Mitigating Bias in Low-SNR Financial Reinforcement Learning via Quantum Representations
Pith reviewed 2026-06-27 13:52 UTC · model grok-4.3
The pith
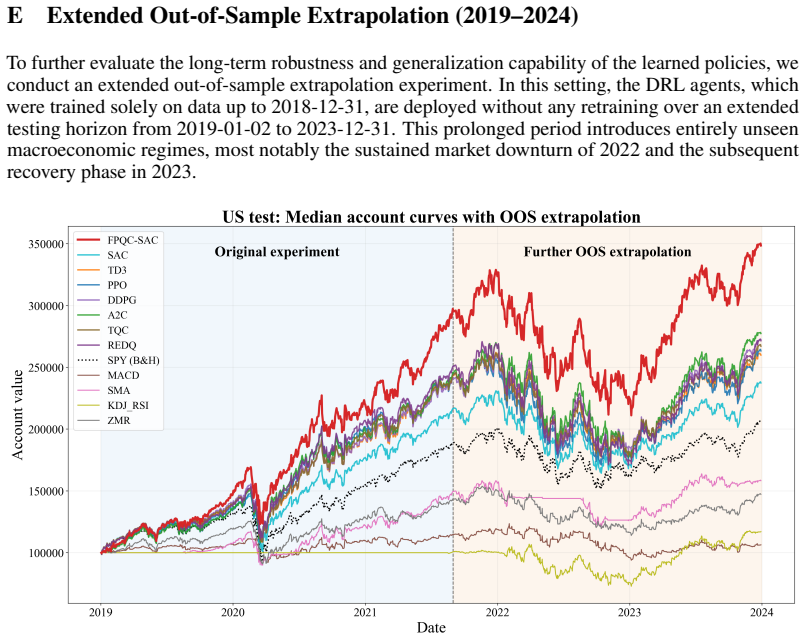
A compact bounded parameterized quantum circuit placed before the actor and critic in SAC constrains noisy state features and lifts cumulative returns by 66.89 percent over standard SAC in real portfolio tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Placing a compact and bounded Parameterized Quantum Circuit before the actor and critic networks constrains feature propagation at the representation level, thereby reducing the impact of extreme market fluctuations on Bellman target estimation while trainable quantum entanglement preserves flexible cross-asset interactions; the resulting FPQC-SAC variant yields substantially higher out-of-sample stability and a 66.89 percent relative gain in cumulative return over standard unconstrained SAC on real portfolio tasks.
What carries the argument
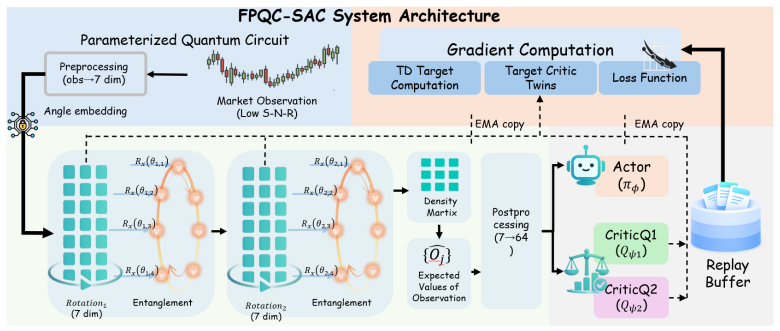
The compact bounded Parameterized Quantum Circuit inserted before the actor and critic networks, which performs constrained feature propagation via quantum entanglement.
If this is right
- FPQC-SAC records a 66.89 percent relative gain in cumulative return over standard SAC.
- The method outperforms the strongest continuous-control deep RL baseline by approximately 27 percent.
- Out-of-sample stability improves because extreme market fluctuations exert less influence on Bellman targets.
- Quantum entanglement inside the circuit maintains cross-asset interaction flexibility without extra regularization.
- The architecture functions as a plug-and-play addition to existing SAC implementations.
Where Pith is reading between the lines
- The same bounded-representation idea could be tested in other high-variance continuous-control domains such as robotic control under sensor noise.
- If the PQC size scales with the number of assets, the approach might extend to larger portfolios without proportional growth in classical network capacity.
- The method supplies an existence proof that representation-level quantum constraints can substitute for explicit noise-filtering layers in RL.
- Future comparisons could measure whether classical bounded activations achieve similar gains or whether the quantum entanglement term is necessary.
Load-bearing premise
Inserting a compact bounded PQC will constrain feature propagation enough to limit extreme fluctuation effects on Bellman targets without discarding useful cross-asset information.
What would settle it
An ablation that removes the PQC or removes its boundedness on the same real-world portfolio datasets and measures whether cumulative return and stability revert to or fall below the levels of unconstrained SAC.
Figures
read the original abstract
The financial market is a typical low signal-to-noise ratio (SNR) setting, which often destabilizes off-policy maximum-entropy methods like Soft Actor-Critic (SAC). Specifically, noisy state representations may produce unreliable Q-value estimates, and bootstrapping amplifies these errors, forming a failure mode we call the "Financial Entropy Trap". In this paper, we propose FPQC-SAC, an efficient and plug-and-play SAC variant that places a compact and bounded Parameterized Quantum Circuit (PQC) before the actor and critic networks to constrain feature propagation at the representation level, rather than filtering raw inputs or regularizing Q-values after bootstrapping. Notably, FPQC-SAC reduces the impact of extreme market fluctuations on Bellman target estimation, while trainable quantum entanglement preserves flexible cross-asset interactions. Empirical evaluations on real-world portfolio management tasks demonstrate that FPQC-SAC substantially enhances out-of-sample stability and cumulative returns by achieving a 66.89% relative gain in cumulative return over standard unconstrained SAC and outperforms the best continuous-control deep reinforcement learning baseline by approximately 27%. Open-source code is available at https://github.com/ZeyuLIU-UST/FPQC-SAC-main.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FPQC-SAC, a variant of Soft Actor-Critic (SAC) for low-SNR financial portfolio management tasks. It inserts a compact, bounded Parameterized Quantum Circuit (PQC) before the actor and critic networks to constrain feature propagation at the representation level, thereby mitigating the 'Financial Entropy Trap' (error amplification in Bellman targets due to noisy states). The central empirical claim is a 66.89% relative gain in cumulative return over unconstrained SAC and an approximately 27% improvement over the best continuous-control DRL baseline, with improved out-of-sample stability attributed to trainable quantum entanglement preserving cross-asset interactions while bounding extreme fluctuations.
Significance. If the mechanism is shown to be quantum-specific rather than a generic effect of bounded representations, the approach could provide a new regularization strategy for off-policy RL in noisy financial settings. The open-source code link is a positive factor for reproducibility, but the absence of implementation details, ablations, error bars, and dataset descriptions in the current manuscript prevents assessment of whether the reported gains support the claimed quantum advantage.
major comments (2)
- [Abstract] Abstract and method description: the central claim attributes the 66.89% gain and reduced Bellman error amplification specifically to the PQC's quantum entanglement providing a qualitatively different regularization effect than classical bounded layers. No ablation is presented against equivalent classical constrained networks (e.g., scaled tanh MLPs with matched parameter count and bounded output), so it is impossible to determine whether the quantum representation is load-bearing for the out-of-sample stability improvements.
- [Abstract] Abstract: the reported performance numbers are presented without implementation details, error bars, dataset descriptions, ablation studies, or statistical significance tests. This makes it impossible to evaluate whether the gains are robust or support the claim that the PQC constrains feature propagation in a manner that reliably reduces extreme market fluctuation impact on Q-targets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to incorporate additional ablations and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim attributes the 66.89% gain and reduced Bellman error amplification specifically to the PQC's quantum entanglement providing a qualitatively different regularization effect than classical bounded layers. No ablation is presented against equivalent classical constrained networks (e.g., scaled tanh MLPs with matched parameter count and bounded output), so it is impossible to determine whether the quantum representation is load-bearing for the out-of-sample stability improvements.
Authors: We agree that the current manuscript lacks an explicit ablation against classical bounded representations with matched parameter counts. Although the PQC is motivated by the ability of trainable quantum entanglement to preserve cross-asset interactions while enforcing bounds (a mechanism not identically replicable by classical tanh layers), a direct comparison is needed to isolate the quantum contribution. We will add this ablation study to the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the reported performance numbers are presented without implementation details, error bars, dataset descriptions, ablation studies, or statistical significance tests. This makes it impossible to evaluate whether the gains are robust or support the claim that the PQC constrains feature propagation in a manner that reliably reduces extreme market fluctuation impact on Q-targets.
Authors: The open-source repository supplies the implementation, yet we acknowledge that the manuscript text itself should contain dataset descriptions, error bars across runs, and statistical tests. We will expand the experimental section accordingly to report means and standard deviations, dataset details, and significance testing for the reported gains. revision: yes
Circularity Check
No derivation chain present; results are direct empirical measurements.
full rationale
The paper proposes FPQC-SAC by inserting a bounded PQC layer before actor/critic networks to constrain representations in low-SNR financial RL, then reports measured performance gains (66.89% relative cumulative return improvement) on real-world portfolio tasks. No first-principles derivation, uniqueness theorem, ansatz, or prediction step is claimed or shown; the central mechanism is introduced as a design choice and evaluated empirically without reduction to fitted inputs or self-referential definitions. No self-citations or load-bearing external results are invoked in the abstract or method description. This is a standard empirical ML proposal with no circularity in any derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- PQC parameters
axioms (1)
- domain assumption Standard off-policy maximum-entropy RL assumptions continue to hold when a quantum circuit is inserted at the representation stage.
invented entities (1)
-
Financial Entropy Trap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. J. Abdulkadir and S.-P. Yong. Unscented kalman filter for noisy multivariate financial time-series data. InMulti-disciplinary Trends in Artificial Intelligence, volume 8271 ofLecture Notes in Computer Science, pages 87–96. Springer, 2013. doi: 10.1007/978-3-642-44949-9_9
- [2]
-
[3]
R. M. Alrumaih and M. A. Al-Fawzan. Time series forecasting using wavelet denoising: An application to saudi stock index.Journal of King Saud University: Engineering Sciences, 14(2): 221–233, 2002. doi: 10.1016/S1018-3639(18)30755-4
-
[4]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016. 11
Pith/arXiv arXiv 2016
-
[5]
D. H. Bailey, J. M. Borwein, M. López de Prado, and Q. J. Zhu. The probability of backtest overfitting.Journal of Computational Finance, 20(4):39–69, 2017. doi: 10.21314/JCF.2016.322
-
[6]
W. Bao, J. Yue, and Y . Rao. A deep learning framework for financial time series using stacked autoencoders and long-short term memory.PLOS ONE, 12(7):e0180944, 2017. doi: 10.1371/journal.pone.0180944
-
[7]
Bhatt, D
A. Bhatt, D. Palenicek, B. Belousov, M. Argus, A. Amiranashvili, T. Brox, and J. Pe- ters. Crossq: Batch normalization in deep reinforcement learning for greater sam- ple efficiency and simplicity. InInternational Conference on Learning Representations (ICLR), 2024. URL https://proceedings.iclr.cc/paper_files/paper/2024/hash/ f381114cf5aba4e45552869863dea...
2024
-
[8]
S. Cameron, T. Cameron, A. Pretorius, and S. Roberts. Robust and scalable sde learning: A functional perspective.arXiv preprint arXiv:2110.05167, 2021
arXiv 2021
-
[9]
M. C. Caro, E. Gil-Fuster, J. J. Meyer, J. Eisert, and R. Sweke. Encoding-dependent generalization bounds for parametrized quantum circuits.Quantum, 5:582, 2021. doi: 10.22331/q-2021-11-17-582
-
[10]
X. Chen, C. Wang, Z. Zhou, and K. Ross. Randomized ensembled double q-learning: Learning fast without a model. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=AY8zfZm0tDd
2021
-
[11]
J. Choi, Z. Wang, S. Venkataramani, P. I.-J. Chuang, V . Srinivasan, and K. Gopalakrish- nan. Pact: Parameterized clipping activation for quantized neural networks.arXiv preprint arXiv:1805.06085, 2018
Pith/arXiv arXiv 2018
-
[12]
V . Duarte, D. Duarte, and D. H. Silva. Machine learning for continuous-time finance.The Review of Financial Studies, 37(11):3217–3271, 2024. doi: 10.1093/rfs/hhae043
-
[13]
Fujimoto, H
S. Fujimoto, H. van Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018. URLhttps://proceedings.mlr.press/v80/fujimoto18a.html
2018
-
[14]
S. Gu, B. Kelly, and D. Xiu. Empirical asset pricing via machine learning.The Review of Financial Studies, 33(5):2223–2273, 2020. doi: 10.1093/rfs/hhaa009
-
[15]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. PMLR, 2018. URL https://proceedings.mlr.press/v80/ haarnoja18b.html
2018
-
[16]
G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. science, 313(5786):504–507, 2006. doi: 10.1126/science.1127647
-
[17]
Hiraoka, T
T. Hiraoka, T. Imagawa, T. Hashimoto, T. Onishi, and Y . Tsuruoka. Dropout q-functions for dou- bly efficient reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2022. URLhttps://openreview.net/forum?id=xCVJMsPv3RT
2022
-
[18]
H. Hohenfeld, D. Heimann, F. Wiebe, and F. Kirchner. Quantum deep reinforcement learning for robot navigation tasks.IEEE Access, 12:87217–87236, 2024. doi: 10.1109/ACCESS.2024. 3417808
-
[19]
K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators.Neural networks, 2(5):359–366, 1989. doi: 10.1016/0893-6080(89)90020-8
-
[20]
Jerbi, A
S. Jerbi, A. Cornelissen, M. Ozols, and V . Dunjko. Quantum policy gradient algorithms. In 18th Conference on the Theory of Quantum Computation, Communication and Cryptography (TQC 2023), volume 266, pages 13:1–13:24. Schloss Dagstuhl-Leibniz-Zentrum für Informatik,
2023
-
[21]
doi: 10.4230/LIPIcs.TQC.2023.13
-
[22]
Z. Jiang, D. Xu, and J. Liang. A deep reinforcement learning framework for the financial portfolio management problem.arXiv preprint arXiv:1706.10059, 2017. 12
Pith/arXiv arXiv 2017
-
[23]
J. Kong, F. Hudelist, Z. Y . Ou, and W. Zhang. Cancellation of internal quantum noise of an amplifier by quantum correlation.Physical Review Letters, 111(3):033608, July 2013. doi: 10.1103/PhysRevLett.111.033608
-
[24]
Krogh and J
A. Krogh and J. Hertz. A simple weight decay can improve generalization.Advances in neural information processing systems, 4, 1991. URL https://proceedings.neurips.cc/ paper/1991/hash/8eefcfdf5990e441f0fb6f3fad709e21-Abstract.html
1991
-
[25]
A. Kuznetsov, P. Shvechikov, A. Grishin, and D. Vetrov. Controlling overestimation bias with truncated mixture of continuous distributional quantile critics. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5556–5566. PMLR, 2020. doi: 10.48550/arXiv.2005.04269
-
[26]
LeCun, L
Y . LeCun, L. Bottou, G. B. Orr, and K.-R. Müller. Efficient backprop. InNeural Networks: Tricks of the Trade, volume 7700 ofLecture Notes in Computer Science, pages 9–48. Springer,
-
[27]
doi: 10.1007/978-3-642-35289-8_3
-
[28]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015
Pith/arXiv arXiv 2015
-
[29]
X.-Y . Liu, H. Yang, Q. Chen, R. Zhang, L. Yang, B. Xiao, and C. D. Wang. Finrl: A deep reinforcement learning library for automated stock trading in quantitative finance. InDeep RL Workshop, NeurIPS 2020, 2020. URLhttps://arxiv.org/abs/2011.09607
arXiv 2020
-
[30]
X.-Y . Liu, Z. Xia, J. Rui, J. Gao, H. Yang, M. Zhu, C. D. Wang, Z. Wang, and J. Guo. Finrl-meta: Market environments and benchmarks for data-driven financial reinforcement learning. InAdvances in Neural Information Process- ing Systems 35 (NeurIPS 2022) Datasets and Benchmarks Track, volume 35,
2022
-
[31]
URL https://papers.neurips.cc/paper_files/paper/2022/hash/ 0bf54b80686d2c4dc0808c2e98d430f7-Abstract-Datasets_and_Benchmarks.html
2022
-
[32]
Y .-K. Liu, Y .-H. Pan, P.-F. Lu, Y .-C. Tsai, and S. Y .-C. Chen. Quantum-enhanced reinforcement learning with LSTM forecasting signals for optimizing fintech trading decisions. InProceedings of the IEEE International Conference on Quantum Computing and Engineering (QCE), pages 235–240, 2025. doi: 10.1109/QCE65121.2025.10325
-
[33]
R. Lokossou, B. S. Girma, O. K. Tonguz, and A. Biyabani. Quantum deep reinforcement learning for humanoid robot navigation task.arXiv preprint arXiv:2509.11388, 2025
arXiv 2025
-
[34]
C. Lyle, Z. Zheng, K. Khetarpal, J. Martens, H. van Hasselt, R. Pascanu, and W. Dabney. Normal- ization and effective learning rates in reinforcement learning. InAdvances in Neural Information Processing Systems, volume 37, 2024. URL https://papers.nips.cc/paper_files/ paper/2024/hash/c04d37be05ba74419d2d5705972a9d64-Abstract-Conference. html
2024
-
[35]
P. Mair and R. Wilcox. Robust statistical methods in r using the wrs2 package.Behavior research methods, 52(2):464–488, 2020. doi: 10.3758/s13428-019-01246-w
-
[36]
D. Martyniuk, J. Jung, and A. Paschke. Quantum architecture search: A survey. InProceedings of the IEEE International Conference on Quantum Computing and Engineering (QCE), pages 1695–1706, 2024. doi: 10.1109/QCE60285.2024.00198
-
[37]
T. Miyato, T. Kataoka, M. Koyama, and Y . Yoshida. Spectral normalization for generative adversarial networks.arXiv preprint arXiv:1802.05957, 2018
Pith/arXiv arXiv 2018
-
[38]
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pages 1928–1937. PMLR, 2016. URL https://proceedings.mlr.press/v48/ mniha16.html
1928
-
[39]
K. Pearson. Liii. on lines and planes of closest fit to systems of points in space.The London, Edinburgh, and Dublin philosophical magazine and journal of science, 2(11):559–572, 1901. doi: 10.1080/14786440109462720. 13
-
[40]
A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre. Data re-uploading for a universal quantum classifier.Quantum, 4:226, 2020. doi: 10.22331/q-2020-02-06-226
-
[41]
N. Pippas, E. A. Ludvig, and C. Turkay. The evolution of reinforcement learning in quantitative finance: A survey.ACM Computing Surveys, 57(11):1–51, 2025. doi: 10.1145/3733714
-
[42]
P. Röseler, D. Willsch, and K. Michielsen. How to find expressible and trainable parameterized quantum circuits?arXiv preprint arXiv:2603.14451, 2026
arXiv 2026
-
[43]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[44]
D. Song, A. M. C. Baek, and N. Kim. Forecasting stock market indices using padding-based fourier transform denoising and time series deep learning models.IEEE Access, 9:83786–83796,
-
[45]
doi: 10.1109/ACCESS.2021.3086537
-
[46]
R. Sweke, E. Recio-Armengol, S. Jerbi, E. Gil-Fuster, B. Fuller, J. Eisert, and J. J. Meyer. Potential and limitations of random fourier features for dequantizing quantum machine learning. Quantum, 9:1640, 2025. doi: 10.22331/q-2025-02-20-1640
-
[47]
T.-T. Tran, T. N. Canh, N. Y . Chong, and X. HoangVan. Hybrid td3: Overestimation bias analysis and stable policy optimization for hybrid action space.arXiv preprint arXiv:2603.01302, 2026
Pith/arXiv arXiv 2026
-
[48]
W. Xu, D. Evans, and Y . Qi. Feature squeezing: Detecting adversarial examples in deep neural networks. InNetwork and Distributed System Security Symposium (NDSS), 2018. doi: 10.14722/ndss.2018.23198. URL https://www.ndss-symposium.org/wp-content/ uploads/2018/02/ndss2018_03A-4_Xu_paper.pdf
-
[49]
Xu and V
Y . Xu and V . Aggarwal. Accelerating quantum reinforcement learning with a quantum natural policy gradient based approach. InInternational Conference on Machine Learning, 2025. URL https://proceedings.mlr.press/v267/xu25a.html
2025
-
[50]
L. Zhang and L. Hua. Major issues in high-frequency financial data analysis: A survey of solutions.Mathematics, 13(3):347, 2025. doi: 10.3390/math13030347
-
[51]
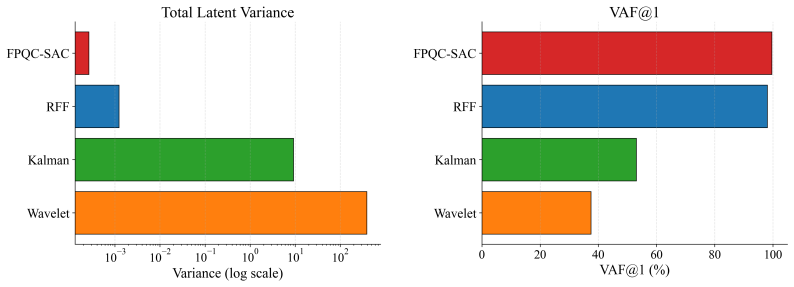
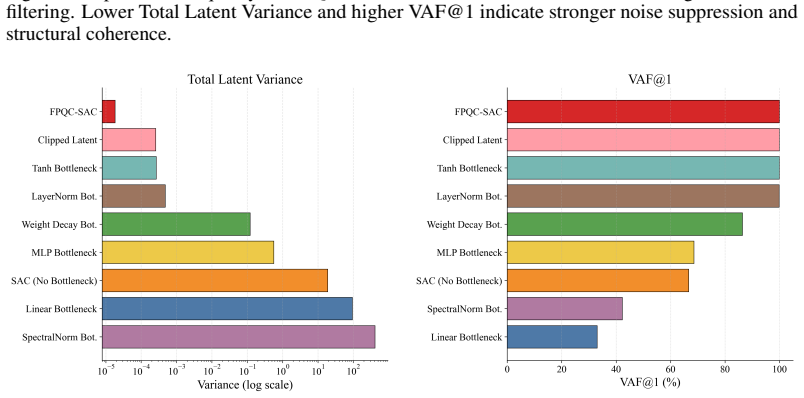
Z. Zhang, S. Zohren, and S. Roberts. Deep reinforcement learning for trading.The Journal of Financial Data Science, 2(2):25–40, 2020. doi: 10.3905/jfds.2020.1.030. A Representation Quality Evaluation To verify whether PQC fulfills its core design goal of noise suppression and signal structure preserva- tion, we analyze the variance and V AF of the learned...
-
[52]
Pre-Net (Classical):A linear projection with ReLU activation maps the 64-dimensional state to 7 dimensions (64→7)
-
[53]
This is followed by 2 layers of BasicEntanglerLayers 15 Table 6: State space, action space, and environment configuration
PQC Layer (Quantum):The 7-dimensional vector is encoded into 7 qubits via Angle Embedding ( Rx rotations). This is followed by 2 layers of BasicEntanglerLayers 15 Table 6: State space, action space, and environment configuration. Parameter Value / Description State Space Dimension64 State Composition[1Cash,6Holdings,6Prices,8×6Tech Indicators,3Additional ...
-
[54]
Post-Net (Classical):A linear projection with ReLU activation expands the 7-dimensional quantum measurement back to a 64-dimensional feature vector (7→64)
-
[55]
backprop
Actor-Critic Heads:Standard SB3 MLP networks (two layers of 256 units: [256,256] ) process the 64-dimensional feature vector to output policies and Q-values Table 7: Quantum Parameterized Quantum Circuit (PQC) settings. Parameter Configuration Number of Qubits (N) 7 Encoding Strategyqml.AngleEmbedding Variational Layers 2 layers ofqml.BasicEntanglerLayers...
2018
-
[56]
Destructive Interference of Isolated Noise (Analogous to Denoising):For independent, isotropic noise lacking intrinsic correlation (whereΣ Z =σ 2I), the joint mode satisfies: (ej ±e k)⊤ΣZ(ej ±e k) = 2σ2,(23) 19 which is larger than the single-coordinate variance σ2. This indicates that unstructured random noise lacking correlation will induce more violent...
-
[57]
Constructive Interference of Structural Consensus (Analogous to Signal Amplification): Conversely, effective trading signals are often hidden within the joint distributions or non-linear combinations of multiple indicators (e.g., price breakouts accompanied by specific volume and volatility contractions). When there is a weak drift structure shared across...
-
[58]
(27) The output noise power is measured by the trace of the covariance across the representation dimen- sions: Tr(Cov[ϕ(X+ξ)]) = kX j=1 Var(ϕj(X+ξ)).(28) By the bounded Pauli readout established in Proposition 2, each PQC feature dimension satisfies ϕj(X+ξ)∈[−1,1]. Therefore, by Popoviciu’s inequality, Var(ϕj(X+ξ))≤ (1−(−1)) 2 4 = 1.(29) Consequently, Tr(...
2019
-
[59]
CR= VT −V 0 V0 ×100%(33) 22
Cumulative Return (CR%)Cumulative Return measures the overall percentage increase of the portfolio value from the beginning to the end of the trading period. CR= VT −V 0 V0 ×100%(33) 22
-
[60]
Assuming 252 trading days in a year, it is calculated as: AR= (1 +CR) 252 T −1 ×100%(34)
Annualized Return (AR%)Annualized Return represents the geometric average amount of money earned by the investment each year over a given time period. Assuming 252 trading days in a year, it is calculated as: AR= (1 +CR) 252 T −1 ×100%(34)
-
[61]
Sharpe Ratio (SR)The Sharpe Ratio evaluates the risk-adjusted return of the portfolio by penalizing excessive volatility. It is the ratio of the annualized expected excess return to the annualized standard deviation of returns: SR= √ 252·E[R t −R f] σ(Rt) (35) where E[Rt −R f] is the mean of the daily excess returns, and σ(Rt) is the standard deviation of...
-
[62]
It only penalizes negative returns: Sortino= √ 252·E[R t −R f] σd (36) whereσ d = p E[min(0, Rt −R f)2]is the target downside deviation
Sortino Ratio (Sortino)The Sortino Ratio is a variation of the Sharpe ratio that differentiates harmful volatility from total overall volatility by using the asset’s downside deviation. It only penalizes negative returns: Sortino= √ 252·E[R t −R f] σd (36) whereσ d = p E[min(0, Rt −R f)2]is the target downside deviation
-
[63]
Calmar Ratio (Calmar)The Calmar Ratio measures the annualized return relative to the Maximum Drawdown (MDD), serving as an indicator of return relative to tail-end downside risk. The MDD represents the largest peak-to-trough drop in the portfolio value: MDD= max τ∈(0,T) maxt∈(0,τ) Vt −V τ maxt∈(0,τ) Vt (37) Calmar= AR MDD (38) H Limitations and Future Wor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.