LAFP: Preserving Latent Action Structure in Latent Policy Learning via Flow Matching
Pith reviewed 2026-06-27 13:56 UTC · model grok-4.3
The pith
LAFP combines flow matching with inference-time interpolation to preserve multimodal latent action distributions in policy learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
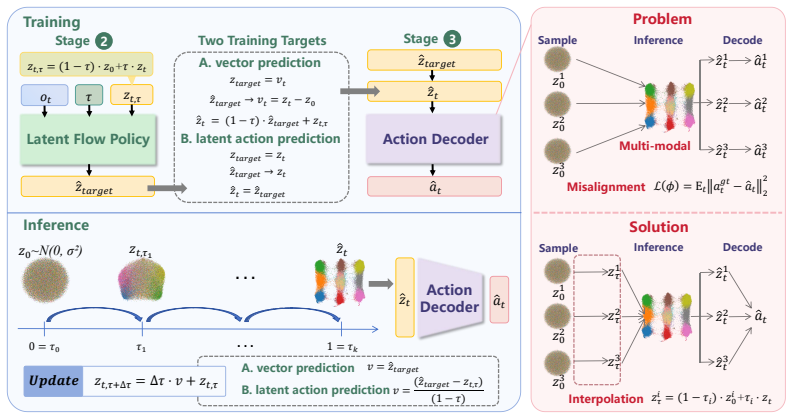
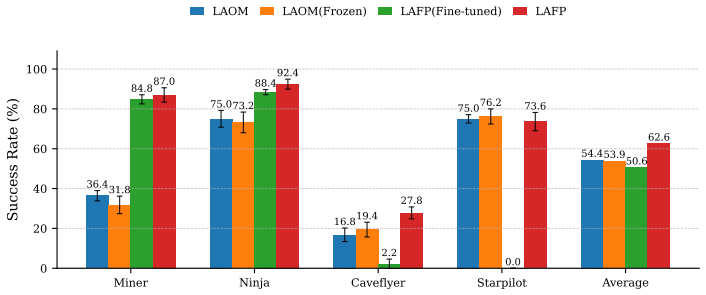
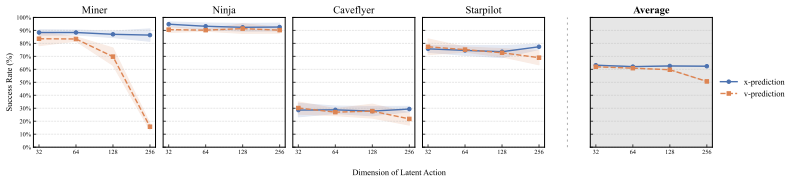
LAFP leverages flow matching for latent policy learning and introduces an inference-time interpolation mechanism to mitigate stochasticity-induced misalignment between latent actions and physical actions. This preserves the pretrained latent action structure that behavior cloning tends to collapse, resulting in consistent improvements on downstream imitation learning tasks.
What carries the argument
The inference-time interpolation mechanism that realigns stochastic latent policy outputs with the physical action decoder during training.
If this is right
- Downstream imitation learning tasks achieve up to 10-15% higher success rates than prior methods.
- The added inference overhead stays below 1x compared with earlier approaches.
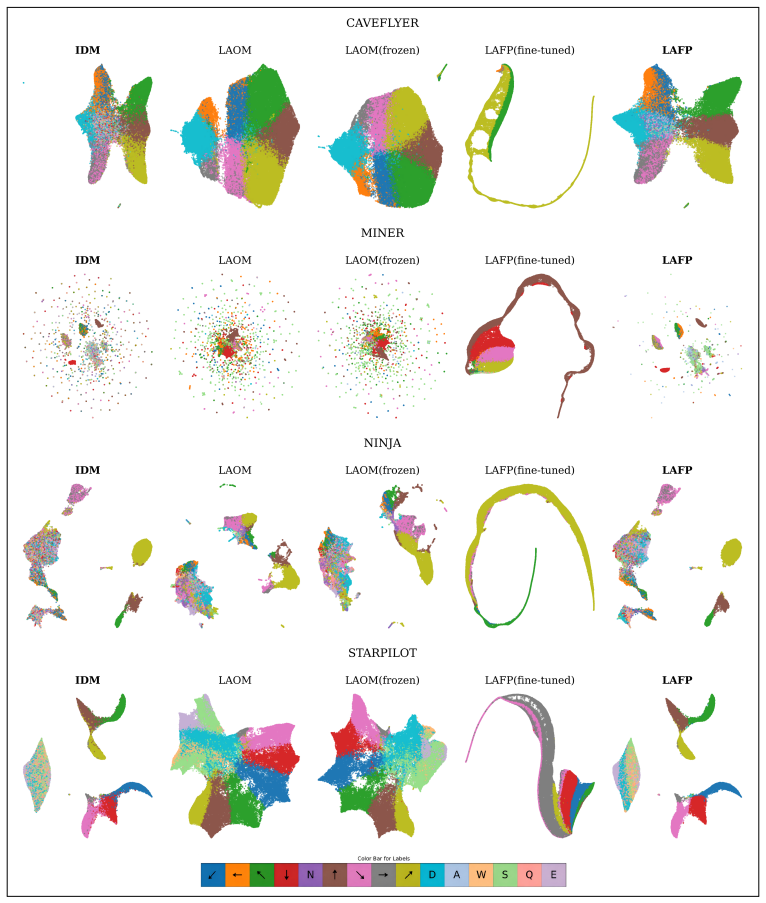
- Multimodal structure in the latent actions is kept intact rather than collapsed to a single mode.
- Large-scale video pretraining of latent actions can be used more effectively with limited real-world interaction data.
Where Pith is reading between the lines
- The same interpolation step might reduce similar misalignment problems when flow matching is used in other stochastic sequence models.
- Ablating the interpolation strength on new robot platforms would test whether the alignment benefit scales with task complexity.
- If the method works mainly by stabilizing decoder training, it could be combined with other latent variable objectives that also suffer from stochastic drift.
Load-bearing premise
The inference-time interpolation mechanism sufficiently reduces misalignment between latent actions and physical actions caused by the stochastic policy without creating new performance issues.
What would settle it
An ablation that removes only the inference-time interpolation and checks whether success rates fall back to the level seen when flow matching is applied without it.
Figures



read the original abstract
Learning high-quality latent actions from large-scale unlabeled videos, coupled with limited real-world interaction data for training an action decoder, has emerged as a promising paradigm for scalable latent policy learning. However, existing approaches typically rely on behavior cloning, which tends to collapse inherently multimodal action distributions into unimodal ones, thereby degrading the pretrained latent action structure. While flow matching provides a potential alternative, directly applying it leads to a misalignment between latent actions and physical actions during action decoder training, due to the stochastic nature of the learned policy. To address these, we propose Latent Action Flow Policy (LAFP), which leverages flow matching for latent policy learning and introduces an inference-time interpolation mechanism to mitigate stochasticity-induced misalignment. Experimental results demonstrate that LAFP consistently outperforms prior methods on downstream imitation learning tasks, achieving up to 10-15% improvement in success rate while incurring less than 1x additional inference overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Latent Action Flow Policy (LAFP) to address limitations in latent policy learning from unlabeled videos and limited interaction data. It argues that behavior cloning collapses multimodal action distributions while direct application of flow matching induces misalignment between latent and physical actions due to policy stochasticity. LAFP applies flow matching for the latent policy and adds an inference-time interpolation mechanism to mitigate this misalignment. The central empirical claim is consistent outperformance on downstream imitation learning tasks, with success-rate gains of 10-15% and less than 1x additional inference overhead.
Significance. If the reported gains are reproducible and the interpolation mechanism proves robust across domains, the work could meaningfully advance scalable robot learning by better preserving multimodal structure in latent action spaces without prohibitive compute cost. The low-overhead design is a practical strength.
major comments (2)
- [Abstract] Abstract: the central claim of 'up to 10-15% improvement in success rate' is presented without reference to specific tasks, number of environments, baselines, number of trials, or statistical significance; this absence prevents assessment of whether the gains are load-bearing for the method's contribution or sensitive to evaluation choices.
- [Abstract] Abstract: the inference-time interpolation is described as mitigating 'stochasticity-induced misalignment,' yet no quantitative analysis (e.g., alignment metrics before/after interpolation or ablation removing the mechanism) is referenced, leaving the weakest assumption of the argument unverified in the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the two major comments point by point below and propose targeted revisions to improve clarity without altering the manuscript's core claims or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'up to 10-15% improvement in success rate' is presented without reference to specific tasks, number of environments, baselines, number of trials, or statistical significance; this absence prevents assessment of whether the gains are load-bearing for the method's contribution or sensitive to evaluation choices.
Authors: We agree that greater specificity in the abstract would help readers evaluate the scope and robustness of the reported gains. Section 4 of the manuscript details the experimental protocol, including the specific downstream imitation tasks, environments, baselines, trial counts, and variability measures. We will revise the abstract to briefly reference the evaluation scope (e.g., consistent gains across the reported tasks and environments) while preserving conciseness. revision: yes
-
Referee: [Abstract] Abstract: the inference-time interpolation is described as mitigating 'stochasticity-induced misalignment,' yet no quantitative analysis (e.g., alignment metrics before/after interpolation or ablation removing the mechanism) is referenced, leaving the weakest assumption of the argument unverified in the provided text.
Authors: Quantitative support for the interpolation mechanism, including alignment metrics before and after its application as well as an ablation removing the component, appears in Section 5 and the appendix. We will revise the abstract to include a concise reference to these analyses, thereby addressing the verification concern directly in the abstract text. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe LAFP as a method that applies flow matching to latent policy learning and adds an inference-time interpolation to handle stochastic misalignment, with performance gains reported as empirical results on downstream tasks. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the text. The central claims rest on external imitation learning benchmarks rather than reducing to inputs defined within the paper itself, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A framework for behavioural cloning
Michael Bain and Claude Sammut. A framework for behavioural cloning. InMachine intelli- gence 15, pages 103–129, 1995
1995
-
[2]
Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[3]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems. InIROS, 2025
2025
-
[6]
Learning to act anywhere with task-centric latent actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Learning to act anywhere with task-centric latent actions. InRSS, 2025
2025
-
[7]
Xizhou Bu, Jiexi Lyu, Fulei Sun, Ruichen Yang, Zhiqiang Ma, and Wei Li. Laof: Robust latent action learning with optical flow constraints.arXiv preprint arXiv:2511.16407, 2025
arXiv 2025
-
[8]
Villa-x: enhancing latent action modeling in vision-language-action models
Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, et al. Villa-x: enhancing latent action modeling in vision-language-action models. InICLR, 2026
2026
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[10]
Leveraging procedural generation to benchmark reinforcement learning
Karl Cobbe, Chris Hesse, Jacob Hilton, and John Schulman. Leveraging procedural generation to benchmark reinforcement learning. InICML, 2020
2020
-
[11]
Learning to act robustly with view-invariant latent actions.arXiv preprint arXiv:2601.02994, 2026
Youngjoon Jeong, Junha Chun, and Taesup Kim. Learning to act robustly with view-invariant latent actions.arXiv preprint arXiv:2601.02994, 2026
arXiv 2026
-
[12]
Object-centric latent action learning
Albina Klepach, Alexander Nikulin, Ilya Zisman, Denis Tarasov, Alexander Derevyagin, Andrei Polubarov, Nikita Lyubaykin, and Vladislav Kurenkov. Object-centric latent action learning. In 7th Robot Learning Workshop: Towards Robots with Human-Level Abilities, 2025
2025
-
[13]
Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
Pith/arXiv arXiv 2025
-
[14]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[15]
Mingyu Liu, Jiuhe Shu, Hui Chen, Zeju Li, Canyu Zhao, Jiange Yang, Shenyuan Gao, Hao Chen, and Chunhua Shen. Stamo: Unsupervised learning of generalizable robot motion from compact state representation.arXiv preprint arXiv:2510.05057, 2025
Pith/arXiv arXiv 2025
-
[16]
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
Pith/arXiv arXiv 2022
-
[17]
Towards generalist robot learning from internet video: A survey.Journal of Artificial Intelligence Research, 83, 2025
Robert McCarthy, Daniel CH Tan, Dominik Schmidt, Fernando Acero, Nathan Herr, Yilun Du, Thomas G Thuruthel, and Zhibin Li. Towards generalist robot learning from internet video: A survey.Journal of Artificial Intelligence Research, 83, 2025
2025
-
[18]
Lary: A latent action representation yielding benchmark for generalizable vision-to-action alignment
Dujun Nie, Fengjiao Chen, Qi Lv, Jun Kuang, Xiaoyu Li, Xuezhi Cao, and Xunliang Cai. Lary: A latent action representation yielding benchmark for generalizable vision-to-action alignment. arXiv preprint arXiv:2604.11689, 2026. 10
Pith/arXiv arXiv 2026
-
[19]
Latent action learning requires supervision in the presence of distractors
Alexander Nikulin, Ilya Zisman, Denis Tarasov, Nikita Lyubaykin, Andrei Polubarov, Igor Kiselev, and Vladislav Kurenkov. Latent action learning requires supervision in the presence of distractors. InICML, 2025
2025
-
[20]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[21]
Learning to act without actions
Dominik Schmidt and Minqi Jiang. Learning to act without actions. InICLR, 2024
2024
-
[22]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[23]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[24]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InNeurIPS, 2017
2017
-
[25]
Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Zhibin Tang, Kun Wu, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.IEEE Robotics and Automation Letters, 2025
2025
-
[26]
Latentvla: Efficient vision-language models for autonomous driving via latent action prediction
Chengen Xie, Bin Sun, Tianyu Li, Junjie Wu, Zhihui Hao, XianPeng Lang, and Hongyang Li. Latentvla: Efficient vision-language models for autonomous driving via latent action prediction. arXiv preprint arXiv:2601.05611, 2026
arXiv 2026
-
[27]
Ge Yan, Jiyue Zhu, Yuquan Deng, Shiqi Yang, Ri-Zhao Qiu, Xuxin Cheng, Marius Memmel, Ranjay Krishna, Ankit Goyal, Xiaolong Wang, et al. Maniflow: A general robot manipulation policy via consistency flow training.arXiv preprint arXiv:2509.01819, 2025
arXiv 2025
-
[28]
Jiange Yang, Yansong Shi, Haoyi Zhu, Mingyu Liu, Kaijing Ma, Yating Wang, Gangshan Wu, Tong He, and Limin Wang. Como: Learning continuous latent motion from internet videos for scalable robot learning.arXiv preprint arXiv:2505.17006, 2025
Pith/arXiv arXiv 2025
-
[29]
Latent action pretraining from videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos. InICLR, 2025
2025
-
[30]
Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Chengming Xu, Yue Ma, Xiaobin Hu, Zhe Cao, Jie Xu, et al. The latent space: Foundation, evolution, mechanism, ability, and outlook.arXiv preprint arXiv:2604.02029, 2026
Pith/arXiv arXiv 2026
-
[31]
What do latent action models actually learn? InNeurIPS, 2025
Chuheng Zhang, Tim Pearce, Pushi Zhang, Kaixin Wang, Xiaoyu Chen, Wei Shen, Li Zhao, and Jiang Bian. What do latent action models actually learn? InNeurIPS, 2025. 11 Appendix Overview This appendix provides supplementary details and experimental results omitted from the main paper due to page constraints. It is organized as follows: • Sec. A reports full ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.