Selecting Samples on Graphs: A Unified Dataset Pruning Framework for Lossless Training Acceleration
Pith reviewed 2026-06-27 07:20 UTC · model grok-4.3
The pith
Modeling datasets as weighted graphs casts dataset pruning as a maximum-weight clique problem with approximation guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing the dataset as a weighted graph in which node weights encode intrinsic value and edge weights encode extrinsic value, dataset pruning becomes the Maximum Weight Clique Problem. Although NP-hard, the structure permits a greedy solution driven by sample-wise marginal gains, and under mild conditions the unified objective admits a formal approximation guarantee that applies to a broad family of importance metrics and supplies concrete design guidelines.
What carries the argument
The weighted-graph model of the dataset that converts pruning into the Maximum Weight Clique Problem, solved by selecting samples according to marginal gain.
Load-bearing premise
The node weights and edge weights chosen to represent intrinsic and extrinsic signals together give a faithful picture of each sample's true utility for the final training task.
What would settle it
Run the greedy algorithm on a dataset whose optimal maximum-weight clique is known by exhaustive search; if the returned subset yields lower downstream accuracy than the true optimum at the same size, the modeling or guarantee does not hold.
Figures
read the original abstract
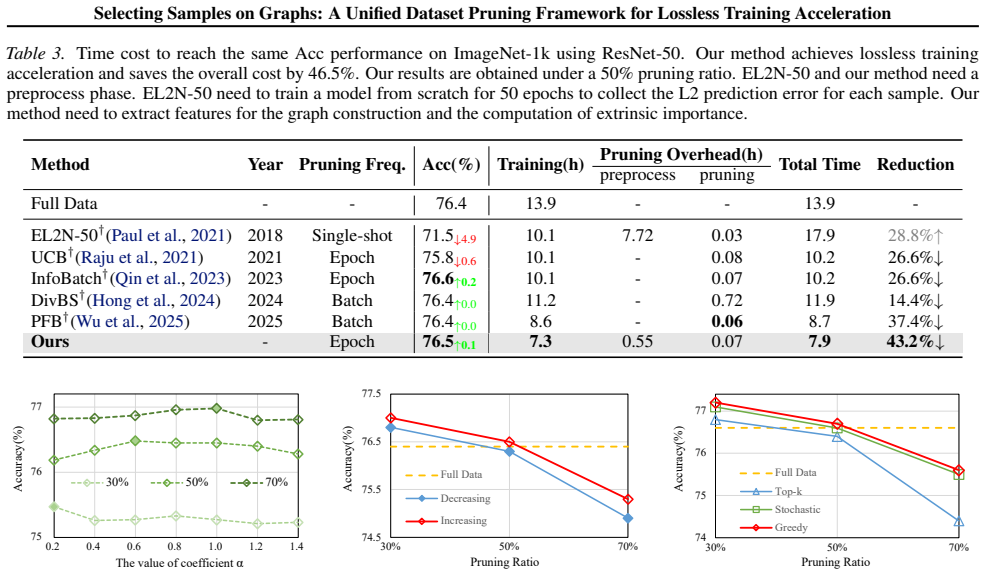
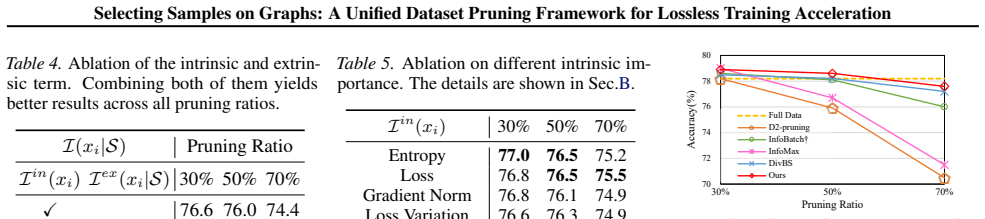
The rapid growth of modern training datasets has significantly increased computational cost, motivating dataset pruning~(DP) methods which retain only a subset of informative samples to reduce training cost. Existing pruning criteria typically rely on either intrinsic signals that assess samples independently or extrinsic signals that promote diversity via pairwise relations. While effective in their own specific regimes, each captures only one aspect of sample utility and lacks robustness across different pruning ratios or data distribution. In this work, we present a unified graph-based DP framework. By modeling the dataset as a weighted graph, where node weights encode intrinsic value and edge weights encode extrinsic value, DP can be cast as a Maximum Weight Clique Problem (MWCP). Although MWCP is NP-hard, its structure admits a principled greedy solution based on sample-wise marginal gains. Under a few mild conditions, we further prove that this unified objective enjoys a formal approximation guarantee, which applies to a broad family of importance metrics and provides practical design guidelines. Extensive experiments show that our method outperforms existing DP methods while substantially reducing training cost, reducing training time by over 40\% without sacrificing accuracy on ImageNet-1k with ResNet-50.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified dataset pruning (DP) framework that models the dataset as a weighted graph, with node weights representing intrinsic sample value and edge weights representing extrinsic (pairwise diversity) value. It casts DP as the Maximum Weight Clique Problem (MWCP), derives a greedy algorithm based on sample-wise marginal gains, and claims a formal approximation guarantee under mild conditions that applies to a broad family of importance metrics. Experiments report >40% wall-clock training reduction on ImageNet-1k/ResNet-50 while preserving accuracy and outperforming prior DP methods.
Significance. If the MWCP modeling and approximation guarantee hold under the stated conditions, the work supplies a principled unification of intrinsic and extrinsic pruning signals together with design guidelines, which could improve robustness across pruning ratios and data distributions. The empirical speedups are practically relevant for large-scale training if the results are reproducible with error bars and ablations.
major comments (2)
- [theoretical analysis / proof section] The abstract and theoretical section state a formal approximation guarantee under mild conditions, but the manuscript does not explicitly list or verify those conditions, nor does it provide the derivation steps. This makes it impossible to assess whether the guarantee applies to the importance metrics used in the experiments (e.g., the node/edge weight definitions).
- [experimental results] Experiments claim strong gains with >40% training time reduction, but report no error bars across runs and provide no ablation on the sensitivity of results to the choice of intrinsic vs. extrinsic signals or the MWCP formulation parameters. This weakens the claim that the method is robust across pruning ratios.
minor comments (2)
- [framework definition] Notation for node weights (intrinsic) and edge weights (extrinsic) should be introduced with explicit equations early in the framework section to improve readability.
- [design guidelines] The paper should include a short table or list mapping common importance metrics (e.g., EL2N, gradient norm) to the corresponding node/edge weight choices.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive recommendation. We address each major comment below.
read point-by-point responses
-
Referee: [theoretical analysis / proof section] The abstract and theoretical section state a formal approximation guarantee under mild conditions, but the manuscript does not explicitly list or verify those conditions, nor does it provide the derivation steps. This makes it impossible to assess whether the guarantee applies to the importance metrics used in the experiments (e.g., the node/edge weight definitions).
Authors: We agree that the conditions and derivation steps must be stated explicitly. In the revised manuscript we will insert a dedicated subsection that lists the mild conditions, supplies the complete derivation of the approximation guarantee, and verifies that the conditions hold for the specific node- and edge-weight definitions employed in the experiments. revision: yes
-
Referee: [experimental results] Experiments claim strong gains with >40% training time reduction, but report no error bars across runs and provide no ablation on the sensitivity of results to the choice of intrinsic vs. extrinsic signals or the MWCP formulation parameters. This weakens the claim that the method is robust across pruning ratios.
Authors: We acknowledge that error bars and targeted ablations are necessary to substantiate robustness claims. The revised manuscript will report standard deviations over multiple independent runs and will include new ablations that isolate the contribution of intrinsic versus extrinsic signals as well as the effect of MWCP formulation parameters across pruning ratios. revision: yes
Circularity Check
No significant circularity; derivation is self-contained mathematical modeling
full rationale
The paper casts dataset pruning as an MWCP on a graph with node/edge weights for intrinsic/extrinsic value, then derives a greedy marginal-gain algorithm and an approximation guarantee under stated mild conditions. This is a standard reduction to a known combinatorial problem followed by analysis of that problem; the guarantee is a theorem about MWCP, not a renaming or fit of the input metrics. No self-citation is load-bearing for the central claim, no parameter is fitted then relabeled as prediction, and no step equates the output to the modeling choice by definition. The framework remains independent of the specific importance metrics chosen.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A few mild conditions under which the MWCP greedy algorithm enjoys a formal approximation guarantee
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., 9 Selecting Samples on Graphs: A Unified Dataset Pruning Framework for Lossless Training Acceleration Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Super-Samples from Kernel Herding
Chen, Y ., Welling, M., and Smola, A. Super-samples from kernel herding.arXiv preprint arXiv:1203.3472,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
AutoAugment: Learning Augmentation Policies from Data
Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V ., and Le, Q. V . Autoaugment: Learning augmentation policies from data.arXiv preprint arXiv:1805.09501,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Jiang, A. H., Wong, D. L.-K., Zhou, G., Andersen, D. G., Dean, J., Ganger, G. R., Joshi, G., Kaminksy, M., Kozuch, M., Lipton, Z. C., et al. Accelerating deep learning by focusing on the biggest losers.arXiv preprint arXiv:1910.00762,
-
[5]
Online Batch Selection for Faster Training of Neural Networks
Loshchilov, I. and Hutter, F. Online batch selection for faster training of neural networks.arXiv preprint arXiv:1511.06343,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
S., Daruwalla, K., and Lipasti, M
Raju, R. S., Daruwalla, K., and Lipasti, M. Accelerating deep learning with dynamic data pruning.arXiv preprint arXiv:2111.12621,
-
[7]
Senzaki, Y . and Hamelain, C. Active learning for deep neural networks on edge devices.arXiv preprint arXiv:2106.10836,
-
[8]
Coverage- centric coreset selection for high pruning rates
Zheng, H., Liu, R., Lai, F., and Prakash, A. Coverage- centric coreset selection for high pruning rates. In11th International Conference on Learning Representations, ICLR 2023,
2023
-
[9]
First, interpretations on the accuracy improvement of our method and other existing methods (such as InfoBatch) are presented (Sec
12 Selecting Samples on Graphs: A Unified Dataset Pruning Framework for Lossless Training Acceleration Appendix This appendix provides additional details and results to complement the main paper. First, interpretations on the accuracy improvement of our method and other existing methods (such as InfoBatch) are presented (Sec. A). Next, we introduce the fu...
2023
-
[10]
Since DivBS performs batch-wise pruning, we adapt our UGIES accordingly and denote this variant asOurs-BS
following the DivBS configuration. Since DivBS performs batch-wise pruning, we adapt our UGIES accordingly and denote this variant asOurs-BS. We similarly adapt InfoBatch for fairness (denoted asInfoBatch- BS). We evaluate the performance under pruning ratios of 70%, 80%, and 90%, and report final mIoU. As shown in Tab. 6, Ours-BS consistently achieves th...
2012
-
[11]
Performance on Object Detection We further evaluate generalization on object detection using SSD-ResNet50 trained on COCO2017 (Lin et al., 2014)
69.80 67.97 64.66 Ours-BS 70.02 68.48 65.79 Full Data 70.80 D.2. Performance on Object Detection We further evaluate generalization on object detection using SSD-ResNet50 trained on COCO2017 (Lin et al., 2014). We compare with InfoBatch (Qin et al.,
2014
-
[12]
and D2-pruning (Maharana et al., 2024). Tab. 7 shows that our method attains the highest AP across all metrics, indicating strong adaptability to various vision tasks. 14 Selecting Samples on Graphs: A Unified Dataset Pruning Framework for Lossless Training Acceleration Table 7.Object detection pruning on COCO2017 using SSD ResNet-50. † denotes our reprod...
2024
-
[13]
(Nemhauser et al., 1978)
For a more detailed and rigorous derivation, we refer the reader to the original work of Nemhauser et al. (Nemhauser et al., 1978). Proof. We may, without loss of generality, assumef(∅) = 0, since adding a constant to f does not change marginal gains nor the greedy solution. LetS t be the greedy set aftertsteps, withS 0 =∅and|S t|=t. By submodularity, for...
1978
-
[14]
SinceBis exponential in the worst case, the overall complexity remains exponential
term reflects repeated weighted-coloring and pruning operations at each node. SinceBis exponential in the worst case, the overall complexity remains exponential. In our setting, each subgraph is fully connected, so clique feasibility no longer provides strong pruning, and the problem reduces to selecting a fixed-size subset of size b= (1−p)N . This solver...
2008
-
[15]
AutoAugment (Cubuk et al., 2018), random path drop, and gradient clipping are applied only to Swin-T to ensure a fair comparison with Dyn-Unc
training settings; for Swin-T we follow Dyn-Unc (He et al., 2024). AutoAugment (Cubuk et al., 2018), random path drop, and gradient clipping are applied only to Swin-T to ensure a fair comparison with Dyn-Unc. The hyperparameters required for reproduction are listed in the Tab
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.