SHERPA: Seam-aware Harmonized ERP Adaptation for Open-Domain 360^circ Panorama Generation
Pith reviewed 2026-06-27 09:43 UTC · model grok-4.3
The pith
SHERPA adapts text-to-image models to generate seamless 360-degree panoramas for both realistic and stylized prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
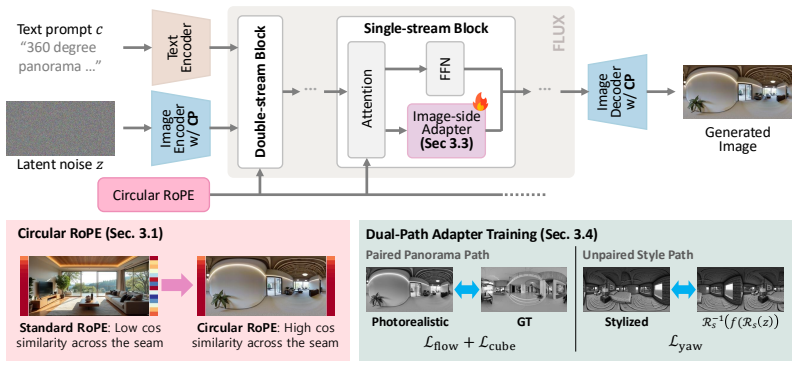
SHERPA generates 360° panoramas across both photorealistic panorama domains and open-domain stylized prompts through frequency-selective Circular RoPE, Circular Latent Encoding/Decoding, image-side FFN adapters, and a Dual-Path Training Scheme.
What carries the argument
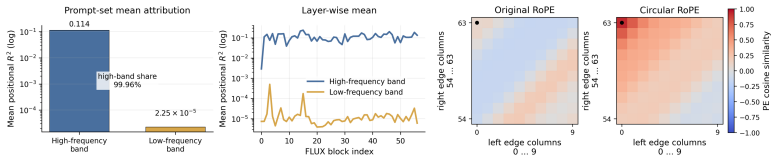
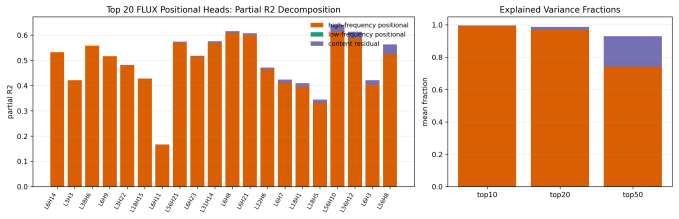
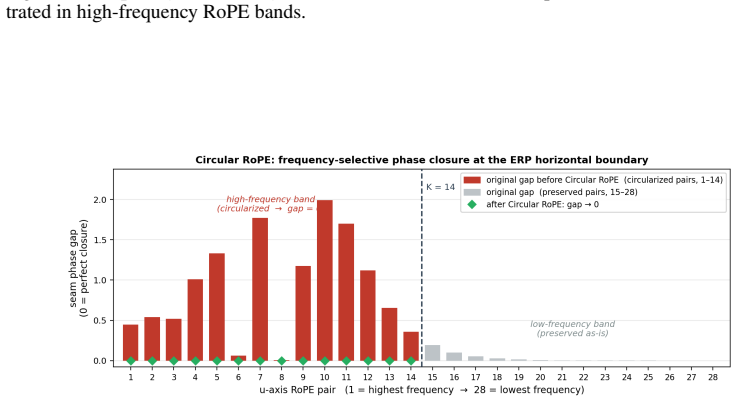
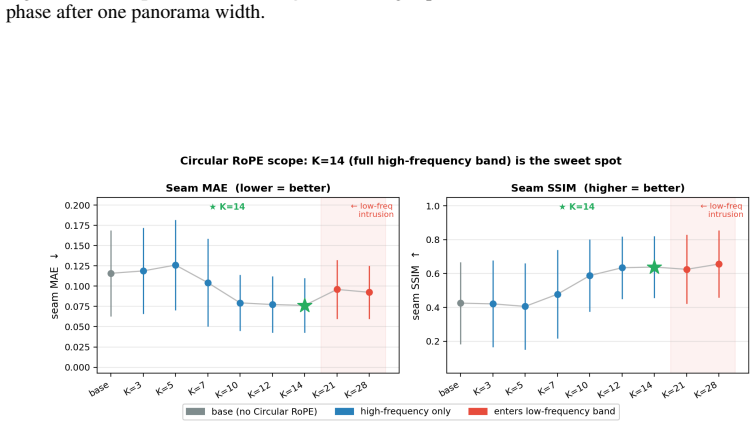
Circular RoPE replaces only the seam-sensitive high-frequency horizontal RoPE band with integer-periodic harmonics while preserving the pretrained lower-frequency spectrum.
If this is right
- Panoramas maintain geometry consistency under yaw rotations without paired target images for stylized cases.
- The method works on both photorealistic and non-photorealistic open-domain prompts.
- Only high-frequency components are altered, leaving most pretrained weights and lower-frequency behavior intact.
- Generation covers full 360° ERP output suitable for games, simulation, and world-building.
Where Pith is reading between the lines
- The same frequency-band split could be tested on other positional encodings in diffusion or flow models for spherical data.
- Integration with existing panorama viewers might allow direct text-driven environment creation for VR or 3D tools.
- Extending the dual-path idea to video or 3D-consistent generation could address temporal wrap-around consistency.
Load-bearing premise
Replacing only the seam-sensitive high-frequency horizontal RoPE band with integer-periodic harmonics while preserving the pretrained lower-frequency spectrum maintains model performance and avoids new artifacts in polar regions.
What would settle it
Visual inspection or quantitative seam/polar artifact metrics on generated panoramas from stylized prompts would show failure if horizontal wraps or poles exhibit distortions.
Figures

















read the original abstract
Panoramic imagery is increasingly used in world-generation, games, and simulation, where users may need not only photorealistic scenes but also stylized and non-photorealistic environments. Large-scale text-to-image diffusion and flow models provide broad style and semantic priors for this goal, but planar image training misaligns them with the wrap-around topology and polar regions of $360^\circ$ panoramas represented in equirectangular projection (ERP). We present SHERPA, a lightweight adaptation framework that combines frequency-selective Circular RoPE, Circular Latent Encoding/Decoding, image-side FFN adapters, and a Dual-Path Training Scheme. Circular RoPE replaces only the seam-sensitive high-frequency horizontal RoPE band with integer-periodic harmonics while preserving the pretrained lower-frequency spectrum. The Paired Panorama Path supervises geometry, while the Unpaired Style Path uses self-supervised yaw consistency for target-free stylized prompts. As a result, SHERPA generates $360^\circ$ panoramas across both photorealistic panorama domains and open-domain stylized prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SHERPA, a lightweight adaptation framework for text-to-image diffusion and flow models to generate 360° panoramas in equirectangular projection (ERP). It introduces frequency-selective Circular RoPE (replacing only the seam-sensitive high-frequency horizontal band with integer-periodic harmonics while preserving lower-frequency spectrum), Circular Latent Encoding/Decoding, image-side FFN adapters, and a Dual-Path Training Scheme (Paired Panorama Path for geometry supervision and Unpaired Style Path for self-supervised yaw consistency) to enable generation across photorealistic panorama domains and open-domain stylized prompts.
Significance. If the central claims hold, the work would be significant for enabling open-domain 360° panorama synthesis by adapting pretrained planar models to ERP topology without full retraining. The dual-path training for target-free stylized adaptation and the selective RoPE modification represent targeted contributions that could reduce artifacts at seams and poles while retaining model priors.
major comments (2)
- [§3.2] §3.2 (Circular RoPE description): The assumption that selectively replacing only the seam-sensitive high-frequency horizontal RoPE band with integer-periodic harmonics while preserving the pretrained lower-frequency spectrum maintains performance and avoids new artifacts in polar regions lacks a derivation or analysis. In ERP, polar latitudes undergo extreme vertical compression, allowing horizontal rotary embeddings at any frequency to couple into latitude-dependent distortions via the projection; no frequency-cutoff justification or phase-discontinuity analysis at the poles is supplied to isolate seam effects.
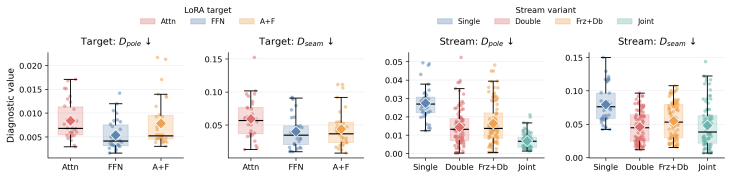
- [§4] §4 (Experiments): No quantitative results, error analysis, ablation studies on the RoPE frequency cutoff, or baseline comparisons are reported to validate that the method achieves the claimed performance across photorealistic and stylized domains, leaving the central claim that SHERPA works for both domains uncheckable from the provided details.
minor comments (2)
- The abstract would be strengthened by including one or two key quantitative metrics or baseline comparisons to ground the performance claims.
- [§3.2] Notation for the frequency band cutoff in Circular RoPE should be defined explicitly with an equation reference rather than described only in prose.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Circular RoPE description): The assumption that selectively replacing only the seam-sensitive high-frequency horizontal RoPE band with integer-periodic harmonics while preserving the pretrained lower-frequency spectrum maintains performance and avoids new artifacts in polar regions lacks a derivation or analysis. In ERP, polar latitudes undergo extreme vertical compression, allowing horizontal rotary embeddings at any frequency to couple into latitude-dependent distortions via the projection; no frequency-cutoff justification or phase-discontinuity analysis at the poles is supplied to isolate seam effects.
Authors: We agree that the current description would benefit from explicit justification. The frequency cutoff was chosen empirically to target the horizontal seam discontinuity while retaining pretrained low-frequency priors that encode global structure. In the revision we will add a dedicated analysis subsection deriving the band selection from the ERP seam geometry, including a phase-continuity argument at the poles that accounts for vertical compression and shows that low-frequency components remain largely unaffected by the periodic replacement. revision: yes
-
Referee: [§4] §4 (Experiments): No quantitative results, error analysis, ablation studies on the RoPE frequency cutoff, or baseline comparisons are reported to validate that the method achieves the claimed performance across photorealistic and stylized domains, leaving the central claim that SHERPA works for both domains uncheckable from the provided details.
Authors: The current manuscript emphasizes the architectural and training innovations with qualitative results. We acknowledge that quantitative validation is necessary to substantiate performance across domains. In the revised version we will include FID and seam-consistency metrics on both photorealistic and stylized test sets, an ablation table varying the RoPE frequency cutoff, and comparisons against relevant baselines (full fine-tuning, standard RoPE, and other ERP adaptations). revision: yes
Circularity Check
No circularity: method is an engineering adaptation without self-referential derivation
full rationale
The paper presents SHERPA as a composite adaptation framework (frequency-selective Circular RoPE, latent encoding, adapters, dual-path training) whose central design choices are stated as explicit engineering decisions rather than derived predictions. No equations or claims reduce a 'first-principles result' or 'prediction' to fitted inputs by construction, and the provided text contains no self-citations invoked as load-bearing uniqueness theorems. The description of Circular RoPE is an ansatz for seam handling, not a tautological redefinition of its own inputs. The derivation chain is therefore self-contained as a proposed method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 33:6840–6851, 2020
2020
-
[2]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[3]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. In International Conference on Learning Representations (ICLR), 2023
2023
-
[4]
FLUX.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. FLUX.https://github.com/black-forest-labs/flux, 2024
2024
-
[5]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[7]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023
2023
-
[8]
MultiDiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. MultiDiffusion: Fusing diffusion paths for controlled image generation. InInternational Conference on Machine Learning (ICML), pages 1737–1752, 2023
2023
-
[9]
SyncDiffusion: Coherent montage via synchronized joint diffusions.Advances in Neural Information Processing Systems (NeurIPS), 36:50648– 50660, 2023
Yuseung Lee, Kunho Kim, Hyunjin Kim, and Minhyuk Sung. SyncDiffusion: Coherent montage via synchronized joint diffusions.Advances in Neural Information Processing Systems (NeurIPS), 36:50648– 50660, 2023
2023
-
[10]
A survey on text-driven 360-degree panorama generation.IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT), 2025
Hai Wang, Xiaoyu Xiang, Weihao Xia, and Jing-Hao Xue. A survey on text-driven 360-degree panorama generation.IEEE Transactions on Circuits and Systems for Video Technology (IEEE TCSVT), 2025
2025
-
[11]
One flight over the gap: A survey from perspective to panoramic vision.arXiv, 2025
Xin Lin, Xian Ge, Dizhe Zhang, Zhaoliang Wan, Xianshun Wang, Xiangtai Li, Wenjie Jiang, Bo Du, Dacheng Tao, Ming-Hsuan Yang, and Lu Qi. One flight over the gap: A survey from perspective to panoramic vision.arXiv, 2025
2025
-
[12]
CubeDiff: Repurposing diffusion-based image models for panorama generation
Nikolai Kalischek, Michael Oechsle, Fabian Manhardt, Philipp Henzler, Konrad Schindler, and Federico Tombari. CubeDiff: Repurposing diffusion-based image models for panorama generation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[13]
Hakan Çapuk, Andrew Bond, Muhammed Burak Kızıl, Emir Göçen, Erkut Erdem, and Aykut Erdem. TanDiT: Tangent-plane diffusion transformer for high-quality 360 panorama generation.arXiv preprint arXiv:2506.21681, 2025
arXiv 2025
-
[14]
Panorama generation from NFoV image done right
Dian Zheng, Cheng Zhang, Xiao-Ming Wu, Cao Li, Chengfei Lv, Jian-Fang Hu, and Wei-Shi Zheng. Panorama generation from NFoV image done right. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[15]
DreamCube: RGB-D panorama generation via multi-plane synchronization
Yukun Huang, Yanning Zhou, Jianan Wang, Kaiyi Huang, and Xihui Liu. DreamCube: RGB-D panorama generation via multi-plane synchronization. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 24922–24932, 2025
2025
-
[16]
360-degree panorama generation from few unregistered NFoV images
Jionghao Wang, Ziyu Chen, Jun Ling, Rong Xie, and Li Song. 360-degree panorama generation from few unregistered NFoV images. InProceedings of the ACM International Conference on Multimedia (ACM MM), pages 6811–6821, 2023
2023
-
[17]
Mengyang Feng, Jinlin Liu, Miaomiao Cui, and Xuansong Xie. Diffusion360: Seamless 360 degree panoramic image generation based on diffusion models.arXiv preprint arXiv:2311.13141, 2023
arXiv 2023
-
[18]
PanoDiffusion: 360-degree panorama outpainting via diffusion
Tianhao Wu, Chuanxia Zheng, and Tat-Jen Cham. PanoDiffusion: 360-degree panorama outpainting via diffusion. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[19]
Text2Light: Zero-shot text-driven HDR panorama generation.ACM Transactions on Graphics (ACM TOG), 41(6):1–16, 2022
Zhaoxi Chen, Guangcong Wang, and Ziwei Liu. Text2Light: Zero-shot text-driven HDR panorama generation.ACM Transactions on Graphics (ACM TOG), 41(6):1–16, 2022. 10
2022
-
[20]
Spherical manifold guided diffusion model for panoramic image generation
Xiancheng Sun, Mai Xu, Shengxi Li, Senmao Ma, Xin Deng, Lai Jiang, and Gang Shen. Spherical manifold guided diffusion model for panoramic image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5824–5834, 2025
2025
-
[21]
SphereDiffusion: Spherical geometry-aware distortion resilient diffusion model
Tao Wu, Xuewei Li, Zhongang Qi, Di Hu, Xintao Wang, Ying Shan, and Xi Li. SphereDiffusion: Spherical geometry-aware distortion resilient diffusion model. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024
2024
-
[22]
Haoran Feng, Dizhe Zhang, Xiangtai Li, Bo Du, and Lu Qi. DiT360: High-fidelity panoramic image generation via hybrid training.arXiv preprint arXiv:2510.11712, 2025
arXiv 2025
-
[23]
HunyuanWorld Team, Zhenwei Wang, Yuhao Liu, Junta Wu, Zixiao Gu, Haoyuan Wang, Xuhui Zuo, Tianyu Huang, Wenhuan Li, Sheng Zhang, et al. HunyuanWorld 1.0: Generating immersive, explorable, and interactive 3D worlds from words or pixels.arXiv preprint arXiv:2507.21809, 2025
arXiv 2025
-
[24]
Jinhong Ni, Chang-Bin Zhang, Qiang Zhang, and Jing Zhang. What makes for text to 360-degree panorama generation with Stable Diffusion? InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16555–16564, 2025
2025
-
[25]
Taming Stable Diffusion for text to 360◦ panorama image generation
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, and Jianfei Cai. Taming Stable Diffusion for text to 360◦ panorama image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[26]
PanoWan: Lifting diffusion video generation models to 360◦ with latitude/longitude-aware mechanisms
Yifei Xia, Shuchen Weng, Siqi Yang, Jingqi Liu, Chengxuan Zhu, Minggui Teng, Zijian Jia, Han Jiang, and Boxin Shi. PanoWan: Lifting diffusion video generation models to 360◦ with latitude/longitude-aware mechanisms. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[27]
Conditional panoramic image generation via masked autoregressive modeling
Chaoyang Wang, Xiangtai Li, Lu Qi, Xiaofan Lin, Jinbin Bai, Qianyu Zhou, and Yunhai Tong. Conditional panoramic image generation via masked autoregressive modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025
2025
-
[28]
Zixun Fang, Kai Zhu, Zhiheng Liu, Yu Liu, Wei Zhai, Yang Cao, and Zheng-Jun Zha. ViewPoint: Panoramic video generation with pretrained diffusion models.arXiv preprint arXiv:2506.23513, 2025
arXiv 2025
-
[29]
Weicai Ye, Chenhao Ji, Zheng Chen, Junyao Gao, Xiaoshui Huang, Song-Hai Zhang, Wanli Ouyang, Tong He, Cairong Zhao, and Guofeng Zhang. DiffPano: Scalable and consistent text to panorama generation with spherical epipolar-aware diffusion.Advances in Neural Information Processing Systems (NeurIPS), 37:1304–1332, 2024
2024
-
[30]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[31]
Rethinking and improving relative position encoding for vision transformer
Kan Wu, Houwen Peng, Minghao Chen, Jianlong Fu, and Hongyang Chao. Rethinking and improving relative position encoding for vision transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10033–10041, 2021
2021
-
[32]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[33]
Minho Park, Taewoong Kang, Jooyeol Yun, Sungwon Hwang, and Jaegul Choo. SphereDiff: Tuning-free omnidirectional panoramic image and video generation via spherical latent representation.arXiv preprint arXiv:2504.14396, 2025
arXiv 2025
-
[34]
Geometry fidelity for spherical images
Anders Christensen, Nooshin Mojab, Khushman Patel, Karan Ahuja, Zeynep Akata, Ole Winther, Mar Gonzalez-Franco, and Andrea Colaco. Geometry fidelity for spherical images. InEuropean Conference on Computer Vision (ECCV), pages 276–292, 2024
2024
-
[35]
Ziyi Wu, Daniel Watson, Andrea Tagliasacchi, David J. Fleet, Marcus A. Brubaker, and Saurabh Saxena. 360Anything: Geometry-Free Lifting of Images and Videos to 360◦.arXiv preprint arXiv:2601.16192, 2026
Pith/arXiv arXiv 2026
-
[36]
Federico Barbero, Alex Vitvitskyi, Christos Perivolaropoulos, Razvan Pascanu, and Petar Veliˇckovi´c. Round and Round We Go! What makes Rotary Positional Encodings useful?arXiv preprint arXiv:2410.06205, 2024. 11
arXiv 2024
-
[37]
GANs trained by a two time-scale update rule converge to a local Nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[38]
Improved techniques for training GANs
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training GANs. InAdvances in Neural Information Processing Systems (NeurIPS), 2016
2016
-
[39]
Enhancing plausibility evaluation for generated designs with denoising autoencoder
Jiajie Fan, Amal Trigui, Thomas Bäck, and Hao Wang. Enhancing plausibility evaluation for generated designs with denoising autoencoder. InEuropean Conference on Computer Vision (ECCV), pages 88–105, 2024
2024
-
[40]
Matterport3D: Learning from RGB-D data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3D: Learning from RGB-D data in indoor environments. InInternational Conference on 3D Vision (3DV), 2017
2017
-
[41]
Ehinger, Aude Oliva, and Antonio Torralba
Jianxiong Xiao, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Recognizing scene viewpoint using panoramic place representation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012
2012
-
[42]
Learning to predict indoor illumination from a single image.ACM Transactions on Graphics (SIGGRAPH Asia), 36(6), 2017
Marc-Andre Gardner, Kalyan Sunkavalli, Ersin Yumer, Xiaohui Shen, Emiliano Gambaretto, Christian Gagné, and Jean-François Lalonde. Learning to predict indoor illumination from a single image.ACM Transactions on Graphics (SIGGRAPH Asia), 36(6), 2017
2017
-
[43]
Poly Haven asset license.https://polyhaven.com/license, accessed 2026
Poly Haven. Poly Haven asset license.https://polyhaven.com/license, accessed 2026
2026
-
[44]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), 2021. 12 Appendix A Additional Analysis of Ci...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.