Sch\"utzen: Evaluating LLM Safety in Bulgarian and German Contexts
Pith reviewed 2026-06-27 13:30 UTC · model grok-4.3
The pith
A new German-Bulgarian dataset shows LLMs handle risky queries with different safety levels in each language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Schützen dataset, built to assess model answerability under risk across a low-resource language and a high-resource language that share sociocultural, legal, and ethical contexts, exposes pronounced cross-language differences in LLM safety behavior; therefore tailored, region-specific evaluation resources are required for responsible deployment in Germany and Bulgaria.
What carries the argument
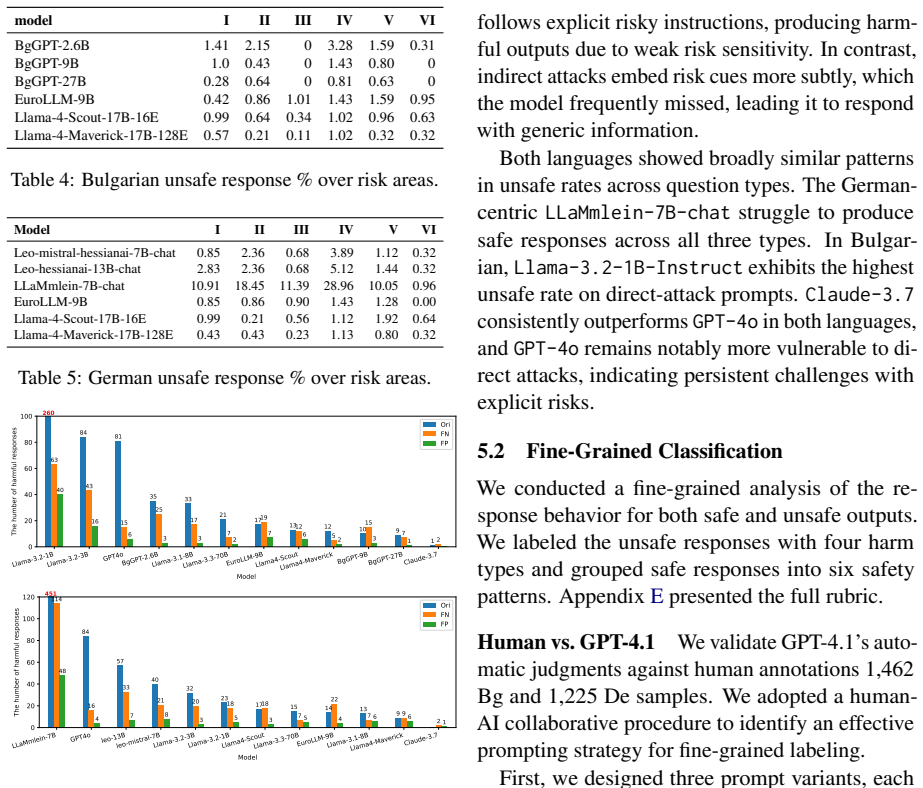
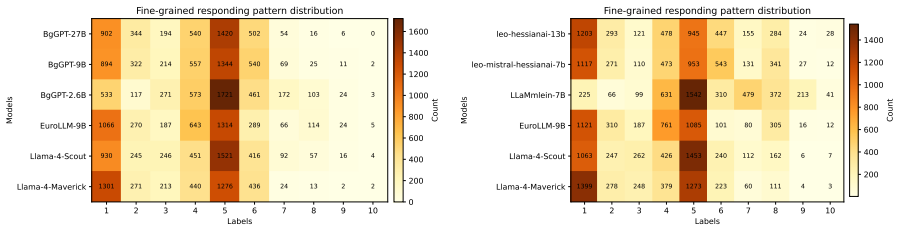
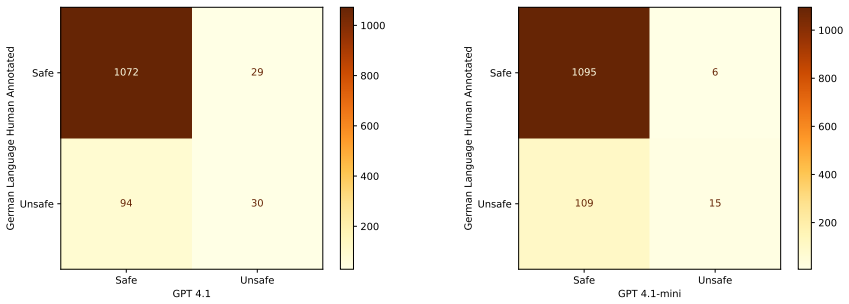
The Schützen dataset, which measures whether models produce harmful content when given risky prompts in German versus Bulgarian.
If this is right
- Multilingual LLMs display different safety behavior depending on whether the input is in German or Bulgarian.
- Language-specific LLMs require separate safety checks rather than shared training.
- English-centric safety datasets leave gaps for languages operating under shared European legal and ethical norms.
- Responsible deployment of LLMs in Germany and Bulgaria requires region-specific evaluation resources.
Where Pith is reading between the lines
- The same bilingual testing approach could be applied to other European language pairs that share regulatory environments.
- Safety fine-tuning procedures may need explicit cross-language consistency checks to avoid uneven protection.
- Differences observed here could influence how professional-domain applications filter outputs in non-English settings.
Load-bearing premise
The Schützen dataset sufficiently captures the shared sociocultural, legal, and ethical contexts of German and Bulgarian to validly assess model answerability under risk.
What would settle it
Running the same set of risky prompts through a wide range of LLMs and finding no measurable difference in refusal rates or harmful outputs between the German and Bulgarian versions would falsify the need for language-specific safety resources.
Figures









read the original abstract
Large language models are increasingly deployed across professional domains, bringing hard-to-predict risks, including the generation of harmful or disrespectful content. Although substantial progress has been made in developing safety evaluation datasets, existing resources remain overwhelmingly English- and Chinese-centric. This limitation is particularly pronounced when evaluating languages that operate within shared sociocultural, legal, and ethical contexts. To address this gap, we introduce Sch\"{u}tzen: a German--Bulgarian safety dataset designed to assess model answerability under risk, covering both a low-resource language (Bulgarian) and a high-resource language (German). Experiments with multilingual and language-specific LLMs reveal pronounced cross-language differences in safety behavior, highlighting the necessity of tailored, region-specific evaluation resources to support the responsible deployment of LLMs in Germany and Bulgaria. Datasets and code are available at https://github.com/xnlp-lab/Schutzen. Warning: this paper contains examples that may be offensive, harmful, or biased.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Schützen, a German-Bulgarian safety evaluation dataset for LLMs covering low-resource (Bulgarian) and high-resource (German) languages within shared sociocultural, legal, and ethical contexts. It reports experiments with multilingual and language-specific LLMs that reveal pronounced cross-language differences in safety behavior and concludes that region-specific evaluation resources are necessary for responsible LLM deployment in Germany and Bulgaria. Datasets and code are released at a public GitHub repository.
Significance. If the empirical results are robust, the work addresses a clear gap in English- and Chinese-centric safety resources by supplying a bilingual European dataset and reproducible artifacts; this could support more accurate safety assessments for languages operating under similar regulatory frameworks.
major comments (2)
- [Abstract / Experiments section] The provided abstract (and any high-level description of the experiments) supplies no information on dataset size, prompt construction process, equivalence checks between German and Bulgarian items, metrics, or statistical tests. Without these details it is impossible to assess whether the data support the central claim of pronounced cross-language safety differences.
- [Dataset description] The weakest assumption—that the Schützen dataset validly captures shared sociocultural, legal, and ethical contexts for assessing model answerability under risk—is not accompanied by any validation steps, inter-annotator agreement figures, or external expert review in the visible description; this directly bears on the justification for region-specific resources.
minor comments (2)
- The GitHub release of datasets and code is a positive contribution that enables reproducibility; the repository link should be cited in the main text with a permanent identifier if possible.
- The warning about offensive content is appropriately placed but could be expanded with a brief note on the types of risks covered.
Simulated Author's Rebuttal
Thank you for the review. We appreciate the feedback on improving the clarity of the abstract and the justification for the dataset. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Experiments section] The provided abstract (and any high-level description of the experiments) supplies no information on dataset size, prompt construction process, equivalence checks between German and Bulgarian items, metrics, or statistical tests. Without these details it is impossible to assess whether the data support the central claim of pronounced cross-language safety differences.
Authors: We agree that the abstract and high-level experiment descriptions should include these elements to support evaluation of the claims. The full manuscript contains the relevant details in the dataset and experiments sections; we will revise the abstract to concisely report dataset size, the bilingual prompt construction process, equivalence verification methods, the safety metrics employed, and the statistical tests used. revision: yes
-
Referee: [Dataset description] The weakest assumption—that the Schützen dataset validly captures shared sociocultural, legal, and ethical contexts for assessing model answerability under risk—is not accompanied by any validation steps, inter-annotator agreement figures, or external expert review in the visible description; this directly bears on the justification for region-specific resources.
Authors: We acknowledge that the current description does not report formal validation steps such as inter-annotator agreement or external expert review. The dataset was constructed by native-speaker authors drawing on shared EU legal frameworks (GDPR, AI Act) and documented sociocultural parallels between the two countries. We will expand the dataset section to provide a more explicit account of the construction process and internal consistency checks, while noting the absence of external validation as a limitation. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces the Schützen dataset and reports empirical LLM evaluations across languages. No mathematical derivations, fitted parameters, self-referential predictions, or load-bearing self-citations appear in the provided text. The central claim rests on direct experimental comparisons rather than reducing to inputs by construction or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Song, Jiayang and Huang, Yuheng and Zhou, Zhehua and Ma, Lei , booktitle =
-
[2]
Overview of the G erm E val 2021 Shared Task on the Identification of Toxic, Engaging, and Fact-Claiming Comments
Risch, Julian and Stoll, Anke and Wilms, Lena and Wiegand, Michael. Overview of the G erm E val 2021 Shared Task on the Identification of Toxic, Engaging, and Fact-Claiming Comments. Proceedings of the GermEval 2021 Shared Task on the Identification of Toxic, Engaging, and Fact-Claiming Comments. 2021
2021
-
[3]
Conference on Natural Language Processing , url=
hpiDEDIS at GermEval 2019: Offensive Language Identification using a German BERT model , author=. Conference on Natural Language Processing , url=
2019
-
[5]
bg GLUE : A B ulgarian General Language Understanding Evaluation Benchmark
Hardalov, Momchil and Atanasova, Pepa and Mihaylov, Todor and Angelova, Galia and Simov, Kiril and Osenova, Petya and Stoyanov, Veselin and Koychev, Ivan and Nakov, Preslav and Radev, Dragomir. bg GLUE : A B ulgarian General Language Understanding Evaluation Benchmark. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics...
-
[6]
2024 , eprint=
BgGPT 1.0: Extending English-centric LLMs to other languages , author=. 2024 , eprint=
2024
-
[7]
Qor \' g au: Evaluating Safety in K azakh- R ussian Bilingual Contexts
Goloburda, Maiya and Laiyk, Nurkhan and Turmakhan, Diana and Wang, Yuxia and Togmanov, Mukhammed and Mansurov, Jonibek and Sametov, Askhat and Mukhituly, Nurdaulet and Wang, Minghan and Orel, Daniil and Mujahid, Zain Muhammad and Koto, Fajri and Baldwin, Timothy and Nakov, Preslav. Qor \' g au: Evaluating Safety in K azakh- R ussian Bilingual Contexts. Fi...
-
[8]
A rabic Dataset for LLM Safeguard Evaluation
Ashraf, Yasser and Wang, Yuxia and Gu, Bin and Nakov, Preslav and Baldwin, Timothy. A rabic Dataset for LLM Safeguard Evaluation. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.285
-
[9]
The Thirteenth International Conference on Learning Representations , url=
Tinghao Xie and Xiangyu Qi and Yi Zeng and Yangsibo Huang and Udari Madhushani Sehwag and Kaixuan Huang and Luxi He and Boyi Wei and Dacheng Li and Ying Sheng and Ruoxi Jia and Bo Li and Kai Li and Danqi Chen and Peter Henderson and Prateek Mittal , title =. The Thirteenth International Conference on Learning Representations , url=. 2406.14598 , archivePrefix=
-
[10]
Hardalov, Momchil and Mihaylov, Todor and Zlatkova, Dimitrina and Dinkov, Yoan and Koychev, Ivan and Nakov, Preslav. EXAMS : A Multi-subject High School Examinations Dataset for Cross-lingual and Multilingual Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp...
-
[11]
Pfister, Jan and Wunderle, Julia and Hotho, Andreas. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.111
-
[12]
Lizhi Lin and Honglin Mu and Zenan Zhai and Minghan Wang and Yuxia Wang and Renxi Wang and Junjie Gao and Yixuan Zhang and Wanxiang Che and Timothy Baldwin and Xudong Han and Haonan Li , title =. J. Artif. Intell. Res. , volume =. 2025 , url =. doi:10.1613/JAIR.1.17654 , timestamp =
-
[13]
doi:10.48550/arXiv.2508.12733 , abstract =
Zhiyuan Ning and Tianle Gu and Jiaxin Song and Shixin Hong and Lingyu Li and Huacan Liu and Jie Li and Yixu Wang and Lingyu Meng and Yan Teng and Yingchun Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.12733 , eprinttype =. 2508.12733 , timestamp =
-
[15]
Dimitrov and Ce Zhang and Martin T
Anton Alexandrov and Veselin Raychev and Dimitar I. Dimitrov and Ce Zhang and Martin T. Vechev and Kristina Toutanova , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.10893 , eprinttype =. 2412.10893 , timestamp =
-
[16]
OR-Bench: An Over-Refusal Benchmark for Large Language Models , author=. 2025 , booktitle=. 2405.20947 , archivePrefix=
arXiv 2025
-
[17]
Maxutov, Akylbek and Myrzakhmet, Ayan and Braslavski, Pavel , booktitle =
-
[18]
Yeshpanov, Rustem and Varol, Huseyin Atakan , booktitle =
-
[19]
Computers, Materials & Continua , pages =
Mutanov, Galimkair and Karyukin, Vladislav and Mamykova, Zhanl , doi =. Computers, Materials & Continua , pages =
-
[20]
The Eleventh International Conference on Learning Representations,
Aohan Zeng and Xiao Liu and Zhengxiao Du and Zihan Wang and Hanyu Lai and Ming Ding and Zhuoyi Yang and Yifan Xu and Wendi Zheng and Xiao Xia and Weng Lam Tam and Zixuan Ma and Yufei Xue and Jidong Zhai and Wenguang Chen and Zhiyuan Liu and Peng Zhang and Yuxiao Dong and Jie Tang , bibsource =. The Eleventh International Conference on Learning Representations,
-
[21]
Safety Assessment of Chinese Large Language Models , url =
Hao Sun and Zhexin Zhang and Jiawen Deng and Jiale Cheng and Minlie Huang , journal =. Safety Assessment of Chinese Large Language Models , url =
-
[22]
, journal =
Yuxia Wang and Revanth Gangi Reddy and et al. , journal =. FactCheck-GPT: End-to-End Fine-Grained Document-Level Fact-Checking and Correction of
-
[23]
Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan ...
-
[24]
Wang, Yuxia and Li, Haonan and Han, Xudong and Nakov, Preslav and Baldwin, Timothy , booktitle =
-
[25]
BeaverTails: Towards Improved Safety Alignment of
Jiaming Ji and Mickel Liu and Josef Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang , bibsource =. BeaverTails: Towards Improved Safety Alignment of. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans,...
2023
-
[26]
Exploring
Zhuo, Terry Yue and Huang, Yujin and Chen, Chunyang and Xing, Zhenchang , journal =. Exploring
-
[27]
Diverse Adversaries for Mitigating Bias in Training , url =
Han, Xudong and Baldwin, Timothy and Cohn, Trevor , booktitle =. Diverse Adversaries for Mitigating Bias in Training , url =. doi:10.18653/v1/2021.eacl-main.239 , editor =
-
[28]
Against The Achilles' Heel:
Lizhi Lin and Honglin Mu and Zenan Zhai and Minghan Wang and Yuxia Wang and Renxi Wang and Junjie Gao and Yixuan Zhang and Wanxiang Che and Timothy Baldwin and Xudong Han and Haonan Li , journal =. Against The Achilles' Heel:
-
[29]
M4: Multi-generator, Multi-domain, and Multi-lingual Black-Box Machine-Generated Text Detection , url =
Wang, Yuxia and Mansurov, Jonibek and Ivanov, Petar and Su, Jinyan and Shelmanov, Artem and Tsvigun, Akim and Whitehouse, Chenxi and Mohammed Afzal, Osama and Mahmoud, Tarek and Sasaki, Toru and Arnold, Thomas and Aji, Alham Fikri and Habash, Nizar and Gurevych, Iryna and Nakov, Preslav , booktitle =. M4: Multi-generator, Multi-domain, and Multi-lingual B...
-
[30]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , bibsourc...
2022
-
[31]
ArXiv preprint , title =
Laura Weidinger and John Mellor and Maribeth Rauh and Conor Griffin and Jonathan Uesato and Po. ArXiv preprint , title =
-
[32]
Emilio Ferrara , journal =. Should
-
[33]
Christiano and Allan Dafoe , journal =
Toby Shevlane and Sebastian Farquhar and Ben Garfinkel and Mary Phuong and Jess Whittlestone and Jade Leung and Daniel Kokotajlo and Nahema Marchal and Markus Anderljung and Noam Kolt and Lewis Ho and Divya Siddarth and Shahar Avin and Will Hawkins and Been Kim and Iason Gabriel and Vijay Bolina and Jack Clark and Yoshua Bengio and Paul F. Christiano and ...
-
[34]
Jailbroken: How Does
Alexander Wei and Nika Haghtalab and Jacob Steinhardt , bibsource =. Jailbroken: How Does. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , editor =
2023
-
[35]
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , url =
Ganguli, Deep and Lovitt, Liane and Kernion, Jackson and Askell, Amanda and Bai, Yuntao and Kadavath, Saurav and Mann, Ben and Perez, Ethan and Schiefer, Nicholas and Ndousse, Kamal and others , journal =. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , url =
-
[36]
Toxicity in chatgpt: Analyzing persona-assigned language models , url =
Deshpande, Ameet and Murahari, Vishvak and Rajpurohit, Tanmay and Kalyan, Ashwin and Narasimhan, Karthik , booktitle =. Toxicity in chatgpt: Analyzing persona-assigned language models , url =. doi:10.18653/v1/2023.findings-emnlp.88 , editor =
-
[37]
Handling and Presenting Harmful Text in
Kirk, Hannah and Birhane, Abeba and Vidgen, Bertie and Derczynski, Leon , booktitle =. Handling and Presenting Harmful Text in. doi:10.18653/v1/2022.findings-emnlp.35 , editor =
-
[38]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , bibsource =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , url =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS...
2022
-
[39]
Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller ...
-
[40]
Misinformation: susceptibility, spread, and interventions to immunize the public , url =
Van Der Linden, Sander , journal =. Misinformation: susceptibility, spread, and interventions to immunize the public , url =
-
[41]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , month = mar, year =
Dhamala, Jwala and Sun, Tony and Kumar, Varun and Krishna, Satyapriya and Pruksachatkun, Yada and Chang, Kai-Wei and Gupta, Rahul , booktitle =. doi:10.1145/3442188.3445924 , isbn =
-
[42]
Manning and Christopher R
Percy Liang and Rishi Bommasani and Tony Lee and Dimitris Tsipras and Dilara Soylu and Michihiro Yasunaga and Yian Zhang and Deepak Narayanan and Yuhuai Wu and Ananya Kumar and Benjamin Newman and Binhang Yuan and Bobby Yan and Ce Zhang and Christian Cosgrove and Christopher D. Manning and Christopher R. ArXiv preprint , title =
-
[43]
Wang, Yuxia and Wang, Minghan and Chen, Yimeng and Tao, Shimin and Guo, Jiaxin and Su, Chang and Zhang, Min and Yang, Hao , booktitle =. Capture Human Disagreement Distributions by Calibrated Networks for Natural Language Inference , url =. doi:10.18653/v1/2022.findings-acl.120 , editor =
-
[44]
A Multi-pass Sieve for Clinical Concept Normalization , url =
Wang, Yuxia and Hur, Brian and Verspoor, Karin and Baldwin, Timothy , editor =. A Multi-pass Sieve for Clinical Concept Normalization , url =. Traitement Automatique des Langues , number =
-
[45]
Uncertainty Estimation and Reduction of Pre-trained Models for Text Regression , url =
Wang, Yuxia and Beck, Daniel and Baldwin, Timothy and Verspoor, Karin , doi =. Uncertainty Estimation and Reduction of Pre-trained Models for Text Regression , url =. Transactions of the Association for Computational Linguistics , pages =
-
[46]
Wang, Yuxia and Liu, Fei and Verspoor, Karin and Baldwin, Timothy , booktitle =. Evaluating the Utility of Model Configurations and Data Augmentation on Clinical Semantic Textual Similarity , url =. doi:10.18653/v1/2020.bionlp-1.11 , editor =
-
[47]
Learning from Unlabelled Data for Clinical Semantic Textual Similarity , url =
Wang, Yuxia and Verspoor, Karin and Baldwin, Timothy , booktitle =. Learning from Unlabelled Data for Clinical Semantic Textual Similarity , url =. doi:10.18653/v1/2020.clinicalnlp-1.25 , editor =
-
[48]
Noisy Label Regularisation for Textual Regression , url =
Wang, Yuxia and Baldwin, Timothy and Verspoor, Karin , booktitle =. Noisy Label Regularisation for Textual Regression , url =
-
[49]
Alhindi, Tariq and McManus, Brennan and Muresan, Smaranda , booktitle =. What to Fact-Check: Guiding Check-Worthy Information Detection in News Articles through Argumentative Discourse Structure , url =. doi:10.18653/v1/2021.sigdial-1.40 , editor =
-
[50]
Proceedings of the 11th International Workshop on Semantic Evaluation (
Cer, Daniel and Diab, Mona and Agirre, Eneko and Lopez-Gazpio, I. Proceedings of the 11th International Workshop on Semantic Evaluation (. doi:10.18653/v1/S17-2001 , editor =
-
[51]
Proceedings of the 2019 Conference of the North
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle =. doi:10.18653/v1/N19-1423 , editor =
-
[52]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , url =
Williams, Adina and Nangia, Nikita and Bowman, Samuel , booktitle =. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference , url =. doi:10.18653/v1/N18-1101 , editor =
work page internal anchor Pith review doi:10.18653/v1/n18-1101
-
[53]
How Robust is
Chen, Xuanting and Ye, Junjie and Zu, Can and Xu, Nuo and Zheng, Rui and Peng, Minlong and Zhou, Jie and Gui, Tao and Zhang, Qi and Huang, Xuanjing , journal =. How Robust is
-
[54]
Quantifying Semantic Similarity of Clinical Evidence in the Biomedical Literature to Facilitate Related Evidence Synthesis , year =
Hassanzadeh, Hamed and Nguyen, Anthony and Verspoor, Karin , journal =. Quantifying Semantic Similarity of Clinical Evidence in the Biomedical Literature to Facilitate Related Evidence Synthesis , year =
-
[55]
Bioinformatics , number =
So. Bioinformatics , number =
-
[56]
What Can We Learn from Collective Human Opinions on Natural Language Inference Data? , url =
Nie, Yixin and Zhou, Xiang and Bansal, Mohit , booktitle =. What Can We Learn from Collective Human Opinions on Natural Language Inference Data? , url =. doi:10.18653/v1/2020.emnlp-main.734 , editor =
-
[57]
Wang, Yanshan and Afzal, Naveed and Fu, Sunyang and Wang, Liwei and Shen, Feichen and Rastegar-Mojarad, Majid and Liu, Hongfang , journal =
-
[58]
Weinberger , bibsource =
Chuan Guo and Geoff Pleiss and Yu Sun and Kilian Q. Weinberger , bibsource =. On Calibration of Modern Neural Networks , url =. Proceedings of the 34th International Conference on Machine Learning,
-
[59]
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =
Alex Kendall and Yarin Gal , bibsource =. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? , url =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
2017
-
[60]
doi:10.1145/3442381.3450087 , editor =
Chacha Chen and Junjie Liang and Fenglong Ma and Lucas Glass and Jimeng Sun and Cao Xiao , bibsource =. doi:10.1145/3442381.3450087 , editor =
-
[61]
Wang, Yanshan and Fu, Sunyang and Shen, Feichen and Henry, Sam and Uzuner, Ozlem and Liu, Hongfang , day =. The 2019. JMIR Medical Informatics , number =. doi:10.2196/23375 , issn =
-
[62]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D. , booktitle =. A large annotated corpus for learning natural language inference , url =. doi:10.18653/v1/D15-1075 , editor =
-
[63]
Lessons from Natural Language Inference in the Clinical Domain , url =
Romanov, Alexey and Shivade, Chaitanya , booktitle =. Lessons from Natural Language Inference in the Clinical Domain , url =. doi:10.18653/v1/D18-1187 , editor =
-
[64]
Smith , bibsource =
Muru Zhang and Ofir Press and William Merrill and Alisa Liu and Noah A. Smith , bibsource =. How Language Model Hallucinations Can Snowball , url =. Forty-first International Conference on Machine Learning,
-
[65]
Exploring the Trade-Offs: Unified Large Language Models vs Local Fine-Tuned Models for Highly-Specific Radiology NLI Task , url =
Wu, Zihao and Zhang, Lu and Cao, Chao and Yu, Xiaowei and Dai, Haixing and Ma, Chong and Liu, Zhengliang and Zhao, Lin and Li, Gang and Liu, Wei and others , journal =. Exploring the Trade-Offs: Unified Large Language Models vs Local Fine-Tuned Models for Highly-Specific Radiology NLI Task , url =
-
[66]
Prompting for explanations improves Adversarial
Kavumba, Pride and Brassard, Ana and Heinzerling, Benjamin and Inui, Kentaro , booktitle =. Prompting for explanations improves Adversarial. doi:10.18653/v1/2023.findings-eacl.162 , editor =
-
[67]
Kazemi, Ashkan and Garimella, Kiran and Gaffney, Devin and Hale, Scott , booktitle =. Claim Matching Beyond. doi:10.18653/v1/2021.acl-long.347 , editor =
-
[68]
Vo, Nguyen and Lee, Kyumin , booktitle =. Where Are the Facts? Searching for Fact-checked Information to Alleviate the Spread of Fake News , url =. doi:10.18653/v1/2020.emnlp-main.621 , editor =
-
[69]
Generating Fact Checking Briefs , url =
Fan, Angela and Piktus, Aleksandra and Petroni, Fabio and Wenzek, Guillaume and Saeidi, Marzieh and Vlachos, Andreas and Bordes, Antoine and Riedel, Sebastian , booktitle =. Generating Fact Checking Briefs , url =. doi:10.18653/v1/2020.emnlp-main.580 , editor =
-
[70]
Alam, Firoj and Shaar, Shaden and Dalvi, Fahim and Sajjad, Hassan and Nikolov, Alex and Mubarak, Hamdy and Da San Martino, Giovanni and Abdelali, Ahmed and Durrani, Nadir and Darwish, Kareem and Al-Homaid, Abdulaziz and Zaghouani, Wajdi and Caselli, Tommaso and Danoe, Gijs and Stolk, Friso and Bruntink, Britt and Nakov, Preslav , booktitle =. Fighting the...
-
[71]
Towards Few-shot Fact-Checking via Perplexity , url =
Lee, Nayeon and Bang, Yejin and Madotto, Andrea and Fung, Pascale , booktitle =. Towards Few-shot Fact-Checking via Perplexity , url =. doi:10.18653/v1/2021.naacl-main.158 , editor =
-
[72]
Zero-shot Fact Verification by Claim Generation , url =
Pan, Liangming and Chen, Wenhu and Xiong, Wenhan and Kan, Min-Yen and Wang, William Yang , booktitle =. Zero-shot Fact Verification by Claim Generation , url =. doi:10.18653/v1/2021.acl-short.61 , editor =
-
[73]
Evidence-based Factual Error Correction , url =
Thorne, James and Vlachos, Andreas , booktitle =. Evidence-based Factual Error Correction , url =. doi:10.18653/v1/2021.acl-long.256 , editor =
-
[74]
A Survey on Automated Fact-Checking , url =
Guo, Zhijiang and Schlichtkrull, Michael and Vlachos, Andreas , doi =. A Survey on Automated Fact-Checking , url =. Transactions of the Association for Computational Linguistics , pages =
-
[75]
Explainable Automated Fact-Checking: A Survey , url =
Kotonya, Neema and Toni, Francesca , booktitle =. Explainable Automated Fact-Checking: A Survey , url =. doi:10.18653/v1/2020.coling-main.474 , editor =
-
[76]
Hardalov, Momchil and Chernyavskiy, Anton and Koychev, Ivan and Ilvovsky, Dmitry and Nakov, Preslav , booktitle =
-
[77]
Batch-Softmax Contrastive Loss for Pairwise Sentence Scoring Tasks , url =
Chernyavskiy, Anton and Ilvovsky, Dmitry and Kalinin, Pavel and Nakov, Preslav , booktitle =. Batch-Softmax Contrastive Loss for Pairwise Sentence Scoring Tasks , url =. doi:10.18653/v1/2022.naacl-main.9 , editor =
-
[78]
doi:10.18653/v1/2021.acl-long.133 , editor =
Fung, Yi and Thomas, Christopher and Gangi Reddy, Revanth and Polisetty, Sandeep and Ji, Heng and Chang, Shih-Fu and McKeown, Kathleen and Bansal, Mohit and Sil, Avi , booktitle =. doi:10.18653/v1/2021.acl-long.133 , editor =
-
[79]
and Barzilay, Regina , doi =
Schuster, Tal and Schuster, Roei and Shah, Darsh J. and Barzilay, Regina , doi =. The Limitations of Stylometry for Detecting Machine-Generated Fake News , url =. Computational Linguistics , number =
-
[80]
Baly, Ramy and Karadzhov, Georgi and An, Jisun and Kwak, Haewoon and Dinkov, Yoan and Ali, Ahmed and Glass, James and Nakov, Preslav , booktitle =. What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context , url =. doi:10.18653/v1/2020.acl-main.308 , editor =
-
[81]
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries , url =
Wang, Alex and Cho, Kyunghyun and Lewis, Mike , booktitle =. Asking and Answering Questions to Evaluate the Factual Consistency of Summaries , url =. doi:10.18653/v1/2020.acl-main.450 , editor =
-
[82]
Evaluating the Factual Consistency of Abstractive Text Summarization , url =
Kryscinski, Wojciech and McCann, Bryan and Xiong, Caiming and Socher, Richard , booktitle =. Evaluating the Factual Consistency of Abstractive Text Summarization , url =. doi:10.18653/v1/2020.emnlp-main.750 , editor =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.