Graph Nets , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , year=
When Do Graph Neural Networks Help with Node Classification? Investigating the Impact of Homophily Principle on Node Distinguishability , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Beyond Homophily in Graph Neural Networks: Current Limitations and Effective Designs , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[8]
International Conference on Learning Representations (ICLR) , year=
Is Homophily a Necessity for Graph Neural Networks? , author=. International Conference on Learning Representations (ICLR) , year=
-
[9]
International Conference on Learning Representations (ICLR) , year=
A Critical Look at the Evaluation of GNNs Under Heterophily: Are We Really Making Progress? , author=. International Conference on Learning Representations (ICLR) , year=
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Classic GNNs are Strong Baselines: Reassessing GNNs for Node Classification , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[12]
International Conference on Machine Learning (ICML) , year=
Revisiting Semi-Supervised Learning with Graph Embeddings , author=. International Conference on Machine Learning (ICML) , year=
-
[13]
International Conference on Learning Representations (ICLR) , year=
Geom-GCN: Geometric Graph Convolutional Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
KDD , year=
Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks , author=. KDD , year=
-
[15]
Relational Representation Learning Workshop, NeurIPS , year=
Pitfalls of Graph Neural Network Evaluation , author=. Relational Representation Learning Workshop, NeurIPS , year=
-
[16]
KDD , year=
Social Influence Analysis in Large-scale Networks , author=. KDD , year=
-
[17]
Simplifying approach to node classification in Graph Neural Networks , journal =
Sunil Kumar Maurya and Xin Liu and Tsuyoshi Murata , keywords =. Simplifying approach to node classification in Graph Neural Networks , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.jocs.2022.101695 , url =
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Beyond fixed depth: Adaptive graph neural networks for node classification under varying homophily , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Revisiting Neighborhood Aggregation in Graph Neural Networks for Node Classification using Statistical Signal Processing , year=
Ghogho, Mounir , booktitle=. Revisiting Neighborhood Aggregation in Graph Neural Networks for Node Classification using Statistical Signal Processing , year=
-
[20]
Adaptive Universal Generalized
Chien, Eli and Peng, Jianhao and Li, Pan and Milenkovic, Olgica , booktitle =. Adaptive Universal Generalized
-
[21]
Abu-El-Haija, Sami and Perozzi, Bryan and Kapoor, Amol and Alipourfard, Nazanin and Lerman, Kristina and Harutyunyan, Hrayr and Ver Steeg, Greg and Galstyan, Aram , booktitle =
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Revisiting Heterophily For Graph Neural Networks , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Open Graph Benchmark: Datasets for Machine Learning on Graphs , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.