The Periodic Table of LLM Reasoning: A Structured Survey of Reasoning Paradigms, Methods, and Failure Modes
Pith reviewed 2026-06-27 12:58 UTC · model grok-4.3
The pith
A taxonomy sorts LLM reasoning into nine paradigms and catalogs their shared failure modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
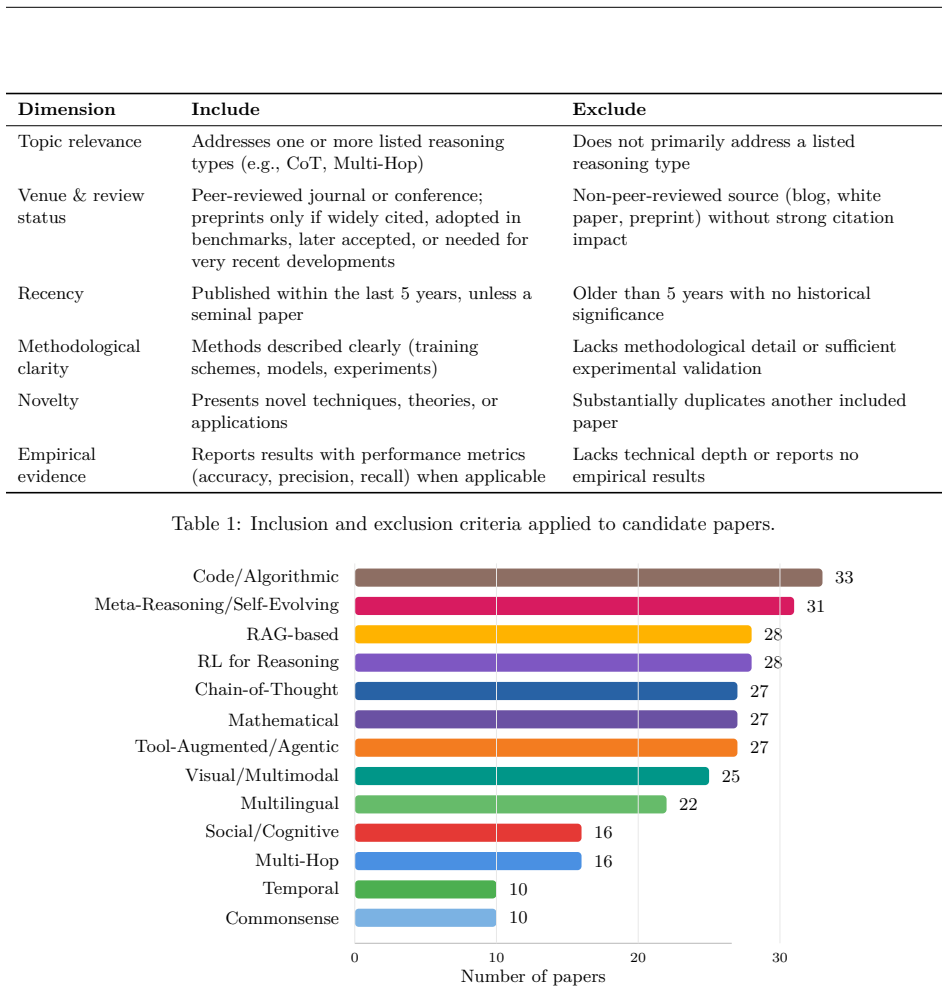
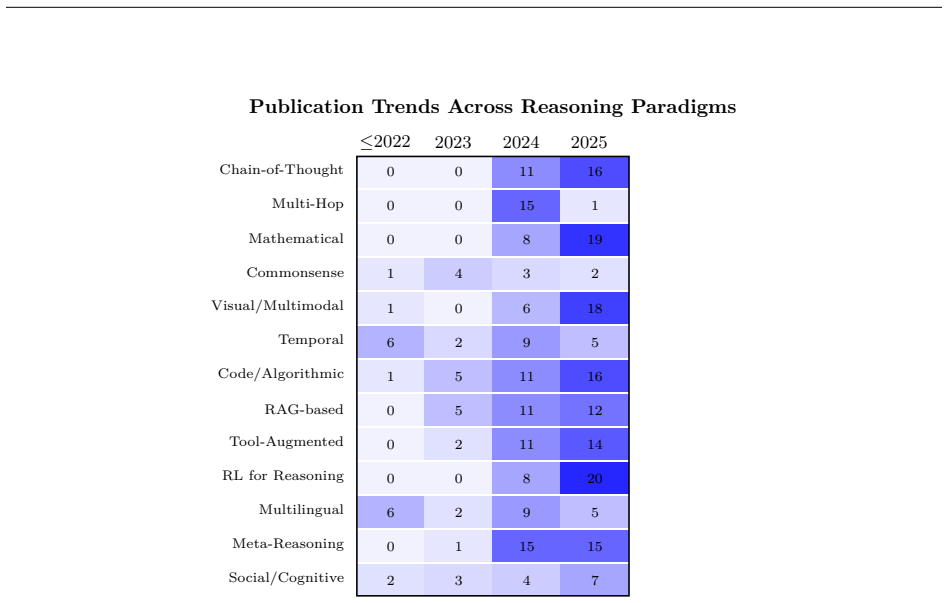
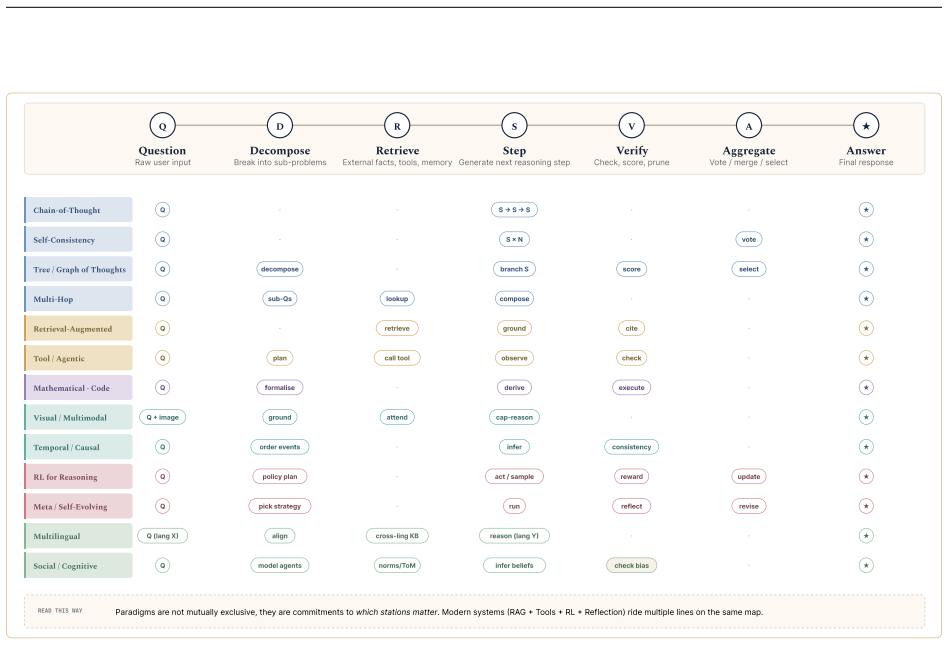
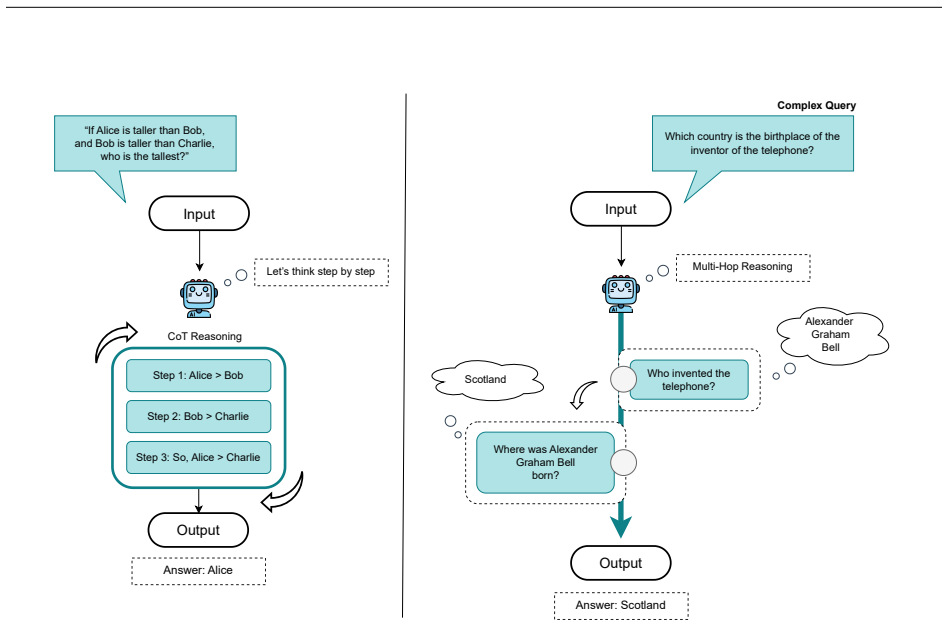
The paper establishes that LLM reasoning research can be organized into a taxonomy of nine paradigms—Chain-of-Thought reasoning, multi-hop reasoning, mathematical reasoning, common sense reasoning, visual and temporal reasoning, code and algorithmic reasoning, retrieval-augmented reasoning, tool-augmented and agentic reasoning, and reinforcement learning-based reasoning—while methodological trends in prompting, architectures, and benchmarks are analyzed and recurring limitations including reasoning hallucinations, brittle multi-step inference, weak causal abstraction, and poor cross-domain generalization are synthesized across the literature.
What carries the argument
The structured taxonomy of nine LLM reasoning paradigms that classifies methods, architectures, training objectives, and evaluation approaches while exposing shared failure patterns.
Load-bearing premise
The more than 300 papers selected from arXiv, Semantic Scholar, Google Scholar, Papers with Code, and the ACL Anthology form a representative and unbiased sample of all current LLM reasoning research.
What would settle it
Discovery of a substantial body of LLM reasoning papers that cannot be placed in any of the nine taxonomy categories or that exhibit failure modes absent from the synthesized list.
Figures



















read the original abstract
Large Language Models (LLMs) have achieved strong performance across natural language processing tasks, yet reliable reasoning remains an open challenge. Although modern LLMs show progress in structured inference, multi-step problem solving, and contextual understanding, their reasoning behavior is often inconsistent and sensitive to prompting strategies, task design, and model scale. This survey provides a systematic analysis of more than 300 recent papers from arXiv, Semantic Scholar, Google Scholar, Papers with Code, and the ACL Anthology to examine how reasoning capabilities emerge in LLMs and where they fail. We make three main contributions. First, we introduce a structured taxonomy of LLM reasoning research, covering Chain-of-Thought reasoning, multi-hop reasoning, mathematical reasoning, common sense reasoning, visual and temporal reasoning, code and algorithmic reasoning, retrieval-augmented reasoning, tool-augmented and agentic reasoning, and reinforcement learning-based reasoning. Second, we analyze methodological trends across these paradigms, including prompting methods, model architectures, training objectives, reward modeling, and evaluation benchmarks. Third, we synthesize recurring limitations and failure modes, such as reasoning hallucinations, brittle multi-step inference, weak causal abstraction, and poor cross-domain generalization. By organizing a rapidly expanding literature, this survey offers a unified view of the current capabilities and limitations of reasoning in LLMs. We also identify emerging research directions, including meta-reasoning, self-evolving reasoning frameworks, multimodal reasoning, and socially grounded reasoning. Overall, this work aims to serve as a reference for developing more robust, interpretable, and generalizable reasoning systems in future language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver a systematic survey of LLM reasoning by analyzing more than 300 papers drawn from arXiv, Semantic Scholar, Google Scholar, Papers with Code, and the ACL Anthology. It introduces a taxonomy organized around nine paradigms (Chain-of-Thought, multi-hop, mathematical, commonsense, visual/temporal, code/algorithmic, retrieval-augmented, tool/agentic, and RL-based reasoning), examines trends in prompting, architectures, objectives, and benchmarks, synthesizes recurring failure modes (hallucinations, brittle multi-step inference, weak causal abstraction, poor cross-domain generalization), and flags emerging directions such as meta-reasoning and multimodal reasoning.
Significance. If the selection and synthesis were demonstrably representative, the work would offer a useful organizing framework for a fast-moving subfield and could help researchers avoid duplicated effort on known failure modes. The survey format itself carries modest incremental value once the methodology is made transparent; absent that transparency, the claimed unification of capabilities and limitations rests on an unverified sample.
major comments (1)
- [Abstract] Abstract (and any methodology section): the central claim of a 'systematic analysis of more than 300 recent papers' that yields a reliable taxonomy and synthesized failure modes is unsupported because the manuscript supplies no search strings, date cutoffs, inclusion/exclusion criteria, deduplication procedure, or relevance-screening protocol. Without these elements the representativeness of the corpus cannot be assessed and the taxonomy may systematically over- or under-weight particular paradigms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the transparency of our literature search process must be improved to support the claim of a systematic analysis, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (and any methodology section): the central claim of a 'systematic analysis of more than 300 recent papers' that yields a reliable taxonomy and synthesized failure modes is unsupported because the manuscript supplies no search strings, date cutoffs, inclusion/exclusion criteria, deduplication procedure, or relevance-screening protocol. Without these elements the representativeness of the corpus cannot be assessed and the taxonomy may systematically over- or under-weight particular paradigms.
Authors: We acknowledge that the manuscript does not currently include explicit details on the search methodology. In the revised version we will insert a new 'Literature Collection and Screening' subsection (placed after the introduction) that documents: the primary search strings employed across arXiv, Semantic Scholar, Google Scholar, Papers with Code, and ACL Anthology (combinations of terms such as "LLM reasoning", "chain-of-thought", "multi-hop reasoning", "mathematical reasoning", "commonsense reasoning", "tool use", "agentic reasoning", and "failure modes"); the date range (primarily January 2022–March 2024, with selected foundational works from 2018–2021); inclusion criteria (peer-reviewed or preprint papers that either introduce a new reasoning method, benchmark, or failure analysis within one of the nine paradigms); exclusion criteria (non-English works, purely theoretical papers without empirical results, and duplicates); the deduplication procedure (title/abstract matching followed by manual review); and the relevance screening protocol (initial keyword filter followed by abstract-level review by the authors). We will also note that the collection was not performed under a formal PRISMA-style protocol. These additions will allow readers to assess corpus representativeness. If the documented process reveals gaps, we will temper the abstract's wording from "systematic analysis" to "comprehensive survey" as appropriate. revision: yes
Circularity Check
No circularity: survey aggregates external literature
full rationale
The paper is a literature survey that constructs a taxonomy by reviewing >300 external papers from public databases. It contains no equations, no fitted parameters, no predictions derived from internal data, and no load-bearing self-citations that reduce the central claims to prior author work by definition. The selection protocol is undocumented, but this is a methodological limitation, not a circular reduction of any derivation to its own inputs. All listed patterns (self-definitional, fitted-input-called-prediction, etc.) are absent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers
Roman Abramov, Felix Steinbauer, and Gjergji Kasneci. Grokking in the Wild: Data Augmentation for Real-World Multi-Hop Reasoning with Transformers . arXiv preprint arXiv:2504.20752, 2025. doi:10.48550/arXiv.2504.20752. URL https://arxiv.org/abs/2504.20752
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[3]
Open deep search: Democratizing search with open-source reasoning agents
Salaheddin Alzubi, Creston Brooks, Purva Chiniya, Edoardo Contente, Chiara von Gerlach, Lucas Irwin, Yihan Jiang, Arda Kaz, Windsor Nguyen, Sewoong Oh, et al. Open deep search: Democratizing search with open-source reasoning agents. arXiv preprint arXiv:2503.20201, 2025. URL https://arxiv.org/abs/2503.20201
arXiv 2025
-
[4]
Can llms reason like humans? assessing theory of mind reasoning in llms for open-ended questions
Maryam Amirizaniani et al. Can llms reason like humans? assessing theory of mind reasoning in llms for open-ended questions. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM), 2024. URL https://dl.acm.org/doi/10.1145/3627673.3679832
-
[5]
Training language models to reason efficiently, 2025
Daman Arora and Andrea Zanette. Training language models to reason efficiently, 2025. URL https://arxiv. org/abs/2502.04463. URL https://arxiv.org/abs/2502.04463
arXiv 2025
-
[6]
Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching
Simon A Aytes, Jinheon Baek, and Sung Ju Hwang. Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching. arXiv preprint arXiv:2503.05179, 2025. URL https://arxiv.org/abs/2503.05179
arXiv 2025
-
[7]
Adaptive domain modeling with language models: A multi-agent approach to task planning
Harisankar Babu, Philipp Schillinger, and Tamim Asfour. Adaptive domain modeling with language models: A multi-agent approach to task planning. arXiv preprint arXiv:2506.19592, 2025
arXiv 2025
-
[8]
Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, et al. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 7421--7454, 2024 a
2024
-
[9]
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks . arXiv preprint arXiv:2412.15204, 2024 b . doi:10.48550/arXiv.2412.15204. URL https://arxiv.org/abs/2412.15204
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15204 2024
-
[10]
Longwriter: Unleashing 10,000+ word generation from long context llms
Yushi Bai, Jiajie Zhang, Xin Lv, Linzhi Zheng, Siqi Zhu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longwriter: Unleashing 10,000+ word generation from long context llms. arXiv preprint arXiv:2408.07055, 2024 c . URL https://arxiv.org/abs/2408.07055
arXiv 2024
-
[11]
Hunter, and Katharina von der Wense
George Arthur Baker, Ankush Raut, Sagi Shaier, Lawrence E. Hunter, and Katharina von der Wense. Lost in the Middle, and In-Between: Enhancing Language Models' Ability to Reason Over Long Contexts in Multi-Hop QA . arXiv preprint arXiv:2412.10079, 2024. doi:10.48550/arXiv.2412.10079. URL https://arxiv.org/abs/2412.10079
-
[12]
Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023, 2023. URL https://arxiv.org/abs/2302.04023
Pith/arXiv arXiv 2023
-
[13]
a is b” fail to learn “b is a
Lukas Berglund, Meg Tong, Maximilian Kaufmann, Mikita Balesni, Asa Stickland, Tomek Korbak, and Owain Evans. The reversal curse: Llms trained on “a is b” fail to learn “b is a”. In International Conference on Learning Representations, volume 2024, pp.\ 18623--18642, 2024
2024
-
[14]
Reasoning language models: A blueprint
Maciej Besta, Julia Barth, Eric Schreiber, Ales Kubicek, Afonso Catarino, Robert Gerstenberger, Piotr Nyczyk, Patrick Iff, Yueling Li, Sam Houliston, et al. Reasoning language models: A blueprint. arXiv preprint arXiv:2501.11223, 2025. URL https://arxiv.org/abs/2501.11223
arXiv 2025
-
[15]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 0 1877--1901, 2020
1901
-
[16]
Devichand Budagam, Ashutosh Kumar, Mahsa Khoshnoodi, Sankalp KJ, Vinija Jain, and Aman Chadha. Hierarchical prompting taxonomy: A universal evaluation framework for large language models aligned with human cognitive principles. arXiv preprint arXiv:2406.12644, 2024
arXiv 2024
-
[17]
Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models
Huanqia Cai, Yijun Yang, and Winston Hu. Mm-iq: Benchmarking human-like abstraction and reasoning in multimodal models. arXiv preprint arXiv:2502.00698, 2025. URL https://arxiv.org/abs/2502.00698
arXiv 2025
-
[18]
Senticnet 7: A commonsense-based neurosymbolic ai framework for explainable sentiment analysis
Erik Cambria, Qian Liu, Sergio Decherchi, Frank Xing, and Kenneth Kwok. Senticnet 7: A commonsense-based neurosymbolic ai framework for explainable sentiment analysis. In Proceedings of the thirteenth language resources and evaluation conference, pp.\ 3829--3839, 2022
2022
-
[19]
Chart-based reasoning: Transferring capabilities from llms to vlms
Victor Carbune, Hassan Mansoor, Fangyu Liu, Rahul Aralikatte, Gilles Baechler, Jindong Chen, and Abhanshu Sharma. Chart-based reasoning: Transferring capabilities from llms to vlms. arXiv preprint arXiv:2403.12596, 2024. URL https://arxiv.org/abs/2403.12596
arXiv 2024
-
[20]
Hyungjoo Chae, Yeonghyeon Kim, Seungone Kim, Kai Tzu-iunn Ong, Beong-woo Kwak, Moohyeon Kim, Seonghwan Kim, Taeyoon Kwon, Jiwan Chung, Youngjae Yu, et al. Language models as compilers: Simulating pseudocode execution improves algorithmic reasoning in language models. arXiv preprint arXiv:2404.02575, 2024. URL https://arxiv.org/abs/2404.02575
arXiv 2024
-
[21]
AlphaMath Almost Zero: Process Supervision without Process
Guoxin Chen, Minpeng Liao, Chengxi Li, and Kai Fan. AlphaMath Almost Zero: Process Supervision without Process . Advances in Neural Information Processing Systems, 37, 2024 a . doi:10.52202/079017-0870. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/30dfe47a3ccbee68cffa0c19ccb1bc00-Abstract-Conference.html
-
[22]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs . arXiv preprint arXiv:2412.18925, 2024 b . doi:10.48550/arXiv.2412.18925. URL https://arxiv.org/abs/2412.18925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.18925 2024
-
[23]
Justin Chih-Yao Chen, Swarnadeep Saha, Elias Stengel-Eskin, and Mohit Bansal. Magdi: Structured distillation of multi-agent interaction graphs improves reasoning in smaller language models. arXiv preprint arXiv:2402.01620, 2024 c . URL https://arxiv.org/abs/2402.01620
arXiv 2024
-
[24]
Reverse thinking makes llms stronger reasoners
Justin Chih-Yao Chen, Zifeng Wang, Hamid Palangi, Rujun Han, Sayna Ebrahimi, Long Le, Vincent Perot, Swaroop Mishra, Mohit Bansal, Chen-Yu Lee, et al. Reverse thinking makes llms stronger reasoners. arXiv preprint arXiv:2411.19865, 2024 d . URL https://arxiv.org/abs/2411.19865
arXiv 2024
-
[25]
Breaking language barriers in multilingual mathematical reasoning: Insights and observations
Nuo Chen, Zinan Zheng, Ning Wu, Ming Gong, Dongmei Zhang, and Jia Li. Breaking language barriers in multilingual mathematical reasoning: Insights and observations. arXiv preprint arXiv:2310.20246, 2023. URL https://arxiv.org/abs/2310.20246
arXiv 2023
-
[26]
Judgelrm: Large reasoning models as a judge
Nuo Chen, Zhiyuan Hu, Qingyun Zou, Jiaying Wu, Qian Wang, Bryan Hooi, and Bingsheng He. Judgelrm: Large reasoning models as a judge. arXiv preprint arXiv:2504.00050, 2025 a . URL https://arxiv.org/abs/2504.00050
arXiv 2025
-
[27]
Qiguang Chen, Libo Qin, Jiaqi Wang, Jinxuan Zhou, and Wanxiang Che. Unlocking the Capabilities of Thought: A Reasoning Boundary Framework to Quantify and Optimize Chain-of-Thought . Advances in Neural Information Processing Systems, 37: 0 54872--54904, 2024 e . doi:10.52202/079017-1740. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/62ab1c...
-
[28]
Advancing tool-augmented large language models: Integrating insights from errors in inference trees
Sijia Chen, Yibo Wang, Yi-Feng Wu, Qingguo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Lijun Zhang. Advancing tool-augmented large language models: Integrating insights from errors in inference trees. Advances in Neural Information Processing Systems, 37: 0 106555--106581, 2024 f . URL https://arxiv.org/abs/2406.07115
arXiv 2024
-
[29]
Tabfact: A large-scale dataset for table-based fact verification
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification. arXiv preprint arXiv:1909.02164, 2019
arXiv 1909
-
[30]
X. Chen, G. Li, Z. Wang, B. Jin, C. Qian, Y. Wang, and H. Ji. Rm-r1: Reward modeling as reasoning. arXiv preprint arXiv:2505.02387, 2025 b . URL https://arxiv.org/pdf/2505.02387
arXiv 2025
-
[31]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs . arXiv preprint arXiv:2412.21187, 2024 g . doi:10.48550/arXiv.2412.21187. URL https://arxiv.org/abs/2412.21187
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.21187 2024
-
[32]
Premise Order Matters in Reasoning with Large Language Models
Xinyun Chen, Ryan Andrew Chi, Xuezhi Wang, and Denny Zhou. Premise Order Matters in Reasoning with Large Language Models . In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pp.\ 6596--6620. PMLR, 2024 h . URL https://proceedings.mlr.press/v235/chen24i.html
2024
-
[33]
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations
Jeffrey Cheng and Benjamin Van Durme. Compressed Chain of Thought: Efficient Reasoning Through Dense Representations . arXiv preprint arXiv:2412.13171, 2024. doi:10.48550/arXiv.2412.13171. URL https://arxiv.org/abs/2412.13171
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.13171 2024
-
[34]
Coral: Benchmarking multi-turn conversational retrieval-augmentation generation
Yiruo Cheng, Kelong Mao, Ziliang Zhao, Guanting Dong, Hongjin Qian, Yongkang Wu, Tetsuya Sakai, Ji-Rong Wen, and Zhicheng Dou. Coral: Benchmarking multi-turn conversational retrieval-augmentation generation. arXiv preprint arXiv:2410.23090, 2024. URL https://arxiv.org/abs/2410.23090
arXiv 2024
-
[35]
Thoughtsculpt: Reasoning with intermediate revision and search
Yizhou Chi, Kevin Yang, and Dan Klein. Thoughtsculpt: Reasoning with intermediate revision and search. arXiv preprint arXiv:2404.05966, 2024. URL https://arxiv.org/abs/2404.05966
arXiv 2024
-
[36]
What the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks
Pavel Chizhov, Mattia Nee, Pierre-Carl Langlais, and Ivan P Yamshchikov. What the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks . arXiv preprint arXiv:2504.07825, 2025. doi:10.48550/arXiv.2504.07825. URL https://arxiv.org/abs/2504.07825
-
[37]
Dall-eval: Probing the reasoning skills and social biases of text-to-image generation models
Jaemin Cho, Abhay Zala, and Mohit Bansal. Dall-eval: Probing the reasoning skills and social biases of text-to-image generation models. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 3043--3054, 2023. URL https://arxiv.org/abs/2202.04053
arXiv 2023
-
[38]
M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding. arXiv preprint arXiv:2411.04952, 2024. URL https://arxiv.org/abs/2411.04952
arXiv 2024
-
[39]
Palm: Scaling language modeling with pathways
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of machine learning research, 24 0 (240): 0 1--113, 2023
2023
-
[40]
Timebench: A comprehensive evaluation of temporal reasoning abilities in large language models
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin. Timebench: A comprehensive evaluation of temporal reasoning abilities in large language models. arXiv preprint arXiv:2311.17667, 2023. URL https://arxiv.org/abs/2311.17667
arXiv 2023
-
[41]
BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering
Zheng Chu, Jingchang Chen, Qianglong Chen, Haotian Wang, Kun Zhu, Xiyuan Du, Weijiang Yu, Ming Liu, and Bing Qin. BeamAggR: Beam Aggregation Reasoning over Multi-source Knowledge for Multi-hop Question Answering . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1229--1248. Associatio...
-
[42]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[43]
The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks
Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, et al. The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks. arXiv preprint arXiv:2502.08235, 2025. URL https://arxiv.org/abs/2502.08235
arXiv 2025
-
[44]
Self-recognition in language models
Tim R Davidson, Viacheslav Surkov, Veniamin Veselovsky, Giuseppe Russo, Robert West, and Caglar Gulcehre. Self-recognition in language models. arXiv preprint arXiv:2407.06946, 2024. URL https://arxiv.org/abs/2407.06946
arXiv 2024
-
[45]
Benchmarks for Automated Commonsense Reasoning: A Survey
Ernest Davis. Benchmarks for Automated Commonsense Reasoning: A Survey . ACM Computing Surveys, 56 0 (4): 0 1--41, 2024. doi:10.1145/3615355. URL https://doi.org/10.1145/3615355
-
[46]
Flow-dpo: Improving llm mathematical reasoning through online multi-agent learning
Yihe Deng and Paul Mineiro. Flow-dpo: Improving llm mathematical reasoning through online multi-agent learning. arXiv preprint arXiv:2410.22304, 2024. URL https://arxiv.org/abs/2410.22304
arXiv 2024
-
[47]
Retrievegpt: Merging prompts and mathematical models for enhanced code-mixed information retrieval
Aniket Deroy and Subhankar Maity. Retrievegpt: Merging prompts and mathematical models for enhanced code-mixed information retrieval. arXiv preprint arXiv:2411.04752, 2024. URL https://arxiv.org/abs/2411.04752
arXiv 2024
-
[48]
Aniket Didolkar, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy Lillicrap, Danilo Rezende, Yoshua Bengio, Michael C. Mozer, and Sanjeev Arora. Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving . Advances in Neural Information Processing Systems, 37: 0 19783--19812, 2024. doi:10.52202/079017-0623. URL htt...
-
[49]
Mapeval: A map-based evaluation of geo-spatial reasoning in foundation models
Mahir Labib Dihan, Md Tanvir Hassan, Md Tanvir Parvez, Md Hasebul Hasan, Md Almash Alam, Muhammad Aamir Cheema, Mohammed Eunus Ali, and Md Rizwan Parvez. Mapeval: A map-based evaluation of geo-spatial reasoning in foundation models. arXiv preprint arXiv:2501.00316, 2024. URL https://arxiv.org/abs/2501.00316
arXiv 2024
-
[50]
Unleashing reasoning capability of llms via scalable question synthesis from scratch
Yuyang Ding, Xinyu Shi, Xiaobo Liang, Juntao Li, Qiaoming Zhu, and Min Zhang. Unleashing reasoning capability of llms via scalable question synthesis from scratch. arXiv preprint arXiv:2410.18693, 2024. URL https://arxiv.org/abs/2410.18693
arXiv 2024
-
[51]
Progressive multimodal reasoning via active retrieval
Guanting Dong, Chenghao Zhang, Mengjie Deng, Yutao Zhu, Zhicheng Dou, and Ji-Rong Wen. Progressive multimodal reasoning via active retrieval. arXiv preprint arXiv:2412.14835, 2024. URL https://arxiv.org/abs/2412.14835
arXiv 2024
-
[52]
Diverse inference and verification for advanced reasoning
Iddo Drori, Gaston Longhitano, Mao Mao, Seunghwan Hyun, Yuke Zhang, Sungjun Park, Zachary Meeks, Xin-Yu Zhang, Ben Segev, Howard Yong, et al. Diverse inference and verification for advanced reasoning. arXiv preprint arXiv:2502.09955, 2025. URL https://arxiv.org/abs/2502.09955
arXiv 2025
-
[53]
Competitive programming with large reasoning models
Ahmed El-Kishky, Alexander Wei, Andre Saraiva, Borys Minaiev, Daniel Selsam, David Dohan, Francis Song, Hunter Lightman, Ignasi Clavera, Jakub Pachocki, et al. Competitive programming with large reasoning models. arXiv preprint arXiv:2502.06807, 2025. URL https://arxiv.org/abs/2502.06807
arXiv 2025
-
[54]
Multinrc: A challenging and native multilingual reasoning evaluation benchmark for llms
Alexander R Fabbri, Diego Mares, Jorge Flores, Meher Mankikar, Ernesto Hernandez, Dean Lee, Bing Liu, and Chen Xing. Multinrc: A challenging and native multilingual reasoning evaluation benchmark for llms. arXiv preprint arXiv:2507.17476, 2025
arXiv 2025
-
[55]
Slam: Towards efficient multilingual reasoning via selective language alignment
Yuchun Fan, Yongyu Mu, Yilin Wang, Lei Huang, Junhao Ruan, Bei Li, Tong Xiao, Shujian Huang, Xiaocheng Feng, and Jingbo Zhu. Slam: Towards efficient multilingual reasoning via selective language alignment. arXiv preprint arXiv:2501.03681, 2025. URL https://aclanthology.org/2025.coling-main.637/
arXiv 2025
-
[56]
Synworld: Virtual scenario synthesis for agentic action knowledge refinement
Runnan Fang, Xiaobin Wang, Yuan Liang, Shuofei Qiao, Jialong Wu, Zekun Xi, Ningyu Zhang, Yong Jiang, Pengjun Xie, Fei Huang, et al. Synworld: Virtual scenario synthesis for agentic action knowledge refinement. arXiv preprint arXiv:2504.03561, 2025. URL https://arxiv.org/abs/2504.03561
arXiv 2025
-
[57]
Complex Reasoning over Logical Queries on Commonsense Knowledge Graphs
Tianqing Fang, Zeming Chen, Yangqiu Song, and Antoine Bosselut. Complex Reasoning over Logical Queries on Commonsense Knowledge Graphs . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 11365--11384, Bangkok, Thailand, 2024. Association for Computational Linguistics. doi:10.18653/v1/2...
-
[58]
Test of time: A benchmark for evaluating llms on temporal reasoning
Bahare Fatemi, Mehran Kazemi, Anton Tsitsulin, Karishma Malkan, Jinyeong Yim, John Palowitch, Sungyong Seo, Jonathan Halcrow, and Bryan Perozzi. Test of time: A benchmark for evaluating llms on temporal reasoning. arXiv preprint arXiv:2406.09170, 2024. URL https://arxiv.org/abs/2406.09170
arXiv 2024
-
[59]
Video-r1: Reinforcing video reasoning in mllms
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms. arXiv preprint arXiv:2503.21776, 2025. URL https://arxiv.org/abs/2503.21776
Pith/arXiv arXiv 2025
-
[60]
Rag foundry: A framework for enhancing llms for retrieval augmented generation
Daniel Fleischer, Moshe Berchansky, Moshe Wasserblat, and Peter Izsak. Rag foundry: A framework for enhancing llms for retrieval augmented generation. arXiv preprint arXiv:2408.02545, 2024. URL https://arxiv.org/abs/2408.02545
arXiv 2024
-
[61]
Daniel Fleischer, Moshe Berchansky, Gad Markovits, and Moshe Wasserblat. SQuARE: Sequential Question Answering Reasoning Engine for Enhanced Chain-of-Thought in Large Language Models . arXiv preprint arXiv:2502.09390, 2025. doi:10.48550/arXiv.2502.09390. URL https://arxiv.org/abs/2502.09390
-
[62]
Re-adaptir: Improving information retrieval through reverse engineered adaptation
William Fleshman and Benjamin Van Durme. Re-adaptir: Improving information retrieval through reverse engineered adaptation. arXiv preprint arXiv:2406.14764, 2024. URL https://arxiv.org/abs/2406.14764
arXiv 2024
-
[63]
Tairan Fu, Javier Conde, Gonzalo Mart \' nez, Mar \' a Grandury, and Pedro Reviriego. Multiple choice questions: Reasoning makes large language models (llms) more self-confident even when they are wrong. arXiv preprint arXiv:2501.09775, 2025. URL https://arxiv.org/abs/2501.09775
Pith/arXiv arXiv 2025
-
[64]
Efficiently serving llm reasoning programs with certaindex
Yichao Fu, Junda Chen, Siqi Zhu, Zheyu Fu, Zhongdongming Dai, Aurick Qiao, and Hao Zhang. Efficiently serving llm reasoning programs with certaindex. arXiv preprint arXiv:2412.20993, 2024. URL https://arxiv.org/abs/2412.20993
arXiv 2024
-
[65]
Andrey Galichin, Alexey Dontsov, Polina Druzhinina, Anton Razzhigaev, Oleg Y Rogov, Elena Tutubalina, and Ivan Oseledets. I have covered all the bases here: Interpreting reasoning features in large language models via sparse autoencoders. arXiv preprint arXiv:2503.18878, 2025. URL https://arxiv.org/abs/2503.18878
arXiv 2025
-
[66]
Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts
Chunjing Gan, Dan Yang, Binbin Hu, Hanxiao Zhang, Siyuan Li, Ziqi Liu, Yue Shen, Lin Ju, Zhiqiang Zhang, Jinjie Gu, Lei Liang, and Jun Zhou. Similarity is Not All You Need: Endowing Retrieval Augmented Generation with Multi Layered Thoughts . arXiv preprint arXiv:2405.19893, 2024. doi:10.48550/arXiv.2405.19893. URL https://arxiv.org/abs/2405.19893
-
[67]
Understanding social reasoning in language models with language models
Kanishk Gandhi, Jan-Philipp Fr \"a nken, Tobias Gerstenberg, and Noah Goodman. Understanding social reasoning in language models with language models. Advances in Neural Information Processing Systems, 36: 0 13518--13529, 2023. URL https://arxiv.org/abs/2306.15448
arXiv 2023
-
[68]
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars
Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars. arXiv preprint arXiv:2503.01307, 2025. URL https://arxiv.org/abs/2503.01307
Pith/arXiv arXiv 2025
-
[69]
Efficient tool use with chain-of-abstraction reasoning
Silin Gao, Jane Dwivedi-Yu, Ping Yu, Xiaoqing Ellen Tan, Ramakanth Pasunuru, Olga Golovneva, Koustuv Sinha, Asli Celikyilmaz, Antoine Bosselut, and Tianlu Wang. Efficient tool use with chain-of-abstraction reasoning. arXiv preprint arXiv:2401.17464, 2024. URL https://arxiv.org/abs/2401.17464
arXiv 2024
-
[70]
Yubin Ge, Salvatore Romeo, Jason Cai, Raphael Shu, Monica Sunkara, Yassine Benajiba, and Yi Zhang. Tremu: Towards neuro-symbolic temporal reasoning for llm-agents with memory in multi-session dialogues. arXiv preprint arXiv:2502.01630, 2025. URL https://arxiv.org/abs/2502.01630
arXiv 2025
-
[71]
Scaling up test-time compute with latent reasoning: A recurrent depth approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171, 2025. URL https://arxiv.org/abs/2502.05171
Pith/arXiv arXiv 2025
-
[72]
Shortcut learning in deep neural networks
Robert Geirhos, J \"o rn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2 0 (11): 0 665--673, 2020
2020
-
[73]
Large language models are not strong abstract reasoners
Ga \"e l Gendron, Qiming Bao, Michael Witbrock, and Gillian Dobbie. Large language models are not strong abstract reasoners. arXiv preprint arXiv:2305.19555, 2023
arXiv 2023
-
[74]
The multilingual mind: A survey of multilingual reasoning in language models
Akash Ghosh, Debayan Datta, Sriparna Saha, and Chirag Agarwal. The multilingual mind: A survey of multilingual reasoning in language models. arXiv preprint arXiv:2502.09457, 2025. URL https://arxiv.org/abs/2502.09457
arXiv 2025
-
[75]
Compositional preference models for aligning lms
Dongyoung Go, Tomasz Korbak, Germ \'a n Kruszewski, Jos Rozen, and Marc Dymetman. Compositional preference models for aligning lms. arXiv preprint arXiv:2310.13011, 2023. URL https://arxiv.org/abs/2310.13011
arXiv 2023
-
[76]
Great models think alike and this undermines ai oversight
Shashwat Goel, Joschka Struber, Ilze Amanda Auzina, Karuna K Chandra, Ponnurangam Kumaraguru, Douwe Kiela, Ameya Prabhu, Matthias Bethge, and Jonas Geiping. Great models think alike and this undermines ai oversight. arXiv preprint arXiv:2502.04313, 2025. URL https://arxiv.org/abs/2502.04313
arXiv 2025
-
[77]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. Towards an ai co-scientist. arXiv preprint arXiv:2502.18864, 2025. URL https://arxiv.org/abs/2502.18864
Pith/arXiv arXiv 2025
-
[78]
Large language models orchestrating structured reasoning achieve kaggle grandmaster level
Antoine Grosnit, Alexandre Maraval, James Doran, Giuseppe Paolo, Albert Thomas, Refinath Shahul Hameed Nabeezath Beevi, Jonas Gonzalez, Khyati Khandelwal, Ignacio Iacobacci, Abdelhakim Benechehab, et al. Large language models orchestrating structured reasoning achieve kaggle grandmaster level. arXiv preprint arXiv:2411.03562, 2024. URL https://arxiv.org/a...
arXiv 2024
-
[79]
Cruxeval: A benchmark for code reasoning, understanding and execution
Alex Gu, Baptiste Rozi \`e re, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida I Wang. Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065, 2024. URL https://arxiv.org/abs/2401.03065
Pith/arXiv arXiv 2024
-
[80]
Auditing prompt caching in language model apis
Chenchen Gu, Xiang Lisa Li, Rohith Kuditipudi, Percy Liang, and Tatsunori Hashimoto. Auditing prompt caching in language model apis. arXiv preprint arXiv:2502.07776, 2025. URL https://arxiv.org/abs/2502.07776
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.