GUI-AC: Enhancing Continual Learning in GUI Agents
Pith reviewed 2026-06-27 13:54 UTC · model grok-4.3
The pith
GUI-AC stabilizes reinforcement fine-tuning for GUI agents by using grounding certainty for adaptive advantage and dynamic clipping.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GUI-AC introduces grounding certainty to support Adaptive Advantage, which down-weights noisy advantage estimates to prevent policy overconfidence, and Dynamic Clipping, which relaxes the clipping bound to encourage exploration range. These mechanisms jointly address instabilities in reinforcement fine-tuning and enable GUI agents to handle persistent distribution shifts from novel interface instances.
What carries the argument
Grounding certainty, which supplies the signal for adaptive advantage estimation and dynamic clipping bounds during reinforcement fine-tuning of GUI agents.
If this is right
- Policy overconfidence from imbalanced rollout outcomes is reduced during adaptation to new interfaces.
- Exploration capacity is preserved because the clipping bound can increase when grounding certainty is high.
- Overall task performance exceeds that of prior state-of-the-art reinforcement fine-tuning methods on continual GUI benchmarks.
- Agents maintain grounding capability across repeated distribution shifts without requiring full retraining.
Where Pith is reading between the lines
- The same certainty signal might be applied to other reinforcement-learning settings that exhibit high-variance advantage estimates and fixed clipping.
- If the computation of grounding certainty generalizes, it could reduce reliance on manual hyperparameter schedules for clipping and advantage normalization.
- The approach may extend naturally to agents operating in other non-stationary interactive environments such as web browsers or mobile applications.
Load-bearing premise
The listed instabilities are the dominant causes of failure in reinforcement fine-tuning for GUI continual learning, and grounding certainty can be computed reliably enough to correct them without creating new failure modes.
What would settle it
Training the method on a held-out collection of previously unseen GUI domains and resolutions and observing either no performance gain over baselines or the reappearance of the same reward discontinuities and exploration collapse would falsify the central claim.
Figures
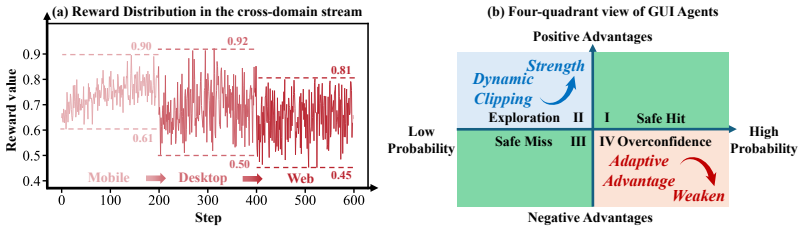

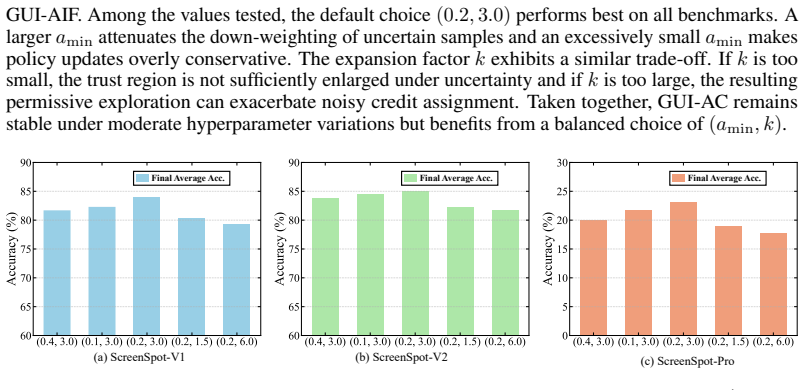
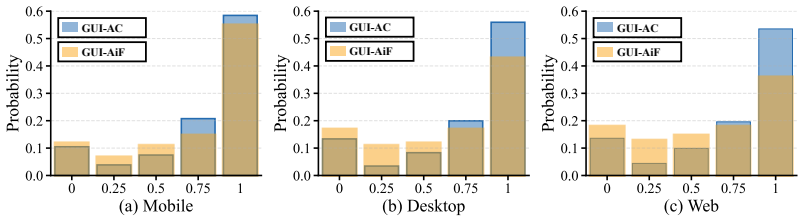
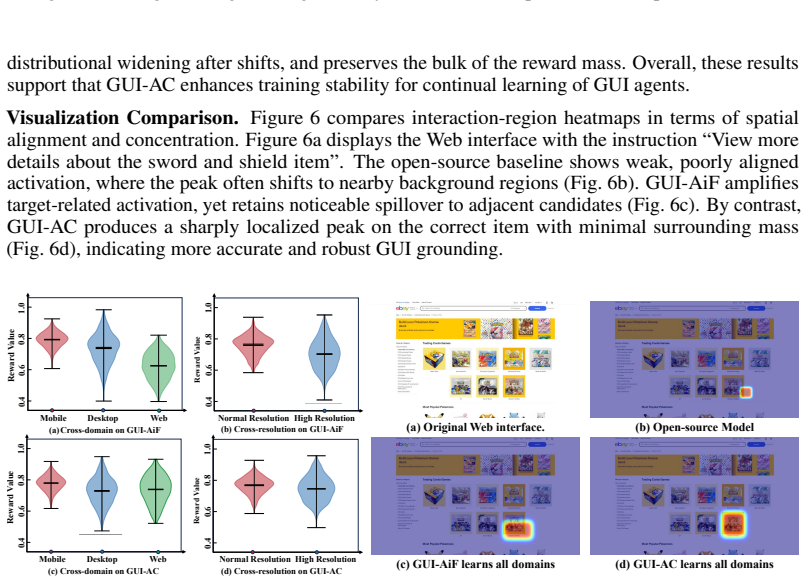
read the original abstract
Graphical User Interfaces (GUIs) serve as the dominant medium for human-computer interaction, yet building GUI agents that generalize across the vast diversity of real-world interface environments, with the same flexibility and robustness that humans naturally exhibit, remains unsolved. Notably, GUI data are inherently non-stationary: the continual emergence of previously unseen interface instances (e.g., novel domains and resolutions) induces persistent distribution shifts, significantly impeding the continual learning of existing GUI agents. Reinforcement fine-tuning (RFT) has attracted considerable attention as a promising approach. Nevertheless, RFT exhibits pronounced instability in its grounding capability, manifested as sharp reward discontinuities and high-variance oscillations. The imbalanced distribution of rollout outcomes introduces substantial noise into advantage estimation, leading to policy overconfidence. The fixed clipping bound suppresses the increase in policy probabilities needed to adapt to new distributions, leading to a collapse in exploration capacity. To address these challenges, we propose GUI-AC, a method that enhances the continual learning capability of GUI agents. GUI-AC introduces grounding certainty to support two core mechanisms: (i) Adaptive Advantage, which down-weights noisy advantage estimates to prevent policy overconfidence; and (ii) Dynamic Clipping, which relaxes the clipping bound to encourage exploration range. Extensive experiments show that these mechanisms jointly improve performance, enabling our method to surpass state-of-the-art baselines. Code is available anonymously at https://anonymous.4open.science/r/GUI-AC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GUI-AC to improve continual learning for GUI agents under non-stationary interface distributions. It diagnoses four instabilities in reinforcement fine-tuning (sharp reward discontinuities, high-variance oscillations, imbalanced rollout outcomes causing noisy advantage estimates, and fixed clipping that limits exploration) and introduces a grounding-certainty signal to drive two mechanisms: Adaptive Advantage (down-weighting noisy advantages to avoid overconfidence) and Dynamic Clipping (relaxing the clipping bound to restore exploration capacity). The abstract asserts that these mechanisms jointly yield performance gains that surpass state-of-the-art baselines, with code released anonymously.
Significance. If the experimental claims hold and the grounding-certainty signal proves robust across distribution shifts, the work would address a practically important obstacle in deploying GUI agents. The explicit targeting of RFT instabilities and the provision of anonymous code are positive features that could support reproducibility and follow-on research in continual learning for interface agents.
major comments (2)
- [Abstract] Abstract: the central claim that 'extensive experiments show that these mechanisms jointly improve performance, enabling our method to surpass state-of-the-art baselines' is unsupported by any referenced metrics, tables, ablation studies, or error analysis. This absence is load-bearing for the primary contribution.
- [Abstract] Abstract: no equations, pseudocode, or formal definitions are supplied for grounding certainty, the Adaptive Advantage weighting function, or the Dynamic Clipping schedule. Without these, it is impossible to evaluate whether the certainty signal is independent of the very policy errors (reward discontinuities, high-variance rollouts) it is intended to correct, leaving the skeptic concern about circularity unaddressed.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback. We address each major comment on the abstract below, proposing targeted revisions where appropriate to strengthen the presentation of our claims and method details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'extensive experiments show that these mechanisms jointly improve performance, enabling our method to surpass state-of-the-art baselines' is unsupported by any referenced metrics, tables, ablation studies, or error analysis. This absence is load-bearing for the primary contribution.
Authors: We agree that referencing specific empirical support would make the abstract's central claim more robust. In the revised version, we will incorporate concise mentions of key quantitative results (such as average success rate improvements and comparisons to baselines) along with explicit references to the primary results table and ablation studies presented in the experimental section. This revision will directly substantiate the claim within the abstract while adhering to length limits. revision: yes
-
Referee: [Abstract] Abstract: no equations, pseudocode, or formal definitions are supplied for grounding certainty, the Adaptive Advantage weighting function, or the Dynamic Clipping schedule. Without these, it is impossible to evaluate whether the certainty signal is independent of the very policy errors (reward discontinuities, high-variance rollouts) it is intended to correct, leaving the skeptic concern about circularity unaddressed.
Authors: Abstracts conventionally omit equations and pseudocode to maintain brevity; these are fully provided in the main manuscript (formal definition and weighting function for grounding certainty and Adaptive Advantage in Section 3.2, Dynamic Clipping schedule in Section 3.3, and pseudocode in Algorithm 1). On the circularity concern, grounding certainty is computed via a dedicated grounding evaluation on localization accuracy for interface elements, which operates independently of the rollout-derived advantage estimates and reward signals. We will add a brief clarifying phrase to the revised abstract and expand the independence discussion in Section 3 to explicitly address this point. revision: partial
Circularity Check
No derivation chain or equations; claims rest on experimental results only.
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or self-citations of prior uniqueness theorems. The method is introduced at the level of high-level mechanisms (Adaptive Advantage, Dynamic Clipping) justified by addressing listed instabilities, with performance claims supported solely by 'extensive experiments.' No load-bearing step reduces by construction to its own inputs, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GUI Agents with Foundation Models: A Comprehensive Survey.arXiv preprint arXiv:2411.04890, 2024
Shuai Wang, Weiwen Liu, Jingxuan Chen, Yuqi Zhou, Weinan Gan, Xingshan Zeng, Yuhan Che, Shuai Yu, Xinlong Hao, Kun Shao, et al. GUI Agents with Foundation Models: A Comprehensive Survey.arXiv preprint arXiv:2411.04890, 2024
arXiv 2024
-
[2]
A Survey on (M)LLM-Based GUI Agents.arXiv preprint arXiv:2504.13865, 2025
Fei Tang, Haolei Xu, Hang Zhang, Siqi Chen, Xingyu Wu, Yongliang Shen, Wenqi Zhang, Guiyang Hou, Zeqi Tan, Yuchen Yan, et al. A Survey on (M)LLM-Based GUI Agents.arXiv preprint arXiv:2504.13865, 2025
arXiv 2025
-
[3]
CogAgent: A Visual Language Model for GUI Agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. CogAgent: A Visual Language Model for GUI Agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14281–14290, 2024
2024
-
[4]
KG-RAG: Enhancing GUI Agent Decision- Making via Knowledge Graph-Driven Retrieval-Augmented Generation
Ziyi Guan, Jason Chun Lok Li, Zhijian Hou, Pingping Zhang, Donglai Xu, Yuzhi Zhao, Mengyang Wu, Jinpeng Chen, Thanh-Toan Nguyen, Pengfei Xian, et al. KG-RAG: Enhancing GUI Agent Decision- Making via Knowledge Graph-Driven Retrieval-Augmented Generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5396–5405, 2025
2025
-
[5]
SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 9313–9332, 2024
2024
-
[6]
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. ShowUI: One Vision-Language-Action Model for GUI Visual Agent. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19498–19508, 2025
2025
-
[7]
Continual GUI Agents.arXiv, 2026
Ziwei Liu, Borui Kang, Hangjie Yuan, Zixiang Zhao, Wei Li, Yifan Zhu, and Tao Feng. Continual GUI Agents.arXiv, 2026
2026
-
[8]
Overcoming Catastrophic Forgetting in Incremental Object Detection via Elastic Response Distillation
Tao Feng, Mang Wang, and Hangjie Yuan. Overcoming Catastrophic Forgetting in Incremental Object Detection via Elastic Response Distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9427–9436, 2022
2022
-
[9]
Yong Du, Yuchen Yan, Fei Tang, Zhengxi Lu, Chang Zong, Weiming Lu, Shengpei Jiang, and Yongliang Shen. Test-Time Reinforcement Learning for GUI Grounding via Region Consistency.arXiv preprint arXiv:2508.05615, 2025
arXiv 2025
-
[10]
Xianhang Ye, Yiqing Li, Wei Dai, Miancan Liu, Ziyuan Chen, Zhangye Han, Hongbo Min, Jinkui Ren, Xiantao Zhang, Wen Yang, et al. GUI-ARP: Enhancing Grounding with Adaptive Region Perception for GUI Agents.arXiv preprint arXiv:2509.15532, 2025. 10
arXiv 2025
-
[11]
Shuquan Lian, Yuhang Wu, Jia Ma, Yifan Ding, Zihan Song, Bingqi Chen, Xiawu Zheng, and Hui Li. UI-AGILE: Advancing GUI Agents with Effective Reinforcement Learning and Precise Inference-Time Grounding.arXiv preprint arXiv:2507.22025, 2025
Pith/arXiv arXiv 2025
-
[12]
Visual-RFT: Visual Reinforcement Fine-Tuning.arXiv preprint arXiv:2503.01785, 2025
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-RFT: Visual Reinforcement Fine-Tuning.arXiv preprint arXiv:2503.01785, 2025
Pith/arXiv arXiv 2025
-
[13]
Zhihao Zhang, Qiaole Dong, Qi Zhang, Jun Zhao, Enyu Zhou, Zhiheng Xi, Senjie Jin, Xiaoran Fan, Yuhao Zhou, Mingqi Wu, et al. Why Reinforcement Fine-Tuning Enables MLLMs Preserve Prior Knowledge Better: A Data Perspective.arXiv preprint arXiv:2506.23508, 2025
arXiv 2025
-
[14]
Jinpeng Wang, Chao Li, Ting Ye, Mengyuan Zhang, Wei Liu, and Jian Luan. ICPO: Intrinsic Confidence- Driven Group Relative Preference Optimization for Efficient Reinforcement Learning.arXiv preprint arXiv:2511.21005, 2025
arXiv 2025
-
[15]
DCPO: Dynamic Clipping Policy Optimization.arXiv preprint arXiv:2509.02333, 2025
Shihui Yang, Chengfeng Dou, Peidong Guo, Kai Lu, Qiang Ju, Fei Deng, and Rihui Xin. DCPO: Dynamic Clipping Policy Optimization.arXiv preprint arXiv:2509.02333, 2025
arXiv 2025
-
[16]
Zhipeng Chen, Yingqian Min, Beichen Zhang, Jie Chen, Jinhao Jiang, Daixuan Cheng, Wayne Xin Zhao, Zheng Liu, Xu Miao, Yang Lu, et al. An Empirical Study on Eliciting and Improving R1-like Reasoning Models.arXiv preprint arXiv:2503.04548, 2025
arXiv 2025
-
[17]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An Open-Source LLM Reinforcement Learning System at Scale. arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[18]
OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem AlShikh, and Ruslan Salakhutdinov. OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web. InEuropean Conference on Computer Vision, pages 161–178. Springer, 2024
2024
-
[19]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents.arXiv preprint arXiv:2410.23218, 2024
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. OS-ATLAS: A Foundation Action Model for Generalist GUI Agents.arXiv preprint arXiv:2410.23218, 2024
Pith/arXiv arXiv 2024
-
[20]
ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use. InProceedings of the 33rd ACM International Conference on Multimedia, pages 8778–8786, 2025
2025
-
[21]
InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners
Yuhang Liu, Pengxiang Li, Congkai Xie, Xavier Hu, Xiaotian Han, Shengyu Zhang, Hongxia Yang, and Fei Wu. InfiGUI-R1: Advancing Multimodal GUI Agents from Reactive Actors to Deliberative Reasoners. arXiv preprint arXiv:2504.14239, 2025
Pith/arXiv arXiv 2025
-
[22]
Xinbin Yuan, Jian Zhang, Kaixin Li, Zhuoxuan Cai, Lujian Yao, Jie Chen, Enguang Wang, Qibin Hou, Jinwei Chen, Peng-Tao Jiang, et al. Enhancing Visual Grounding for GUI Agents via Self-Evolutionary Reinforcement Learning.arXiv preprint arXiv:2505.12370, 2025
arXiv 2025
-
[23]
GUI-G 2: Gaussian Reward Modeling for GUI Grounding
Fei Tang, Zhangxuan Gu, Zhengxi Lu, Xuyang Liu, Shuheng Shen, Changhua Meng, Wen Wang, Wenqi Zhang, Yongliang Shen, Weiming Lu, et al. GUI-G 2: Gaussian Reward Modeling for GUI Grounding. arXiv preprint arXiv:2507.15846, 2025
arXiv 2025
-
[24]
Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[25]
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the Digital World as Humans Do: Universal Visual Grounding for GUI Agents.arXiv preprint arXiv:2410.05243, 2024
Pith/arXiv arXiv 2024
-
[26]
Large Language Model-Brained GUI Agents: A Survey.arXiv preprint arXiv:2411.18279, 2024
Chaoyun Zhang, Shilin He, Jiaxu Qian, Bowen Li, Liqun Li, Si Qin, Yu Kang, Minghua Ma, Guyue Liu, Qingwei Lin, et al. Large Language Model-Brained GUI Agents: A Survey.arXiv preprint arXiv:2411.18279, 2024
Pith/arXiv arXiv 2024
-
[27]
OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, et al. OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5555–5579, 2025. 11
2025
-
[28]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
2023
-
[29]
Aria-UI: Visual Grounding for GUI Instructions
Yuhao Yang, Yue Wang, Dongxu Li, Ziyang Luo, Bei Chen, Chao Huang, and Junnan Li. Aria-UI: Visual Grounding for GUI Instructions. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22418–22433, 2025
2025
-
[30]
Longxi Gao, Li Zhang, and Mengwei Xu. UIShift: Enhancing VLM-based GUI Agents through Self- supervised Reinforcement Learning.arXiv preprint arXiv:2505.12493, 2025
arXiv 2025
-
[31]
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception.arXiv preprint arXiv:2401.16158, 2024
Pith/arXiv arXiv 2024
-
[32]
UFO: A UI-Focused Agent for Windows OS Interaction
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, et al. UFO: A UI-Focused Agent for Windows OS Interaction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pag...
2025
-
[33]
AutoGLM: Autonomous Foundation Agents for GUIs.arXiv preprint arXiv:2411.00820, 2024
Xiao Liu, Bo Qin, Dongzhu Liang, Guang Dong, Hanyu Lai, Hanchen Zhang, Hanlin Zhao, Iat Long Iong, Jiadai Sun, Jiaqi Wang, et al. AutoGLM: Autonomous Foundation Agents for GUIs.arXiv preprint arXiv:2411.00820, 2024
arXiv 2024
-
[34]
Android in the Wild: A Large-Scale Dataset for Android Device Control.Advances in Neural Information Processing Systems, 36:59708–59728, 2023
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Android in the Wild: A Large-Scale Dataset for Android Device Control.Advances in Neural Information Processing Systems, 36:59708–59728, 2023
2023
-
[35]
AppAgent: Multimodal Agents as Smartphone Users
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. AppAgent: Multimodal Agents as Smartphone Users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–20, 2025
2025
-
[36]
PP-OCR: A Practical Ultra Lightweight OCR System.arXiv preprint arXiv:2009.09941, 2020
Yuning Du, Chenxia Li, Ruoyu Guo, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Zilin Yu, Yehua Yang, Qingqing Dang, et al. PP-OCR: A Practical Ultra Lightweight OCR System.arXiv preprint arXiv:2009.09941, 2020
arXiv 2009
-
[37]
Segment Anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment Anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[38]
OmniParser for Pure Vision Based GUI Agent.arXiv preprint arXiv:2408.00203, 2024
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadallah. OmniParser for Pure Vision Based GUI Agent.arXiv preprint arXiv:2408.00203, 2024
arXiv 2024
-
[39]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. UI-TARS: Pioneering Automated GUI Interaction with Native Agents. arXiv preprint arXiv:2501.12326, 2025
Pith/arXiv arXiv 2025
-
[40]
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor C˘arbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. ScreenAI: A Vision-Language Model for UI and Infographics Understanding.arXiv preprint arXiv:2402.04615, 2024
arXiv 2024
-
[41]
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. GUI-R1: A Generalist R1-Style Vision-Language Action Model For GUI Agents.arXiv preprint arXiv:2504.10458, 2025
Pith/arXiv arXiv 2025
-
[42]
Continual Learning for Generative AI: From LLMs to MLLMs and Beyond, 2025
Haiyang Guo, Fanhu Zeng, Fei Zhu, Jiayi Wang, Xukai Wang, Jingang Zhou, Hongbo Zhao, Wenzhuo Liu, Shijie Ma, Da-Han Wang, Xu-Yao Zhang, and Cheng-Lin Liu. Continual Learning for Generative AI: From LLMs to MLLMs and Beyond, 2025
2025
-
[43]
LLaV A-c: Continual Improved Visual Instruction Tuning.arXiv preprint arXiv:2506.08666, 2025
Wenzhuo Liu, Fei Zhu, Haiyang Guo, Longhui Wei, and Cheng-Lin Liu. LLaV A-c: Continual Improved Visual Instruction Tuning.arXiv preprint arXiv:2506.08666, 2025
arXiv 2025
-
[44]
RL’s Razor: Why Online Reinforcement Learning Forgets Less.arXiv preprint arXiv:2509.04259, 2025
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. RL’s Razor: Why Online Reinforcement Learning Forgets Less.arXiv preprint arXiv:2509.04259, 2025
Pith/arXiv arXiv 2025
-
[45]
RL Fine-Tuning Heals OOD Forgetting in SFT.arXiv preprint arXiv:2509.12235, 2025
Hangzhan Jin, Sitao Luan, Sicheng Lyu, Guillaume Rabusseau, Reihaneh Rabbany, Doina Precup, and Mohammad Hamdaqa. RL Fine-Tuning Heals OOD Forgetting in SFT.arXiv preprint arXiv:2509.12235, 2025. 12
Pith/arXiv arXiv 2025
-
[46]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[47]
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Guanjing Xiong, and Hongsheng Li. UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning.arXiv preprint arXiv:2503.21620, 2025
Pith/arXiv arXiv 2025
-
[48]
Yuqi Zhou, Sunhao Dai, Shuai Wang, Kaiwen Zhou, Qinglin Jia, and Jun Xu. GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents.arXiv preprint arXiv:2505.15810, 2025. 13 A Appendix A.1 Reward Function and Its Interaction with the Method. In our implementation, GUI-AC uses the same task format as Continual GUI Agents [7]. This ensur...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.