Breaking Entropy Bounds: Accelerating RL Training via MTP with Rejection Sampling
Pith reviewed 2026-06-27 10:22 UTC · model grok-4.3
The pith
Probabilistic rejection sampling and an end-to-end TV loss keep MTP acceptance rates high during RL despite rising entropy, delivering up to 1.8x training acceleration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
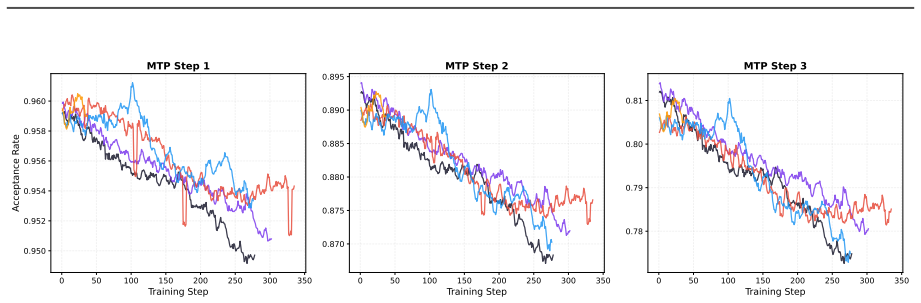
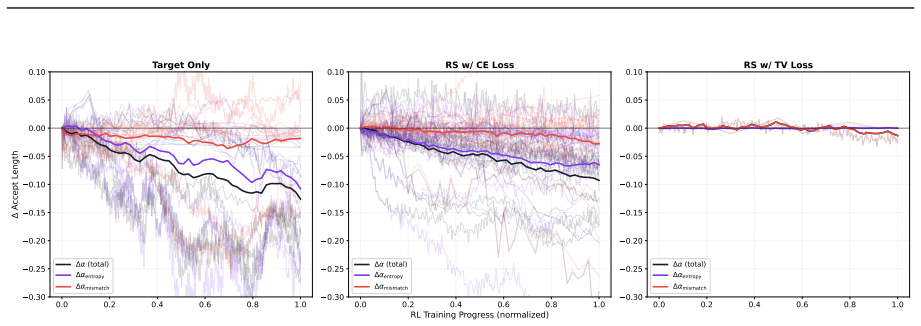
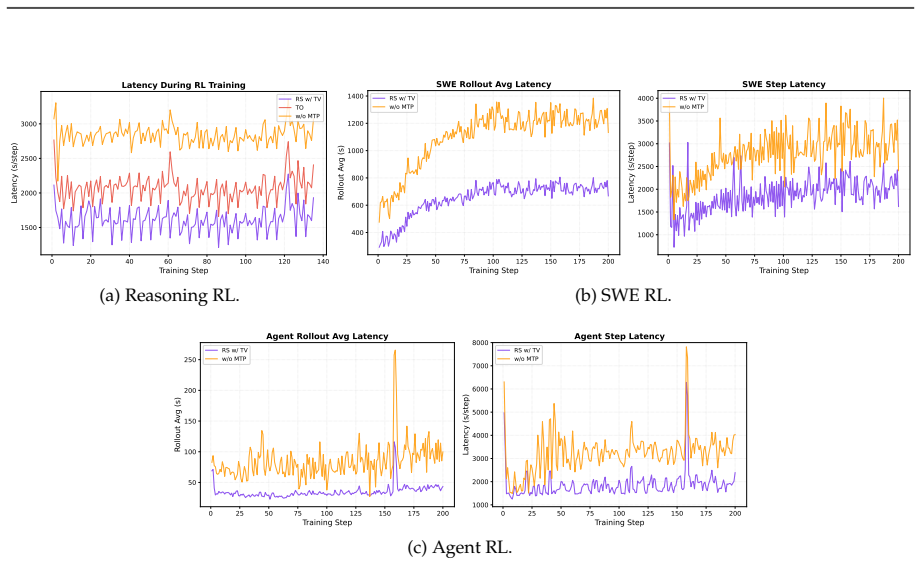
The MTP acceptance rate is fundamentally bounded by the fluctuation of model entropy, which shows a clear negative linear relationship with entropy rise in the RL stage; probabilistic rejection sampling largely alleviates this disturbance, and an end-to-end TV loss that directly optimizes the multi-step rejection sampling acceptance rate yields approximately 10 percent higher acceptance, up to 95 percent rates, up to 25 percent extra inference throughput, and up to 1.8x end-to-end acceleration in async RL training of Qwen3.5, Qwen3.6, and Qwen3.7 models when combined with pre-RL MTP training.
What carries the argument
the end-to-end total variation loss that directly optimizes multi-step rejection sampling acceptance rate for MTP
If this is right
- Pre-RL MTP training with the TV loss and rejection sampling produces stable acceptance rates and speedups throughout the entire RL process.
- Up to 25 percent additional inference throughput is gained across mathematical reasoning, code generation, and agentic tasks.
- Online MTP updating during RL becomes unnecessary, removing associated computational overhead.
- The combination enables consistent 1.8x end-to-end acceleration in asynchronous RL training pipelines.
Where Pith is reading between the lines
- The approach could be tested on model families other than Qwen to check whether the entropy-acceptance relationship generalizes.
- Similar rejection-sampling adjustments might improve other speculative-decoding methods that also suffer entropy degradation.
- Entropy-aware loss design could become a standard lever when combining acceleration techniques with RL post-training.
- Measuring entropy variance early in RL could predict whether MTP will remain useful without retraining.
Load-bearing premise
Entropy fluctuation during RL is the dominant limiter of MTP acceptance rates and maintains a negative linear relationship that holds for the tested models and tasks.
What would settle it
Plotting MTP acceptance rate against model entropy across RL stages on the same models and finding no consistent negative linear relationship, or running the TV loss versus cross-entropy and observing no acceptance-rate gain.
Figures











read the original abstract
Reinforcement learning (RL) has become a key component in modern large language models, yet the rollout stage remains the key bottleneck in RL training pipelines. Although Multi-Token Prediction (MTP) offers a natural solution to accelerate rollouts through speculative decoding, many studies have observed that MTP acceptance rates degrade significantly during RL training, leading to limited speedup performance. To address this bottleneck, we present Bebop, a systematic study of MTP in LLM post-training, and offer practical recipes to integrate MTP into large-scale RL pipelines. First, we reveal that the MTP acceptance rate is fundamentally bounded by the fluctuation of model entropy, which demonstrates a clear negative linear relationship with the rise of entropy in the RL stage. Second, we show that probabilistic rejection sampling largely alleviates the disturbance introduced by entropy in RL compared to greedy draft sampling. We further identify that the conventional MTP training objectives (cross-entropy or KL) are suboptimal in such settings, and therefore we propose a novel end-to-end TV loss that directly optimizes multi-step rejection sampling acceptance rate, yielding ~10% acceptance rate improvements, achieving up to 95% acceptance rates and up to 25% extra inference throughput gains across mathematical reasoning, code generation, and agentic tasks. Third, we test various online MTP training strategies during RL and show that pre-RL MTP training with e2e TV loss and rejection sampling achieves a consistent acceptance rate and speedup throughout the entire RL, eliminating the need for costly online MTP updating. We provide extensive experiments and analysis that validate our findings. Experimental results show our method achieves up to 1.8x end-to-end acceleration in async RL training of Qwen3.5, Qwen3.6, and Qwen3.7 models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Bebop, a framework for integrating Multi-Token Prediction (MTP) into LLM RL post-training to accelerate the rollout bottleneck. It claims that MTP acceptance rates are fundamentally bounded by rising model entropy (via an observed negative linear relationship during RL), shows that probabilistic rejection sampling mitigates entropy-induced degradation better than greedy sampling, and proposes a novel end-to-end total-variation (TV) loss that directly optimizes multi-step acceptance rates. The approach reportedly yields ~10% acceptance gains, up to 95% acceptance rates, 25% extra throughput, and 1.8x end-to-end acceleration on Qwen3.5/3.6/3.7 models across math, code, and agentic tasks, with pre-RL MTP training plus rejection sampling sufficing to maintain performance without online MTP updates.
Significance. If the empirical relationships and speedups are robust, the work addresses a practical bottleneck in scaling RL for LLMs and could enable more efficient post-training pipelines. The emphasis on practical recipes (rejection sampling, TV loss, pre-RL training) and extensive experiments across tasks adds value if the controls and statistics are solid.
major comments (2)
- [Abstract] Abstract (first paragraph): the central claim that MTP acceptance rate 'is fundamentally bounded by the fluctuation of model entropy' rests on an observed negative linear relationship during RL training. This relationship is load-bearing for the motivation of rejection sampling versus greedy draft sampling and for the TV loss; however, the manuscript provides no controlled ablations that hold other factors (policy shift, reward alignment, MTP-head drift) fixed while varying entropy, so it is unclear whether entropy is the dominant causal limiter or merely correlated.
- [Abstract] Abstract: the reported quantitative gains (~10% acceptance improvement, 95% rates, 1.8x end-to-end acceleration, 25% throughput) are presented without reference to the exact baselines, number of independent runs, variance, or statistical tests. These numbers are load-bearing for the practical claims; the full paper must supply them with clear controls against standard MTP + greedy and against online MTP fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments. We will revise the manuscript to improve clarity on the nature of the entropy-acceptance relationship and to provide fuller experimental details as requested.
read point-by-point responses
-
Referee: [Abstract] Abstract (first paragraph): the central claim that MTP acceptance rate 'is fundamentally bounded by the fluctuation of model entropy' rests on an observed negative linear relationship during RL training. This relationship is load-bearing for the motivation of rejection sampling versus greedy draft sampling and for the TV loss; however, the manuscript provides no controlled ablations that hold other factors (policy shift, reward alignment, MTP-head drift) fixed while varying entropy, so it is unclear whether entropy is the dominant causal limiter or merely correlated.
Authors: We acknowledge that the manuscript presents the negative linear relationship as an observed empirical pattern across multiple RL training runs rather than as the result of controlled ablations that isolate entropy while holding policy shift, reward alignment, and MTP-head drift fixed. The claim of being 'fundamentally bounded' is therefore grounded in consistent correlation rather than direct causal evidence. In revision we will temper the wording to 'strongly correlated with' and add a paragraph discussing possible confounding factors. We do not currently have the additional controlled experiments and will note this limitation explicitly. revision: partial
-
Referee: [Abstract] Abstract: the reported quantitative gains (~10% acceptance improvement, 95% rates, 1.8x end-to-end acceleration, 25% throughput) are presented without reference to the exact baselines, number of independent runs, variance, or statistical tests. These numbers are load-bearing for the practical claims; the full paper must supply them with clear controls against standard MTP + greedy and against online MTP fine-tuning.
Authors: The full manuscript already contains comparisons to standard MTP with greedy sampling and evaluates pre-RL versus online MTP training. To meet the request for explicit reporting, we will expand the experimental section to state the precise baseline configurations, the number of independent runs (with seeds), report means and standard deviations, and include any statistical comparisons performed. These additions will be made in the revised version. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents its core claims as empirical observations from training runs (negative linear relationship between entropy rise and MTP acceptance rate; benefits of rejection sampling and TV loss), without any equations, derivations, or first-principles steps that reduce a result to a fitted input or self-referential definition. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing. The reported speedups and acceptance rates are tied directly to experimental measurements rather than any construction that would make the output equivalent to the input by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MTP acceptance rate is fundamentally bounded by model entropy fluctuation with a clear negative linear relationship during RL training.
Reference graph
Works this paper leans on
-
[1]
Draft-OPD: On-Policy Distillation for Speculative Draft Models
URLhttps://openreview.net/forum?id=chfJJYC3iL. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024. URLhttps://openre...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.64434/tml.20251026 2024
-
[2]
The TV gradient is proportional to qj, so it automatically ignores low-probability tokens
The forward KL gradient applies a nonzero force toeverytoken where qj ̸=p j, including tokens with negligible probability. The TV gradient is proportional to qj, so it automatically ignores low-probability tokens
-
[3]
rejected under rejection sampling
The forward KL gradient does not distinguish between tokens that would be accepted vs. rejected under rejection sampling. The TV gradient explicitly incorporates this distinction via the indicator 1[q j ≤p j]
-
[4]
The TV gradient is bounded byq j
The forward KL gradient can be large when qj ≫p j (overconfident draft). The TV gradient is bounded byq j. C Analysis of the Reverse KL Divergence The preceding analysis focuses on the forward KL divergenceD KL(p∥q), which is equivalent to CE loss up to a constant. A natural question is whether the reverse KL divergence DKL(q∥p) = ∑v qv log qv pv would be...
-
[5]
mode-seeking
Zero-forcing behavior.The reverse KL does not penalize q(v)→ 0 even when p(v)> 0, since limq→0 qlog(q/p) = 0. This “mode-seeking” property allows the draft to drop modes of p, directly forfeiting the overlap min(p(v) , q(v)) at those tokens and reducing the acceptance rate. In contrast, the forward KL is “zero-avoiding” (DKL(p∥q)→∞ when q(v)→ 0 with p(v)>...
-
[6]
The reverse KL imposes anasymmetric 22 penalty: over-estimation (qj >p j, so log(qj/p j)> 0) incurs a much stronger gradient than under- estimation
Asymmetric over-/under-estimation penalty.The acceptance ratio of rejection sampling depends on ∑v min(p(v) , q(v)), which penalizes over-estimation ( q>p ) and under-estimation ( q<p ) symmetrically—both reduce the overlap by |q(v)−p(v)| . The reverse KL imposes anasymmetric 22 penalty: over-estimation (qj >p j, so log(qj/p j)> 0) incurs a much stronger ...
-
[7]
Indirect optimization target.Like the forward KL, the reverse KL does not directly optimize dTV(p, q). The log-ratio log(qj/p j) in the reverse KL gradient provides a soft, nonlinear signal, whereas the TV gradient’s indicator 1[q j ≤p j] provides a hard, direct signal aligned with the rejection sampling decision boundary. Summary.In terms of suitability ...
-
[8]
to p( ˆv)<p(v ∗ 1), introducing an additional entropy-dependent deficit. Both effects reinforce the negative slope, so the linear approximation still holds with a potentially steeper slope: αTO ≈a TO −b TO · H(p), (22) where the slope bTO is empirically comparable to bRS (see §6), though the two arise from different mechanisms: bTO is driven by the concen...
-
[9]
Practical considerations.The above analysis assumes δ is a constant, but in practice, the draft head has finite capacity
(42) This bound is independent ofH(p), yielding: αRS TV ≥1− δ 2, (43) which proves Proposition 4. Practical considerations.The above analysis assumes δ is a constant, but in practice, the draft head has finite capacity. When H(p) increases, the effective support |Seff(p)| ≈exp(H(p)) grows, and maintaining uniform relative accuracy across more tokens may r...
-
[10]
, γ, draw ui ∼Uniform( 0, 1) and accept ˆyi if ui ·q i( ˆyi)<p i( ˆyi), i.e., with probability min 1,p i( ˆyi)/qi( ˆyi)
Sequential acceptance: For each draft step i= 1, . . ., γ, draw ui ∼Uniform( 0, 1) and accept ˆyi if ui ·q i( ˆyi)<p i( ˆyi), i.e., with probability min 1,p i( ˆyi)/qi( ˆyi) . Stop at the first rejection
-
[11]
For rejection at step j, the residual distribution is presid(v)∝max( 0, pj(v)−q j(v)); for the bonus token (all accepted), the residual is simply pγ(v)
Residual resampling: If draft token ˆyj is rejected at step j, or if all γ drafts are accepted (bonus token case), sample the next token from the residual distribution. For rejection at step j, the residual distribution is presid(v)∝max( 0, pj(v)−q j(v)); for the bonus token (all accepted), the residual is simply pγ(v). The kernel computes this via a two-...
-
[12]
The kernel records the index of the first rejected step
Acceptance kernel: A sequential Triton kernel iterates over draft steps, computing p( ˆyi) and q( ˆyi) from the cached target and draft probabilities, and accepting if ui ·q( ˆyi)<p( ˆyi) for a pseudo- random ui generated via tl.rand seeded by the request’s random seed and position. The kernel records the index of the first rejected step. 6https://github....
-
[13]
For rejection at step j: zresid(v) =log max( 0, pj(v)−q j(v)); for the bonus token: zresid(v) =z target,γ(v) (the raw target logits)
Residual logits kernel: A parallel Triton kernel computes the residual distribution in logit space. For rejection at step j: zresid(v) =log max( 0, pj(v)−q j(v)); for the bonus token: zresid(v) =z target,γ(v) (the raw target logits). The resampled token is then drawn from this residual distribution using the same Gumbel-Max sampling as the draft stage. Al...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.