Act on What You See: Unlocking Safe Social Navigation in Vision-Language-Action Models
Pith reviewed 2026-06-27 12:50 UTC · model grok-4.3
The pith
Pretrained vision-language-action models already encode pedestrian distinctions and collision forecasts internally, yet standard behavior cloning does not convert those signals into safe actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretrained VLA models already encode pedestrian-object distinctions and future collision signals in their internal representations, but behavior cloning fails to translate these signals into socially appropriate actions; SALSA bridges the intermediate-layer social features to the action head and supplies automatically generated future-risk supervision, enabling the policy to act on the representations it already possesses.
What carries the argument
SALSA, a two-stage annotation-free post-training framework that first performs social behavioral alignment by bridging intermediate-layer features on counterfactual human-object scene pairs and then performs temporal safety alignment by training on automatically generated future-risk supervision.
If this is right
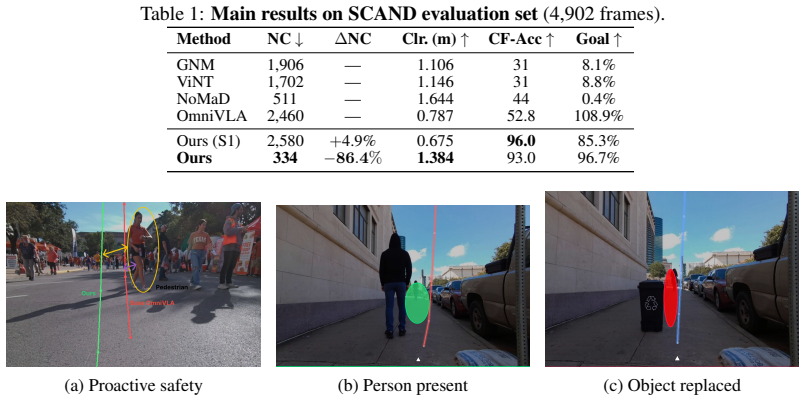
- Near-collision rate on SCAND and real-world tests falls by 86.4 percent.
- Accuracy on social counterfactual questions rises from 53 percent to 93 percent.
- Safer social navigation becomes possible by aligning existing latent representations with action outputs rather than by collecting new demonstration data.
- The same pretrained model can be adapted for safer behavior without full retraining from scratch.
Where Pith is reading between the lines
- The same two-stage alignment pattern could be tested on other embodied models that show latent task knowledge not expressed in their initial outputs.
- Deployment results suggest the method may reduce the amount of manual safety tuning required when moving VLA policies from simulation to physical environments.
- If the internal signals prove consistent across different VLA architectures, the approach could serve as a lightweight adapter rather than a full retraining pipeline.
Load-bearing premise
Automatically generated counterfactual human-object pairs and future-risk labels can be produced without introducing new biases that would block transfer to unseen real-world scenes.
What would settle it
Measure whether a VLA model without the SALSA stages already produces distinguishable internal activations for pedestrian versus object scenes, or test whether the reported accuracy gains vanish when the counterfactual pairs are replaced by random scene edits.
Figures


read the original abstract
Safe social navigation requires robots to distinguish people from ordinary obstacles and to react before danger becomes imminent. We show that pretrained Vision-Language-Action (VLA) models already encode pedestrian-object distinctions and future collision signals in their internal representations, but behavior cloning fails to translate these signals into socially appropriate actions. To address this mismatch, we propose SALSA, a two-stage annotation-free post-training framework: (1) social behavioral alignment bridges intermediate-layer social features to the action head and trains on counterfactual human-object scene pairs to break visual saliency shortcuts; (2) temporal safety alignment provides automatically generated future-risk supervision to enable anticipatory collision avoidance. On SCAND and real-world deployment, SALSA reduces near-collisions by 86.4% and improves social counterfactual accuracy from 53% to 93%, demonstrating that safer social navigation can be achieved by teaching VLA policies to act on representations they already possess. These results show that pretrained VLA policies can be adapted for safer social navigation by better aligning their latent representations with action generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that pretrained Vision-Language-Action (VLA) models already encode pedestrian-object distinctions and future collision signals in their internal representations, yet standard behavior cloning fails to translate these signals into socially appropriate actions. It introduces SALSA, a two-stage annotation-free post-training framework: (1) social behavioral alignment that bridges intermediate-layer social features to the action head using counterfactual human-object scene pairs to break visual saliency shortcuts, and (2) temporal safety alignment that supplies automatically generated future-risk supervision for anticipatory collision avoidance. On the SCAND benchmark and real-world deployment, SALSA is reported to reduce near-collisions by 86.4% and raise social counterfactual accuracy from 53% to 93%.
Significance. If the empirical results and attribution to existing representations hold after verification, the work would be significant for robotics because it shows that substantial safety gains in social navigation are achievable via lightweight post-training of existing VLA models without manual annotations. The annotation-free framing, if substantiated, addresses a practical bottleneck in scaling robot deployment. The approach of explicitly bridging intermediate features rather than end-to-end fine-tuning is a concrete methodological contribution that could generalize to other VLA safety tasks.
major comments (3)
- [Abstract] Abstract: The quantitative claims (86.4% near-collision reduction and accuracy improvement from 53% to 93%) are presented without any reference to baseline methods, number of trials, statistical significance testing, or controls for confounds such as dataset shifts between training and test scenes. These omissions are load-bearing because the central claim attributes the gains specifically to SALSA unlocking preexisting representations rather than to artifacts of the evaluation protocol.
- [Method] Method section (counterfactual generation and future-risk supervision): The two-stage procedure depends entirely on automatically generated counterfactual human-object pairs and future-risk labels. No quantitative validation of label fidelity (e.g., inter-annotator agreement on a sampled subset or bias audit) is described. This is load-bearing for the claim that improvements arise from 'acting on representations they already possess' rather than from systematic mislabeling or visual shortcuts introduced by the generation process.
- [Experiments] Experiments (SCAND and real-world results): The paper must include ablations that isolate the contribution of each SALSA stage and that compare against standard behavior cloning with the same automatically generated supervision. Without these controls, it remains unclear whether the reported gains require the proposed bridging mechanism or could be obtained by simply training on the new labels.
minor comments (2)
- [Abstract] Abstract: The phrase 'annotation-free' is used prominently, yet the automatic generation still requires hand-specified rules for creating counterfactuals and risk labels; these rules should be stated explicitly so readers can assess potential inductive biases.
- [Experiments] The real-world deployment description lacks basic details such as robot platform, environment characteristics, and number of trials, which would aid reproducibility even if full code is released.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of evaluation rigor and methodological validation. We address each major comment point by point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The quantitative claims (86.4% near-collision reduction and accuracy improvement from 53% to 93%) are presented without any reference to baseline methods, number of trials, statistical significance testing, or controls for confounds such as dataset shifts between training and test scenes. These omissions are load-bearing because the central claim attributes the gains specifically to SALSA unlocking preexisting representations rather than to artifacts of the evaluation protocol.
Authors: We agree that the abstract would benefit from additional context on the evaluation protocol. In the revised version, we will expand the abstract to reference the standard behavior cloning baseline, note the evaluation across the full SCAND test set (multiple scenes and trials), and indicate that statistical significance testing and controls for scene variations (via fixed benchmark splits) are detailed in Section 4. This directly supports the attribution to SALSA by clarifying the comparison setup. revision: yes
-
Referee: [Method] Method section (counterfactual generation and future-risk supervision): The two-stage procedure depends entirely on automatically generated counterfactual human-object pairs and future-risk labels. No quantitative validation of label fidelity (e.g., inter-annotator agreement on a sampled subset or bias audit) is described. This is load-bearing for the claim that improvements arise from 'acting on representations they already possess' rather than from systematic mislabeling or visual shortcuts introduced by the generation process.
Authors: The counterfactual and future-risk labels are generated via deterministic geometric and temporal rules derived from raw observations, making human inter-annotator agreement inapplicable by design. We acknowledge the referee's point on the need for explicit fidelity checks. We will add a new paragraph and table in the revised Method section reporting a bias audit on a random sample of 200 generated pairs, including quantitative metrics for shortcut introduction and agreement with manual verification on that subset. revision: yes
-
Referee: [Experiments] Experiments (SCAND and real-world results): The paper must include ablations that isolate the contribution of each SALSA stage and that compare against standard behavior cloning with the same automatically generated supervision. Without these controls, it remains unclear whether the reported gains require the proposed bridging mechanism or could be obtained by simply training on the new labels.
Authors: We agree that isolating the stages and controlling for the supervision source is necessary to substantiate the bridging mechanism. The current experiments compare against behavior cloning but do not fully ablate the two stages independently. In the revision, we will add a dedicated ablation study (new Table in Section 4) with four conditions: social alignment only, temporal safety alignment only, full SALSA, and standard behavior cloning trained on identical generated labels. Results will confirm the necessity of the feature-bridging step. revision: yes
Circularity Check
No significant circularity; empirical method with external evaluation
full rationale
The paper describes an empirical two-stage post-training procedure (SALSA) applied to pretrained VLA models, with claimed gains measured on SCAND and real-world deployments. No equations, derivations, or load-bearing steps reduce the reported improvements (e.g., 86.4% near-collision reduction) to fitted parameters renamed as predictions or to self-citations. The automatic generation of counterfactual pairs and risk labels is presented as an implementation detail whose correctness is independent of the central claim; it does not create a self-definitional loop where the output is forced by the input construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Francis, C
A. Francis, C. P ´erez-d’Arpino, C. Li, F. Xia, A. Alahi, R. Alami, A. Bera, A. Biswas, J. Biswas, R. Chandra, et al. Principles and guidelines for evaluating social robot navigation algorithms. ACM Transactions on Human-Robot Interaction, 14(2):1–65, 2025
2025
-
[2]
P. T. Singamaneni, P. Bachiller-Burgos, L. J. Manso, A. Garrell, A. Sanfeliu, A. Spalanzani, and R. Alami. A survey on socially aware robot navigation: Taxonomy and future challenges. The International Journal of Robotics Research, 43(10):1533–1572, 2024
2024
-
[3]
Y . Cui, H. Zhang, Y . Wang, and R. Xiong. Learning world transition model for socially aware robot navigation. In2021 ieee international conference on robotics and automation (icra), pages 9262–9268. IEEE, 2021
2021
-
[4]
D. M. Nguyen, M. Nazeri, A. Payandeh, A. Datar, and X. Xiao. Toward human-like so- cial robot navigation: A large-scale, multi-modal, social human navigation dataset. In2023 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 7442–
-
[5]
G. Seneviratne, J. An, V . Shende, S. Ellahy, Y . Amin, K. Manasanjani, S. Chopra, J. D. Kannan, and D. Manocha. Chop: Counterfactual human preference labels improve obstacle avoidance in visuomotor navigation policies.arXiv preprint arXiv:2603.02004, 2026
arXiv 2026
-
[6]
Z. Fang, A. Xiao, D. Hsu, and G. H. Lee. From obstacles to etiquette: Robot social navigation with vlm-informed path selection.IEEE Robotics and Automation Letters, 2026
2026
- [7]
-
[8]
A. Payandeh, D. Song, M. Nazeri, J. Liang, P. Mukherjee, A. H. Raj, Y . Kong, D. Manocha, and X. Xiao. Social-llava: Enhancing robot navigation through human-language reasoning in social spaces.arXiv preprint arXiv:2501.09024, 2024
arXiv 2024
- [9]
-
[10]
Z. Huang, Y . Zhang, J. Liu, R. Song, C. Tang, and J. Ma. Tic-vla: A think-in-control vision-language-action model for robot navigation in dynamic environments.arXiv preprint arXiv:2602.02459, 2026
Pith/arXiv arXiv 2026
-
[11]
J. R. Han, M. Vanniasinghe, H. Sahak, N. Rhinehart, and T. D. Barfoot. Ratatouille: Imitation learning ingredients for real-world social robot navigation.arXiv preprint arXiv:2509.17204, 2025
arXiv 2025
-
[12]
W. Chen, O. Mees, A. Kumar, and S. Levine. Vision-language models provide promptable representations for reinforcement learning.arXiv preprint arXiv:2402.02651, 2024
arXiv 2024
-
[13]
D. Song, J. Liang, A. Payandeh, A. H. Raj, X. Xiao, and D. Manocha. Vlm-social-nav: Socially aware robot navigation through scoring using vision-language models, 2024. URLhttps: //arxiv.org/abs/2404.00210. 9
arXiv 2024
-
[14]
Zhang, Y
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. Safevla: Towards safety alignment of vision-language-action model via safe reinforcement learning.arXiv e-prints, pages arXiv–2503, 2025
2025
-
[15]
Y . Kong, D. Song, J. Liang, D. Manocha, Z. Yao, and X. Xiao. Autospatial: Visual-language reasoning for social robot navigation through efficient spatial reasoning learning. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11298– 11304. IEEE, 2025
2025
- [16]
-
[17]
Helbing and P
D. Helbing and P. Molnar. Social force model for pedestrian dynamics.Physical review E, 51 (5):4282, 1995
1995
-
[18]
Y . F. Chen, M. Liu, M. Everett, and J. P. How. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning, 2016. URLhttps://arxiv.org/ abs/1609.07845
Pith/arXiv arXiv 2016
-
[19]
Y . F. Chen, M. Everett, M. Liu, and J. P. How. Socially aware motion planning with deep reinforcement learning, 2018. URLhttps://arxiv.org/abs/1703.08862
Pith/arXiv arXiv 2018
-
[20]
C. Chen, Y . Liu, S. Kreiss, and A. Alahi. Crowd-robot interaction: Crowd-aware robot navi- gation with attention-based deep reinforcement learning, 2019. URLhttps://arxiv.org/ abs/1809.08835
arXiv 2019
-
[21]
X. Wu, R. Chandra, T. Guan, A. Bedi, and D. Manocha. Intent-aware planning in hetero- geneous traffic via distributed multi-agent reinforcement learning. InConference on Robot Learning, pages 446–477. PMLR, 2023
2023
-
[22]
Z. Fang, A. Xiao, D. Hsu, and G. H. Lee. From obstacles to etiquette: Robot social navigation with vlm-informed path selection, 2026. URLhttps://arxiv.org/abs/2602.09002
arXiv 2026
-
[23]
S. Luo, P. Sun, J. Zhu, Y . Deng, C. Yu, A. Xiao, and X. Wang. Gson: A group-based social navigation framework with large multimodal model, 2025. URLhttps://arxiv.org/abs/ 2409.18084
arXiv 2025
-
[24]
T. Guan, Y . Yang, H. Cheng, M. Lin, R. Kim, R. Madhivanan, A. Sen, and D. Manocha. Zsorn: language-driven object-centric zero-shot object retrieval and navigation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 10922–10928. IEEE, 2025
2025
-
[25]
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine. Gnm: A general navigation model to drive any robot, 2023. URLhttps://arxiv.org/abs/2210.03370
arXiv 2023
- [27]
-
[28]
M. J. Munje, C. Tang, S. Liu, Z. Hu, Y . Zhu, J. Cui, G. Warnell, J. Biswas, and P. Stone. Socialnav-sub: Benchmarking vlms for scene understanding in social robot navigation, 2025. URLhttps://arxiv.org/abs/2509.08757
arXiv 2025
-
[29]
Chefer, S
H. Chefer, S. Gur, and L. Wolf. Generic attention-model explainability for interpreting bi- modal and encoder-decoder transformers. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 397–406, 2021. 10
2021
-
[30]
Aflalo, M
E. Aflalo, M. Du, S.-Y . Tseng, Y . Liu, C. Wu, N. Duan, and V . Lal. Vl-interpret: An inter- active visualization tool for interpreting vision-language transformers. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 21406–21415, 2022
2022
-
[31]
T. Oikarinen and T.-W. Weng. Clip-dissect: Automatic description of neuron representations in deep vision networks.arXiv preprint arXiv:2204.10965, 2022
arXiv 2022
-
[32]
M. G. Castro, S. Rajagopal, D. Gorbatov, M. Schmittle, R. Baijal, O. Zhang, R. Scalise, S. Talia, E. Romig, C. de Melo, et al. Vamos: A hierarchical vision-language-action model for capability-modulated and steerable navigation.arXiv preprint arXiv:2510.20818, 2025
arXiv 2025
-
[33]
H. Buurmeijer, C. A. Alonso, A. Swann, and M. Pavone. Observing and controlling features in vision-language-action models, 2026. URLhttps://arxiv.org/abs/2603.05487
arXiv 2026
-
[34]
H. Lu, H. Li, P. S. Shahani, S. Herbers, and M. Scheutz. Probing a vision-language-action model for symbolic states and integration into a cognitive architecture, 2025. URLhttps: //arxiv.org/abs/2502.04558
arXiv 2025
- [35]
-
[36]
Karnan, A
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone. Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation.IEEE Robotics and Automation Letters, 7(4):11807–11814, 2022
2022
-
[37]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[38]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the Na- tional Academy of Sciences, 114(13):3521–3526, 2017
2017
-
[39]
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine. Gnm: A general navigation model to drive any robot. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7226–7233. IEEE, 2023
2023
-
[40]
D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine. Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
arXiv 2023
-
[41]
Sridhar, D
A. Sridhar, D. Shah, C. Glossop, and S. Levine. Nomad: Goal masked diffusion policies for navigation and exploration. In2024 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 63–70. IEEE, 2024. 11 A Detailed Real-Robot Deployment Results Table 3: Detailed real-robot deployment metrics per scenario, computed over the logged trials wi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.