4DP-QA: Scalable QA for 4D Perception in Vision Language Models
Pith reviewed 2026-06-27 10:54 UTC · model grok-4.3
The pith
A QA generation pipeline with True-Motion Tracking produces 400K samples that improve VLMs on 4D motion reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
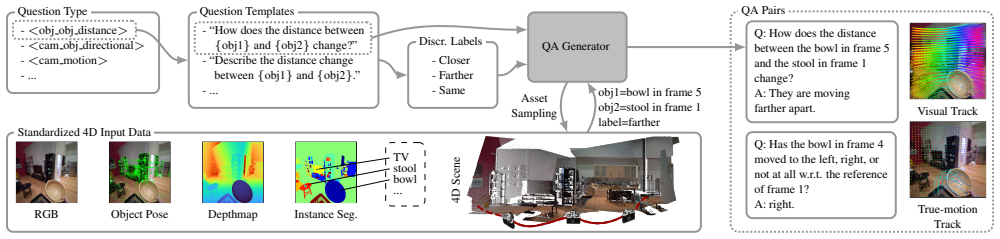
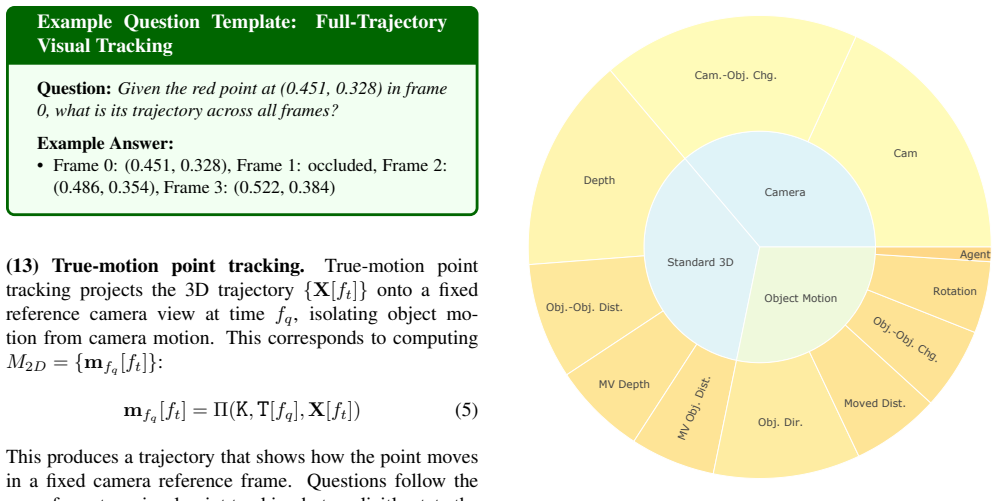
By introducing True-Motion Tracking in a fixed reference system, the pipeline disentangles object and camera motion to create large-scale QA data focused on 4D perception, which when used for training leads to performance gains on external benchmarks.
What carries the argument
True-Motion Tracking, a method of tracking motion in a fixed reference system that gives an intuitive, disentangled description of object and camera movements.
If this is right
- Existing VLMs gain improved 4D scene understanding after training on the generated dataset.
- The method scales the creation of motion-related QA pairs to hundreds of thousands of examples.
- The 4DP-QA-Bench provides a way to evaluate disentangled motion reasoning in VLMs.
- Focus on motion disentanglement addresses a core limitation in current video-language datasets.
Where Pith is reading between the lines
- Similar tracking approaches could be used to create training data for other dynamic scene tasks like prediction or planning.
- Applying the pipeline to real captured videos might further increase dataset diversity without manual labeling.
- The gains suggest that current VLMs lack explicit 4D signals that synthetic disentangled data can supply.
Load-bearing premise
That the True-Motion Tracking accurately separates object motion from camera motion in a way that helps rather than confuses model learning.
What would settle it
If models trained on 4DP-QA show no improvement or reduced performance on the external benchmark compared to baselines, the claim of effectiveness would not hold.
Figures




read the original abstract
Despite recent advances, Vision Language Models (VLMs) still struggle to grasp the dynamics of the world. We note that the ability to reason about a 4D scene, challenging in itself, is further complicated by two factors. First, VLMs observe motion indirectly via its projection onto 2D images. Second, existing datasets fail to disentangle object and camera motion. To address these challenges, we present a QA generation pipeline that focuses on motion-related scene understanding. We take particular care of the entanglement of camera and object motion by casting tracking in both the traditional way and in a novel, fixed reference system, dubbed True-Motion Tracking, which provides an intuitive description of motion. From this pipeline, we generate a large-scale training dataset of 400K samples, 4DP-QA (4D Perception QA), and a 2.2K-sample benchmark, 4DP-QA-Bench. Training existing models on our dataset yields performance improvements on an external benchmark, validating the effectiveness of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a QA generation pipeline for 4D scene understanding in VLMs that addresses indirect motion observation and camera-object motion entanglement. It proposes True-Motion Tracking in a fixed reference system alongside traditional tracking, generates a 400K-sample training dataset (4DP-QA) and 2.2K-sample benchmark (4DP-QA-Bench), and reports that training existing VLMs on the dataset improves performance on an external benchmark.
Significance. If the reported gains are specifically attributable to the disentanglement provided by True-Motion Tracking rather than generic data scale, the dataset and pipeline could meaningfully advance VLM capabilities for dynamic 4D reasoning. The scale of 400K samples and explicit focus on motion disentanglement represent concrete contributions to training resources in this area.
major comments (3)
- [Abstract] Abstract: The central claim that 'training existing models on our dataset yields performance improvements on an external benchmark, validating the effectiveness of our method' is stated without any quantitative results, error bars, baseline numbers, or details on how the external benchmark was evaluated or constructed. This directly undermines assessment of whether the gains support the technical contribution.
- [§3] §3 (pipeline description): No ablation studies are presented comparing models trained with True-Motion Tracking against those using only standard tracking or other motion representations. Without such controls, it is impossible to determine whether observed gains arise from the fixed-reference disentanglement or from increased data volume alone, which is load-bearing for the claim that the novel tracking method is effective.
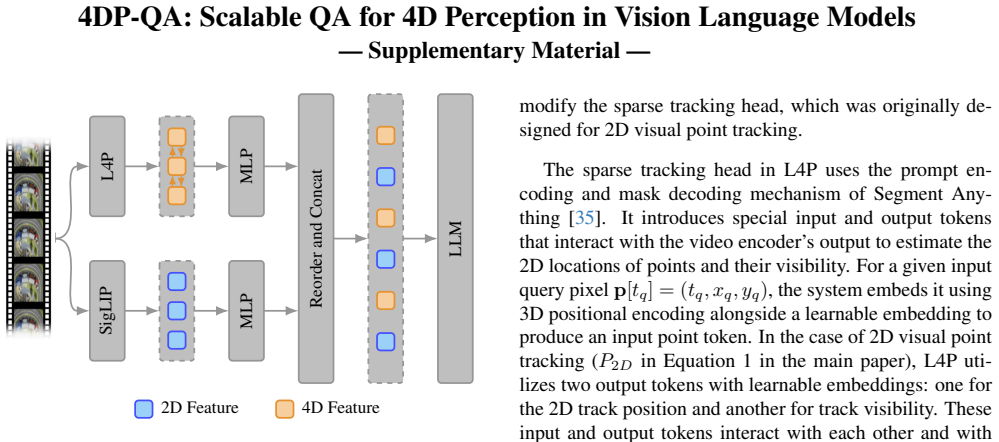
- [§3.2] §3.2 (True-Motion Tracking): The fixed-reference system is described as providing an 'intuitive description of motion' and accurate disentanglement, but no quantitative validation against ground-truth 3D trajectories, projection error metrics, or bias analysis is supplied to confirm it avoids introducing new artifacts compared to traditional tracking.
minor comments (2)
- [Abstract] The abstract and introduction could more clearly distinguish the contributions of the dataset scale versus the tracking innovation.
- [§3] Notation for the fixed reference system and traditional tracking should be formalized with equations to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights areas where the manuscript can better substantiate its claims. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'training existing models on our dataset yields performance improvements on an external benchmark, validating the effectiveness of our method' is stated without any quantitative results, error bars, baseline numbers, or details on how the external benchmark was evaluated or constructed. This directly undermines assessment of whether the gains support the technical contribution.
Authors: We agree that the abstract would benefit from quantitative support. The full manuscript contains experimental results with specific performance metrics on the external benchmark. In the revision, we will update the abstract to include key numbers (e.g., baseline vs. improved accuracies), mention error bars or variance where reported, and briefly note the external benchmark's construction and evaluation protocol. revision: yes
-
Referee: [§3] §3 (pipeline description): No ablation studies are presented comparing models trained with True-Motion Tracking against those using only standard tracking or other motion representations. Without such controls, it is impossible to determine whether observed gains arise from the fixed-reference disentanglement or from increased data volume alone, which is load-bearing for the claim that the novel tracking method is effective.
Authors: This is a fair critique. The current version focuses on the end-to-end pipeline and dataset scale without isolating the tracking component. We will add ablation studies in the revised manuscript that compare VLM performance when trained on data generated with standard tracking versus True-Motion Tracking (holding data volume constant) to demonstrate the specific contribution of the disentanglement. revision: yes
-
Referee: [§3.2] §3.2 (True-Motion Tracking): The fixed-reference system is described as providing an 'intuitive description of motion' and accurate disentanglement, but no quantitative validation against ground-truth 3D trajectories, projection error metrics, or bias analysis is supplied to confirm it avoids introducing new artifacts compared to traditional tracking.
Authors: We acknowledge the absence of direct quantitative validation in §3.2. The method is motivated by its ability to operate in a fixed world coordinate system. In revision, we will expand §3.2 with additional implementation details, qualitative trajectory visualizations, and any available projection consistency metrics. A full ground-truth 3D comparison is constrained by the synthetic generation process, but we will discuss potential artifacts and their mitigation. revision: partial
Circularity Check
No significant circularity; central claim is empirical improvement on external benchmark.
full rationale
The paper generates 4DP-QA via a pipeline including True-Motion Tracking and reports that training VLMs on it improves results on an external benchmark. This validation is measured outside the method's own definitions, fitted values, or self-citations. No load-bearing step reduces a claimed prediction or uniqueness result to an internal fit, self-citation chain, or redefinition by construction. The derivation chain is self-contained against the external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard computer-vision tracking algorithms remain accurate when recast into a fixed reference system.
invented entities (1)
-
True-Motion Tracking
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosmos world foundation model platform for Physical AI.ArXiv Preprint, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for Physical AI.ArXiv Preprint, 2025. 7
2025
-
[2]
Flamingo: A visual language model for few-shot learning.Advances in Neural Information Processing Systems (NeurIPS), 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: A visual language model for few-shot learning.Advances in Neural Information Processing Systems (NeurIPS), 2022. 2
2022
-
[3]
Llava-onevision-1.5: Fully open framework for democratized multimodal training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training. ArXiv Preprint, 2025. 6
2025
-
[4]
ScanQA: 3D question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Mo- toaki Kawanabe. ScanQA: 3D question answering for spatial scene understanding. InIEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2022. 1, 3
2022
-
[5]
L4P: Low-level 4D vision perception unified
Abhishek Badki, Hang Su, Bowen Wen, and Orazio Gallo. L4P: Low-level 4D vision perception unified. InInterna- tional Conference on 3D Vision (3DV), 2026. 3, 5, 7, 8, 9
2026
-
[6]
Qwen2.5-VL: Technical report.ArXiv Preprint,
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL: Technical report.ArXiv Preprint,
-
[7]
1, 2, 4, 5, 6, 7, 17
-
[8]
HOT3D: Hand and object tracking in 3D from ego- centric multi-view videos
Prithviraj Banerjee, Sindi Shkodrani, Pierre Moulon, Shreyas Hampali, Shangchen Han, Fan Zhang, Linguang Zhang, Jade Fountain, Edward Miller, Selen Basol, Richard Newcombe, Robert Wang, Jakob Julian Engel, and Tomas Hodan. HOT3D: Hand and object tracking in 3D from ego- centric multi-view videos. InIEEE Conference on Computer Vision and Pattern Recognitio...
2024
-
[9]
Track2act: Predicting point tracks from internet videos enables generalizable robot manipula- tion
Homanga Bharadhwaj, Roozbeh Mottaghi, Abhinav Gupta, and Shubham Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipula- tion. InEuropean Conference on Computer Vision (ECCV),
-
[10]
Benchmark designers should” train on the test set” to expose exploitable non-visual shortcuts.ArXiv Preprint, 2025
Ellis Brown, Jihan Yang, Shusheng Yang, Rob Fergus, and Saining Xie. Benchmark designers should” train on the test set” to expose exploitable non-visual shortcuts.ArXiv Preprint, 2025. 17
2025
-
[11]
Vir- tual KITTI 2.ArXiv Preprint, 2020
Yohann Cabon, Naila Murray, and Martin Humenberger. Vir- tual KITTI 2.ArXiv Preprint, 2020. 3, 18
2020
-
[12]
SpatialVLM: Endow- ing vision-language models with spatial reasoning capabili- ties
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. SpatialVLM: Endow- ing vision-language models with spatial reasoning capabili- ties. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1, 3
2024
-
[13]
Eagle 2.5: Boosting long-context post-training for frontier vision- language models
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Max Ehrlich, Tong Lu, Limin Wang, Bryan Catanzaro, Jan Kautz, Andrew Tao, Zhiding Yu, and Guilin Liu. Eagle 2.5: Boosting long-context post-training for frontier vision- language models. InAdvances in Neural Information Pro- cessing Systems (Neu...
2025
-
[14]
Scan2Cap: Context-aware dense captioning in rgb-d scans
Zhenyu Chen, Ali Gholami, Matthias Nießner, and Angel X Chang. Scan2Cap: Context-aware dense captioning in rgb-d scans. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 1, 3
2021
-
[15]
InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2024. 2
2024
-
[16]
Spatial- RGPT: Grounded spatial reasoning in vision-language mod- els.Advances in Neural Information Processing Systems (NeurIPS), 2024
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Rui- han Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatial- RGPT: Grounded spatial reasoning in vision-language mod- els.Advances in Neural Information Processing Systems (NeurIPS), 2024. 3
2024
-
[17]
3D aware region prompted vision language model.ArXiv Preprint, 2025
An-Chieh Cheng, Yang Fu, Yukang Chen, Zhijian Liu, Xiao- long Li, Subhashree Radhakrishnan, Song Han, Yao Lu, Jan Kautz, Pavlo Molchanov, et al. 3D aware region prompted vision language model.ArXiv Preprint, 2025. 3
2025
-
[18]
Local all-pair correspon- dence for point tracking.ArXiv Preprint, 2024
Seokju Cho, Jiahui Huang, Jisu Nam, Honggyu An, Seun- gryong Kim, and Joon-Young Lee. Local all-pair correspon- dence for point tracking.ArXiv Preprint, 2024. 3
2024
-
[19]
Seurat: From Moving Points to Depth
Seokju Cho, Jiahui Huang, Seungryong Kim, and Joon- Young Lee. Seurat: From Moving Points to Depth. In IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2025. 3
2025
-
[20]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.ArXiv Preprint, 2025
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.ArXiv Preprint, 2025. 4, 6
2025
-
[21]
TAP-Vid: A benchmark for track- ing any point in a video.Advances in Neural Information Processing Systems (NeurIPS), 2022
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adri `a Re- casens, Lucas Smaira, Yusuf Aytar, Jo ˜ao Carreira, Andrew Zisserman, and Yi Yang. TAP-Vid: A benchmark for track- ing any point in a video.Advances in Neural Information Processing Systems (NeurIPS), 2022. 2, 3, 17
2022
-
[22]
TAPIR: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. TAPIR: Tracking any point with per-frame initialization and temporal refinement. InIEEE International Conference on Computer Vision (ICCV), 2023. 3
2023
-
[23]
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. VLM-3R: Vision-language models aug- mented with instruction-aligned 3D reconstruction.arXiv preprint arXiv:2505.20279, 2025. 3, 5, 17
Pith/arXiv arXiv 2025
-
[24]
MeshLLM: Empowering large lan- guage models to progressively understand and generate 3D mesh
Shuangkang Fang, I Shen, Yufeng Wang, Yi-Hsuan Tsai, Yi Yang, Shuchang Zhou, Wenrui Ding, Takeo Igarashi, Ming-Hsuan Yang, et al. MeshLLM: Empowering large lan- guage models to progressively understand and generate 3D mesh. InIEEE International Conference on Computer Vi- sion (ICCV), 2025. 2
2025
-
[25]
St4RTrack: Simultaneous 4D reconstruction and tracking in the world
Haiwen Feng, Junyi Zhang, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J Black, Trevor Darrell, and Angjoo Kanazawa. St4RTrack: Simultaneous 4D reconstruction and tracking in the world. InIEEE International Conference on Computer Vision (ICCV), 2025. 3 19
2025
-
[26]
Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 3
2025
-
[27]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Com- puter Vision (ECCV), 2024. 17
2024
-
[28]
Ego4D: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the world in 3,000 hours of egocentric video. In IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2022. 7
2022
-
[29]
Kubric: A scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapra- gasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3, 18
2022
-
[30]
ReVisionLLM: Recur- sive vision-language model for temporal grounding in hour- long videos
Tanveer Hannan, Md Mohaiminul Islam, Jindong Gu, Thomas Seidl, and Gedas Bertasius. ReVisionLLM: Recur- sive vision-language model for temporal grounding in hour- long videos. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[31]
Gpt-4o system card
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. ArXiv Preprint, 2024. 6
2024
-
[32]
Omnispa- tial: Towards comprehensive spatial reasoning benchmark for vision language models
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispa- tial: Towards comprehensive spatial reasoning benchmark for vision language models. InInternational Conference on Learning Representations (ICLR), 2026. 17
2026
-
[33]
Token-efficient long video understanding for multimodal LLMs.ArXiv Preprint, 2025
Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, Zhiqi Li, De-An Huang, Guilin Liu, Zhiding Yu, Kurt Keutzer, et al. Token-efficient long video understanding for multimodal LLMs.ArXiv Preprint, 2025. 2
2025
-
[34]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.ArXiv Preprint, 2020. 1
2020
-
[35]
Co- Tracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- Tracker: It is better to track together. InEuropean Confer- ence on Computer Vision (ECCV), 2024. 2, 3
2024
-
[36]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. SAM: Segment anything.ArXiv Preprint,
-
[37]
ST-VLM: Kine- matic instruction tuning for spatio-temporal reasoning in vision-language models.ArXiv Preprint, 2025
Dohwan Ko, Sihyeon Kim, Yumin Suh, Minseo Yoon, Man- mohan Chandraker, Hyunwoo J Kim, et al. ST-VLM: Kine- matic instruction tuning for spatio-temporal reasoning in vision-language models.ArXiv Preprint, 2025. 3
2025
-
[38]
SEED-Bench: Benchmarking multimodal large language models
Bohao Li, Yuying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. SEED-Bench: Benchmarking multimodal large language models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[39]
LLaVa-OneVision: Easy visual task transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. LLaVa-OneVision: Easy visual task transfer. ArXiv Preprint, 2024. 3, 6
2024
-
[40]
FrameOracle: Learning what to see and how much to see in videos.ArXiv Preprint, 2025
Chaoyu Li, Tianzhi Li, Fei Tao, Zhenyu Zhao, Ziqian Wu, Maozheng Zhao, Juntong Song, Cheng Niu, and Pooyan Fa- zli. FrameOracle: Learning what to see and how much to see in videos.ArXiv Preprint, 2025. 2
2025
-
[41]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational Conference on Machine Learning (ICML), 2023. 2
2023
-
[42]
STI-Bench: Are MLLMs ready for precise spatial-temporal world understanding? InIEEE International Conference on Computer Vision (ICCV), 2025
Yun Li, Yiming Zhang, Tao Lin, XiangRui Liu, Wenxiao Cai, Zheng Liu, and Bo Zhao. STI-Bench: Are MLLMs ready for precise spatial-temporal world understanding? InIEEE International Conference on Computer Vision (ICCV), 2025. 3
2025
-
[43]
Depth anything 3: Recovering the visual space from any views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. ArXiv Preprint, 2025. 4
2025
-
[44]
VILA: On pre-training for vi- sual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Moham- mad Shoeybi, and Song Han. VILA: On pre-training for vi- sual language models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2, 3, 5
2024
-
[45]
Visual instruction tuning.Advances in Neural Information Processing Systems (NeurIPS), 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems (NeurIPS), 2023. 1, 2
2023
-
[46]
MMBench: Is your multi-modal model an all-around player? InEuropean Conference on Computer Vision (ECCV), 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. MMBench: Is your multi-modal model an all-around player? InEuropean Conference on Computer Vision (ECCV), 2024. 3
2024
-
[47]
NVILA: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yux- ian Gu, Dacheng Li, Xiuyu Li, Yunhao Fang, Yukang Chen, Cheng-Yu Hsieh, De-An Huang, An-Chieh Cheng, Vish- wesh Nath, Jinyi Hu, Sifei Liu, Ranjay Krishna, Daguang Xu, Xiaolong Wang, Pavlo Molchanov, Jan Kautz, Hongxu Yin, Song Han, and Yao Lu. NVILA:...
2025
-
[48]
SQA3D: Situ- ated question answering in 3D scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. SQA3D: Situ- ated question answering in 3D scenes. InInternational Con- ference on Learning Representations (ICLR), 2023. 1, 3
2023
-
[49]
Aria Digital Twin: A new benchmark dataset for egocentric 3D machine percep- tion
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Pe- ters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria Digital Twin: A new benchmark dataset for egocentric 3D machine percep- tion. InIEEE International Conference on Computer Vision (ICCV), 2023. 3, 18 20
2023
-
[50]
The 2017 DA VIS challenge on video object segmentation.ArXiv Preprint, 2017
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 DA VIS challenge on video object segmentation.ArXiv Preprint, 2017. 7, 8
2017
-
[51]
GPT4Point: A unified framework for point-language understanding and generation
Zhangyang Qi, Ye Fang, Zeyi Sun, Xiaoyang Wu, Tong Wu, Jiaqi Wang, Dahua Lin, and Hengshuang Zhao. GPT4Point: A unified framework for point-language understanding and generation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[52]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInternational Conference on Machine Learning (ICML), 2021. 1
2021
-
[53]
SAT: Dynamic spatial aptitude training for multimodal language models
Arijit Ray, Jiafei Duan, Ellis Brown, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kem- bhavi, Bryan A Plummer, Ranjay Krishna, et al. SAT: Dynamic spatial aptitude training for multimodal language models. InConference on Language Modeling (COLM),
-
[54]
What does CLIP know about a red circle? Visual prompt engineering for VLMs
Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. What does CLIP know about a red circle? Visual prompt engineering for VLMs. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2023. 4, 5, 12
2023
-
[55]
SHIFT: A synthetic driving dataset for continuous multi-task domain adaptation
Tao Sun, Mattia Segu, Janis Postels, Yuxuan Wang, Luc Van Gool, Bernt Schiele, Federico Tombari, and Fisher Yu. SHIFT: A synthetic driving dataset for continuous multi-task domain adaptation. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3, 18
2022
-
[56]
Gemini robotics: Bringing ai into the physical world.ArXiv Preprint, 2025
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Are- nas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.ArXiv Preprint, 2025. 6
2025
-
[57]
DriveVLM: The convergence of autonomous driving and large vision-language models.ArXiv Preprint,
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Zhiyong Zhao, Yang Wang, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. DriveVLM: The convergence of autonomous driving and large vision-language models.ArXiv Preprint,
-
[58]
VGGSfM: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. VGGSfM: Visual geometry grounded deep structure from motion. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[59]
SpatialVID: A large-scale video dataset with spatial annotations.ArXiv Preprint, 2025
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. SpatialVID: A large-scale video dataset with spatial annotations.ArXiv Preprint, 2025. 3
2025
-
[60]
Continuous 3D per- ception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3D per- ception model with persistent state. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 3, 4
2025
-
[61]
InternVideo2: Scaling foundation models for mul- timodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. InternVideo2: Scaling foundation models for mul- timodal video understanding. InEuropean Conference on Computer Vision (ECCV), 2024. 1, 2
2024
-
[62]
Llama-Mesh: Unifying 3D mesh generation with language models.ArXiv Preprint, 2024
Zhengyi Wang, Jonathan Lorraine, Yikai Wang, Hang Su, Jun Zhu, Sanja Fidler, and Xiaohui Zeng. Llama-Mesh: Unifying 3D mesh generation with language models.ArXiv Preprint, 2024. 2
2024
-
[63]
Any-point trajectory modeling for policy learning.ArXiv Preprint, 2024
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning.ArXiv Preprint, 2024. 2
2024
-
[64]
SpatialTrackerV2: 3D point tracking made easy
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Iurii Makarov, Bingyi Kang, Xin Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. SpatialTrackerV2: 3D point tracking made easy. InIEEE International Conference on Computer Vision (ICCV), 2025. 3
2025
-
[65]
SpatialTrackerV2: 3D point tracking made easy
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. SpatialTrackerV2: 3D point tracking made easy. InIEEE International Conference on Computer Vision (ICCV), 2025. 3
2025
-
[66]
Video- MTR: Reinforced multi-turn reasoning for long video under- standing.ArXiv Preprint, 2025
Yuan Xie, Tianshui Chen, Zheng Ge, and Lionel Ni. Video- MTR: Reinforced multi-turn reasoning for long video under- standing.ArXiv Preprint, 2025. 2
2025
-
[67]
Youtube-VOS: A large-scale video object segmentation benchmark.ArXiv Preprint, 2018
Ning Xu, Linjie Yang, Yuchen Fan, Dingcheng Yue, Yuchen Liang, Jianchao Yang, and Thomas Huang. Youtube-VOS: A large-scale video object segmentation benchmark.ArXiv Preprint, 2018. 7
2018
-
[68]
PointLLM: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiang- miao Pang, and Dahua Lin. PointLLM: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision (ECCV), 2024. 2
2024
-
[69]
Qwen3 technical report.ArXiv Preprint, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.ArXiv Preprint, 2025. 5, 6, 11, 17
2025
-
[70]
Thinking in space: How mul- timodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces. InIEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), 2025. 3, 5, 7
2025
-
[71]
MMSI-Bench: A benchmark for multi- image spatial intelligence.ArXiv Preprint, 2025
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, et al. MMSI-Bench: A benchmark for multi- image spatial intelligence.ArXiv Preprint, 2025. 17
2025
-
[72]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InIEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2023. 9
2023
-
[73]
Tapip3d: Tracking any point in persistent 3d geome- try.arXiv preprint arXiv:2504.14717, 2025
Bowei Zhang, Lei Ke, Adam W Harley, and Katerina Fragki- adaki. Tapip3d: Tracking any point in persistent 3d geome- try.arXiv preprint arXiv:2504.14717, 2025. 3
arXiv 2025
-
[74]
Vision-language models for vision tasks: A survey.pami,
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.pami,
-
[75]
From Flatland to Space: Teaching vision-language models to perceive and reason in 3D.ArXiv Preprint, 2025
Jiahui Zhang, Yurui Chen, Yanpeng Zhou, Yueming Xu, Ze Huang, Jilin Mei, Junhui Chen, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, et al. From Flatland to Space: Teaching vision-language models to perceive and reason in 3D.ArXiv Preprint, 2025. 3, 17 21
2025
-
[76]
Video-3D LLM: Learning position-aware video representation for 3D scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3D LLM: Learning position-aware video representation for 3D scene understanding. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[77]
Uni4D-LLM: A unified spatiotemporal-aware VLM for 4D understanding and gen- eration.ArXiv Preprint, 2025
Hanyu Zhou and Gim Hee Lee. Uni4D-LLM: A unified spatiotemporal-aware VLM for 4D understanding and gen- eration.ArXiv Preprint, 2025. 2
2025
-
[78]
VLM4D: Towards spatiotemporal awareness in vision language mod- els
Shijie Zhou, Alexander Vilesov, Xuehai He, Ziyu Wan, Shuwang Zhang, Aditya Nagachandra, Di Chang, Dong- dong Chen, Xin Eric Wang, and Achuta Kadambi. VLM4D: Towards spatiotemporal awareness in vision language mod- els. InIEEE International Conference on Computer Vision (ICCV), 2025. 3, 6, 7
2025
-
[79]
LLaV A-3D: A simple yet effective pathway to empowering LLLMs with 3D-awareness.ArXiv Preprint,
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. LLaV A-3D: A simple yet effective pathway to empowering LLLMs with 3D-awareness.ArXiv Preprint,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.