Understanding Cross-Sensor Feature Variations for Generalizable 3D Perception
Pith reviewed 2026-06-27 10:48 UTC · model grok-4.3
The pith
Modeling visual scene variations in the frequency domain allows regularizing radar-camera BEV fusion for better cross-dataset 3D detection without target samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By characterizing visual scene variations in the frequency domain and synthesizing diverse source-domain views, the framework captures how image-level variations influence multi-modal BEV features. These variation patterns regularize the detector to keep the learned fusion space stable under latent scene changes, improving generalization across datasets without requiring target-domain samples.
What carries the argument
A frequency-domain variation modeling framework that synthesizes source-domain views and uses the resulting BEV feature comparisons to regularize the multi-modal fusion space.
If this is right
- Consistent performance improvements on cross-dataset radar-camera 3D detection tasks between View-of-Delft and TJ4DRadSet across multiple BEV fusion backbones.
- The regularization remains beneficial even when a small amount of target-domain data is incorporated during training.
- The approach requires no changes to the inference pipeline as it operates only during training.
- Encourages the fusion space to be invariant to certain image-level variations derived from frequency analysis.
Where Pith is reading between the lines
- Similar frequency-based regularization could apply to other sensor combinations like lidar-camera in 3D perception.
- Identifying specific frequency bands that correspond to cross-sensor shifts might allow more targeted regularization.
- Combining this source-only method with light domain adaptation could yield further gains in low-data target scenarios.
- Extending the synthesis to include radar-specific variations alongside visual ones might strengthen the approach.
Load-bearing premise
That frequency domain analysis of visual scenes can generate source variations that accurately represent the effects of real cross-dataset differences on the fused BEV features.
What would settle it
Running the method on View-of-Delft to TJ4DRadSet and observing no improvement or a performance drop compared to the unregularized baseline would falsify the effectiveness of the regularization.
Figures

read the original abstract
Radar-camera BEV perception often suffers from degraded performance when evaluated across datasets, as changes in driving scenes, sensor configurations, and environmental conditions can alter both the input observations and the internal fused representations. This work studies this issue from the perspective of source-domain variation modeling, aiming to improve the robustness of BEV-based 3D detectors without relying on target-domain samples. We introduce a framework that characterizes visual scene variations in the frequency domain and uses them to synthesize diverse source-domain views. By comparing the resulting fused BEV representations, the framework further captures how image-level variations influence multi-modal BEV features. These variation patterns are then used to regularize the detector, encouraging the learned fusion space to remain stable under latent scene changes. The proposed method is applied only during training and leaves the inference pipeline unchanged. Experiments on cross-dataset radar-camera 3D detection between View-of-Delft and TJ4DRadSet demonstrate consistent improvements over multiple BEV fusion backbones, and the gains remain effective when a small amount of target-domain data is available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that radar-camera BEV 3D detectors suffer from cross-dataset degradation due to variations in scenes, sensor configurations, and conditions; it addresses this by characterizing visual scene variations in the frequency domain, synthesizing diverse source-domain views, comparing the resulting BEV features to capture image-level influences on multi-modal fusion, and using the resulting patterns as a regularization signal during training (without changing inference). Experiments on View-of-Delft to TJ4DRadSet cross-dataset radar-camera 3D detection report consistent gains over multiple BEV fusion backbones, with the gains persisting when limited target-domain data is available.
Significance. If the central mechanism holds, the work would provide a practical, source-only regularization approach for multi-modal BEV perception that improves robustness to domain shift without requiring target samples at test time. The frequency-domain synthesis and BEV-feature comparison steps, if shown to produce stable regularization targets, would constitute a concrete technical contribution to generalizable 3D detection.
major comments (2)
- [Abstract, §3] Abstract and §3 (method overview): the paper explicitly lists sensor-configuration changes among the sources of cross-dataset degradation, yet the proposed pipeline characterizes and synthesizes only visual image variations in the frequency domain. No mechanism is described for propagating or modeling the effect of differing radar/camera intrinsics or extrinsics on the fused BEV features; if the learned regularization subspace therefore omits the dominant cross-sensor component, the reported gains on VoD↔TJ4DRadSet cannot be attributed to the claimed variation-capture process.
- [§4.2] §4.2 (experiments): the cross-dataset results are presented as evidence that the regularization stabilizes the fusion space, but the evaluation does not include an ablation that isolates the contribution of frequency-domain synthesis versus generic data-augmentation or feature-level consistency losses. Without this control, it remains unclear whether the observed improvements stem from the specific variation-modeling claim or from incidental regularization effects.
minor comments (2)
- [§3.1] Notation for the frequency-domain representation and the subsequent BEV-feature comparison operator should be introduced once and used consistently; several symbols appear to be redefined between the synthesis and regularization subsections.
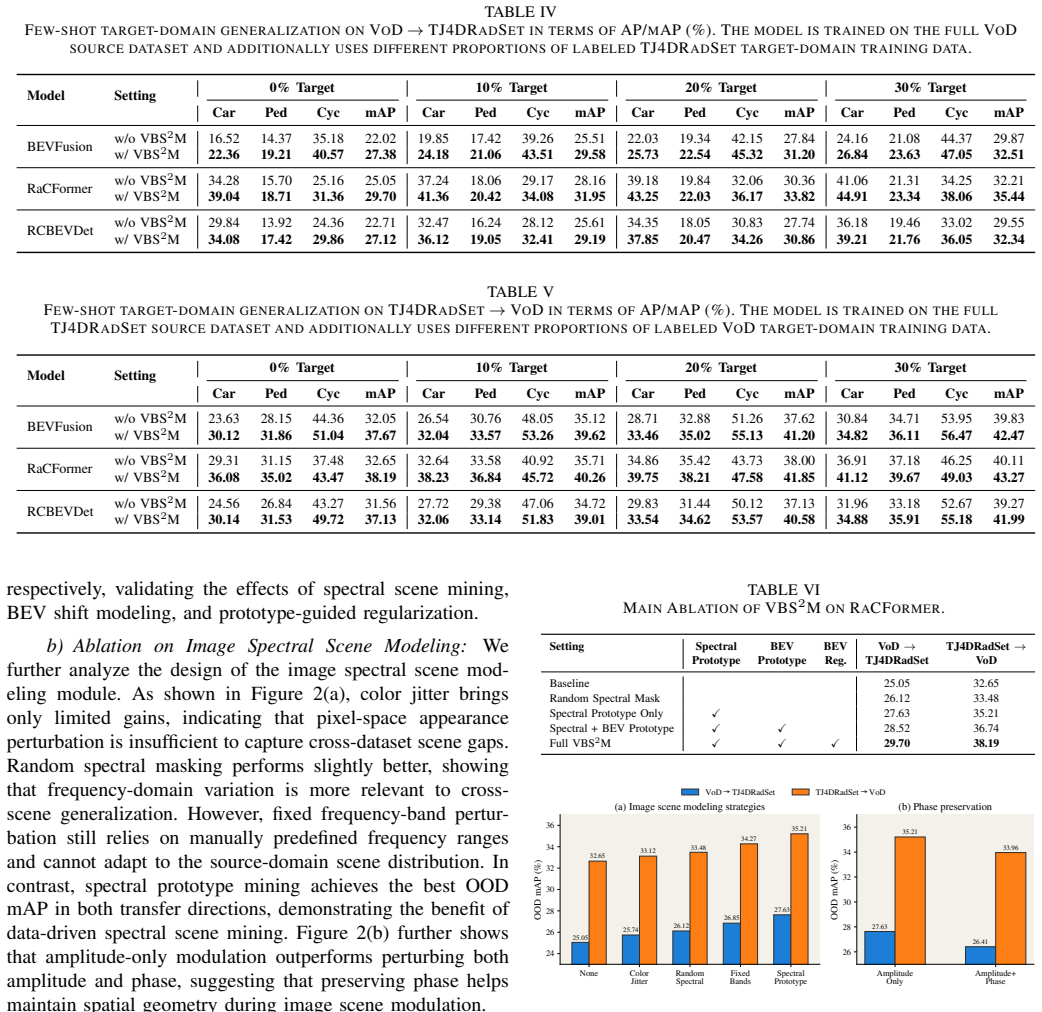
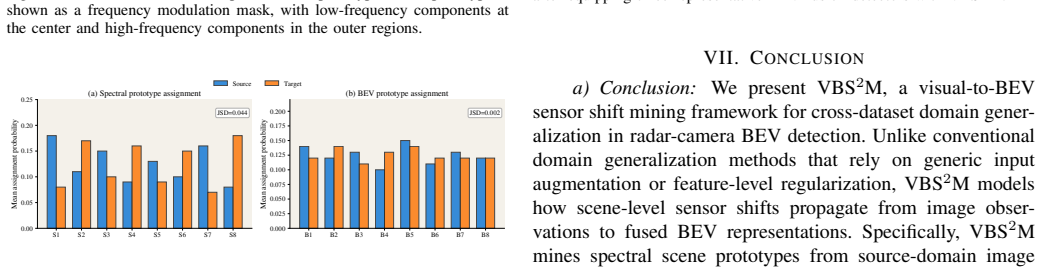
- [Figure 2, §3.3] Figure 2 caption and the corresponding text in §3.3 refer to “latent scene changes” without clarifying whether these are the synthesized frequency variations or an additional latent variable; the distinction affects how readers interpret the regularization objective.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method overview): the paper explicitly lists sensor-configuration changes among the sources of cross-dataset degradation, yet the proposed pipeline characterizes and synthesizes only visual image variations in the frequency domain. No mechanism is described for propagating or modeling the effect of differing radar/camera intrinsics or extrinsics on the fused BEV features; if the learned regularization subspace therefore omits the dominant cross-sensor component, the reported gains on VoD↔TJ4DRadSet cannot be attributed to the claimed variation-capture process.
Authors: We acknowledge the observation. The abstract lists sensor-configuration changes among general sources of degradation, but the method explicitly models only visual scene variations via frequency-domain synthesis and uses the resulting BEV-feature comparisons as the regularization signal. The VoD-to-TJ4DRadSet experiments do involve differing sensor setups, and the gains show that visual-variation regularization improves fusion stability even when sensor differences are present. However, we do not describe an explicit propagation mechanism for intrinsics/extrinsics. In revision we will update the abstract and §3 to state the scope more precisely (visual variations only) while retaining the cross-dataset results as evidence of practical benefit. This is a partial revision for clarity. revision: partial
-
Referee: [§4.2] §4.2 (experiments): the cross-dataset results are presented as evidence that the regularization stabilizes the fusion space, but the evaluation does not include an ablation that isolates the contribution of frequency-domain synthesis versus generic data-augmentation or feature-level consistency losses. Without this control, it remains unclear whether the observed improvements stem from the specific variation-modeling claim or from incidental regularization effects.
Authors: We agree that an isolating ablation is needed. In the revised manuscript we will add controlled experiments comparing the full frequency-domain pipeline against (i) generic image-level augmentations and (ii) standard feature-consistency losses without frequency synthesis, using the same backbones and cross-dataset protocol. This will clarify whether the reported gains arise from the specific variation-modeling mechanism. revision: yes
Circularity Check
No significant circularity; derivation is self-contained with external experimental validation.
full rationale
The paper introduces a training-time regularization framework that characterizes visual variations in the frequency domain, synthesizes source views, compares resulting BEV features, and applies the learned patterns to stabilize multi-modal fusion. No equations or steps are presented that reduce a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction. The central mechanism is an explicit synthesis-and-comparison procedure whose outputs are used as regularization targets; this is not equivalent to the input data by definition. Experiments on View-of-Delft to TJ4DRadSet transfer provide independent falsifiable evidence. The reader's assessment of score 2.0 is consistent with at most a minor non-load-bearing self-citation (none visible here). No patterns from the enumerated list are exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges,
D. Feng, C. Haase-Sch ¨utz, L. Rosenbaum, H. Hertlein, C. Glaeser, F. Timm, W. Wiesbeck, and K. Dietmayer, “Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges,” IEEE Transactions on Intelligent Transporta- tion Systems, vol. 22, no. 3, pp. 1341–1360, 2020
2020
-
[2]
Seeing through fog without seeing fog: Deep multi- modal sensor fusion in unseen adverse weather,
M. Bijelic, T. Gruber, F. Mannan, F. Kraus, W. Ritter, K. Dietmayer, and F. Heide, “Seeing through fog without seeing fog: Deep multi- modal sensor fusion in unseen adverse weather,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pp. 11682–11692, 2020
2020
-
[3]
Shift: a synthetic driving dataset for continuous multi-task domain adaptation,
T. Sun, M. Segu, J. Postels, Y . Wang, L. Van Gool, B. Schiele, F. Tombari, and F. Yu, “Shift: a synthetic driving dataset for continuous multi-task domain adaptation,” in Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition , pp. 21371–21382, 2022
2022
-
[4]
Unimode: Unified monocular 3d object detection,
Z. Li, X. Xu, S. Lim, and H. Zhao, “Unimode: Unified monocular 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 16561–16570, 2024
2024
-
[5]
Bev-dg: Cross-modal learning under bird’s-eye view for domain generalization of 3d semantic segmentation,
M. Li, Y . Zhang, X. Ma, Y . Qu, and Y . Fu, “Bev-dg: Cross-modal learning under bird’s-eye view for domain generalization of 3d semantic segmentation,” in Proceedings of the IEEE/CVF International Confer- ence on Computer Vision , pp. 11632–11642, 2023
2023
-
[6]
Unsupervised domain adaptation for monocular 3d object detection via self-training,
Z. Li, Z. Chen, A. Li, L. Fang, Q. Jiang, X. Liu, and J. Jiang, “Unsupervised domain adaptation for monocular 3d object detection via self-training,” in European conference on computer vision, pp. 245–262, Springer, 2022
2022
-
[7]
Da- bev: Unsupervised domain adaptation for bird’s eye view perception,
K. Jiang, J. Huang, W. Xie, J. Lei, Y . Li, L. Shao, and S. Lu, “Da- bev: Unsupervised domain adaptation for bird’s eye view perception,” in European Conference on Computer Vision , pp. 322–341, Springer, 2024
2024
-
[8]
Cross-dataset sensor align- ment: Making visual 3d object detector generalizable,
L. Zheng, Y . Liu, Y . Wang, and H. Zhao, “Cross-dataset sensor align- ment: Making visual 3d object detector generalizable,” in Conference on Robot Learning , pp. 1903–1929, PMLR, 2023
1903
-
[9]
4seasons: A cross-season dataset for multi- weather slam in autonomous driving,
P. Wenzel, R. Wang, N. Yang, Q. Cheng, Q. Khan, L. V on Stumberg, N. Zeller, and D. Cremers, “4seasons: A cross-season dataset for multi- weather slam in autonomous driving,” in DAGM German Conference on Pattern Recognition, pp. 404–417, Springer, 2020
2020
-
[10]
Domain generalization of 3d object detection by density-resampling,
S. Li, L. Ma, and X. Li, “Domain generalization of 3d object detection by density-resampling,” in European Conference on Computer Vision , pp. 456–473, Springer, 2024
2024
-
[11]
Roburcdet: Enhancing robustness of radar-camera fusion in bird's eye view for 3d object detection,
J. Yue, Z. Lin, X. Lin, X. Zhou, X. Li, L. Qi, Y . Wang, and M.-H. Yang, “Roburcdet: Enhancing robustness of radar-camera fusion in bird's eye view for 3d object detection,” in International Conference on Learning Representations, vol. 2025, pp. 12726–12741, 2025
2025
-
[12]
Rc- bevfusion: A plug-in module for radar-camera bird’s eye view feature fusion,
L. St ¨acker, S. Mishra, P. Heidenreich, J. Rambach, and D. Stricker, “Rc- bevfusion: A plug-in module for radar-camera bird’s eye view feature fusion,” in DAGM German Conference on Pattern Recognition, pp. 178– 194, Springer, 2023
2023
-
[13]
Rcbevdet: Radar-camera fusion in bird’s eye view for 3d object detection,
Z. Lin, Z. Liu, Z. Xia, X. Wang, Y . Wang, S. Qi, Y . Dong, N. Dong, L. Zhang, and C. Zhu, “Rcbevdet: Radar-camera fusion in bird’s eye view for 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 14928– 14937, 2024
2024
-
[14]
Bevuda: Multi-geometric space alignments for domain adaptive bev 3d object detection,
J. Liu, R. Zhang, X. Li, X. Chi, Z. Chen, M. Lu, Y . Guo, and S. Zhang, “Bevuda: Multi-geometric space alignments for domain adaptive bev 3d object detection,” in 2024 IEEE International Conference on Robotics and Automation (ICRA) , pp. 9487–9494, IEEE, 2024
2024
-
[15]
Bevuda++: geometric-aware unsupervised domain adaptation for multi- view 3d object detection,
R. Zhang, J. Liu, X. Li, X. Chi, D. Wang, L. Du, Y . Du, and S. Zhang, “Bevuda++: geometric-aware unsupervised domain adaptation for multi- view 3d object detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 5, pp. 5109–5122, 2024
2024
-
[16]
Domain generalization through data augmentation: A survey of methods, applications, and challenges,
J. Mai, C. Gao, and J. Bao, “Domain generalization through data augmentation: A survey of methods, applications, and challenges,” Mathematics, vol. 13, no. 5, p. 824, 2025
2025
-
[17]
Domain generalization via invariant feature representation,
K. Muandet, D. Balduzzi, and B. Sch ¨olkopf, “Domain generalization via invariant feature representation,” in International conference on machine learning, pp. 10–18, PMLR, 2013
2013
-
[18]
Generalizing to unseen domains: A survey on domain generalization,
J. Wang, C. Lan, C. Liu, Y . Ouyang, T. Qin, W. Lu, Y . Chen, W. Zeng, and P. S. Yu, “Generalizing to unseen domains: A survey on domain generalization,” IEEE transactions on knowledge and data engineering , vol. 35, no. 8, pp. 8052–8072, 2022
2022
-
[19]
On the benefits of representation regularization in invariance based domain generalization,
C. Shui, B. Wang, and C. Gagn ´e, “On the benefits of representation regularization in invariance based domain generalization,” Machine Learning, vol. 111, no. 3, pp. 895–915, 2022
2022
-
[20]
Towards generalizable multi-camera 3d object detection via perspective render- ing,
H. Lu, Y . Zhang, G. Wang, Q. Lian, D. Du, and Y .-C. Chen, “Towards generalizable multi-camera 3d object detection via perspective render- ing,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 39, pp. 5811–5819, 2025
2025
-
[21]
Multi- class road user detection with 3+ 1d radar in the view-of-delft dataset,
A. Palffy, E. Pool, S. Baratam, J. F. Kooij, and D. M. Gavrila, “Multi- class road user detection with 3+ 1d radar in the view-of-delft dataset,” IEEE Robotics and Automation Letters , vol. 7, no. 2, pp. 4961–4968, 2022
2022
-
[22]
Tj4dradset: A 4d radar dataset for au- tonomous driving,
L. Zheng, Z. Ma, X. Zhu, B. Tan, S. Li, K. Long, W. Sun, S. Chen, L. Zhang, M. Wan, et al. , “Tj4dradset: A 4d radar dataset for au- tonomous driving,” in 2022 IEEE 25th international conference on intelligent transportation systems (ITSC) , pp. 493–498, IEEE, 2022
2022
-
[23]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” in 2023 IEEE international conference on robotics and automation (ICRA), pp. 2774–2781, ieee, 2023
2023
-
[24]
Racformer: Towards high-quality 3d object detection via query-based radar-camera fusion,
X. Chu, J. Deng, G. You, Y . Duan, H. Li, and Y . Zhang, “Racformer: Towards high-quality 3d object detection via query-based radar-camera fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 17081–17091, 2025
2025
-
[25]
Bridging domain generalization to multimodal domain generalization via unified representations,
H. Huang, Y . Xia, S. Zhou, H. Wang, S. Wang, and Z. Zhao, “Bridging domain generalization to multimodal domain generalization via unified representations,” in Proceedings of the IEEE/CVF International Confer- ence on Computer Vision , pp. 22488–22498, 2025
2025
-
[26]
Open domain generalization with domain-augmented meta-learning,
Y . Shu, Z. Cao, C. Wang, J. Wang, and M. Long, “Open domain generalization with domain-augmented meta-learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9624–9633, 2021
2021
-
[27]
Augmentation-based domain generalization for semantic segmentation,
M. Schwonberg, F. El Bouazati, N. M. Schmidt, and H. Gottschalk, “Augmentation-based domain generalization for semantic segmentation,” in 2023 IEEE Intelligent Vehicles Symposium (IV), pp. 1–8, IEEE, 2023
2023
-
[28]
Object-aware domain gen- eralization for object detection,
W. Lee, D. Hong, H. Lim, and H. Myung, “Object-aware domain gen- eralization for object detection,” in proceedings of the AAAI conference on artificial intelligence , vol. 38, pp. 2947–2955, 2024
2024
-
[29]
Out-of-distribution generalization via risk extrapolation (rex),
D. Krueger, E. Caballero, J.-H. Jacobsen, A. Zhang, J. Binas, D. Zhang, R. Le Priol, and A. Courville, “Out-of-distribution generalization via risk extrapolation (rex),” in International conference on machine learning , pp. 5815–5826, PMLR, 2021
2021
-
[30]
Boosting domain generalized and adaptive detection with diffusion models: Fitness, generalization, and transferability,
B. He, Y . Ji, Z. Tan, and L. Wu, “Boosting domain generalized and adaptive detection with diffusion models: Fitness, generalization, and transferability,” in Proceedings of the IEEE/CVF International Confer- ence on Computer Vision , pp. 1912–1923, 2025
1912
-
[31]
Towards single-source domain generalized object detection via causal visual prompts,
C. Li, H. Xu, C. Gao, Z. Wang, Y . Liu, and X. Zhu, “Towards single-source domain generalized object detection via causal visual prompts,” Advances in Neural Information Processing Systems , vol. 38, pp. 104893–104921, 2026
2026
-
[32]
From dataset to real-world: general 3d object detection via generalized cross-domain few-shot learning,
S. Li, J. Shen, L. Ma, and X. Li, “From dataset to real-world: general 3d object detection via generalized cross-domain few-shot learning,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 40, pp. 6415–6423, 2026
2026
-
[33]
X. Feng, W. Zhang, L. Zhang, Y . Zhuge, H. Lu, and Y . He, “Towards cross-platform generalization: Domain adaptive 3d detection with aug- mentation and pseudo-labeling,”arXiv preprint arXiv:2601.08174, 2026
arXiv 2026
-
[34]
Rpgfusion: 4d radar prior-guided multi-modal fusion for 3d detection,
X. Qiu and W. Liu, “Rpgfusion: 4d radar prior-guided multi-modal fusion for 3d detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 284–294, 2026
2026
-
[35]
Cvfusion: Cross-view fusion of 4d radar and camera for 3d object detection,
H. Zhong, Z. Xiang, R. Xu, J. Fu, P. Xu, S. Wang, Z. Yang, T. Pu, and E. Liu, “Cvfusion: Cross-view fusion of 4d radar and camera for 3d object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision , pp. 28188–28197, 2025
2025
-
[36]
Rctrans: Radar-camera transformer via radar densifier and sequential decoder for 3d object detection,
Y . Li, Y . Yang, and Z. Lei, “Rctrans: Radar-camera transformer via radar densifier and sequential decoder for 3d object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 39, pp. 5048– 5056, 2025
2025
-
[37]
R4det: 4d radar-camera fusion for high-performance 3d object detection,
Z. Xia, Y . Tang, Y . Wang, Z. Wang, and W. Qin, “R4det: 4d radar-camera fusion for high-performance 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 18766–18775, 2026
2026
-
[38]
Sdef-bev: spatial-aware dual-expert radar-camera fusion for robust bev 3d object detection,
J. Li, X. Bai, Q. Liu, S. Xiong, and H. Wang, “Sdef-bev: spatial-aware dual-expert radar-camera fusion for robust bev 3d object detection,” Scientific Reports, 2026
2026
-
[39]
Radiate: A radar dataset for automotive perception in bad weather,
M. Sheeny, E. De Pellegrin, S. Mukherjee, A. Ahrabian, S. Wang, and A. Wallace, “Radiate: A radar dataset for automotive perception in bad weather,” in 2021 IEEE International Conference on Robotics and Automation (ICRA) , pp. 1–7, IEEE, 2021
2021
-
[40]
D. Wu, F. Yang, B. Xu, P. Liao, and B. Liu, “A survey of deep learning based radar and vision fusion for 3d object detection in autonomous driving,” arXiv preprint arXiv:2406.00714 , 2024
arXiv 2024
-
[41]
When domain generalization meets generalized category discovery: An adap- tive task-arithmetic driven approach,
V . Rathore, S. Dutta, S. Mehrotra, Z. Kira, B. Banerjee, et al., “When domain generalization meets generalized category discovery: An adap- tive task-arithmetic driven approach,” in Proceedings of the Computer Vision and Pattern Recognition Conference , pp. 4905–4915, 2025
2025
-
[42]
A novel cross-perturbation for single domain generalization,
D. Zhao, L. Qi, X. Shi, Y . Shi, and X. Geng, “A novel cross-perturbation for single domain generalization,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 11, pp. 10903–10916, 2024
2024
-
[43]
Spg: Unsu- pervised domain adaptation for 3d object detection via semantic point generation,
Q. Xu, Y . Zhou, W. Wang, C. R. Qi, and D. Anguelov, “Spg: Unsu- pervised domain adaptation for 3d object detection via semantic point generation,” in Proceedings of the IEEE/CVF international conference on computer vision , pp. 15446–15456, 2021
2021
-
[44]
Leveraging vision-language models for improving domain generalization in image classification,
S. Addepalli, A. R. Asokan, L. Sharma, and R. V . Babu, “Leveraging vision-language models for improving domain generalization in image classification,” in Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition , pp. 23922–23932, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.