MV-Actor: Aligning Multi-View Semantics and Spatial Awareness for Bimanual Manipulation
Pith reviewed 2026-06-27 12:50 UTC · model grok-4.3
The pith
MV-Actor builds a unified semantic-spatial representation from multiple camera views to improve bimanual robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
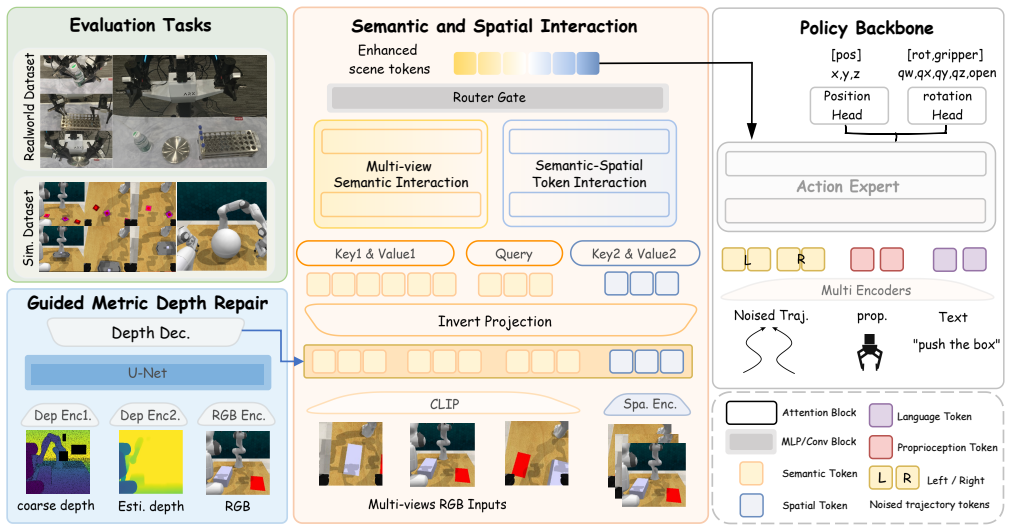
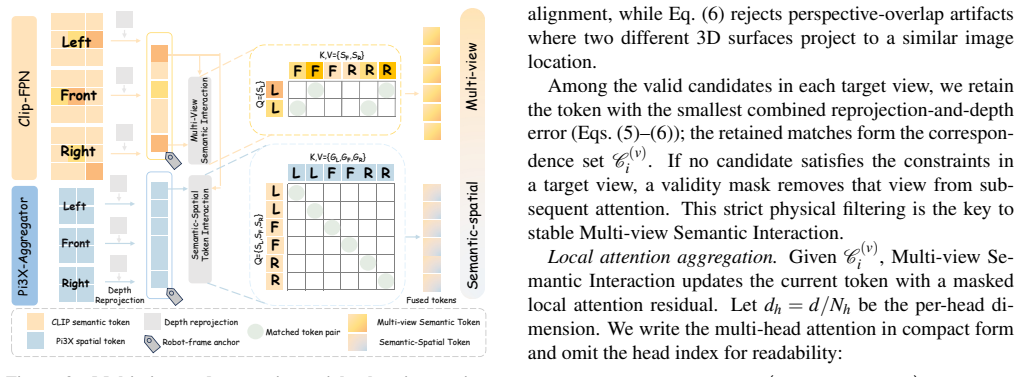
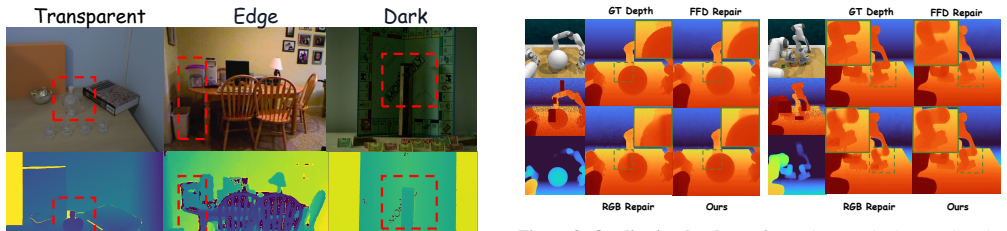
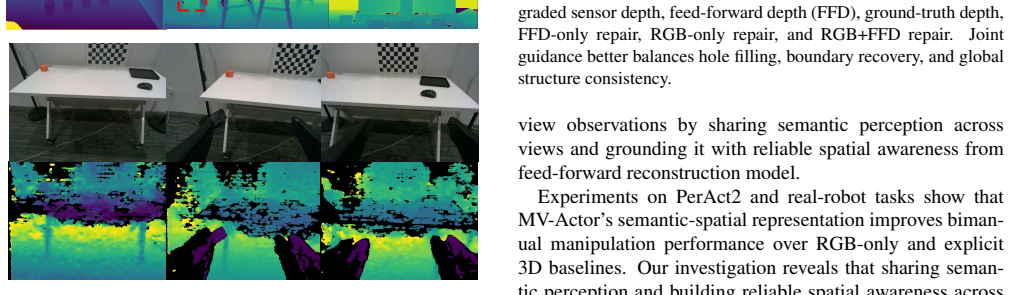
MV-Actor establishes a unified semantic-spatial representation for bimanual manipulation by first performing Multi-view Semantic Interaction to share semantic perception across views, then applying Semantic-Spatial Token Interaction to ground visual semantics with feed-forward reconstruction model features for reliable spatial awareness, and finally using a Guided Metric Depth Repair module to refine degraded sensor depth under consumer-grade noise.
What carries the argument
The three modules of Multi-view Semantic Interaction, Semantic-Spatial Token Interaction, and Guided Metric Depth Repair that together construct the unified semantic-spatial representation.
If this is right
- Bimanual policies gain higher task success rates once semantic information is actively shared across all available camera views.
- Spatial awareness remains usable even when depth sensors are unstable or consumer-grade, provided the repair module supplies metric anchors.
- Real-world deployment becomes more robust to camera motion because the framework explicitly handles viewpoint changes through the interaction modules.
- The same interaction pattern can be applied to other multi-camera manipulation setups that currently suffer from isolated view processing.
Where Pith is reading between the lines
- The approach could extend to tasks with more than two arms if the semantic interaction module is scaled to additional views without redesign.
- Replacing the reconstruction model inside the token interaction step with a different spatial prior might further reduce reliance on any single depth sensor.
- Testing the framework on longer-horizon tasks would reveal whether the unified representation maintains consistency over extended sequences.
Load-bearing premise
The three modules will combine to produce a unified semantic-spatial representation that overcomes the limits of independent view encoding and shallow fusion.
What would settle it
A controlled test on the PerAct2 benchmark in which MV-Actor without one or more of the three modules shows no improvement over independent-view or shallow-fusion baselines under frequent viewpoint changes and noisy depth.
Figures




read the original abstract
Robotic manipulation has been widely applied in industrial scenarios. Compared with single-arm manipulation, bimanual manipulation is equipped with multiple cameras to capture information from different viewpoints. However, existing multi-view policies encode each view independently or fuse view features shallowly, resulting in limited sharing semantic perception and unreliable spatial awareness. In this paper, we propose \textbf{MV-Actor}, a multi-view perception framework that builds a unified semantic-spatial representation for bimanual manipulation. First, MV-Actor performs Multi-view Semantic Interaction to share semantic perception across views. Then it uses Semantic-Spatial Token Interaction to ground visual semantics with feed-forward reconstruction model features and acquire reliable spatial awareness. Finally, a Guided Metric Depth Repair module refines degraded sensor depth to provide more reliable metric anchors under consumer-grade depth noise. In simulation experiments conducted on the PerAct2 bimanual benchmark, MV-Actor achieves a state-of-the-art average success rate of 87.8\%. In real-world evaluations with more frequent viewpoint changes and unstable consumer-grade depth, MV-Actor outperforms both RGB and RGB-D baselines, further demonstrating the benefit of sharing semantic perception and reliable spatial awareness for bimanual manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
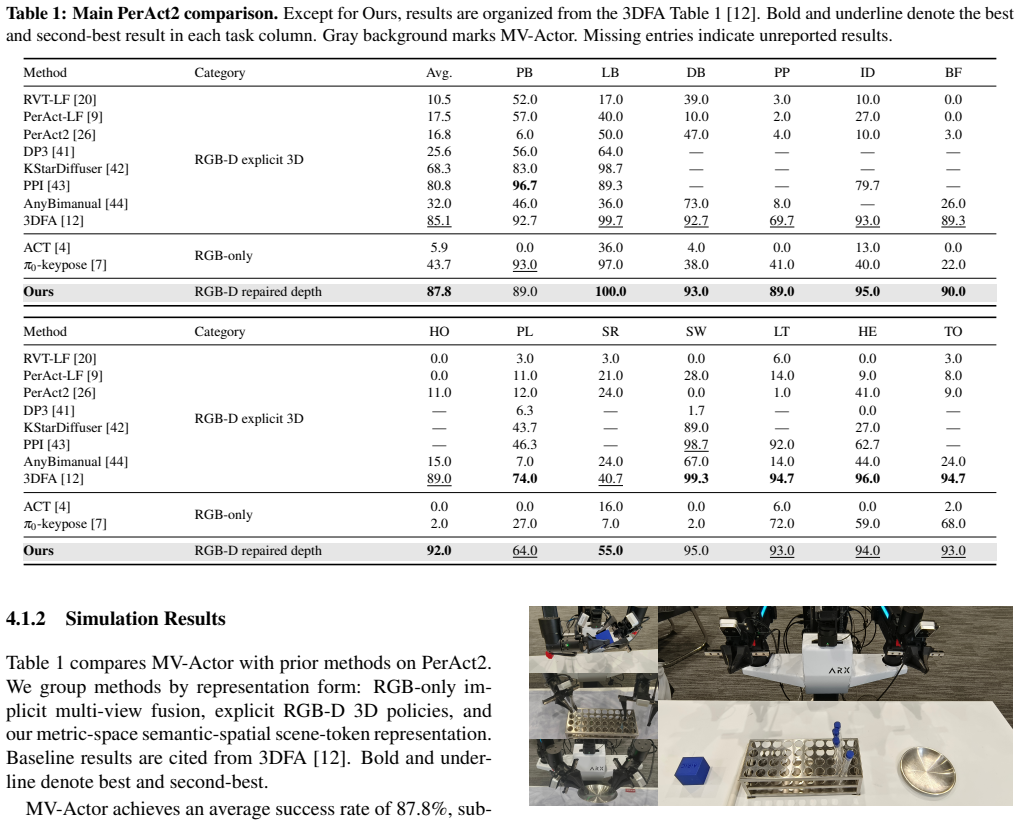
Summary. The paper proposes MV-Actor, a multi-view perception framework for bimanual robotic manipulation. It introduces three modules to build a unified semantic-spatial representation: Multi-view Semantic Interaction to share semantic perception across views, Semantic-Spatial Token Interaction to ground visual semantics with feed-forward reconstruction model features for reliable spatial awareness, and Guided Metric Depth Repair to refine degraded sensor depth under consumer-grade noise. The framework is evaluated on the PerAct2 bimanual benchmark in simulation, achieving a state-of-the-art average success rate of 87.8%, and in real-world experiments with frequent viewpoint changes and unstable depth, where it outperforms both RGB and RGB-D baselines.
Significance. If the empirical results hold after detailed validation, this work would advance multi-view policies for bimanual manipulation by showing that aligned semantic-spatial representations can overcome limitations of independent view encoding and shallow fusion, with particular relevance to robustness under viewpoint variation and noisy depth sensors. The reported performance gains in both simulation and real-world settings with consumer hardware indicate potential practical impact.
major comments (1)
- [Abstract] Abstract: The abstract states the 87.8% average success rate and outperformance over baselines but supplies no methodology details, baselines, ablation results, or error analysis, making it impossible to determine whether the data supports the central claim that the three modules produce a unified representation sufficient to overcome the stated limitations.
minor comments (2)
- The manuscript would benefit from a diagram or pseudocode clarifying the data flow and interactions among the three proposed modules.
- Ensure consistent use of terminology (e.g., 'feed-forward reconstruction model') and provide a reference or brief description for any external models used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the significance of MV-Actor. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states the 87.8% average success rate and outperformance over baselines but supplies no methodology details, baselines, ablation results, or error analysis, making it impossible to determine whether the data supports the central claim that the three modules produce a unified representation sufficient to overcome the stated limitations.
Authors: We acknowledge that the abstract is concise by design. It does provide a high-level overview of the methodology via the three named modules (Multi-view Semantic Interaction, Semantic-Spatial Token Interaction, Guided Metric Depth Repair) and explicitly states outperformance over RGB and RGB-D baselines. Full methodology details appear in Section 3, experimental setup and baselines in Section 4.1 (with results in Tables 1–2), module ablations in Section 4.3, and error/failure analysis in Section 4.4. These sections supply the evidence that the unified semantic-spatial representation addresses the limitations of independent view encoding and shallow fusion. To further address the concern, we will revise the abstract to include a brief clause on the evaluation protocol and ablation findings, subject to length constraints. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper proposes an empirical multi-view framework (MV-Actor) consisting of three described modules and validates performance via simulation benchmarks (PerAct2, 87.8% success) and real-world trials. No equations, derivations, fitted parameters, or predictions appear in the provided text. Claims rest on experimental outcomes rather than any self-referential definitions, imported uniqueness theorems, or ansatzes smuggled via self-citation. The argument is self-contained against external benchmarks with no load-bearing reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Trends and challenges in robot manipulation.Science, 364(6446):eaat8414, 2019
Aude Billard and Danica Kragic. Trends and challenges in robot manipulation.Science, 364(6446):eaat8414, 2019
2019
-
[2]
Diffusion policy: Visuomotor policy learn- ing via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shu- ran Song. Diffusion policy: Visuomotor policy learn- ing via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[3]
RT-1: Robotics Transformer for real- world control at scale.Robotics: Science and Systems XIX, pages 1–22, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. RT-1: Robotics Transformer for real- world control at scale.Robotics: Science and Systems XIX, pages 1–22, 2023
2023
-
[4]
Learning fine-grained bimanual manip- ulation with low-cost hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manip- ulation with low-cost hardware. InICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems, pages 1–22, 2023
2023
-
[5]
Mobile ALOHA: Learning bimanual mobile manipulation us- ing low-cost whole-body teleoperation
Zipeng Fu, Tony Z Zhao, and Chelsea Finn. Mobile ALOHA: Learning bimanual mobile manipulation us- ing low-cost whole-body teleoperation. InProceedings 9 of the Conference on Robot Learning (CoRL), pages 4066–4083. PMLR, 2024
2024
-
[6]
RDT-1B: a diffusion foundation model for bi- manual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: a diffusion foundation model for bi- manual manipulation. InProceedings of the Interna- tional Conference on Learning Representations (ICLR), pages 29982–30009, 2025
2025
-
[7]
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A Vision-Language-Action flow model for general robot control.arXiv preprint arXiv:2410.24164, pages 1–17, 2024
Pith/arXiv arXiv 2024
-
[8]
BFA: Best-feature-aware fusion for multi-view fine-grained manipulation.IEEE Robotics and Automation Letters, 10(9):8930–8937, 2025
Zihan Lan, Weixin Mao, Haosheng Li, Le Wang, Tian- cai Wang, Haoqiang Fan, and Osamu Yoshie. BFA: Best-feature-aware fusion for multi-view fine-grained manipulation.IEEE Robotics and Automation Letters, 10(9):8930–8937, 2025
2025
-
[9]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InProceedings of the Conference on Robot Learning (CoRL), pages 785–799. PMLR, 2023
2023
-
[10]
Act3D: 3D feature field transformers for multi-task robotic manipulation
Theophile Gervet, Zhou Xian, Nikolaos Gkanatsios, and Katerina Fragkiadaki. Act3D: 3D feature field transformers for multi-task robotic manipulation. In Proceedings of the Conference on Robot Learning (CoRL), pages 3949–3965. PMLR, 2023
2023
-
[11]
3D Diffuser Actor: Policy diffusion with 3D scene representations
Tsung-Wei Ke, Nikolaos Gkanatsios, and Katerina Fragkiadaki. 3D Diffuser Actor: Policy diffusion with 3D scene representations. InProceedings of the Con- ference on Robot Learning (CoRL), pages 1949–1974. PMLR, 2024
1949
-
[12]
Nikolaos Gkanatsios, Jiahe Xu, Matthew Bronars, Ar- salan Mousavian, Tsung-Wei Ke, and Katerina Fragki- adaki. 3D FlowMatch Actor: Unified 3D policy for single- and dual-arm manipulation.arXiv preprint arXiv:2508.11002, pages 1–23, 2025
arXiv 2025
-
[13]
Zheng Li, Pei Qu, Yufei Jia, Shihui Zhou, Haizhou Ge, Jiahang Cao, Jinni Zhou, Guyue Zhou, and Jun Ma. ManiVID-3D: Generalizable view-invariant reinforce- ment learning for robotic manipulation via disentangled 3D representations.IEEE Robotics and Automation Let- ters, 11(4):4235–4242, 2026
2026
-
[14]
DUSt3R: Geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 20697–20709, 2024
2024
-
[15]
Jiacheng Dong, Huan Li, Sicheng Zhou, Wenhao Hu, Weili Xu, and Yan Wang. MeMix: Writing less, remem- bering more for streaming 3D reconstruction.arXiv preprint arXiv:2603.15330, pages 1–19, 2026
arXiv 2026
-
[16]
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He.π 3: Permutation- equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, pages 1–17, 2025
Pith/arXiv arXiv 2025
-
[17]
Multi-view masked world models for visual robotic manipulation
Younggyo Seo, Junsu Kim, Stephen James, Kimin Lee, Jinwoo Shin, and Pieter Abbeel. Multi-view masked world models for visual robotic manipulation. InPro- ceedings of the International Conference on Machine Learning (ICML), pages 30613–30632. PMLR, 2023
2023
-
[18]
Learning view-invariant world models for visual robotic manipulation
Jing-Cheng Pang, Nan Tang, Kaiyuan Li, Yuting Tang, Xin-Qiang Cai, Zhen-Yu Zhang, Gang Niu, Masashi Sugiyama, and Yang Yu. Learning view-invariant world models for visual robotic manipulation. InProceedings of the International Conference on Learning Represen- tations (ICLR), pages 1–24, 2025
2025
-
[19]
3D-MVP: 3D multiview pretraining for manipulation
Shengyi Qian, Kaichun Mo, Valts Blukis, David F Fouhey, Dieter Fox, and Ankit Goyal. 3D-MVP: 3D multiview pretraining for manipulation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22530–22539, 2025
2025
-
[20]
RVT: Robotic view transformer for 3D object manipulation
Ankit Goyal, Jie Xu, Yijie Guo, Valts Blukis, Yu-Wei Chao, and Dieter Fox. RVT: Robotic view transformer for 3D object manipulation. InProceedings of the Conference on Robot Learning (CoRL), pages 694–710. PMLR, 2023
2023
-
[21]
RVT-2: Learning precise ma- nipulation from few demonstrations
Ankit Goyal, Valts Blukis, Jie Xu, Yijie Guo, Yu-Wei Chao, and Dieter Fox. RVT-2: Learning precise ma- nipulation from few demonstrations. InRSS Workshop: Data Generation for Robotics, pages 1–11, 2024
2024
-
[22]
Qingyu Fan, Zhaoxiang Li, Yi Lu, Wang Chen, Qiu Shen, Xiao-xiao Long, Yinghao Cai, Tao Lu, Shuo Wang, and Xun Cao. PEAfowl: Perception-enhanced multi-view Vision-Language-Action for bimanual ma- nipulation.arXiv preprint arXiv:2601.17885, pages 1– 11, 2026
arXiv 2026
-
[23]
Wenbo Hu, Jingli Lin, Yilin Long, Yunlong Ran, Li- han Jiang, Yifan Wang, Chenming Zhu, Runsen Xu, Tai Wang, and Jiangmiao Pang. G 2VLM: Geome- try grounded vision language model with unified 3D reconstruction and spatial reasoning.arXiv preprint arXiv:2511.21688, pages 1–14, 2025
arXiv 2025
-
[24]
Dy- nam3D: Dynamic layered 3D tokens empower VLM for vision-and-language navigation.Advances in Neural In- formation Processing Systems (NeurIPS), 38:153522– 153544, 2026
Zihan Wang, Seungjun Lee, and Gim Hee Lee. Dy- nam3D: Dynamic layered 3D tokens empower VLM for vision-and-language navigation.Advances in Neural In- formation Processing Systems (NeurIPS), 38:153522– 153544, 2026. 10
2026
-
[25]
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. Evo-0: Vision-Language-Action model with implicit spatial un- derstanding.arXiv preprint arXiv:2507.00416, pages 1–9, 2025
arXiv 2025
-
[26]
PerAct2: Benchmarking and learning for robotic bimanual manipulation tasks
Markus Grotz, Mohit Shridhar, Yu-Wei Chao, Tamim Asfour, and Dieter Fox. PerAct2: Benchmarking and learning for robotic bimanual manipulation tasks. In CoRL Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond, pages 1–18, 2024
2024
-
[27]
V oxAct-B: V oxel-based acting and stabilizing policy for bimanual manipulation
I-Chun Arthur Liu, Sicheng He, Daniel Seita, and Gau- rav S Sukhatme. V oxAct-B: V oxel-based acting and stabilizing policy for bimanual manipulation. InPro- ceedings of the Conference on Robot Learning (CoRL), pages 4354–4370. PMLR, 2025
2025
-
[28]
InterACT: Inter-dependency aware action chunking with hierarchical attention trans- formers for bimanual manipulation
Andrew Choong-Won Lee, Ian Chuang, Ling-Yuan Chen, and Iman Soltani. InterACT: Inter-dependency aware action chunking with hierarchical attention trans- formers for bimanual manipulation. InProceedings of the Conference on Robot Learning (CoRL), pages 1730–
-
[29]
Denois- ing diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 33:6840– 6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denois- ing diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 33:6840– 6851, 2020
2020
-
[30]
De- noising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. De- noising Diffusion Implicit Models. InProceedings of the International Conference on Learning Representa- tions (ICLR), pages 1–20, 2021
2021
-
[31]
Scalable diffu- sion models with transformers
William Peebles and Saining Xie. Scalable diffu- sion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 4195–4205, 2023
2023
-
[32]
RT-2: Vision-Language- Action models transfer web knowledge to robotic con- trol
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. RT-2: Vision-Language- Action models transfer web knowledge to robotic con- trol. InProceedings of the Conference on Robot Learn- ing (CoRL), pages 2165–2183. PMLR, 2023
2023
-
[33]
Octo: An open-source generalist robot policy
Oier Mees, Dibya Ghosh, Karl Pertsch, Kevin Black, Homer Rich Walke, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, et al. Octo: An open-source generalist robot policy. InICRA Workshop on Vision-Language Models for Navigation and Manip- ulation, pages 1–17, 2024
2024
-
[34]
OpenVLA: An open-source Vision-Language-Action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. OpenVLA: An open-source Vision-Language-Action model. InProceedings of the Conference on Robot Learning (CoRL), pages 2679–2713. PMLR, 2025
2025
-
[35]
InProceedings of the Conference on Robot Learning (CoRL), pages 17–40
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al.π 0.5: a Vision-Language-Action model with open- world generalization. InProceedings of the Conference on Robot Learning (CoRL), pages 17–40. PMLR, 2025
2025
-
[36]
Flow Matching for gen- erative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matthew Le. Flow Matching for gen- erative modeling. InProceedings of the International Conference on Learning Representations (ICLR), pages 1–28, 2023
2023
-
[37]
Autoregressive ac- tion sequence learning for robotic manipulation.IEEE Robotics and Automation Letters, 10(5):4898–4905, 2025
Xinyu Zhang, Yuhan Liu, Haonan Chang, Liam Schramm, and Abdeslam Boularias. Autoregressive ac- tion sequence learning for robotic manipulation.IEEE Robotics and Automation Letters, 10(5):4898–4905, 2025
2025
-
[38]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. InProceedings of the International Conference on Machine Learning (ICML), pages 8748–
-
[39]
U-Net: Convolutional networks for biomedical im- age segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical im- age segmentation. InProceedings of the Interna- tional Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pages 234–
-
[40]
On the continuity of rotation representations in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 5745–5753, 2019
2019
-
[41]
3D Diffusion Policy: Generalizable visuomotor policy learning via simple 3D representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3D Diffusion Policy: Generalizable visuomotor policy learning via simple 3D representations. InRSS Workshop on Dexterous Manip- ulation: Design, Perception and Control, pages 1–17, 2024
2024
-
[42]
Spatial-temporal graph diffusion policy with kinematic modeling for bimanual robotic manip- ulation
Qi Lv, Hao Li, Xiang Deng, Rui Shao, Yinchuan Li, Jianye Hao, Longxiang Gao, Michael Yu Wang, and Liqiang Nie. Spatial-temporal graph diffusion policy with kinematic modeling for bimanual robotic manip- ulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17394–17404, 2025
2025
-
[43]
Yuyin Yang, Zetao Cai, Yang Tian, Jia Zeng, and Jiang- miao Pang. Gripper keypose and object pointflow as interfaces for bimanual robotic manipulation.arXiv preprint arXiv:2504.17784, pages 1–20, 2025. 11
arXiv 2025
-
[44]
Anybimanual: Transferring unimanual policy for general bimanual ma- nipulation
Guanxing Lu, Tengbo Yu, Haoyuan Deng, Season Si Chen, Yansong Tang, and Ziwei Wang. Anybimanual: Transferring unimanual policy for general bimanual ma- nipulation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 13662–13672, 2025
2025
-
[45]
Booster: a benchmark for depth from images of specular and transparent surfaces.IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 46(1):85–102, 2023
Pierluigi Zama Ramirez, Alex Costanzino, Fabio Tosi, Matteo Poggi, Samuele Salti, Stefano Mattoccia, and Luigi Di Stefano. Booster: a benchmark for depth from images of specular and transparent surfaces.IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 46(1):85–102, 2023
2023
-
[46]
Indoor segmentation and support inference from RGBD images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from RGBD images. InProceedings of the European Conference on Computer Vision (ECCV), pages 746–
-
[47]
A taxonomy and evaluation of dense two-frame stereo correspon- dence algorithms.International Journal of Computer Vision, 47(1):7–42, 2002
Daniel Scharstein and Richard Szeliski. A taxonomy and evaluation of dense two-frame stereo correspon- dence algorithms.International Journal of Computer Vision, 47(1):7–42, 2002
2002
-
[48]
Depth map artefacts reduction: A review.IET Image Processing, 14(12):2630–2644, 2020
Mostafa Mahmoud Ibrahim, Qiong Liu, Rizwan Khan, Jingyu Yang, Ehsan Adeli, and You Yang. Depth map artefacts reduction: A review.IET Image Processing, 14(12):2630–2644, 2020
2020
-
[49]
MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xi- ang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 5261–5271, 2025
2025
-
[50]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 770– 778, 2016
2016
-
[51]
Feature pyra- mid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyra- mid networks for object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2117–2125, 2017. 12 SUPPLEMENTARY MA TERIAL A. Module-Level Implementation Details Semantic tokens and anchorsFrozen...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.