The Hidden Cost of Pairwise Verification in Synthetic Speech Source Tracing
Pith reviewed 2026-06-27 08:35 UTC · model grok-4.3
The pith
Global anchoring achieves lower error than pairwise verification for synthetic speech source tracing because it shapes embedding directions differently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
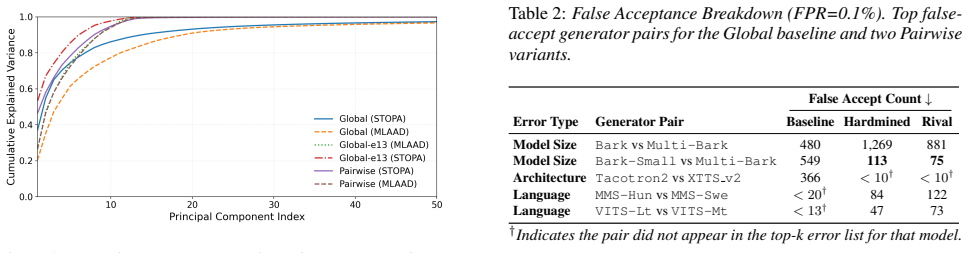
Under matched backbones and a fixed data and epoch budget on MLAAD and STOPA, global anchoring yields lower in-domain error (8.61% EER) than pairwise variants (12-15% EER). Because pairwise objectives optimize similarity directly, they concentrate variance into fewer embedding directions, reducing resolution among closely related generators. Imposing a similar bottleneck on the globally supervised baseline leaves it competitive, and embedding-space analysis with k99 shows the gap arises from how the pairwise objective shapes the retained directions rather than from dimensionality reduction alone.
What carries the argument
The pairwise verification objective versus global anchoring, together with k99 analysis of retained variance directions in the embedding space.
If this is right
- Pairwise objectives reduce the ability to distinguish closely related synthetic speech generators even when advanced backbones and mining are used.
- Global anchoring preserves more useful embedding directions under the same training constraints.
- Imposing dimensionality bottlenecks on global models does not erase their advantage over pairwise ones.
- The performance difference appears in in-domain results and is not explained by dimensionality reduction alone.
Where Pith is reading between the lines
- Tasks that require fine distinctions among similar classes may benefit from global supervision over standard pairwise metric learning.
- Similar objective comparisons could be run on other open-set attribution problems such as image or video generator tracing.
- Hybrid objectives that combine global and pairwise terms might retain the strengths of both.
- Varying the data or compute budget could test whether the observed gap shrinks under different optimization regimes.
Load-bearing premise
The fixed data and epoch budget plus matched backbones create equivalent optimization difficulty for global versus pairwise objectives.
What would settle it
Training pairwise models for many more epochs or with a larger data budget until their EER matches or beats the global baseline would show the gap was due to unequal training regimes rather than the objective itself.
Figures

read the original abstract
Open-set source tracing is increasingly framed as a verification problem, motivating the use of pairwise metric-learning objectives from biometrics. We thus compare global anchoring and pairwise verification under matched backbones and a fixed data and epoch budget on MLAAD (in-domain) and STOPA (out-of-domain). In our runs, global anchoring yields lower in-domain error (8.61% EER) than pairwise variants (12-15% EER), even with rival mining and XLS-R finetuning. Because pairwise objectives optimize similarity directly, they concentrate variance into fewer embedding directions, reducing resolution among closely related generators. To test if this drives the drop, we impose a similar bottleneck to the globally supervised baseline, yet the baseline remains competitive. Together with an embedding-space analysis ($k_{99}$), these results suggest that the gap is not explained by dimensionality alone, but rather by the pairwise objective's shaping of the retained directions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that global anchoring yields lower in-domain EER (8.61%) than pairwise verification objectives (12-15% EER) for open-set synthetic speech source tracing on MLAAD (in-domain) and STOPA (out-of-domain), even under matched backbones, fixed data/epoch budgets, rival mining, and XLS-R finetuning. It attributes the gap not to dimensionality but to pairwise objectives shaping retained embedding directions (reducing resolution among similar generators), supported by a bottleneck ablation on the global baseline and an embedding-space k99 analysis.
Significance. If robust, the result cautions against direct transfer of pairwise metric-learning objectives from biometrics to source tracing, as they may concentrate variance and limit discriminative power. Strengths include the empirical isolation of dimensionality via bottleneck test and the independent k99 measurement on learned embeddings; the work is purely empirical with no circular or self-referential derivations.
major comments (1)
- [abstract, paragraph on experimental setup] Abstract, paragraph on experimental setup: the central claim that the EER gap (and k99 results) stems from the pairwise objective's shaping of retained directions requires that the fixed data/epoch budget and matched backbones produce comparably converged models. Pairwise verification with rival mining is known to be sensitive to margin, temperature, and mining frequency; without training curves, validation monitoring, or evidence that extra epochs/retuning would not close the gap, the attribution to objective shape rather than optimization difficulty remains untested. The bottleneck ablation addresses dimensionality but not this equivalence.
minor comments (2)
- Notation: 'k99' should be rendered as k_{99} for clarity in the embedding-space analysis description.
- The abstract refers to 'in our runs' but provides no details on number of runs, random seeds, or statistical significance testing for the reported EER differences.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on convergence equivalence. We address the concern directly below and agree that additional evidence would strengthen the attribution of the EER gap to objective shape rather than optimization differences.
read point-by-point responses
-
Referee: the central claim that the EER gap (and k99 results) stems from the pairwise objective's shaping of retained directions requires that the fixed data/epoch budget and matched backbones produce comparably converged models. Pairwise verification with rival mining is known to be sensitive to margin, temperature, and mining frequency; without training curves, validation monitoring, or evidence that extra epochs/retuning would not close the gap, the attribution to objective shape rather than optimization difficulty remains untested. The bottleneck ablation addresses dimensionality but not this equivalence.
Authors: We agree that the fixed budget alone does not prove comparable convergence and that sensitivity of pairwise verification to hyperparameters could affect results. In our experiments the epoch count was selected after preliminary runs in which validation EER for both objectives stabilized, but we did not report the curves. In revision we will add training and validation loss/EER curves for all methods under the reported budget, together with the hyperparameter search details (margin, temperature, mining frequency) used for the pairwise variants. If the curves confirm that both families reach plateau performance, this will support the claim that the gap arises from retained embedding directions rather than under-optimization. The bottleneck ablation will remain as evidence that dimensionality is not the sole factor. revision: yes
Circularity Check
No circularity; purely empirical comparison with independent measurements
full rationale
The paper reports experimental EER results (8.61% vs 12-15%) and k99 embedding analysis under matched backbones and fixed budgets. No derivation, equation, or self-citation chain reduces any reported quantity to a fitted parameter or input by construction. The bottleneck ablation and out-of-domain tests are external measurements on the learned embeddings, not tautological. The central claim rests on observed performance gaps rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recently, Source Tracing has been explored to provide post- incident countermeasures by attributing the attack to the syn- thesizer used to create the deepfake
Introduction As speech synthesis approaches evolved into a substantial se- curity threat [1, 2, 3, 4], audio deepfake detection provided a sufficient countermeasure against deepfake-related incidents. Recently, Source Tracing has been explored to provide post- incident countermeasures by attributing the attack to the syn- thesizer used to create the deepf...
-
[2]
From Classification to Verification Early forensic works framed source tracing as a closed-set classification problem. Borrelli et al. [12] pioneered the use of SVMs to distinguish generator architectures, while subse- quent studies decomposed the task into component-level anal- ysis, classifying specific vocoders or acoustic models sepa- rately [13, 14]....
Pith/arXiv arXiv 2026
-
[3]
Hypothesis and Comparison Strategy We study how training objectives affect verification perfor- mance and the geometry of representation for open-set source tracing
Experimental Framework 3.1. Hypothesis and Comparison Strategy We study how training objectives affect verification perfor- mance and the geometry of representation for open-set source tracing. Motivated by the success of pairwise learning in bio- metrics [5, 6], we test whether pairwise objectives improve gen- eralization or trade off fine-grained resolu...
-
[4]
Global anchoring (Baseline).We re-implement the attribution-based verification framework established by Ne- groni et al. [11]. This approach treats open-set verification as a representation learning problem via closed-set classification. The model projects the pooled embeddinghto class logits via a linear layer and is optimized using Softmax Cross-Entropy...
-
[5]
Pairwise Verification.Pairwise systems replace the classifi- cation head with a fusion module that maps an embedding pair (ha, hb)to a scalar similarity score, estimating the probability that the two samples were generated by the same generator. We compare four trial selection regimes: •Intermediate (Random):A baseline regime sampling anchor-positive pair...
-
[6]
impostor pairs
Experiments and Results 4.1. Establishing the Pairwise Baseline Unless stated otherwise, we use the pairwise defaults tuned on MLAAD-dev (3 seeds), namelyintermediatesampling and XLS-R+MHFA+FFCosine, and keep the training budget fixed thereafter (full sweeps in the supplement). Table 1:Global vs. pairwise objectives with bottleneck and backbone controls.M...
-
[7]
VITS-Neon), both objectives exhibit high error rates
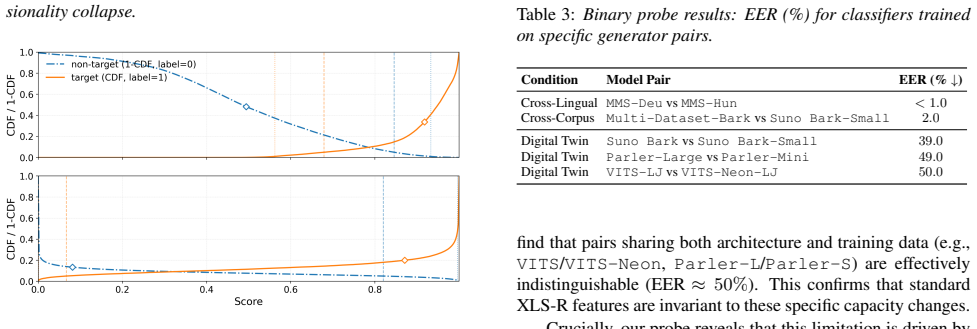
Shared Limitations (Digital Twins).For pairs shar- ing identical architectures and training data (e.g.,VITSvs. VITS-Neon), both objectives exhibit high error rates. As in- dicated by the binary probe experiments (Section 4.5), these sources appear topologically overlapping in the XLS-R feature space. The inability to distinguish them reflects a limitation...
-
[8]
Bark-Small
Loss of Resolution (Architectural Cousins).A critical divergence appears for systems that share an architecture but differ in configuration, such asMulti-Dataset-Barkvs. Bark-Small. While the Global Model retains sufficient dis- criminability to separate these variants in our setting (480 er- rors), the Pairwise Model exhibits a nearly threefold increase ...
-
[9]
Conclusion Across our experiments, global supervision remains a strong baseline for open-set synthetic speech attribution: it achieves the best in-domain verification on MLAAD, while the tested pairwise variants improve with mining and SSL finetuning but do not match it. Diagnostics of the learned representations suggest that the gap is not explained by e...
-
[10]
Acknowledgements This work was partially supported by the Brno University of Technology (internal project FIT-S-23-8151) and the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:90254)
-
[11]
The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
Generative AI Use Disclosure During the preparation of this work, the authors used Generative AI Models (specifically Google Gemini, ChatGPT, and Gram- marly) for language editing and text refinement. The authors reviewed and edited the output as needed and take full respon- sibility for the publication’s content
-
[12]
Assessing the human ability to recognize synthetic speech in ordinary conversation,
D. Prudk ´y, A. Firc, and K. Malinka, “Assessing the human ability to recognize synthetic speech in ordinary conversation,” in2023 International Conference of the Biometrics Special Interest Group (BIOSIG), 2023, pp. 1–5
2023
-
[13]
The dawn of a text-dependent society: deepfakes as a threat to speech verification systems,
A. Firc and K. Malinka, “The dawn of a text-dependent society: deepfakes as a threat to speech verification systems,” ser. SAC ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 1646–1655. [Online]. Available: https://doi.org/10.1145/3477314.3507013
-
[14]
Deepfakes as a threat to a speaker and facial recognition: an overview of tools and attack vectors,
A. Firc, K. Malinka, and P. Han ´aˇcek, “Deepfakes as a threat to a speaker and facial recognition: an overview of tools and attack vectors,”Heliyon, vol. 9, no. 4, pp. 1–33, april 2023. [Online]. Available: https://www.fit.vut.cz/research/publication/12850
2023
-
[15]
Resilience of voice assistants to synthetic speech,
K. Malinka, A. Firc, P. Kaˇska, T. Lapˇsansk´y, O. ˇSandor, and I. Ho- moliak, “Resilience of voice assistants to synthetic speech,” in Computer Security – ESORICS 2024, J. Garcia-Alfaro, R. Kozik, M. Chora ´s, and S. Katsikas, Eds. Cham: Springer Nature Switzerland, 2024, pp. 66–84
2024
-
[16]
Facenet: A unified embedding for face recognition and clustering,
F. Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), June 2015
2015
-
[17]
Deep speaker: an end-to-end neural speaker embedding system,
C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kannan, and Z. Zhu, “Deep speaker: an end-to-end neural speaker embedding system,” 2017. [Online]. Available: https://arxiv.org/abs/1705.02304
Pith/arXiv arXiv 2017
-
[18]
Synthetic Speech Source Tracing using Metric Learning,
D. Koutsianos, S. Zacharopoulos, Y . Panagakis, and T. Stafylakis, “Synthetic Speech Source Tracing using Metric Learning,” inIn- terspeech 2025, 2025, pp. 1558–1562
2025
-
[19]
TADA: Training- free Attribution and Out-of-Domain Detection of Audio Deep- fakes,
A. Stan, D. Combei, D. Oneata, and H. Cucu, “TADA: Training- free Attribution and Out-of-Domain Detection of Audio Deep- fakes,” inInterspeech 2025, 2025, pp. 1543–1547
2025
-
[20]
Mlaad: The multi-language audio anti-spoofing dataset,
N. M. M ¨uller, P. Kawa, W. H. Choong, E. Casanova, E. G ¨olge, T. M ¨uller, P. Syga, P. Sperl, and K. B ¨ottinger, “Mlaad: The multi-language audio anti-spoofing dataset,”arXiv preprint arXiv:2401.09512, 2024
Pith/arXiv arXiv 2024
-
[21]
STOPA: A Dataset of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution,
A. Firc, M. Chhibber, J. Mishra, V . Pratap Singh, T. Kinnunen, and K. Malinka, “STOPA: A Dataset of Systematic VariaTion Of DeePfake Audio for Open-Set Source Tracing and Attribution,” in Interspeech 2025, 2025, pp. 1553–1557
2025
-
[22]
Source Ver- ification for Speech Deepfakes ,
V . Negroni, D. Salvi, P. Bestagini, and S. Tubaro, “ Source Ver- ification for Speech Deepfakes ,” inInterspeech 2025, 2025, pp. 1548–1552
2025
-
[23]
Synthetic speech detection through short-term and long-term prediction traces,
C. Borrelli, P. Bestagini, F. Antonacci, A. Sarti, and S. Tubaro, “Synthetic speech detection through short-term and long-term prediction traces,”EURASIP Journal on Information Security, vol. 2021, no. 1, p. 2, Apr 2021. [Online]. Available: https://doi.org/10.1186/s13635-021-00116-3
-
[24]
Source tracing: Detect- ing voice spoofing,
T. Zhu, X. Wang, X. Qin, and M. Li, “Source tracing: Detect- ing voice spoofing,” in2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2022, pp. 216–220
2022
-
[25]
Source Trac- ing of Audio Deepfake Systems,
N. Klein, T. Chen, H. Tak, R. Casal, and E. Khoury, “Source Trac- ing of Audio Deepfake Systems,” inInterspeech 2024, 2024, pp. 1100–1104
2024
-
[26]
Generalize audio deepfake algorithm recognition via attribution enhancement,
Z. Wang, D. Ye, J. Li, and J. Deng, “Generalize audio deepfake algorithm recognition via attribution enhancement,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[27]
Source tracing of synthetic speech systems through paralinguistic pre-trained repre- sentations,
Girish, M. M. Akhtar, O. C. Phukan, D. Singh, S. R. Behera, P. B. Reddy, A. B. Buduru, and R. Sharma, “Source tracing of synthetic speech systems through paralinguistic pre-trained repre- sentations,” in2025 33rd European Signal Processing Conference (EUSIPCO), 2025, pp. 496–500
2025
-
[28]
Investigating prosodic signatures via speech pre-trained models for audio deepfake source attribution,
O. Chetia Phukan, D. Singh, S. R. Behera, A. B. Buduru, and R. Sharma, “Investigating prosodic signatures via speech pre-trained models for audio deepfake source attribution,” in Findings of the Association for Computational Linguistics: ACL 2025, W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, Eds. Vienna, Austria: Association for Computational Lingu...
2025
-
[29]
Towards neural audio codec source parsing,
O. C. Phukan, Girish, M. M. Akhtar, A. B. Buduru, and R. Sharma, “Towards neural audio codec source parsing,” 2025. [Online]. Available: https://arxiv.org/abs/2506.12627
arXiv 2025
-
[30]
Advancing zero- shot open-set speech deepfake source tracing,
M. Chhibber, J. Mishra, and T. H. Kinnunen, “Advancing zero- shot open-set speech deepfake source tracing,” 2025. [Online]. Available: https://arxiv.org/abs/2509.24674
Pith/arXiv arXiv 2025
-
[31]
Audio Deepfake Source Tracing using Multi-Attribute Open-Set Identification and Verification,
P. Falez, T. Marteau, D. Lolive, and A. Delhay, “Audio Deepfake Source Tracing using Multi-Attribute Open-Set Identification and Verification,” inInterspeech 2025, 2025, pp. 1528–1532
2025
-
[32]
Margin mat- ters: Towards more discriminative deep neural network embed- dings for speaker recognition,
X. Xiang, S. Wang, H. Huang, Y . Qian, and K. Yu, “Margin mat- ters: Towards more discriminative deep neural network embed- dings for speaker recognition,” in2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Confer- ence (APSIPA ASC), 2019, pp. 1652–1656
2019
-
[33]
Xls-r: Self-supervised cross-lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Con- neau, and M. Auli, “Xls-r: Self-supervised cross-lingual speech representation learning at scale,” inInterspeech 2022, 2022, pp. 2278–2282
2022
-
[34]
Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 6367–6371
2022
-
[35]
Ca-mhfa: A context-aware multi-head fac- torized attentive pooling for ssl-based speaker verification,
J. Peng, L. Mo ˇsner, L. Zhang, O. Plchot, T. Stafylakis, L. Bur- get, and J. ˇCernock´y, “Ca-mhfa: A context-aware multi-head fac- torized attentive pooling for ssl-based speaker verification,” in ICASSP 2025 - 2025 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[36]
What data enables optimal decisions? an exact characterization for linear optimization,
O. Bennouna, A. Bennouna, S. Amin, and A. Ozdaglar, “What data enables optimal decisions? an exact characterization for linear optimization,” 2025. [Online]. Available: https: //arxiv.org/abs/2505.21692
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.