Forecasting Future Behavior as a Learning Task
Pith reviewed 2026-06-27 12:53 UTC · model grok-4.3
The pith
Behavior Forecasters trained on LRM trajectories predict future behavior more accurately than frontier models reading the same trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose an alternative that bypasses the explanation step: treat behavior forecasting as a learnable task and train Behavior Forecasters that operates on a single reasoning trajectory to make the same forecasts one would typically seek from an explanation. The forecaster's training data is obtained by querying the LRM with no human annotation, and its inference is done in a single forward pass. We instantiate this approach on two tasks: how likely the LRM is to repeat its answer on re-runs, and how removing parts of the input changes its answer. We evaluate this approach on both tasks across three diverse reasoning datasets and find that trained Behavior Forecasters are more accurate than
What carries the argument
Behavior Forecaster: a smaller model initialized from the target LRM, fine-tuned end-to-end to output behavior predictions such as repetition likelihood from a single reasoning trajectory in one forward pass.
If this is right
- Trained Behavior Forecasters achieve higher accuracy than GPT-5.4 or Claude Opus-4.6 reading the same trajectories as naive readers.
- Forecasting requires only a single forward pass at a small fraction of the inference cost of frontier models.
- Fine-tuning the backbone end-to-end and initializing it from the target LRM are each necessary for the performance gains.
- The reasoning trajectory encodes information about the LRM's future behavior beyond what naive reading conveys.
Where Pith is reading between the lines
- The method could be extended to forecast additional behaviors such as hallucination rates or output length without new human labels.
- Behavior Forecasters could function as lightweight monitors that run alongside deployed LRMs to anticipate problems before they appear.
- Training forecasters on open-weight models would allow third parties to build behavior predictors without access to the original proprietary systems.
Load-bearing premise
The assumption that fine-tuning the backbone end-to-end and initializing it from the target LRM are each necessary for strong performance and that the trajectory carries information about future behavior beyond what naive reading conveys.
What would settle it
An experiment in which a forecaster not initialized from the target LRM or trained without end-to-end fine-tuning matches the accuracy of the proposed forecasters on the repetition-probability and input-sensitivity tasks.
Figures

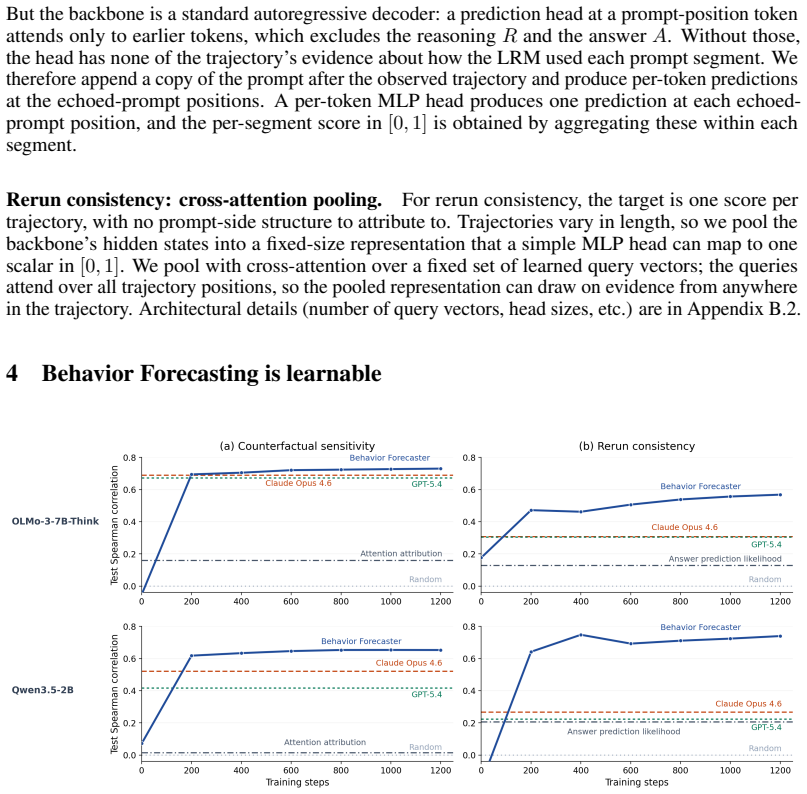
read the original abstract
Trust in an AI system is often anchored by explanations of how it works, which one then uses to forecast its behavior on new inputs. For large reasoning models (LRMs), this conventional route is particularly difficult to follow: explanation methods for single token generations do not naturally generalize to long trajectories, and the trajectories themselves are often not faithful when read as natural language. We propose an alternative that bypasses the explanation step: treat behavior forecasting as a learnable task and train Behavior Forecasters that operates on a single reasoning trajectory to make the same forecasts one would typically seek from an explanation. The forecaster's training data is obtained by querying the LRM with no human annotation, and its inference is done in a single forward pass. We instantiate this approach on two tasks: how likely the LRM is to repeat its answer on re-runs, and how removing parts of the input changes its answer. We evaluate this approach on both tasks across three diverse reasoning datasets and find that trained Behavior Forecasters are more accurate than GPT-5.4 and Claude Opus-4.6 reading the same trajectories as naive readers, at a small fraction of their inference cost. We find that fine-tuning the backbone end-to-end and initializing it from the target LRM are each necessary for strong performance. These results show that the reasoning trajectory carries information about the LRM's future behavior that goes beyond what naive reading conveys.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that behavior forecasting for large reasoning models can be framed as a supervised learning task where labels are generated by querying the target model itself. A Behavior Forecaster is trained on reasoning trajectories to predict future behaviors such as answer repetition and sensitivity to input changes. The trained forecaster outperforms larger models like GPT-5.4 and Claude Opus-4.6 on the same task when given the trajectories, at lower cost, and both initialization from the target model and end-to-end fine-tuning are necessary for good performance. This is demonstrated on three reasoning datasets for two tasks.
Significance. If the results hold, this work provides evidence that reasoning trajectories contain information about future model behavior that is not easily accessible through naive reading by even larger models. It offers a practical, scalable method for forecasting LRM behavior without human annotation or complex explanation techniques. The emphasis on self-supervised label generation and the necessity of model-specific training are positive aspects that strengthen the contribution.
minor comments (1)
- [Abstract] The abstract states the outperformance claim but does not include any specific metrics, dataset details, or experimental controls, which would help readers assess the results quickly.
Simulated Author's Rebuttal
We thank the referee for the supportive summary and recommendation of minor revision. No specific major comments were raised in the report, so we have no points requiring detailed rebuttal at this stage. We will address any minor issues identified during the revision process.
Circularity Check
No significant circularity
full rationale
The paper describes a supervised learning setup in which labels for future LRM behavior are generated by separate queries to the target model (no human annotation), after which a distinct forecaster model—initialized from the LRM and fine-tuned end-to-end—is trained to predict those labels from a single trajectory. This process does not reduce any claimed prediction to its own inputs by construction, nor does it rely on self-citation chains, uniqueness theorems, or smuggled ansatzes. The evaluation compares the trained forecaster against larger models prompted on the same trajectories, and the paper states that both initialization and end-to-end fine-tuning were found necessary. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning trajectories contain information about the LRM's future behavior that exceeds what naive reading extracts
invented entities (1)
-
Behavior Forecaster
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2512.12777 , year=
State over Tokens: Characterizing the Role of Reasoning Tokens , author=. arXiv preprint arXiv:2512.12777 , year=
-
[2]
Nature , volume=
Machine behaviour , author=. Nature , volume=. 2019 , publisher=
2019
-
[3]
Journal of Social Computing , year=
Generative Models as a Complex Systems Science: How Can We Make Sense of Large Language Model Behavior? , author=. Journal of Social Computing , year=
-
[4]
Beyond Accuracy: Behavioral Testing of
Ribeiro, Marco Tulio and Wu, Tongshuang and Guestrin, Carlos and Singh, Sameer , booktitle=. Beyond Accuracy: Behavioral Testing of. 2020 , doi=
2020
-
[5]
ICML Workshop on Human Interpretability in Machine Learning , year=
On the Robustness of Interpretability Methods , author=. ICML Workshop on Human Interpretability in Machine Learning , year=
-
[6]
International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations , year=
-
[7]
Evaluating Explainable
Hase, Peter and Bansal, Mohit , booktitle=. Evaluating Explainable. 2020 , doi=
2020
-
[8]
2019 , howpublished=
The Bitter Lesson , author=. 2019 , howpublished=
2019
-
[9]
arXiv preprint arXiv:1702.08608 , year=
Towards a rigorous science of interpretable machine learning , author=. arXiv preprint arXiv:1702.08608 , year=
-
[10]
Artificial Intelligence , volume=
Explanation in Artificial Intelligence: Insights from the Social Sciences , author=. Artificial Intelligence , volume=. 2019 , doi=
2019
-
[11]
arXiv preprint arXiv:2512.07810 , year=
Auditing Games for Sandbagging , author=. arXiv preprint arXiv:2512.07810 , year=
-
[12]
arXiv preprint arXiv:2512.18311 , year=
Monitoring Monitorability , author=. arXiv preprint arXiv:2512.18311 , year=
-
[13]
2025 , eprint=
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation , author=. 2025 , eprint=
2025
-
[14]
Anand Swaroop and Akshat Nallani and Saksham Uboweja and Adiliia Uzdenova and Michael Nguyen and Kevin Zhu and Sunishchal Dev and Ashwinee Panda and Vasu Sharma and Maheep Chaudhary , year=. 2509.13334 , archivePrefix=
-
[15]
CoRR , volume =
Joshua Goodman , title =. CoRR , volume =. 2001 , url =
2001
-
[16]
Patterns , volume=
Explainability pitfalls: Beyond dark patterns in explainable AI , author=. Patterns , volume=. 2024 , publisher=
2024
-
[17]
Jmir Ai , volume=
How explainable artificial intelligence can increase or decrease clinicians' trust in AI applications in health care: systematic review , author=. Jmir Ai , volume=. 2024 , publisher=
2024
-
[18]
2025 , note =
International AI Safety Report: First Key Update: Capabilities and Risk Implications , institution =. 2025 , note =
2025
-
[19]
Cognitive science , volume=
Finding structure in time , author=. Cognitive science , volume=. 1990 , publisher=
1990
-
[20]
2025 , eprint=
Large language models can learn and generalize steganographic chain-of-thought under process supervision , author=. 2025 , eprint=
2025
-
[21]
1980 , publisher=
Metaphors we live by , author=. 1980 , publisher=
1980
-
[22]
Transactions of the Association for Computational Linguistics , volume =
Wang, Ling and Zhao, Qi and Li, Ming , title =. Transactions of the Association for Computational Linguistics , volume =. 2024 , doi =
2024
-
[23]
2024 , eprint=
Let's Think Dot by Dot: Hidden Computation in Transformer Language Models , author=. 2024 , eprint=
2024
-
[24]
arXiv preprint arXiv:2502.06807 , year =
Competitive Programming with Large Reasoning Models , author =. arXiv preprint arXiv:2502.06807 , year =
-
[25]
2025 , note =
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. 2025 , note =
2025
-
[26]
arXiv preprint arXiv:2506.22992 , year=
MARBLE: A Hard Benchmark for Multimodal Spatial Reasoning and Planning , author=. arXiv preprint arXiv:2506.22992 , year=
-
[27]
Joshua T. Goodman. A bit of progress in language modeling. Computer Speech & Language. 2001. doi:10.1006/csla.2001.0174
-
[28]
CoRR , volume =
Rebecca Hwa , title =. CoRR , volume =. 1999 , url =
1999
-
[29]
Supervised Grammar Induction using Training Data with Limited Constituent Information
Hwa, Rebecca. Supervised Grammar Induction using Training Data with Limited Constituent Information. Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics. 1999
1999
-
[30]
, title =
Jurafsky, Daniel and Martin, James H. , title =
-
[31]
, author=
The Use of Participles and Gerunds. , author=. Online Submission , year=
-
[32]
2024 , url=
OpenAI o1 System Card , author=. 2024 , url=
2024
-
[33]
arXiv preprint arXiv:2411.14405 , year=
Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions , author=. arXiv preprint arXiv:2411.14405 , year=
-
[34]
arXiv preprint arXiv:2501.12948 , year=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[35]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen Team , month =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[36]
International Conference on Learning Representations , year=
From Sparse Dependence to Sparse Attention: Unveiling How Chain-of-Thought Enhances Transformer Sample Efficiency , author=. International Conference on Learning Representations , year=
-
[37]
arXiv preprint arXiv:2410.21333 , year=
Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse , author=. arXiv preprint arXiv:2410.21333 , year=
-
[38]
Lindsey, Jack and Gurnee, Wes and Ameisen, Emmanuel and Chen, Brian and Pearce, Adam and Turner, Nicholas L. and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[39]
arXiv preprint arXiv:2411.15124 , year=
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
-
[40]
2025 , eprint=
Towards Better Chain-of-Thought: A Reflection on Effectiveness and Faithfulness , author=. 2025 , eprint=
2025
-
[41]
arXiv preprint arXiv:2508.00943 , year=
Llms can covertly sandbag on capability evaluations against chain-of-thought monitoring , author=. arXiv preprint arXiv:2508.00943 , year=
-
[42]
2024 , eprint=
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning , author=. 2024 , eprint=
2024
-
[43]
2025 , eprint=
Typed Chain-of-Thought: A Curry-Howard Framework for Verifying LLM Reasoning , author=. 2025 , eprint=
2025
-
[44]
2025 , eprint=
How does Chain of Thought Think? Mechanistic Interpretability of Chain-of-Thought Reasoning with Sparse Autoencoding , author=. 2025 , eprint=
2025
-
[45]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[46]
Studies in the Logic of Explanation , author=. Philosophy of Science , year=. doi:10.1086/286983 , url=
-
[47]
Reintroducing Prediction to Explanation , author=. Philosophy of Science , year=. doi:10.1086/648111 , url=
-
[48]
Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
Formalizing trust in artificial intelligence: Prerequisites, causes and goals of human trust in AI , author=. Proceedings of the 2021 ACM conference on fairness, accountability, and transparency , pages=
2021
-
[49]
Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , year=
How Explainability Contributes to Trust in AI , author=. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , year=
2022
-
[50]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year=
Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year=
-
[51]
Advances in Neural Information Processing Systems , volume=
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[52]
2025 , eprint=
Unspoken Hints: Accuracy Without Acknowledgement in LLM Reasoning , author=. 2025 , eprint=
2025
-
[53]
arXiv preprint arXiv:2503.08679 , year=
Chain-of-thought reasoning in the wild is not always faithful , author=. arXiv preprint arXiv:2503.08679 , year=
-
[54]
plausibility: On the (un) reliability of explanations from large language models , author=
Faithfulness vs. plausibility: On the (un) reliability of explanations from large language models , author=. arXiv preprint arXiv:2402.04614 , year=
-
[55]
Journal of Machine Learning Research , volume=
Causal abstraction: A theoretical foundation for mechanistic interpretability , author=. Journal of Machine Learning Research , volume=
-
[56]
arXiv preprint arXiv:2307.13702 , year=
Measuring Faithfulness in Chain-of-Thought Reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
-
[57]
2025 , eprint=
s1: Simple test-time scaling , author=. 2025 , eprint=
2025
-
[58]
arXiv preprint arXiv:2310.02226 , year=
Think before you speak: Training Language Models With Pause Tokens , author=. arXiv preprint arXiv:2310.02226 , year=
-
[59]
arXiv preprint arXiv:2212.03827 , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. arXiv preprint arXiv:2212.03827 , year=
-
[60]
Nature Machine Intelligence , volume=
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead , author=. Nature Machine Intelligence , volume=. 2019 , publisher=
2019
-
[61]
1996 , publisher=
Using Language , author=. 1996 , publisher=
1996
-
[62]
International Journal of Human-Computer Studies , volume =
Lumsden, Karen and Moran, Alan , title =. International Journal of Human-Computer Studies , volume =. 2005 , doi =
2005
-
[63]
Chi, Michelene T. H. , title =. Educational Psychologist , volume =. 2001 , doi =
2001
-
[64]
Fonseca, Bea and Chi, Michelene T. H. , title =. Trends in Cognitive Sciences , volume =. 2009 , doi =
2009
-
[65]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[66]
2025 , eprint=
Are DeepSeek R1 And Other Reasoning Models More Faithful? , author=. 2025 , eprint=
2025
-
[67]
Chain-of-Thought Is Not Explainability , publisher =
Barez, Fazl and Wu, Tung-Yu and Arcuschin, Iv\'. Chain-of-Thought Is Not Explainability , publisher =
-
[68]
2023 , eprint=
A Survey on Evaluation of Large Language Models , author=. 2023 , eprint=
2023
-
[69]
ArXiv , year=
Can LLMs Explain Themselves Counterfactually? , author=. ArXiv , year=
-
[70]
ArXiv , year=
How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts? , author=. ArXiv , year=
-
[71]
arXiv preprint arXiv:2406.10625 , year=
On the hardness of faithful chain-of-thought reasoning in large language models , author=. arXiv preprint arXiv:2406.10625 , year=
-
[72]
arXiv preprint arXiv:2405.04382 , year=
Large language models cannot explain themselves , author=. arXiv preprint arXiv:2405.04382 , year=
-
[73]
ArXiv , year=
MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency , author=. ArXiv , year=
-
[74]
arXiv preprint arXiv:2405.15092 , year=
Dissociation of faithful and unfaithful reasoning in llms , author=. arXiv preprint arXiv:2405.15092 , year=
-
[75]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[76]
2025 , eprint=
A Pragmatic Way to Measure Chain-of-Thought Monitorability , author=. 2025 , eprint=
2025
-
[77]
2025 , eprint=
The Geometry of Reasoning: Flowing Logics in Representation Space , author=. 2025 , eprint=
2025
-
[78]
ArXiv , year=
Evaluating Step-by-step Reasoning Traces: A Survey , author=. ArXiv , year=
-
[79]
ICLR , year=
Emergent world representations: Exploring a sequence model trained on a synthetic task , author=. ICLR , year=
-
[80]
Understanding intermediate layers using linear classifier probes , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.