Conservation Laws from Data Symmetry in Neural Networks
Pith reviewed 2026-06-27 13:52 UTC · model grok-4.3
The pith
Data symmetries do not generically induce extra conserved quantities during neural network gradient-flow training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
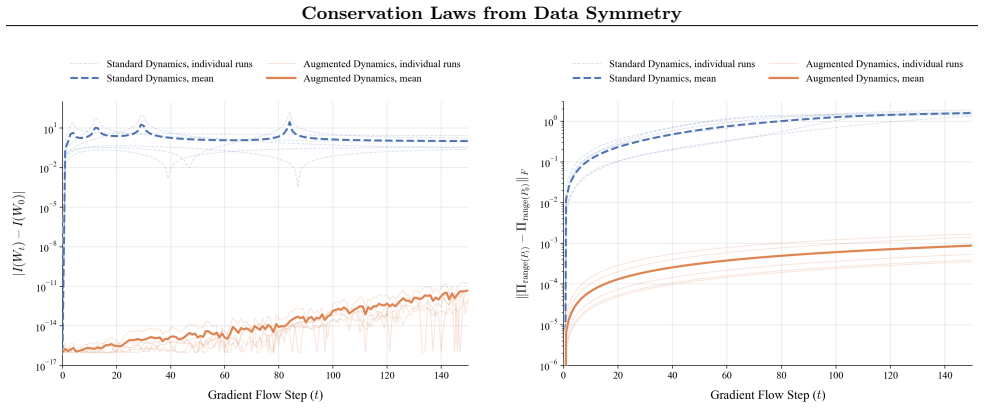
Under the assumption that the loss function is analytic and non-polynomial, data symmetries generically do not induce any additional integrals of motion. For mean squared error loss, there are situations in which data augmentation yields extra conserved quantities. The authors introduce tensorizable networks to characterize the architectures and losses for which this occurs.
What carries the argument
Tensorizable networks, a family of architectures in which dependence on parameters and inputs can be separated using an intermediate representation.
Load-bearing premise
The loss function is analytic and non-polynomial.
What would settle it
Finding an analytic non-polynomial loss function together with a data symmetry that produces an observable extra integral of motion during gradient flow would falsify the generic negative claim.
Figures

read the original abstract
We explore whether intrinsic symmetries of the training data lead to conserved quantities during gradient-flow training of neural networks. Under the assumption that the loss function is analytic and non-polynomial, we prove that data symmetries generically do not induce any additional integrals of motion. For mean squared error (MSE) loss, on the other hand, there are situations in which data augmentation yields extra conserved quantities. We build a framework, utilizing \emph{tensorizable networks} to describe this phenomenon. Tensorizable networks are a family of architectures whose dependence on parameters and inputs can be separated using an intermediate representation. They include linear and polynomial networks, as well as Lightning Attention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript explores whether intrinsic symmetries of the training data induce conserved quantities during gradient-flow training of neural networks. Under the assumption that the loss function is analytic and non-polynomial, it proves that data symmetries generically do not induce any additional integrals of motion. For mean squared error (MSE) loss, however, there are situations in which data augmentation yields extra conserved quantities; these are characterized via a framework of tensorizable networks (whose parameter and input dependence can be separated via an intermediate representation), which includes linear and polynomial networks as well as Lightning Attention.
Significance. If the central claims hold, the work provides a precise distinction between loss classes regarding the emergence of conservation laws from data symmetries, together with a new architectural framework for the positive (MSE) case. The explicit conditioning on analytic non-polynomial losses and the separate treatment of MSE are strengths; the paper also supplies a mathematical proof under stated assumptions rather than empirical fitting.
minor comments (3)
- §2 (or wherever the tensorizable-network definition appears): the separation of parameter and input dependence via the intermediate representation should be stated as a formal definition with explicit conditions on the intermediate map, to make the scope of the framework unambiguous for readers outside the authors' immediate circle.
- The phrase 'generically' in the main negative result is used without a preceding sentence that recalls the precise measure or topology with respect to which genericity is taken; adding one sentence would improve readability without altering the argument.
- Figure captions (or the Lightning Attention example) could usefully include a one-sentence reminder of which loss is being used, to avoid any momentary confusion between the generic and MSE cases.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and for recommending minor revision. The provided summary accurately captures our central results on the distinction between analytic non-polynomial losses (where data symmetries generically yield no additional conserved quantities) and the MSE case (where tensorizable networks can produce extra integrals of motion).
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a mathematical proof under the explicit assumption that the loss function is analytic and non-polynomial, showing that data symmetries generically do not induce additional integrals of motion, with a separate case for MSE loss handled via the tensorizable networks framework. No load-bearing steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the central claims are conditioned on stated assumptions and appear self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The loss function is analytic and non-polynomial
invented entities (1)
-
tensorizable networks
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Abide by the law and follow the flow: Conservation laws for gradient flows , author=. Advances in neural information processing systems , volume=
-
[2]
arXiv preprint arXiv:2405.12888 , year=
Keep the momentum: Conservation laws beyond Euclidean gradient flows , author=. arXiv preprint arXiv:2405.12888 , year=
-
[3]
Convergence of Large Margin Separable Linear Classification , url =
Zhang, Tong , booktitle =. Convergence of Large Margin Separable Linear Classification , url =
-
[4]
International Conference on Machine Learning , pages=
Hidden symmetries of ReLU networks , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[5]
arXiv preprint arXiv:1312.6120 , year=
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks , author=. arXiv preprint arXiv:1312.6120 , year=
-
[6]
Advances in neural information processing systems , volume=
Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced , author=. Advances in neural information processing systems , volume=
-
[7]
arXiv preprint arXiv:1810.02032 , year=
Gradient descent aligns the layers of deep linear networks , author=. arXiv preprint arXiv:1810.02032 , year=
-
[8]
International conference on machine learning , pages=
Group equivariant convolutional networks , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[9]
arXiv preprint arXiv:2104.13478 , year=
Geometric deep learning: Grids, groups, graphs, geodesics, and gauges , author=. arXiv preprint arXiv:2104.13478 , year=
-
[10]
Journal of Machine Learning Research , volume=
A group-theoretic framework for data augmentation , author=. Journal of Machine Learning Research , volume=
-
[11]
Advances in neural information processing systems , volume=
Scalars are universal: Equivariant machine learning, structured like classical physics , author=. Advances in neural information processing systems , volume=
-
[12]
arXiv preprint, arXiv:2005.00178 , year=
On the benefits of invariance in neural networks , author=. arXiv preprint, arXiv:2005.00178 , year=
arXiv 2005
-
[13]
Advances in Neural Information Processing Systems , volume=
On the implicit bias of linear equivariant steerable networks , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Conference on Learning Theory , pages=
Learning with invariances in random features and kernel models , author=. Conference on Learning Theory , pages=. 2021 , organization=
2021
-
[15]
Transactions on Machine Learning Research , year=
Optimization dynamics of equivariant and augmented neural networks , author=. Transactions on Machine Learning Research , year=
-
[16]
2025 International Conference on Sampling Theory and Applications (SampTA) , pages=
Data augmentation and regularization for learning group equivariance , author=. 2025 International Conference on Sampling Theory and Applications (SampTA) , pages=. 2025 , organization=
2025
-
[17]
2013 , publisher=
Representation theory: a first course , author=. 2013 , publisher=
2013
-
[18]
1946 , publisher=
The classical groups: their invariants and representations , author=. 1946 , publisher=
1946
-
[19]
arXiv preprint arXiv:2506.13714 , year=
Understanding Learning Invariance in Deep Linear Networks , author=. arXiv preprint arXiv:2506.13714 , year=
-
[20]
arXiv preprint arXiv:2104.05508 , year=
Noether: The more things change, the more stay the same , author=. arXiv preprint arXiv:2104.05508 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Noether’s learning dynamics: Role of symmetry breaking in neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
arXiv preprint arXiv:2012.04728 , year=
Neural mechanics: Symmetry and broken conservation laws in deep learning dynamics , author=. arXiv preprint arXiv:2012.04728 , year=
arXiv 2012
-
[23]
arXiv preprint arXiv:2210.17216 , year=
Symmetries, flat minima, and the conserved quantities of gradient flow , author=. arXiv preprint arXiv:2210.17216 , year=
-
[24]
International Conference on Learning Representations , year=
A Convergence Analysis of Gradient Descent for Deep Linear Neural Networks , author=. International Conference on Learning Representations , year=
-
[25]
Information and Inference: A Journal of the IMA , volume=
Learning deep linear neural networks: Riemannian gradient flows and convergence to global minimizers , author=. Information and Inference: A Journal of the IMA , volume=. 2022 , publisher=
2022
-
[26]
Constructive Approximation , volume=
Neural network identifiability for a family of sigmoidal nonlinearities , author=. Constructive Approximation , volume=. 2022 , publisher=
2022
-
[27]
The Fourteenth International Conference on Learning Representations , year=
Learning on a razor’s edge: Identifiability and singularity of polynomial neural networks , author=. The Fourteenth International Conference on Learning Representations , year=
-
[28]
arXiv preprint arXiv:2601.21645 , year=
Identifiable Equivariant Networks are Layerwise Equivariant , author=. arXiv preprint arXiv:2601.21645 , year=
-
[29]
arXiv preprint arXiv:2408.17221 , year=
Geometry of lightning self-attention: Identifiability and dimension , author=. arXiv preprint arXiv:2408.17221 , year=
-
[30]
parametric equivalence of ReLU networks , author=
Functional vs. parametric equivalence of ReLU networks , author=. International conference on learning representations , year=
-
[31]
2003 , publisher=
Linear algebra and its applications , author=. 2003 , publisher=
2003
-
[32]
arXiv preprint arXiv:2501.18915 , year=
Algebra Unveils Deep Learning--An Invitation to Neuroalgebraic Geometry , author=. arXiv preprint arXiv:2501.18915 , year=
-
[33]
arXiv preprint arXiv:2603.29566 , year=
The Geometry of Polynomial Group Convolutional Neural Networks , author=. arXiv preprint arXiv:2603.29566 , year=
-
[34]
Nachrichten von der Gesellschaft der Wissenschaften zu Göttingen, Mathematisch-Physikalische Klasse , pages =
-
[35]
arXiv preprint arXiv:2605.03601 , year=
Most ReLU Networks Admit Identifiable Parameters , author=. arXiv preprint arXiv:2605.03601 , year=
-
[36]
arXiv preprint math-ph/0609050 , year=
How to generate random matrices from the classical compact groups , author=. arXiv preprint math-ph/0609050 , year=
-
[37]
Experimental mathematics , volume=
Packing lines, planes, etc.: Packings in Grassmannian spaces , author=. Experimental mathematics , volume=. 1996 , publisher=
1996
-
[38]
Characterizing
Gunasekar, Suriya and Lee, Jason and Soudry, Daniel and Srebro, Nathan , month = jul, year =. Characterizing. Proceedings of the 35th
-
[39]
Understanding deep learning (still) requires rethinking generalization , volume =. Commun. ACM , author =. 2021 , pages =. doi:10.1145/3446776 , abstract =
-
[40]
Implicit
Arora, Sanjeev and Cohen, Nadav and Hu, Wei and Luo, Yuping , year =. Implicit. Advances in
-
[41]
Neyshabur, Behnam and Tomioka, Ryota and Srebro, Nathan , month = apr, year =. In. doi:10.48550/arXiv.1412.6614 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6614
-
[42]
Soudry, Daniel and Hoffer, Elad and Nacson, Mor Shpigel and Gunasekar, Suriya and Srebro, Nathan , month = oct, year =. The. doi:10.48550/arXiv.1710.10345 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.