FitVTON: Fit-aware Virtual Try-On via Body-Garment Size Control
Pith reviewed 2026-06-27 09:51 UTC · model grok-4.3
The pith
Encoding body-garment size in text prompts allows virtual try-on to match real fitting across body shapes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
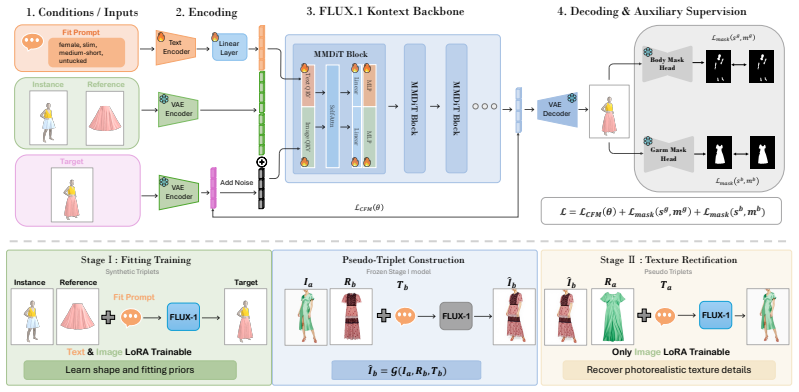
FitVTON encodes garment-body size through structured text prompts and learns from simulated try-on triplets from parameterized garment model. Auxiliary heads predict masks for garment and exposed body, and a texture rectification stage improves realistic appearance from simulated data, resulting in authentic fitting fidelity with significant sizing accuracy and shape preservation.
What carries the argument
Structured text prompts that encode body-garment size relations, trained on simulated try-on triplets with auxiliary mask heads and texture rectification.
If this is right
- Generates try-on images with higher sizing accuracy on varied body shapes than inpainting baselines.
- Preserves original garment silhouettes more faithfully while keeping competitive visual quality.
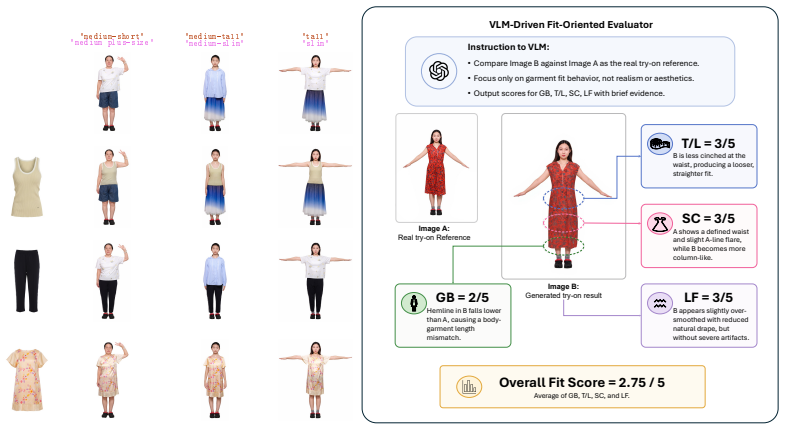
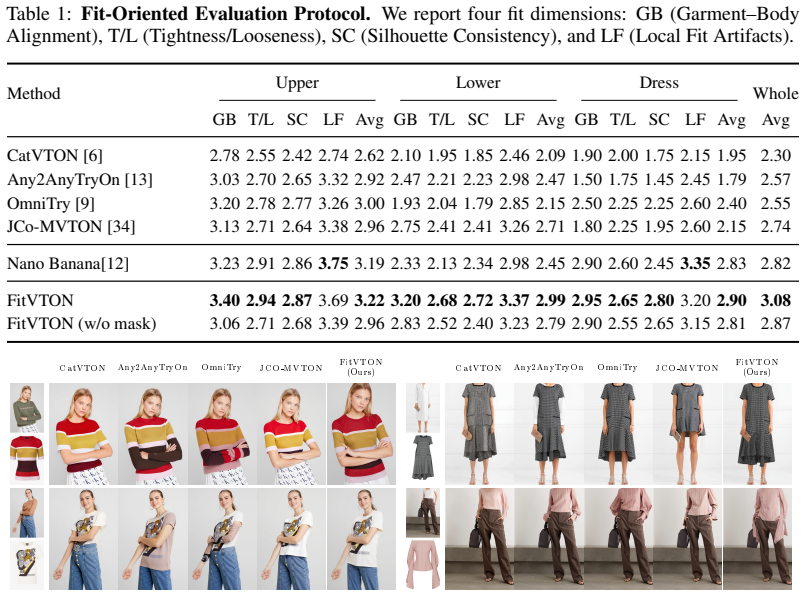
- Supports a VLM-based scoring protocol and new dataset for quantitative fit evaluation.
- Allows fit control without requiring explicit 3D garment deformation at inference time.
Where Pith is reading between the lines
- Text-based size encoding may extend to controlling other physical properties such as drape or stretch in generated clothing images.
- The simulation-to-real pipeline could reduce the need for large paired real-world try-on datasets in future systems.
- Direct integration of user-provided measurements into prompts might enable personalized fitting without additional model retraining.
Load-bearing premise
That simulated try-on triplets generated from a parameterized garment model, combined with VLM-based scoring on the new FittingEffect3K dataset, provide a reliable proxy for real-world garment fit across diverse bodies.
What would settle it
Human raters viewing side-by-side photos of the same garments actually worn by people of different sizes consistently prefer outputs from prior methods over FitVTON on fit realism.
Figures










read the original abstract
While diffusion-based virtual try-on has achieved impressive visual realism, most methods treat the task as 2D inpainting, prioritizing texture preservation over physical plausibility. Consequently, they often produce plausible-looking images that fail to reflect authentic garment fit across diverse body shapes. We present FitVTON, a Fit-aware virtual try-on model on different bodies in the wild. FitVTON encodes garment-body size through structured text prompts, and learn from simulated try-on triplets from parameterized garment model. To improve the fitting effects over garment silhouettes, we introduce two auxiliary head to predict the masks for both the garment and the exposed body. We further introduce a texture rectification stage to improve realistic appearance from simulated data. To evaluate the fitting fidelity, we curate a real-world dataset, FittingEffect3K, combining VLM-based scoring protocol. Both subjective and quantitive experiments show that FitVTON demonstrate authentic fitting fidelity, with significant sizing accuracy and shape preservation over state-of-the-art methods while maintaining competitive image quality. Project Page: https://zenoning.github.io/FitVTON/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FitVTON, a diffusion-based virtual try-on model that encodes body-garment size relationships via structured text prompts, trains on simulated try-on triplets generated from a parameterized garment model, adds two auxiliary heads to predict garment and exposed-body masks, and applies a texture rectification stage. It curates the real-world FittingEffect3K dataset and introduces a VLM-based scoring protocol; both subjective and quantitative experiments are claimed to show superior fitting fidelity, sizing accuracy, and shape preservation relative to prior SOTA methods while preserving competitive image quality.
Significance. If the simulation-to-real gap and VLM scoring protocol can be shown to align with physical garment fit, the size-control mechanism and auxiliary mask heads would address a recognized limitation of 2D inpainting try-on methods. The work would then be relevant to e-commerce applications requiring plausible fit across body shapes. However, the significance is currently limited by the absence of any reported validation that the simulated triplets reproduce drape, tension, or occlusion behavior and that VLM scores correlate with actual wear measurements.
major comments (2)
- [Evaluation] Evaluation section: the claim of 'significant sizing accuracy and authentic fitting fidelity' rests on VLM-based scoring of the newly curated FittingEffect3K dataset, yet no comparison is reported between VLM scores and either expert human fit ratings or direct physical measurements (e.g., garment circumference vs. body circumference at key landmarks). Without such calibration, the quantitative gains cannot be taken as evidence that the method improves physical plausibility.
- [Method] Method section (simulation pipeline): the training data are generated from a parameterized garment model, but the manuscript provides neither equations describing the garment parameterization nor any quantitative comparison (e.g., drape error, tension maps) between the simulated triplets and real photographs of the same garments on the same bodies. This gap directly undermines the central assertion that the learned model captures authentic fit.
minor comments (2)
- [Abstract] Abstract: 'quantitive' is a typo for 'quantitative'; 'demonstrate' should agree with the singular subject 'FitVTON'.
- [Abstract] The abstract states that both subjective and quantitative experiments were performed, but the manuscript does not list the exact metrics, baselines, or number of participants for the subjective study.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate. Our responses focus on clarifying existing elements of the work and acknowledging genuine limitations without overstating the current evidence.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the claim of 'significant sizing accuracy and authentic fitting fidelity' rests on VLM-based scoring of the newly curated FittingEffect3K dataset, yet no comparison is reported between VLM scores and either expert human fit ratings or direct physical measurements (e.g., garment circumference vs. body circumference at key landmarks). Without such calibration, the quantitative gains cannot be taken as evidence that the method improves physical plausibility.
Authors: We acknowledge that the manuscript does not include a direct calibration study correlating VLM scores with expert human fit ratings or physical measurements such as circumference comparisons. The quantitative results rely on the VLM protocol, which is supplemented by subjective human evaluations reported in the experiments. We agree this calibration would provide stronger support for physical plausibility claims. In the revision we will expand the evaluation section to include more explicit alignment between VLM scores and the subjective study outcomes, and we will add a dedicated limitations paragraph noting the absence of physical measurement validation. revision: partial
-
Referee: [Method] Method section (simulation pipeline): the training data are generated from a parameterized garment model, but the manuscript provides neither equations describing the garment parameterization nor any quantitative comparison (e.g., drape error, tension maps) between the simulated triplets and real photographs of the same garments on the same bodies. This gap directly undermines the central assertion that the learned model captures authentic fit.
Authors: We agree that the current manuscript lacks explicit equations for the garment parameterization and does not report quantitative metrics such as drape error or tension maps comparing simulations to real photographs. The parameterization is based on standard techniques but was not detailed in the main text. We will add the relevant equations and a more complete description of the simulation process to the revised method section. For the quantitative validation gap, we relied on visual fidelity and downstream performance on real data rather than direct simulation-to-real error metrics; we will note this choice and its implications in the revision. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes a diffusion-based virtual try-on architecture that encodes size via text prompts, trains on triplets from an external parameterized garment simulator, adds auxiliary mask heads, and applies a texture rectification stage. Evaluation uses a separately curated real-world dataset (FittingEffect3K) with VLM scoring. None of the load-bearing steps reduce by definition or self-citation to the target outputs; the simulation source and dataset curation are presented as independent inputs rather than tautological re-labelings of the model's predictions. No self-definitional equations, fitted-input-as-prediction patterns, or uniqueness theorems imported from the authors' prior work appear in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chatgarment: Garment estimation, generation and editing via large language models
Siyuan Bian, Chenghao Xu, Yuliang Xiu, Artur Grigorev, Zhen Liu, Cewu Lu, Michael J Black, and Yao Feng. Chatgarment: Garment estimation, generation and editing via large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2924–2934, 2025
2025
-
[2]
Mikołaj Bi ´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. Ac- cessed: 2025-01
2024
-
[4]
Viton-hd: High-resolution virtual try-on via misalignment-aware normalization
Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 14131–14140, 2021
2021
-
[5]
Improving diffusion models for authentic virtual try-on in the wild
Yisol Choi, Sangkyung Kwak, Kyungmin Lee, Hyungwon Choi, and Jinwoo Shin. Improving diffusion models for authentic virtual try-on in the wild. InEuropean Conference on Computer Vision, pages 206–235. Springer, 2024
2024
-
[6]
Zheng Chong, Xiao Dong, Haoxiang Li, Shiyue Zhang, Wenqing Zhang, Xujie Zhang, Han- qing Zhao, Dongmei Jiang, and Xiaodan Liang. Catvton: Concatenation is all you need for virtual try-on with diffusion models.arXiv preprint arXiv:2407.15886, 2024
-
[7]
Accurate 3d body shape regression using metric and semantic attributes
Vasileios Choutas, Lea Müller, Chun-Hao P Huang, Siyu Tang, Dimitrios Tzionas, and Michael J Black. Accurate 3d body shape regression using metric and semantic attributes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2718–2728, 2022
2022
-
[8]
Clo3d.https://clo3d.com/en/, 2022
CLO3D. Clo3d.https://clo3d.com/en/, 2022
2022
-
[9]
Omnitry: Virtual try-on anything without masks.arXiv preprint arXiv:2508.13632, 2025
Yutong Feng, Linlin Zhang, Hengyuan Cao, Yiming Chen, Xiaoduan Feng, Jian Cao, Yux- iong Wu, and Bin Wang. Omnitry: Virtual try-on anything without masks.arXiv preprint arXiv:2508.13632, 2025
-
[10]
Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images
Yuying Ge, Ruimao Zhang, Xiaogang Wang, Xiaoou Tang, and Ping Luo. Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5337–5345, 2019
2019
-
[11]
Parser-free virtual try-on via distilling appearance flows
Yuying Ge, Yibing Song, Ruimao Zhang, Chongjian Ge, Wei Liu, and Ping Luo. Parser-free virtual try-on via distilling appearance flows. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8485–8493, 2021
2021
-
[12]
Nano banana pro (gemini 3).https://blog.google, 2025
Google. Nano banana pro (gemini 3).https://blog.google, 2025. Large Language and Image Model
2025
-
[13]
Any2anytryon: Leveraging adaptive position embeddings for versatile virtual clothing tasks
Hailong Guo, Bohan Zeng, Yiren Song, Wentao Zhang, Jiaming Liu, and Chuang Zhang. Any2anytryon: Leveraging adaptive position embeddings for versatile virtual clothing tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19085– 19096, 2025
2025
-
[14]
Viton: An image-based virtual try-on network
Xintong Han, Zuxuan Wu, Zhe Wu, Ruichi Yu, and Larry S Davis. Viton: An image-based virtual try-on network. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7543–7552, 2018
2018
-
[15]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[16]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Boyuan Jiang, Xiaobin Hu, Donghao Luo, Qingdong He, Chengming Xu, Jinlong Peng, Jiangn- ing Zhang, Chengjie Wang, Yunsheng Wu, and Yanwei Fu. Fitdit: Advancing the authentic garment details for high-fidelity virtual try-on.arXiv preprint arXiv:2411.10499, 2024
-
[18]
Stableviton: Learn- ing semantic correspondence with latent diffusion model for virtual try-on
Jeongho Kim, Guojung Gu, Minho Park, Sunghyun Park, and Jaegul Choo. Stableviton: Learn- ing semantic correspondence with latent diffusion model for virtual try-on. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8176–8185, 2024
2024
-
[19]
Promptdresser: Improving the quality and controllability of virtual try-on via generative textual prompt and prompt-aware mask
Jeongho Kim, Hoiyeong Jin, Sunghyun Park, and Jaegul Choo. Promptdresser: Improving the quality and controllability of virtual try-on via generative textual prompt and prompt-aware mask. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16026–16036, 2025
2025
-
[20]
Garmentcode: Programming parametric sewing patterns.ACM Transactions on Graphics (TOG), 42(6):1–15, 2023
Maria Korosteleva and Olga Sorkine-Hornung. Garmentcode: Programming parametric sewing patterns.ACM Transactions on Graphics (TOG), 42(6):1–15, 2023
2023
-
[21]
Garmentcodedata: A dataset of 3d made-to-measure garments with sewing patterns
Maria Korosteleva, Timur Levent Kesdogan, Fabian Kemper, Stephan Wenninger, Jasmin Koller, Yuhan Zhang, Mario Botsch, and Olga Sorkine-Hornung. Garmentcodedata: A dataset of 3d made-to-measure garments with sewing patterns. InEuropean Conference on Computer Vision, pages 110–127. Springer, 2024
2024
-
[22]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Tryongan: Body-aware try-on via layered interpolation.ACM Transactions on Graphics (TOG), 40(4): 1–10, 2021
Kathleen M Lewis, Srivatsan Varadharajan, and Ira Kemelmacher-Shlizerman. Tryongan: Body-aware try-on via layered interpolation.ACM Transactions on Graphics (TOG), 40(4): 1–10, 2021
2021
-
[24]
Xiu Li, Michael Kampffmeyer, Xin Dong, Zhenyu Xie, Feida Zhu, Haoye Dong, Xiaodan Liang, et al. Warpdiffusion: Efficient diffusion model for high-fidelity virtual try-on.arXiv preprint arXiv:2312.03667, 2023
-
[25]
Anyfit: Controllable virtual try-on for any combination of attire across any scenario.Advances in Neural Information Processing Systems, 37:83164–83196, 2024
Yuhan Li, Hao Zhou, Wenxiang Shang, Ran Lin, Xuanhong Chen, and Bingbing Ni. Anyfit: Controllable virtual try-on for any combination of attire across any scenario.Advances in Neural Information Processing Systems, 37:83164–83196, 2024
2024
-
[26]
Smpl: A skinned multi-person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. InSeminal Graphics Papers: Pushing the Bound- aries, Volume 2, pages 851–866. 2023
2023
-
[27]
Warp: A high-performance python framework for gpu simulation and graphics
Miles Macklin. Warp: A high-performance python framework for gpu simulation and graphics. https://github.com/nvidia/warp, 2022. NVIDIA GPU Technology Conference (GTC)
2022
-
[28]
Dress code: High-resolution multi-category virtual try-on
Davide Morelli, Matteo Fincato, Marcella Cornia, Federico Landi, Fabio Cesari, and Rita Cucchiara. Dress code: High-resolution multi-category virtual try-on. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2231–2235, 2022
2022
-
[29]
Ladi-vton: Latent diffusion textual-inversion enhanced virtual try-on
Davide Morelli, Alberto Baldrati, Giuseppe Cartella, Marcella Cornia, Marco Bertini, and Rita Cucchiara. Ladi-vton: Latent diffusion textual-inversion enhanced virtual try-on. In Proceedings of the 31st ACM international conference on multimedia, pages 8580–8589, 2023
2023
-
[30]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019
2019
-
[31]
Style3d.https://www.style3d.com, 2022
Style3D. Style3d.https://www.style3d.com, 2022. 11
2022
-
[32]
Gen- eralised dice overlap as a deep learning loss function for highly unbalanced segmentations
Carole H Sudre, Wenqi Li, Tom Vercauteren, Sebastien Ourselin, and M Jorge Cardoso. Gen- eralised dice overlap as a deep learning loss function for highly unbalanced segmentations. InDeep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pages 240–248. Springer, 2017
2017
-
[33]
Siqi Wan, Jingwen Chen, Yingwei Pan, Ting Yao, and Tao Mei. Incorporating visual corre- spondence into diffusion model for virtual try-on.arXiv preprint arXiv:2505.16977, 2025
-
[34]
Jco-mvton: Jointly controllable multi-modal diffusion transformer for mask-free virtual try-on
Aowen Wang, Wei Li, Hao Luo, Mengxing Ao, Chenyu Zhu, Xinyang Li, and Fan Wang. Jco-mvton: Jointly controllable multi-modal diffusion transformer for mask-free virtual try-on. arXiv preprint arXiv:2508.17614, 2025
-
[35]
To- ward characteristic-preserving image-based virtual try-on network
Bochao Wang, Huabin Zheng, Xiaodan Liang, Yimin Chen, Liang Lin, and Meng Yang. To- ward characteristic-preserving image-based virtual try-on network. InProceedings of the Eu- ropean conference on computer vision (ECCV), pages 589–604, 2018
2018
-
[36]
Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning
Zhenyu Xie, Zaiyu Huang, Xin Dong, Fuwei Zhao, Haoye Dong, Xijin Zhang, Feida Zhu, and Xiaodan Liang. Gp-vton: Towards general purpose virtual try-on via collaborative local-flow global-parsing learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23550–23559, 2023
2023
-
[37]
Ootdiffusion: Outfitting fusion based latent diffusion for controllable virtual try-on
Yuhao Xu, Tao Gu, Weifeng Chen, and Arlene Chen. Ootdiffusion: Outfitting fusion based latent diffusion for controllable virtual try-on. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8996–9004, 2025
2025
-
[38]
Towards photo-realistic virtual try-on by adaptively generating-preserving image content
Han Yang, Ruimao Zhang, Xiaobao Guo, Wei Liu, Wangmeng Zuo, and Ping Luo. Towards photo-realistic virtual try-on by adaptively generating-preserving image content. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7850– 7859, 2020
2020
-
[39]
Texture- preserving diffusion models for high-fidelity virtual try-on
Xu Yang, Changxing Ding, Zhibin Hong, Junhao Huang, Jin Tao, and Xiangmin Xu. Texture- preserving diffusion models for high-fidelity virtual try-on. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7017–7026, 2024
2024
-
[40]
D 4-vton: Dynamic semantics disentangling for differential diffusion based virtual try-on
Zhaotong Yang, Zicheng Jiang, Xinzhe Li, Huiyu Zhou, Junyu Dong, Huaidong Zhang, and Yong Du. D 4-vton: Dynamic semantics disentangling for differential diffusion based virtual try-on. InEuropean Conference on Computer Vision, pages 36–52. Springer, 2024
2024
-
[41]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[42]
Boow-vton: Boosting in-the-wild virtual try-on via mask-free pseudo data training
Xuanpu Zhang, Dan Song, Pengxin Zhan, Tianyu Chang, Jianhao Zeng, Qingguo Chen, Wei- hua Luo, and An-An Liu. Boow-vton: Boosting in-the-wild virtual try-on via mask-free pseudo data training. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26399–26408, 2025
2025
-
[43]
Mmtryon: Multi-modal multi-reference control for high-quality fashion generation
Xujie Zhang, Ente Lin, Xiu Li, Yuxuan Luo, Michael Kampffmeyer, Xin Dong, and Xiaodan Liang. Mmtryon: Multi-modal multi-reference control for high-quality fashion generation. arXiv preprint arXiv:2405.00448, 2024
-
[44]
Design2garmentcode: Turning design concepts to tangible garments through program synthesis
Feng Zhou, Ruiyang Liu, Chen Liu, Gaofeng He, Yong-Lu Li, Xiaogang Jin, and Huamin Wang. Design2garmentcode: Turning design concepts to tangible garments through program synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23712–23722, 2025
2025
-
[45]
Tryondiffusion: A tale of two unets
Luyang Zhu, Dawei Yang, Tyler Zhu, Fitsum Reda, William Chan, Chitwan Saharia, Moham- mad Norouzi, and Ira Kemelmacher-Shlizerman. Tryondiffusion: A tale of two unets. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4606–4615, 2023. 12 Appendix In this appendix, we provide supplementary materials for FitVTON. A....
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.