RoVE: Rotary Value Embeddings Attention for Relative Position-dependent Value Pathways
Pith reviewed 2026-06-27 13:49 UTC · model grok-4.3
The pith
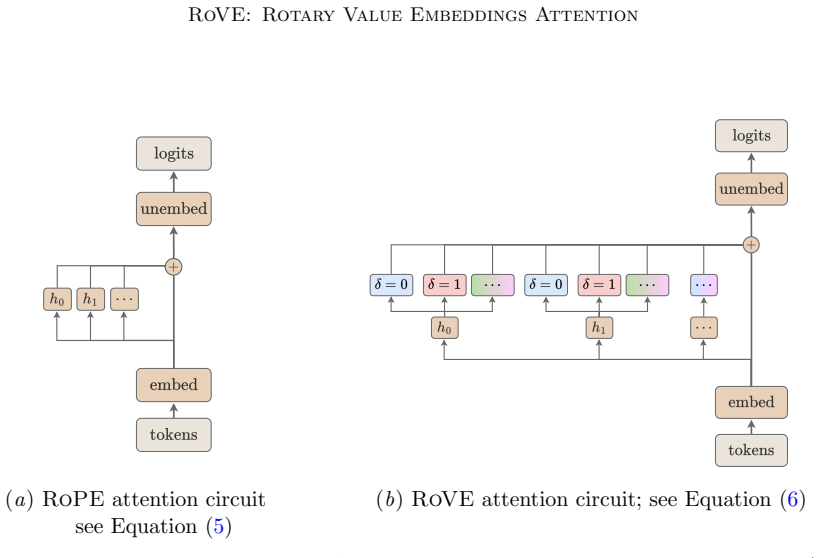
RoVE rotates value embeddings with keys to add relative position dependence to the value pathway in RoPE attention without extra parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Rotating value embeddings simultaneously with keys turns RoPE attention into attentive convolution by making the value pathway position-dependent, which produces consistent improvements on few-shot in-context learning, out-of-distribution perplexity, and long-context retrieval in 124M and 354M GPT-2 models.
What carries the argument
Simultaneous rotation of value embeddings together with key embeddings, which creates a relative position-dependent value pathway.
If this is right
- The change yields measurable gains on few-shot in-context learning tasks.
- Out-of-distribution perplexity decreases compared with baseline RoPE.
- Long-context retrieval improves, with largest benefits on tasks requiring long-range aggregation.
- The operation unifies independent formulations of attentive convolution across computer vision, robotics, and LLM architectures.
Where Pith is reading between the lines
- The same rotation trick could be tested on other relative position methods besides RoPE.
- The attentive-convolution view suggests the method may transfer directly to vision or robotics transformers that already use similar operations.
- Scaling the approach to models larger than 354M could increase the observed advantage on long-sequence tasks.
Load-bearing premise
That rotating the value embeddings at the same time as the keys will create a useful position-dependent value pathway without causing instability or unwanted side effects in the attention scores.
What would settle it
An ablation where value embeddings receive the same rotation as keys yet long-context retrieval accuracy stays the same or drops relative to standard RoPE.
Figures

read the original abstract
Rotary Position Embeddings (RoPE) make attention scores position-relative but leave the value pathway position-blind: the message sent by a value token is the same regardless of its distance from the query. We propose RoVE, a parameter-free modification that makes values position-sensitive by rotating them simultaneously with keys, and show that it turns RoPE attention into attentive convolution. This new perspective unifies several independent formulations of the same operation across computer vision, robotics, and modern LLM architectures. Trained 124M and 354M GPT-2 models show consistent empirical gains over RoPE on few-shot in-context learning, out-of-distribution perplexity, and long-context retrieval, with the clearest improvements on tasks that require long-range aggregation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RoVE, a parameter-free modification to Rotary Position Embeddings (RoPE) that rotates value embeddings simultaneously with keys to introduce relative position dependence into the value pathway. This is claimed to convert standard RoPE attention into attentive convolution and unifies independent formulations across computer vision, robotics, and modern LLM architectures. Experiments on 124M and 354M GPT-2 models report consistent empirical gains over RoPE on few-shot in-context learning, out-of-distribution perplexity, and long-context retrieval, with strongest effects on long-range aggregation tasks.
Significance. If the central claim holds, the work supplies a zero-parameter route to position-sensitive value pathways, which may improve long-range modeling in transformers while preserving model size. The unification across domains and the parameter-free construction are explicit strengths that could aid interpretability and adoption.
major comments (1)
- Abstract: the central claim that simultaneously rotating value embeddings with keys yields a stable, beneficial position-dependent value pathway without unintended interactions in the attention computation is load-bearing but receives no derivation, equation, or stability analysis; this must be supplied with explicit justification to support the unification and empirical claims.
minor comments (1)
- The abstract states empirical gains on specific tasks but supplies no controls, baselines, or variance measures; adding a brief reference to these in the main text would strengthen readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the clear identification of a point that strengthens the presentation. We address the single major comment below and commit to revisions that supply the requested explicit justification while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: Abstract: the central claim that simultaneously rotating value embeddings with keys yields a stable, beneficial position-dependent value pathway without unintended interactions in the attention computation is load-bearing but receives no derivation, equation, or stability analysis; this must be supplied with explicit justification to support the unification and empirical claims.
Authors: We agree that the abstract, being concise, does not itself contain the derivation. The full manuscript (Section 3) derives the RoVE modification explicitly: the value rotation is applied identically to the key rotation, yielding attention scores of the form q_i^T R_{j-i} k_j and value contributions v_j rotated by the same relative angle, which algebraically reduces to a position-dependent convolution kernel without additional parameters or cross-term instabilities. A short stability argument follows from the unitary property of the rotation matrices, preserving norm and avoiding the explosion or vanishing that would occur with non-orthogonal transformations. To meet the referee's request we will (i) insert a compact equation into the abstract and (ii) add a one-sentence pointer to the Section 3 derivation and stability note. These changes directly support the unification and empirical sections without altering any claims or results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes RoVE as a direct, parameter-free modification to existing RoPE by simultaneously rotating value embeddings with keys, explicitly framed as turning RoPE attention into attentive convolution. This is a constructive change rather than a derivation that reduces to fitted inputs or self-definitions. The unification is presented as a perspective linking independent prior formulations across domains, with empirical validation on trained GPT-2 models. No load-bearing self-citations, ansatz smuggling, or predictions equivalent to inputs by construction appear in the provided claims or abstract. The method is self-contained as an architectural extension against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zoology: Measuring and improving recall in efficient language models
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Y Zou, Atri Rudra, and Christopher R´ e. Zoology: Measuring and improving recall in efficient language models. InInternational conference on learning representations, volume 2024, pages 15664–15730,
2024
-
[2]
Federico Barbero, Alex Vitvitskyi, Christos Perivolaropoulos, Razvan Pascanu, and Petar Veliˇ ckovi´ c. Round and round we go! what makes rotary positional encodings useful? arXiv preprint arXiv:2410.06205,
-
[3]
5 Garc´ıa-Castellanos, Weiler & Bekkers Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse...
1901
-
[4]
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending con- text window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595,
-
[5]
Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509,
Pith/arXiv arXiv 1904
-
[6]
On the relationship between self-attention and convolutional layers.arXiv preprint arXiv:1911.03584,
Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self-attention and convolutional layers.arXiv preprint arXiv:1911.03584,
arXiv 1911
-
[7]
Longrope: Extending llm context window beyond 2 million tokens.arXiv preprint arXiv:2402.13753,
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. Longrope: Extending llm context window beyond 2 million tokens.arXiv preprint arXiv:2402.13753,
-
[8]
https://transformer- circuits.pub/2021/framework/index.html. Daniel Y. Fu, Tri Dao, Khaled K. Saab, Armin W. Thomas, Atri Rudra, and Christopher R´ e. Hungry Hungry Hippos: Towards language modeling with state space models. In International Conference on Learning Representations, 2023a. Daniel Y. Fu, Elliot L. Epstein, Eric Nguyen, Armin W. Thomas, Michae...
arXiv 2021
-
[9]
Anand Gopalakrishnan, Robert Csord´ as, J¨ urgen Schmidhuber, and Michael C Mozer
URLhttps://proceedings.neurips.cc/paper_files/paper/2020/hash/ 15231a7ce4ba789d13b722cc5c955834-Abstract.html. Anand Gopalakrishnan, Robert Csord´ as, J¨ urgen Schmidhuber, and Michael C Mozer. De- coupling the” what” and” where” with polar coordinate positional embeddings.arXiv preprint arXiv:2509.10534,
Pith/arXiv arXiv 2020
-
[10]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654,
-
[11]
URLhttp://arxiv.org/abs/ 2407.09941. arXiv:2407.09941 [cs]. David Klee, Boce Hu, Andrew Cole, Heng Tian, Dian Wang, Robert Platt, and Robin Walters. RAVEN: End-to-end equivariant robot learning with RGB cameras. InThe Fourteenth International Conference on Learning Representations,
-
[12]
Functional interpolation for relative positions improves long context transformers
Shanda Li, Chong You, Guru Guruganesh, Joshua Ainslie, Santiago Ontanon, Manzil Za- heer, Sumit Sanghai, Yiming Yang, Sanjiv Kumar, and Srinadh Bhojanapalli. Functional interpolation for relative positions improves long context transformers. InInternational Conference on Learning Representations, volume 2024, pages 11303–11328, 2024b. Peter Lippmann, Gerr...
2024
-
[13]
co/datasets/HuggingFaceFW/fineweb-edu
URLhttps://huggingface. co/datasets/HuggingFaceFW/fineweb-edu. Takeru Miyato, Bernhard Jaeger, Max Welling, and Andreas Geiger. Gta: A geometry- aware attention mechanism for multi-view transformers. InInternational Conference on Learning Representations, volume 2024, pages 8172–8208,
2024
-
[14]
GitHub repository. Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Przemyslaw Kazienko, Jan Kocon, and Jiaming et al. Kong. Rwkv: Reinventing rnns for the transformer era.arXiv:2305.13048,
-
[15]
Yarn: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. InInternational Conference on Learning Representations, volume 2024, pages 31932–31951,
2024
-
[16]
URLhttp://arxiv.org/abs/2302.10866. arXiv:2302.10866 [cs]. Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409,
-
[17]
URLhttp://arxiv.org/abs/ 2002.03830. arXiv:2002.03830 [cs]. 8 RoVE: Rotary Value Embeddings Attention Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
arXiv 2002
-
[18]
Mrrope: Mixed-radix rotary position embedding.arXiv preprint arXiv:2601.22181,
Qingyuan Tian, Wenhong Zhu, Xiaoran Liu, Xiaofeng Wang, and Rui Wang. Mrrope: Mixed-radix rotary position embedding.arXiv preprint arXiv:2601.22181,
-
[19]
URLhttp: //arxiv.org/abs/2601.15275. arXiv:2601.15275 [cs]. Chuanyang Zheng, Yihang Gao, Han Shi, Jing Xiong, Jiankai Sun, Jingyao Li, Minbin Huang, Xiaozhe Ren, Michael Ng, Xin Jiang, et al. Dape v2: Process attention score as feature map for length extrapolation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (...
-
[20]
Full Experimental Results A.1
9 Garc´ıa-Castellanos, Weiler & Bekkers Appendix A. Full Experimental Results A.1. Setup Models:We train two GPT-2-style transformers in the nanoGPT framework (nanoGPT, 2022). Thesmallmodel (≈124M parameters) has 12 layers, 12 attention heads, and em- bedding dimension 768; themediummodel (≈354M parameters) has 24 layers, 16 heads, and embedding dimension
2022
-
[21]
Theonlyarchitectural difference between theRoPEandRoVEconditions is the value pathway; all other architectural and training hyperparameters are held fixed. Training:Both models are trained for one epoch on FineWebEdu-10B (≈10B tokens of educational web text tokenised with the GPT-2 tiktoken encoder) (Lozhkov et al., 2024), with a sequence length of 1024 t...
2024
-
[22]
positional interpolation at inference time without any fine-tuning, where the frequency modulation is applied to all rotation matrices, covering both the QK- and OV-circuits. •RULER long-context retrieval.We evaluate on four RULER synthetic tasks (Hsieh et al., 2024), namely Common Word Extraction (CWE), multi-key Needle-in-a-Haystack (NIAH), Question Ans...
2024
-
[23]
what” and “where
add a fixed or learned vectorp i to each token embedding before projection, yielding scores Aape ij = (WQ(xi +p i))⊤(WK(xj +p j)), which depend on the absolute indicesiandjseparately, making extrapolation to unseen lengths fragile. •Additive relative encodings(ARPE; Raffel et al. 2020; Press et al. 2021; Chi et al. 2022; Li et al. 2024b) replace the absol...
2020
-
[24]
formalises this through a polar decomposition of (4), identifying a content-dependent phase cross-term that entangles positional and semantic information, which is replaced by pure-magnitude representations to yield a score that factors into a content product and a positional cosine, improving perplexity and length generalisation. These works restructure ...
2019
-
[25]
However, the operation requires materialising the fulln×nscore tensor before softmax, ruling outFlashAttention
takes a complementary approach, applying a narrow convolution kernel across heads over the pre-softmax score tensor (on top of a standard ad- ditive positional bias), and shows that this convolution component alone provably suffices for associative recall even when the bias is zeroed out. However, the operation requires materialising the fulln×nscore tens...
2023
-
[26]
direct path
takes this frequency-dependent logic to its principled con- clusion by treating each dimension according to its wavelengthλ m = 2π/ω m relative to the training contextL. Dimensions withλ m ≪Lcomplete many full rotations within the training window; their angles are robustly periodic and can therefore be safelyextrapolated (left unscaled) at inference time....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.