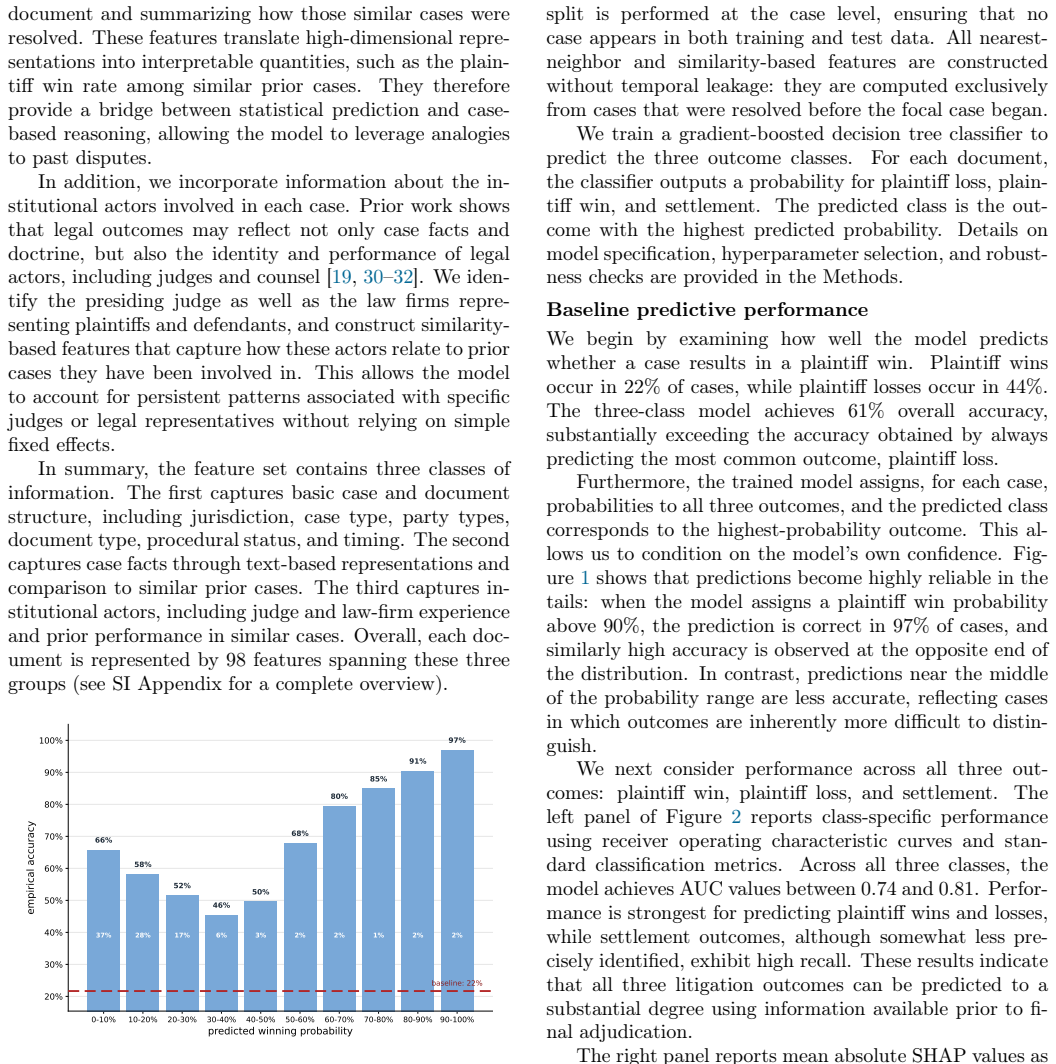
0
Python package splits network reduction into partition then aggregate steps
NPAP: Network Partitioning and Aggregation Package for Python
NPAP lets users plug in custom strategies for each stage, making graph simplification modular and easier to adapt across domains.
 full image
full image
abstract click to expand
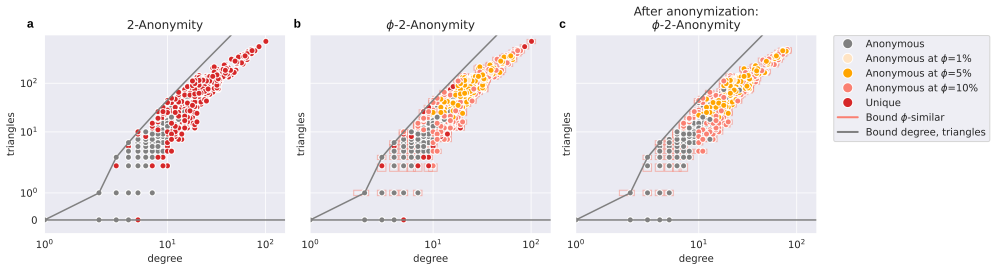
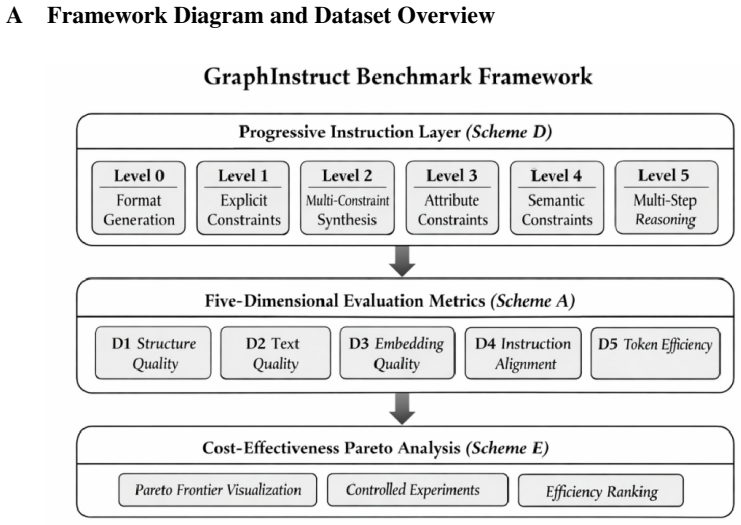
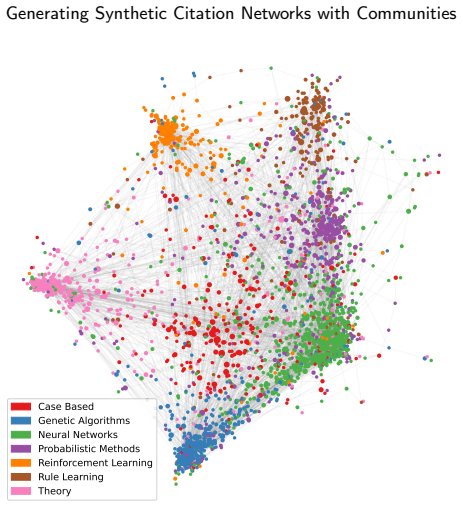
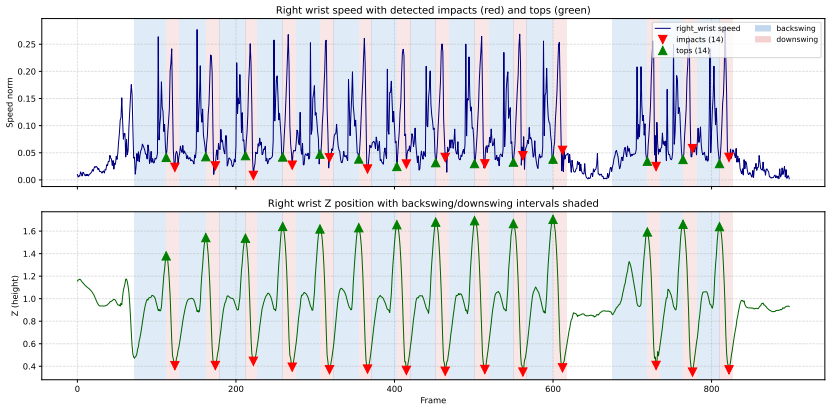
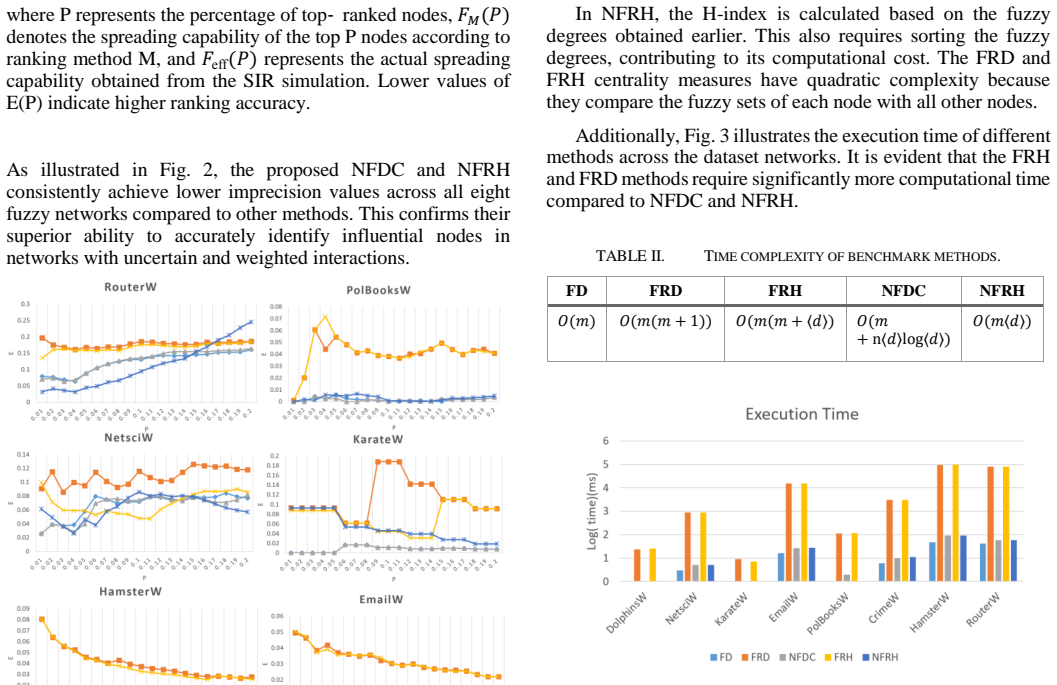
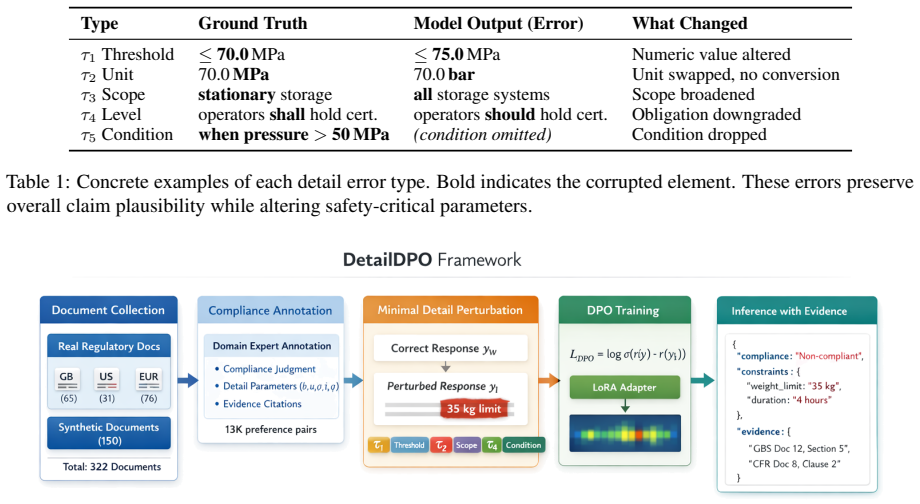
NPAP (Network Partitioning and Aggregation Package) is an open-source Python library for reducing the spatial complexity of network graphs. Built on NetworkX, it provides an accessible standalone package designed to be readily integrated with other software and frameworks. Instead of treating the spatial reduction process as a single action, NPAP explicitly splits it into two distinct steps: partitioning, which assigns vertices (nodes) to groups (clusters), and aggregation, which reduces the network based on a given assignment. NPAP's strategy pattern architecture allows users to employ and register custom partitioning and aggregation strategies seamlessly without modifying the core code. Currently, NPAP provides 13 different partitioning strategies and two pre-defined aggregation profiles. Although initially developed with a focus on power systems, its architecture is general-purpose and applicable to any network graph.