LoRA-Muon: Spectral Steepest Descent on the Low-Rank Manifold
Pith reviewed 2026-06-27 07:15 UTC · model grok-4.3
The pith
LoRA-Muon applies the spectral steepest-descent rule to low-rank factors to act as a reliable proxy for full-rank Muon optimizers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
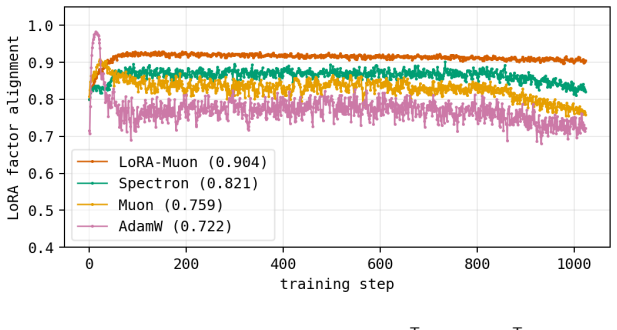
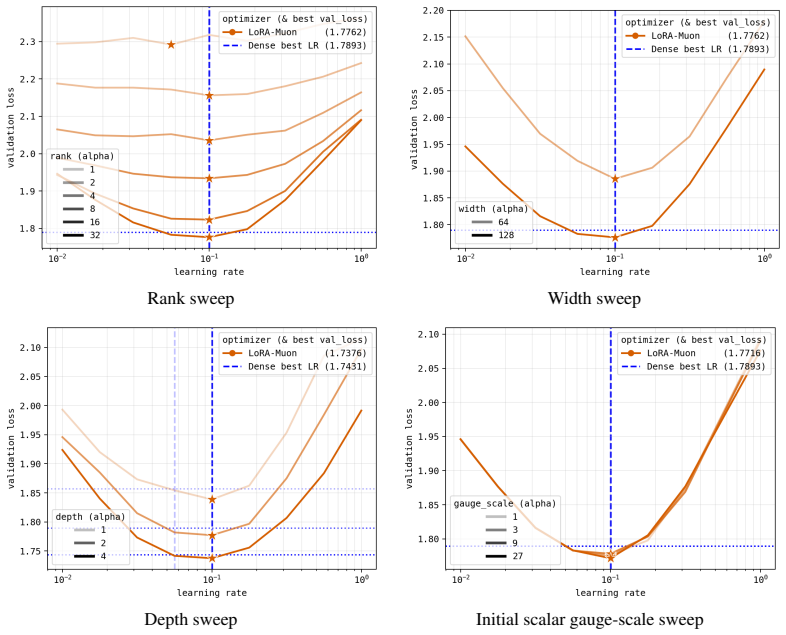
LoRA-Muon is a good low-rank proxy for full-rank Muon and Shampoo-family optimizers. Its optimal learning rates transfer across rank, width, depth, and factor-rescaling. In compute-matched TinyShakespeare study, a rank-2 proxy recovers the dense best tested learning rate, and a rank-32 LoRA-Muon run attains lower mean validation loss than the dense baseline in the seed-averaged sweep.
What carries the argument
The spectral steepest-descent rule applied to the low-rank factors, together with the split weight-decay rule.
If this is right
- Optimal learning rates transfer across rank, width, depth, and factor-rescaling.
- A rank-2 proxy recovers the dense best tested learning rate.
- A rank-32 LoRA-Muon run attains lower mean validation loss than the dense baseline.
- LoRA-Muon computes the update without QR-decomposition and avoids storing second moments.
Where Pith is reading between the lines
- LoRA-Muon could allow practitioners to use very low ranks for adapters without retuning learning rates for each choice.
- The method may extend to other spectral or Shampoo-style optimizers in low-rank settings.
- By avoiding second moments it reduces memory pressure during finetuning of large models.
- Performance gains at moderate ranks suggest it could replace dense training in some regimes.
Load-bearing premise
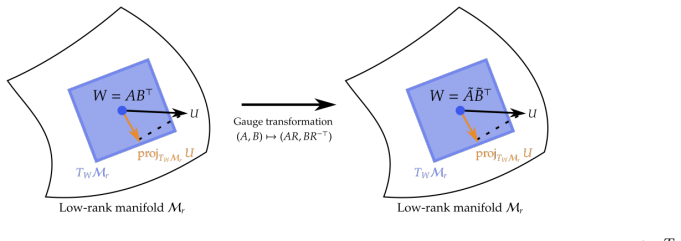
That applying the spectral steepest-descent rule to low-rank factors with split weight-decay preserves the convergence properties of full-rank Muon without new rank-dependent sensitivities.
What would settle it
A set of runs in which the best learning rate for LoRA-Muon at one rank fails to perform well at another rank, or where no rank of LoRA-Muon matches or beats the dense Muon validation loss.
Figures
read the original abstract
Low-Rank Adaptation (LoRA) significantly reduces compute and memory costs for finetuning Deep Learning models but is often harder to tune than dense training: when using factor-wise optimizers such as AdamW, it is sensitive to initialization choices, its optimal learning rates transfer poorly across ranks, and it often fails to beat dense baselines. We derive LoRA-Muon by applying the Muon optimizer's spectral steepest-descent rule to the low-rank setting. Along with our split weight-decay rule, our main claim is that LoRA-Muon is a good low-rank proxy for full-rank Muon and Shampoo-family optimizers. Its optimal learning rates transfer across rank, width, depth, and factor-rescaling. In our compute-matched TinyShakespeare study, a rank-$2$ proxy recovers the dense best tested learning rate, and a rank-$32$ LoRA-Muon run attains lower mean validation loss than the dense baseline in the seed-averaged sweep. We further show that the Spectron optimizer depends on arbitrary factor scaling, so it would likely be a poor fit when finetuning starts from badly imbalanced factors, and that LoRA-RITE's simplified QR-coordinate core implements the same spectral update. LoRA-Muon computes that update without QR-decomposition and avoids storing second moments, making it more accelerator-friendly and memory-efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoRA-Muon by applying Muon's spectral steepest-descent rule directly to the low-rank factors of LoRA adapters, together with a split weight-decay rule. It claims this yields a good low-rank proxy for full-rank Muon and Shampoo-family optimizers whose optimal learning rates transfer across rank, width, depth, and factor rescaling. In compute-matched TinyShakespeare experiments, a rank-2 proxy recovers the dense best-tested learning rate while a rank-32 run attains lower mean validation loss than the dense baseline in seed-averaged sweeps. The work also contrasts Spectron's dependence on factor scaling and notes that LoRA-RITE implements an equivalent spectral update without QR or second moments.
Significance. If the proxy property and LR-transfer claims hold, the result would be significant for efficient finetuning: it directly targets LoRA's documented tuning difficulties with factor-wise optimizers and offers a memory-efficient, accelerator-friendly alternative that can match or exceed dense baselines under compute-matched conditions. The empirical TinyShakespeare study provides initial evidence of practical utility, and the avoidance of QR decomposition and second-moment storage is a concrete implementation advantage.
major comments (2)
- [Derivation section] Derivation section: the manuscript applies the spectral steepest-descent rule factor-wise to the low-rank factors together with the split weight-decay modification, but supplies no analysis or bound showing that the resulting update on the product matrix approximates Riemannian steepest descent on the fixed-rank manifold or matches full-rank Muon closely enough for rank-independent LR transfer. This assumption is load-bearing for the central proxy claim.
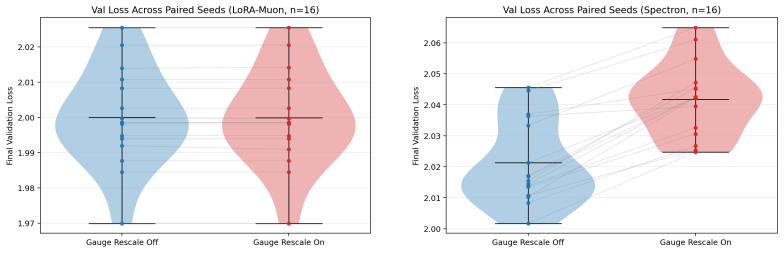
- [TinyShakespeare study] TinyShakespeare study (experimental results): the claims that rank-2 recovers the dense optimal LR and rank-32 attains lower mean validation loss than the dense baseline are presented without visible error bars, seed count, exact exclusion rules, or full protocol details. These omissions prevent verification of the performance and transfer assertions that support the proxy conclusion.
minor comments (1)
- [Abstract] Abstract: Spectron and LoRA-RITE are referenced without prior definition or citation; a brief contextual sentence would improve readability for readers unfamiliar with those baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, providing the strongest honest defense of the manuscript while acknowledging where additional details or revisions are warranted.
read point-by-point responses
-
Referee: [Derivation section] Derivation section: the manuscript applies the spectral steepest-descent rule factor-wise to the low-rank factors together with the split weight-decay modification, but supplies no analysis or bound showing that the resulting update on the product matrix approximates Riemannian steepest descent on the fixed-rank manifold or matches full-rank Muon closely enough for rank-independent LR transfer. This assumption is load-bearing for the central proxy claim.
Authors: The derivation proceeds by directly transplanting Muon's spectral steepest-descent rule to the factors A and B of the LoRA update together with the split weight-decay modification; no claim is made that this exactly reproduces Riemannian steepest descent on the fixed-rank manifold. The central proxy claim is instead that the resulting optimizer inherits the rank-independent learning-rate transfer property observed for full-rank Muon and Shampoo-family methods. This property is demonstrated empirically across the reported rank, width, depth, and rescaling sweeps rather than derived from a theoretical bound. We view the absence of such a bound as a limitation of scope—the paper emphasizes a practical, accelerator-friendly implementation—rather than a flaw in the presented evidence. revision: no
-
Referee: [TinyShakespeare study] TinyShakespeare study (experimental results): the claims that rank-2 recovers the dense optimal LR and rank-32 attains lower mean validation loss than the dense baseline are presented without visible error bars, seed count, exact exclusion rules, or full protocol details. These omissions prevent verification of the performance and transfer assertions that support the proxy conclusion.
Authors: The referee correctly notes that the current experimental reporting is insufficient for full verification. In the revised manuscript we will add (i) error bars showing standard error of the mean across the five independent random seeds used for every sweep, (ii) an explicit statement of the seed count, (iii) confirmation that no runs were excluded from the reported averages, and (iv) expanded protocol details covering the precise compute-matching procedure, hyperparameter grids, and initialization scheme. These additions will directly address the verifiability concern while leaving the underlying experimental outcomes unchanged. revision: yes
Circularity Check
No significant circularity; derivation applies external Muon rule directly
full rationale
The paper derives LoRA-Muon explicitly as the application of the pre-existing Muon spectral steepest-descent rule (plus a split weight-decay modification) to low-rank factors. No equations or central claims reduce the transfer properties, convergence behavior, or proxy performance to quantities defined or fitted inside this paper. Empirical results on TinyShakespeare are presented separately as validation rather than as mathematical necessities. Comparisons to Spectron and LoRA-RITE are external and do not create self-referential loops. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The spectral steepest-descent rule from the Muon optimizer can be applied directly to the low-rank factors of LoRA.
Reference graph
Works this paper leans on
-
[1]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2022
Pith/arXiv arXiv 2022
-
[2]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations, 2015. URL https://arxiv.org/abs/1412. 6980
2015
-
[3]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[4]
Nan Chen, Soledad Villar, and Soufiane Hayou. Learning rate scaling across LoRA ranks and transfer to full finetuning.arXiv preprint arXiv:2602.06204, 2026
arXiv 2026
-
[5]
Stabilizing native low-rank LLM pretraining.arXiv preprint arXiv:2602.12429, 2026
Paul Janson, Edouard Oyallon, and Eugene Belilovsky. Stabilizing native low-rank LLM pretraining.arXiv preprint arXiv:2602.12429, 2026
arXiv 2026
-
[6]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Pith/arXiv arXiv 2024
-
[7]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon
2024
-
[8]
Deriving Muon, 2025
Jeremy Bernstein. Deriving Muon, 2025. URL https://jeremybernste.in/writing/ deriving-muon
2025
-
[9]
Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982, 2025
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. Muon is sca...
Pith/arXiv arXiv 2025
-
[10]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, pages 1842–1850. PMLR, 2018
2018
-
[11]
Scalable second order optimization for deep learning.arXiv preprint arXiv:2002.09018, 2021
Rohan Anil, Vineet Gupta, Tomer Koren, Kevin Regan, and Yoram Singer. Scalable second order optimization for deep learning.arXiv preprint arXiv:2002.09018, 2021
arXiv 2002
-
[12]
CASPR without accumulation is Muon, February 2025
Franz Louis Cesista. CASPR without accumulation is Muon, February 2025. URL https: //leloykun.github.io/ponder/caspr-wo-accum-is-muon/
2025
-
[13]
Weight decay may matter more than µp for learning rate transfer in practice
Atli Kosson, Jeremy Welborn, Yang Liu, Martin Jaggi, and Xi Chen. Weight decay may matter more than µp for learning rate transfer in practice. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[14]
Zhang, Niccolò Ajroldi, Bernhard Schölkopf, and Antonio Orvieto
Egor Shulgin, Dimitri von Rütte, Tianyue H. Zhang, Niccolò Ajroldi, Bernhard Schölkopf, and Antonio Orvieto. Deriving hyperparameter scaling laws via modern optimization theory.arXiv preprint arXiv:2603.15958, 2026
arXiv 2026
-
[15]
On the role of batch size in stochastic conditional gradient methods
Rustem Islamov, Roman Machacek, Aurelien Lucchi, Antonio Silveti-Falls, Eduard Gorbunov, and V olkan Cevher. On the role of batch size in stochastic conditional gradient methods. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[16]
Boyd and Lieven Vandenberghe.Convex optimization
Stephen P. Boyd and Lieven Vandenberghe.Convex optimization. Cambridge University Press, Cambridge, UK ; New York, 2004. ISBN 978-0-521-83378-3
2004
-
[17]
Training deep learning models with norm-constrained LMOs
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and V olkan Cevher. Training deep learning models with norm-constrained LMOs. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 49069–49104. PMLR, 13–19 Jul 2025. 10
2025
-
[18]
Boumal.An Introduction to Optimization on Smooth Manifolds
Nicolas Boumal.An introduction to optimization on smooth manifolds. Cambridge University Press, 2023. doi: 10.1017/9781009166164
-
[19]
Tenenholtz, Lester Mackey, and Nicolo Fusi
Mikhail Khodak, Neil A. Tenenholtz, Lester Mackey, and Nicolo Fusi. Initialization and regu- larization of factorized neural layers. InInternational Conference on Learning Representations, 2021
2021
-
[20]
char-rnn, 2015
Andrej Karpathy. char-rnn, 2015. URLhttps://github.com/karpathy/char-rnn
2015
-
[21]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[22]
Query-Key Normalization for Transformers
Alex Henry, Prudhvi Raj Dachapally, Shubham Shantaram Pawar, and Yuxuan Chen. Query-key normalization for transformers. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4246–4253, Online, nov 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.379
-
[23]
RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021
Pith/arXiv arXiv 2021
-
[24]
Flexattention: A programming model for generating fused attention variants
Juechu Dong, BOYUAN FENG, Driss Guessous, Yanbo Liang, and Horace He. Flexattention: A programming model for generating fused attention variants. InProceedings of Machine Learning and Systems, volume 7. MLSys, 2025
2025
-
[25]
Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415, 2016
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415, 2016
Pith/arXiv arXiv 2016
-
[26]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[27]
Scalable optimization in the modular norm.arXiv preprint arXiv:2405.14813, 2024
Tim Large, Yang Liu, Minyoung Huh, Hyojin Bahng, Phillip Isola, and Jeremy Bernstein. Scalable optimization in the modular norm.arXiv preprint arXiv:2405.14813, 2024
arXiv 2024
-
[28]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=yRtgZ1K8hO. 11 A Proofs A.1 From the decoupled subproblems to the closed-form factor...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.